
人がするように世界を見て理解するためにさまざまなシステムを教える試みは数十年前に始まりましたが、今ではこれらの技術は完璧になり、私たちの生活の多くの分野で積極的に使用されています。 Habréにはマシンビジョン、ニューラルネットワーク、認識アルゴリズムに関する詳細な記事が既にあります。これらの複雑なテクノロジーについては詳しく説明しません。実際の世界でのこれらのシステムの実用化について説明します。
どのように機能しますか? 簡単に
画像認識システムにとって、私たちにとって写真とは、さまざまな色のパラメーターを持つピクセルのセットです。 画像内の個々のオブジェクトを認識するようにシステムに教えるには、データセットを提供する必要があります。これは、目的のオブジェクトがどこにあるかを正確に示す数千の画像のセットです。 たとえば、写真で人を認識することをシステムに学習させる場合、さまざまな年齢、さまざまなポーズ、衣服、さまざまな条件の人の写真をたくさん表示する必要があります。 このようなトレーニングの後、システムは写真内の人物を正確に認識することができます。 しかし、別の質問があります。システムの写真が単なるピクセルのコレクションである場合、ニューラルネットワークは写真に正確に描かれているものをどのように理解するのでしょうか。
画像内のオブジェクトを認識するためにさまざまな方法が使用されますが、最も有望な方法の1つは、方向勾配ヒストグラム(HOG)方法です。 画像は変色し、16x16ピクセルブロックでシステムは色の変化の方向(勾配ベクトル)を見つけ、画像全体にこれらのベクトルのマップを構築します。これにより、位置/位置および照明によって変化しないオブジェクトの兆候を「スナップショット」します。 アルゴリズムの改良版はCoHOGと呼ばれます-オブジェクトの境界を考慮します。つまり、勾配ベクトルだけでなく形状を認識します。
東芝はCoHOG方式を改善し、低光での認識を大幅に改善しました。たとえば、従来のCoHOGは、ヘッドライトで歩行者がほとんど見えない暗闇での高速認識が不十分です。 ECoHOGメソッド (方向付けられた勾配の組み合わせのヒストグラムの技術)は、彼の頭、脚、腕、肩を見つけるために、彼の輪郭の方向とサイズの追加分析を通して人を決定します。 CoHOGが画像上の人体測定の輪郭を単純に分離する場合(分析「オブジェクト境界-境界ベクトル」)、ECoHOGの場合、オブジェクト境界の相対的な寸法が重要です。
アプリケーションの5つの主要分野
マーケティング
パターン認識は、広告とマーケティングの有望な分野です。 ニューラルネットワークは数時間で物事を学習することができますが、それ以外の場合は、専門家の大規模なチームと数週間、場合によっては数か月の研究が必要です。 たとえば、ソーシャルメディア監視システムであるロシアのサービスYouScanは、ソーシャルネットワーク上のブランドの言及を追跡します。 さらに、彼はこれを投稿のテキストだけでなく写真でも行い、製品に関する特定の結論を引き出すのにも役立ちます。 パターン認識の助けを借りて、写真の中に興味深いパターンが見つかりました。検索は誰にも起こらなかったでしょう。動物の中で、猫はアップルのテクノロジーで、犬はアディダスのブランドでよく見られます。 この異常な情報は、広告のターゲット設定に役立ちます。
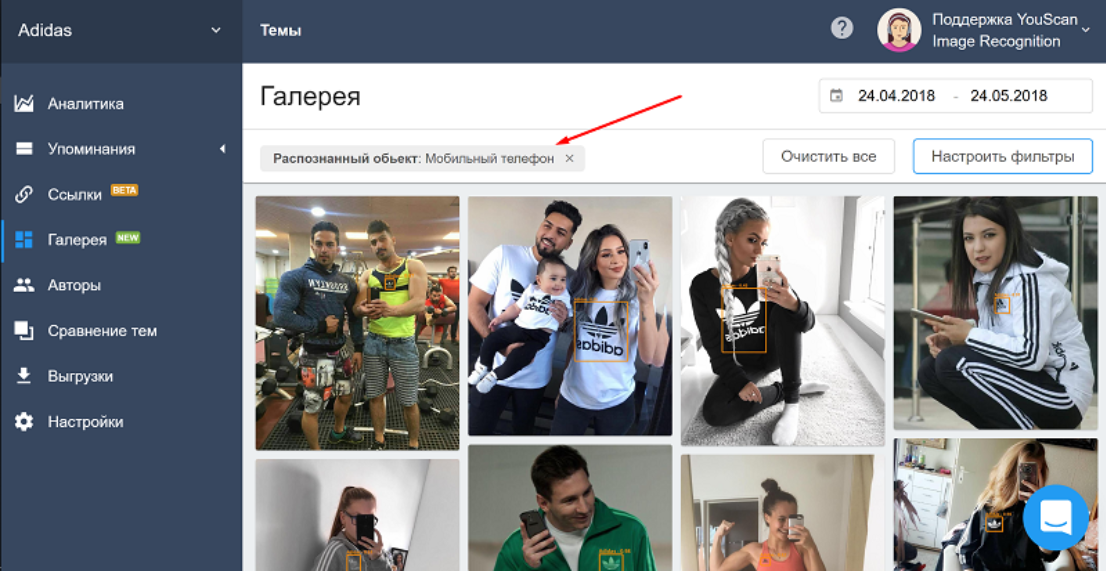
Adidasのロゴを検索する際、YouScanサービスは所有者の手にあるスマートフォンで写真をフィルタリングしました。 著作権:YouScan
ビデオ監視
都市監視カメラでのパターン認識は、おそらくマシンビジョンを使用する最も避けられない可能性です。 2017年以来、混雑した場所にいる犯罪者を特定するために、スマートビデオ監視システムがモスクワでテストされています。 ロシアの企業NTechLabの技術は、すでにカメラの都市ネットワークに接続されており、すでに数十人の犯罪者の拘束に役立っています。 中国では、このようなビデオ監視システムは、顔だけでなく、公共の場で車や衣服のブランドも認識できます。これは、その後マーケターが研究に使用できます。
