Infrastructure as Code: How to Overcome Problems with XP
Hello, Habr! Previously, I complained about life in the Infrastructure as code paradigm and did not propose anything to solve this situation. Today I came back to tell you what approaches and practices will help to break out of the abyss of despair and drive the situation in the right direction.

In the previous article “Infrastructure as code: first acquaintance”, I shared my impression of this area, tried to reflect on the current situation in this area, and even suggested that standard practices known to all developers can help. It might seem that there were many complaints about life, but there were no proposals to get out of this situation.
We are now in the Sre Onboarding Team, which consists of six programmers and three infrastructure engineers. We are all trying to write Infrastructure as code (IaC). We do this because, in principle, we are able to write code and in the history we are developers of the level “above average”.
The conclusion from my last article was this: I tried to inspire optimism (primarily in myself), I wanted to say that we will try the approaches and practices known to us in order to deal with the difficulties and difficulties that exist in this area.
We are now struggling with these IaC issues:
All developers are familiar with extreme programming (XP) and the practices behind it. Many of us worked on this approach, and it was successful. So why not take advantage of the principles and practices laid down there to overcome the difficulties of infrastructure? We decided to apply this approach and see what happens.
Let's look at some practices from XP and how they affect the speed and quality of feedback.
In my understanding, feedback is the answer to the question, am I doing right, are we going there? In XP, there is a divine little scheme in this regard: a time feedback loop. The interesting thing is that the lower we are, the faster we are able to get an OS to answer the necessary questions.
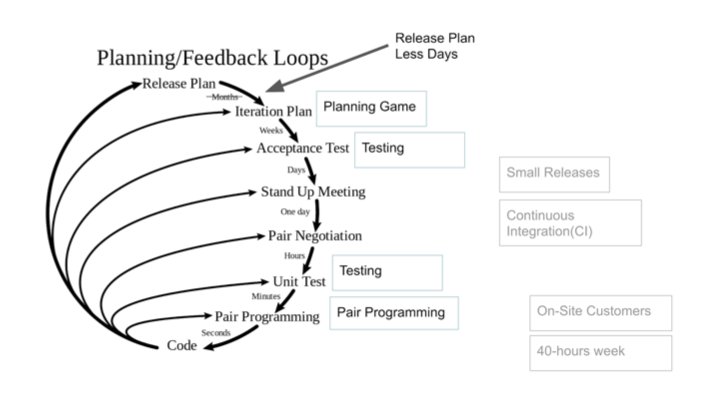
This is a rather interesting topic for discussion that in our IT industry it is possible to quickly get an OS. Imagine howpainful it is to do a project for half a year and only then find out that a mistake was made at the very beginning. This happens in the design, and in any construction of complex systems.
In our case, IaC feedback helps us. Immediately I make a small adjustment to the diagram above: we do not have a monthly release plan, but happen several times a day. Some practices are tied to this OS cycle, which we will consider in more detail.
Tests are mentioned twice in the XP feedback loop. It is not just that. They are extremely important for all extreme programming techniques.
It is assumed that you have Unit and Acceptance tests. Some give you feedback in a few minutes, others in a few days, because they are written longer, and run less often.
There is a classic test pyramid, which shows that there should be more tests.
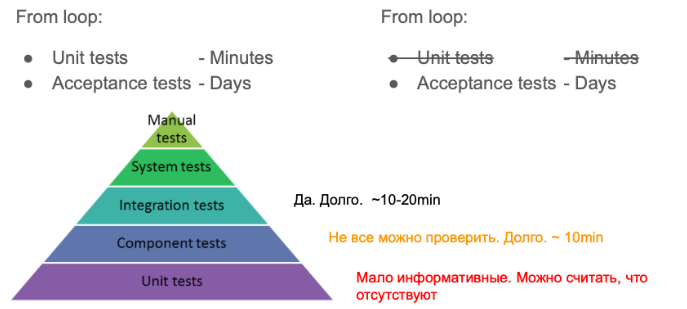
How does this scheme apply to us in an IaC project? Actually ... nothing.
The absence of Unit-tests during the assembly of images or modules of the terraform makes it possible to shift work to separate services that can simply be pulled by REST, or to Python scripts.
