Personalized product and content recommendations are used to increase conversion, average check and improve user experience.

An example of using the approach is Amazon and Netflix. Amazon began using a collaborative filtering approach in the early years of its existence and achieved revenue growth only through the algorithm by 10%. Netflix increases the amount of viewed content due to the approach based on the recommendation system algorithm by 40%. Now, it’s easier to name a company that doesn’t use this approach than to list all who use it.
Netflix has a fascinating story related to this technology. In 2006-2009 (even before the Kaggle ML competition venue became popular), Netflix announced an open contest to improve the algorithm with a prize pool of $ 1,000,000. The competition lasted 2 years and several thousand developers and scientists participated in it. If Netflix hired them in the state, the costs would be many times higher than the promised prize. As a result, one of the teams won by sending a solution with the required quality 2 hours earlier than the other team, repeating the result of the winner. As a result, the money went to a quick team. The competition has become a catalyst for qualitative changes in the field of personalized recommendations.
The main approach to solving the problem of constructing recommender systems is collaborative filtering.
The idea of collaborative filtering is simple - if a user made a purchase of a product or viewed content, we’ll find users with similar tastes and recommend to our client that people like him have consumed, but the client hasn’t. This is a user-based approach.
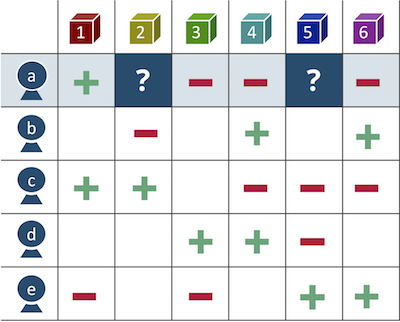
Figure 1 - Product preference matrix
Similarly, you can look at the problem from the point of view of the goods, and pick up complementary goods to the customer’s basket by increasing the average check, or replacing the goods that are not in stock by an analogue. This is an Item-Based approach.
In the simplest case, the algorithm for finding the nearest neighbors is used.
Example: If Maria likes the film “Titanic” and “Star Wars”, the closest user to her tastes will be Anya, who also watched “Hachiko” in addition to these films. Let's recommend Maria the movie “Hachiko”. It is worth clarifying that usually they use not one nearest neighbor, but several, with averaging of the results.
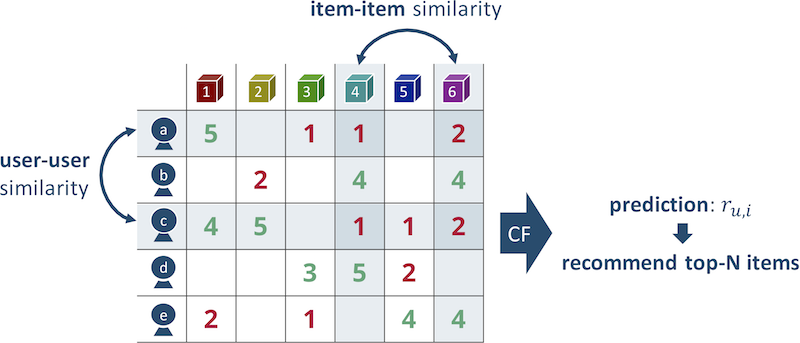
Fig. 2 The principle of operation of the algorithm of the nearest neighbors
Everything seems to be simple, but the quality of the recommendations using this approach is small.
Consider complex algorithms of recommendation systems based on the property of matrices, or rather, on the decomposition of matrices.
The classic algorithm is SVD (singular matrix decomposition).
The meaning of the algorithm is that the matrix of product preferences (the matrix where the rows are users and the columns are the products with which users interacted) is represented as the product of three matrices.
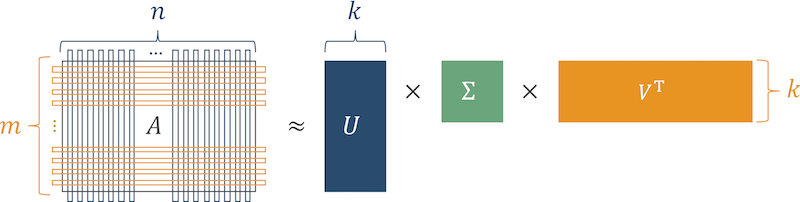
Fig. 3 SVD algorithm
After restoring the original matrix, cells where the user had zeros and “large” numbers appeared, show the degree of latent interest in the product. Arrange these numbers and get a list of products relevant to the user.
During this operation, the user and the product appear "latent" signs. These are signs showing the "hidden" state of the user and the product.
But it is known that both the user and the product, in addition to “latent” ones, also have obvious signs. This is gender, age, average purchase receipt, region, etc.
Let's try to enrich our model with this data.
To do this, we use the factorization machine algorithm.
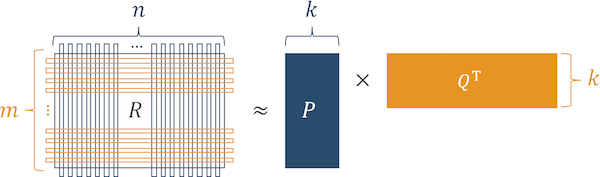
Fig. 4 Algorithm of operation of factorization machines
From our experience, at Data4 , case studies in the field of building recommendation systems for online stores, namely factorization machines, give the best result. So, we used factorization machines to build a recommendation system for our client, KupiVip. The growth in the RMSE metric was 6-7%.
But matrix-based approaches have their drawbacks. The number of generalized patterns of mutual combination of goods is not large. To solve this problem, it is advisable to use neural networks. But a neural network requires volumes of data that only large companies have.
From our experience, at Data4 , only one client has a neural network for personalized product recommendations that gave the best result. But, with success, you can get up to 10% of the RMSE metric. Neural networks are used on YouTube and some of the largest content sites.
Use cases
For online stores
- Recommend products relevant to the user on the pages of the online store
- Use the “you may like” block in the product card
- In your cart recommend complementary goods (remote control for TV)
- If the product is not in stock, recommend an analog.
- Make personalized newsletters
For content
- Increase engagement by recommending relevant articles, films, books, videos
Other
- Recommend people in dating apps
- Recommend dishes in a restaurant
In the article, we discussed the basics of the design of recommender systems and use cases. We learned that the basic principle is to recommend products that people with a similar taste like and to use the collaborative filtering algorithm.
In the next article , life hacks of recommendation systems based on real business cases will be considered. We show which metrics are best used and which proximity coefficient to choose for prediction.