ビデオは、画像と顔の認識の実際の作業を示していますSenseTime
薬
パターン認識はすでに医学の真のブレークスルーになっています-多くの場合、コンピューターは最も経験豊富な医師でさえ見逃していることに気づきます。 彼らは独特の助手として行動し、その「技術的な」意見は医師の仮説を裏付けるか、より深い研究をもたらします。
ロシアでは、CT、MRI、PET画像の癌性病変を診断するためのソフトウェアシステムの開発が進行中です。 これを行うために、数千のタグ付き画像がニューラルネットワークを介して駆動され、その後、新しい画像の認識精度が95〜97%に向上します。 とりわけ、このようなプラットフォームの開発は、モスクワのIT部門がGoogle TensorFlowオープンライブラリを使用して実施しています。
Googleが作成したインセプションニューラルネットワークは、リンパ節生検の顕微鏡検査を分析して、乳腺のがん細胞を検索します。 人にとっては、これは非常に長くて骨の折れるプロセスであり、その間、画像サイズは100,000 x 100,000ピクセルであるため、間違えたり、重要な何かを見逃したりするのは簡単です。 Inceptionのニューラルネットワークは、医師の72%に対して約92%の感度を提供します。 ニューラルネットワークは、画像のすべての疑わしい部分を見失うことはありませんが、医師が後でフィルタリングする誤ったアラームは許可されます。
車
車のオブジェクト認識は、ADAS(高度なドライバーアシスタンスシステム)セキュリティシステムに必要な部分です。 ADASは、レーダーや赤外線センサーなどの高度なツールを使用して、または単眼カメラを使用して実装できます。 前の記事で、すでに1台のビデオカメラで車が歩行者、標識、信号機をリアルタイムで認識するのに十分であると述べました。 ただし、このような「オンザフライ」での認識は非常にリソースを消費するタスクであり、専用のプロセッサが必要です。 東芝は数年にわたって一連のプロセッサを開発しています。 彼らは、単一のカメラからの動画に基づいて3次元モデルを構築し、それによって道路上の未知の障害物に気付きます。 結局、ニューラルネットワークが人、マーク、標識のみを認識するように訓練されている場合、アスファルトの上に横たわるタイヤやフェンスは認識されず、危険と見なされません。

Viscontiプロセッサは、画像内のゾーンを識別して分類し、自動操縦装置またはADASが決定を下せるようにします。 出典:東芝
ドローン
ドローンでは、エンターテイメントと科学の両方の目的でオブジェクト認識が使用されます。 2015年には、投げるときの自動エンジン始動と所有者追跡機能を備えたリリードローンによって多くのノイズが発生しました。 リリーは、移動の軌跡と速度に関係なく、レンズを所有者に向けました。 確かに、このリリーの機能はパターン認識とは何の関係もありませんでした。ドローンは人の画像だけでなく、所有者の手に置かれたコントロールパネルも見ていました。
画像認識ドローンは、より深刻なことにも使用されます。 たとえば、ノルウェーの会社eSmart Systemsはスマートグリッドソリューションを開発しました。 プロジェクトの1つであるConnected Droneでは、ドローンを使用して電力線のトラブルシューティングを行います。 送電網要素の認識の訓練を受けて、電線、絶縁体、および送電線の他の部分の完全性を検証します。 これは、都市または企業への電力供給が回線に依存している場合、故障を迅速に特定するために特に重要です。 送電線は手の届きにくい場所に設置されることが多いことを考慮すると、ドイガの乗組員を派遣して大河や山のどこかに障害を見つけることは、チームを派遣するよりもはるかに効果的です。

ESmartドローンはエネルギーインフラストラクチャの要素を検出し、損傷した場合はオブジェクトにマークを付けて、オペレーターに警告を残します。 出典:eSmart Systems