For example, we needed to make it so that when the virtual machine started , it registered itself in the ScaleFT service, and when itself destroyed, it deleted itself.
Since ScaleFT is a service, we are forced to work with it through the API. There was written a wrapper that you can pull and say: "Come in and delete this, that." It stores all the necessary settings and accesses.
We can already write normal tests for this, since it does not differ from ordinary software in any way: some apiha gets wet, you pull, and look what happens.
Tests are, of course, good. You can write a lot of them, they can be of different types. They will work at their levels and give us feedback. But the problem with poor Unit tests, which give the fastest OS, remains. At the same time, he continues to want a fast OS, it is easy and pleasant to work with it. Not to mention the quality of the solution. Fortunately, there are techniques to give even faster feedback than unit tests. This is pair programming.
When writing code, I want to get feedback on its quality as quickly as possible. Yes, you can write everything in the feature branch (so as not to break anything to anyone), make a pull request in the github, assign it to someone whose opinion has weight, and wait for an answer.
But you can wait a long time. People are all busy, and the answer, even if it is, may not be the highest in quality. Suppose that the answer came right away, the reviewer instantly understood the whole idea, but the answer still comes belatedly, after the fact. But I want something earlier. Here is pair programming and is aimed at this - so that immediately, at the time of writing.
The following are the pair programming styles and their applicability in working on IaC:
1. Classic, Experienced + experienced, timer change. Two roles - driver and navigator. Two people. They work on one code and change roles after a certain predetermined period of time.
Consider the compatibility of our problems with style:
The main problem with applying this style to IaC at an uneven pace. In traditional software development, you have a very uniform movement. You can spend five minutes and write N. Spend 10 minutes and write 2N, 15 minutes - 3N. Here you can spend five minutes and write N, and then spend another 30 minutes and write a tenth of N. Here you do not know anything, you have a plug, dumbass. The trial takes time and distracts from the programming itself.
I can say that we tried sharing responsibilities for designing a test script and implementing code for it. One participant came up with a script, in this part of the work he was responsible, he had the last word. And the other was responsible for the implementation. It worked out well. The quality of the scenario with this approach increases.
3. Strong Style. Difficult practice . The idea is that one participant becomes a directory navigator, and the second takes on the role of an executing driver. In this case, the right to make decisions exclusively with the navigator. The driver only prints and in a word can affect what is happening. Roles do not change for a long time.
Well suited for training, but requires strong soft skills. On this we faltered. The technique was difficult. And the point here is not even infrastructure.
4. Mobbing, swarming and all the well-known, but not listed here styles are not considered, because did not try and say about it in the context of our work will not work.
We have regular partners for several days (less than a week). We do one task together. For a while we sit together: one writes, the second sits and watches as support team. Then we disagree for a while, everyone does some independent things, then we converge again, synchronize very quickly, do something together and again diverge.
The last block of practices through which OS problems are solved is the organization of work with the tasks themselves. This also includes the exchange of experience, which is outside pair work. Consider three practices:
1. Tasks through the goal tree. We organized the general management of the project through a tree that goes endlessly into the future. Technically, the lead is done at Miro. There is one task - it is an intermediate goal. Either smaller goals or groups of tasks go from it. From them are the tasks themselves. All tasks are created and conducted on this board.
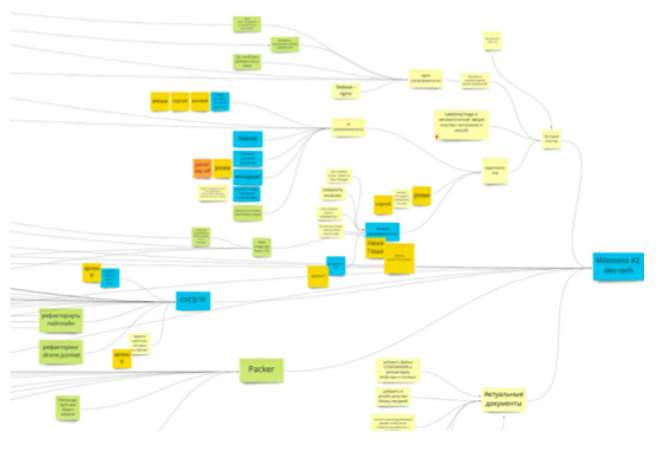
This scheme also gives feedback that occurs once a day when we synchronize at rallies. The presence in front of everyone of a general plan, while structured and completely open, allows everyone to keep abreast of what is happening and how far we have progressed.
