In this article, life hacks of recommendation systems based on real business cases will be considered. It will show which metrics are better to use, and what degree of proximity to choose for prediction.
Machine learning uses various metrics to evaluate the performance of algorithms. But in business, the basic metric is the same - how much money the implementation of the solution will bring. Based on this, in our cases that the Data4 team implements , we try to increase the total revenue per user.
To maximize revenue, it is useful to know what products the user has purchased. But unfortunately, if we build the matrix of product preferences only on data on purchases, our matrix will turn out to be sparse, and the quality will suffer.
Lifehack number 1
Let's use in the matrix of product preferences not only purchases, but also intermediate steps: clicking on a card, adding to the basket, placing an order.
We will assign a weight coefficient to each action, and our matrix will turn out to be more “dense”.
But not all products are equally conversion. After opening the card, a person may not continue the purchase due to the “internal” properties of the goods. Example: luxury items are often viewed, but bought little.
Life hack number 2
Let's build the distribution of goods for each stage of the funnel, and remove from the recommendations for 5-10% of the lowest conversion products at each stage. The main thing is not to “splash out the baby with water”. The remaining goods will have “internal” properties that do not impede the purchase. An example of an internal property is clothing sizes available. If the product is good, but only of one size, the conversion will be low.
We figured out the goods, now let's look at how to measure the "similarity" of the user.
There are many similarity metrics, starting with cosine proximity, least squares, and ending with exotic options.
Lifehack number 3
Based on the experience of Data4 in building recommender systems for online stores, work is underway with discharged matrices. For such matrices, it is best to use the proximity coefficient - Jacquard. This gives an increase in metrics more than a change of algorithms.
Lifehack number 4
Before using neural networks, try SVD and factorization machines. It works.
Fig. 1 The principle of operation of factorization machines
Lifehack number 5
Recognizing similar products by image is fun, but quality using behavior-based SVDs is better.
Lifehack number 6
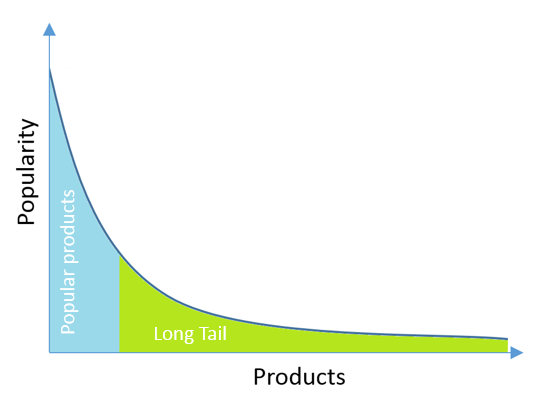
Recommend new products to new users (this overcomes the problem of a cold start), and to regular users from the long tail of the distribution of product popularity. Recommendations work well when they recommend low-frequency products suitable for the user. It makes no sense to recommend the Titanic movie, if the user wanted to watch it, he already watched it. But a little-known movie or product can pleasantly surprise the user.
Lifehack number 7
Make a variety of recommendations, no one wants to open the page, see 10 identical fur coats, or just films of one director. A variety of content increases the likelihood of a purchase.

Lifehack number 8
Choose a metric that you understand how it works. Let a simple RMSE, but a reliable result than nDCG @ K (this metric is suitable), and a random result.
Lifehack number 9
People can take offense at the recommendations, so women should not recommend large sizes of clothing if you do not know their size.
Lifehack number 10
Just conducting an A / B test on users will tell you how the solution works. Quality metrics - an intermediate result, A / B test - confirmation, which may disappoint you, but often pleases.
Using the described techniques, our Data4 team carried out several cases of implementing recommendation systems.
In the article, we talked that to improve the quality of the recommendation system, you can 1) take into account intermediate user actions 2) Eliminate low-conversion products 3) Use the Jacquard coefficient for sparse matrices 4) Use SVD and factorization machines if you are not Google 5) Be careful when searching for proximity according to the image, if the budget is limited 6) Recommend non-obvious products to old users from the tail of distribution of popularity 7) Recommend various products 8) Use the right quality metrics wa 9) Do not offend people with recommendations 10) Use the A / B test to verify the result.