Advantages of visual vision of tasks:
2. Changeable presenters of morning rallies. At stand-ups, such a problem turned out - people do many tasks in parallel. Sometimes tasks are loosely coupled and there is no understanding of who is doing what. And the opinion of another team member is very important. This is additional information that can change the course of solving a problem. Of course, usually someone is paired with you, but consultation and tips are always not superfluous.
To improve this situation, we applied the technique of “Changing the leading stand-up”. Now they rotate on a specific list, and this has its effect. When it comes to you, you are forced to plunge and understand what is happening in order to conduct a scrum meeting well.

3. Internal demo. Help in solving a problem from pair programming, visualization on the task tree and help at scrum rallies in the morning is good, but not perfect. In a couple you are limited only by your knowledge. The task tree helps you globally understand who does what. And the host and colleagues at the morning meeting will not plunge deeply into your problems. Certainly they can miss something.
The solution was found in demonstrating the work done to each other and their subsequent discussion. We gather once a week for an hour and show the details of solutions to the tasks that we have done over the past week.
During the demonstration, it is necessary to reveal the details of the task and be sure to demonstrate its work.
After the full-time part, there is always a discussion in the thread. This is where the necessary feedback on our tasks appears.

As a result, a survey is conducted to identify the usefulness of what is happening. This is already feedback on the essence of the speech and the importance of the task.

It may seem that the tone of the article is somewhat pessimistic. This is not true. Two grassroots feedback levels, namely tests and pair programming, work. Not as perfect as in traditional development, but there is a positive effect from this.
Tests, in their current form, provide only partial coverage of the code. Many configuration functions are not tested. Their influence on direct work when writing code is low. However, there is an effect from integration tests, and it is they that make it possible to conduct refactorings without fear. This is a great achievement. Also, with the transfer of focus to development in high-level languages (we have python, go), the problem goes away. But there are a lot of checks on the “glue” and there is no need for a sufficiently general integration.
Work in pairs depends more on specific people. There is a task factor and our soft skills. It turns out very well with someone, worse with someone. There is definitely a benefit from this. It is clear that even with insufficient observance of the rules of pair work, the fact of joint performance of tasks positively affects the quality of the result. Personally, it’s easier and more pleasant for me to work together.
Higher-level methods for influencing the OS - planning and working with tasks precisely produce effects: a high-quality exchange of knowledge and an improvement in the quality of development.
In the previous article “Infrastructure as code: first acquaintance”, I shared my impression of this area, tried to reflect on the current situation in this area, and even suggested that standard practices known to all developers can help. It might seem that there were many complaints about life, but there were no proposals to get out of this situation.
Who we are, where we are and what problems we have
We are now in the Sre Onboarding Team, which consists of six programmers and three infrastructure engineers. We are all trying to write Infrastructure as code (IaC). We do this because, in principle, we are able to write code and in the history we are developers of the level “above average”.
- We have a set of advantages: a certain background, knowledge of practices, the ability to write code, the desire to learn new things.
- And there is a sagging part, it’s also a minus: lack of knowledge on infrastructure materiel.
The technology stack we use in our IaC.
- Terraform to create resources.
- Packer for assembling images. These are Windows CentOS 7 images.
- Jsonnet to do a powerful build in drone.io, as well as to generate packer json and our terraform modules.
- Azure
- Ansible for cooking images.
- Python for support services as well as provisioning scripts.
- And all this in VSCode with plugins shared between team members.
The conclusion from my last article was this: I tried to inspire optimism (primarily in myself), I wanted to say that we will try the approaches and practices known to us in order to deal with the difficulties and difficulties that exist in this area.
We are now struggling with these IaC issues:
- Imperfection of tools, code development tools.
- Slow deployment. Infrastructure is part of the real world, and it can be slow.
- Lack of approaches and practices.
- We are new and don’t know much.
Extreme Programming (XP) to the rescue
All developers are familiar with extreme programming (XP) and the practices behind it. Many of us worked on this approach, and it was successful. So why not take advantage of the principles and practices laid down there to overcome the difficulties of infrastructure? We decided to apply this approach and see what happens.
Checking the applicability of the XP approach to your field
I give a description of the environment for which XP is well suited, and how it relates to us:
1. Dynamically changing software requirements. We understood what the ultimate goal was. But the details can vary. We ourselves decide where we need to steer, so the requirements change periodically (mainly by ourselves). If we take the SRE team, which itself does automation, and itself restricts the requirements and scope of work, then this item goes well.
2. Risks caused by fixed time projects using new technology. We may face risks when using some unknown things. And this is 100% our case. Our entire project is the use of technologies with which we were not completely familiar. In general, this is a constant problem, because in the field of infrastructure, many new technologies are constantly appearing.
3.4. Small, co-located extended development team. The technology you are using allows for automated unit and functional tests. These two points do not quite suit us. Firstly, we are not a team, and secondly, there are nine of us, which can be considered a large team. Although, according to a number of definitions of a “big” team, a lot are 14+ people.
1. Dynamically changing software requirements. We understood what the ultimate goal was. But the details can vary. We ourselves decide where we need to steer, so the requirements change periodically (mainly by ourselves). If we take the SRE team, which itself does automation, and itself restricts the requirements and scope of work, then this item goes well.
2. Risks caused by fixed time projects using new technology. We may face risks when using some unknown things. And this is 100% our case. Our entire project is the use of technologies with which we were not completely familiar. In general, this is a constant problem, because in the field of infrastructure, many new technologies are constantly appearing.
3.4. Small, co-located extended development team. The technology you are using allows for automated unit and functional tests. These two points do not quite suit us. Firstly, we are not a team, and secondly, there are nine of us, which can be considered a large team. Although, according to a number of definitions of a “big” team, a lot are 14+ people.
Let's look at some practices from XP and how they affect the speed and quality of feedback.
XP feedback loop principle
In my understanding, feedback is the answer to the question, am I doing right, are we going there? In XP, there is a divine little scheme in this regard: a time feedback loop. The interesting thing is that the lower we are, the faster we are able to get an OS to answer the necessary questions.
This is a rather interesting topic for discussion that in our IT industry it is possible to quickly get an OS. Imagine how
In our case, IaC feedback helps us. Immediately I make a small adjustment to the diagram above: we do not have a monthly release plan, but happen several times a day. Some practices are tied to this OS cycle, which we will consider in more detail.
Important: feedback can be the solution to all the problems stated above. Together with XP practices, it can pull despair out of the abyss.
How to get yourself out of the abyss of despair: three practices
Tests
Tests are mentioned twice in the XP feedback loop. It is not just that. They are extremely important for all extreme programming techniques.
It is assumed that you have Unit and Acceptance tests. Some give you feedback in a few minutes, others in a few days, because they are written longer, and run less often.
There is a classic test pyramid, which shows that there should be more tests.
How does this scheme apply to us in an IaC project? Actually ... nothing.
- Unit tests, in spite of the fact that there should be a lot of them, cannot be very many. Or they are very indirectly testing something. In fact, we can say that we do not write them at all. But here are a few applications for such tests, which we still managed to do:
- Testing code on jsonnet. This, for example, is our pipeline assembly in drone, which is quite complicated. The jsonnet code is well covered by tests.
We use this Unit testing framework for Jsonnet . - Tests for scripts that are executed when the resource starts. Scripts in Python, which means you can write tests for them.
- Testing code on jsonnet. This, for example, is our pipeline assembly in drone, which is quite complicated. The jsonnet code is well covered by tests.
- Checking the configuration in tests is potentially possible, but we do not. It is also possible to configure the verification of resource configuration rules through tflint . However, just for terraform there are too basic checks, but many test scripts are written for AWS. And we are on Azure, so this is not suitable again.
- Component integration tests: it depends on how you classify them and where you put them. But they basically work.
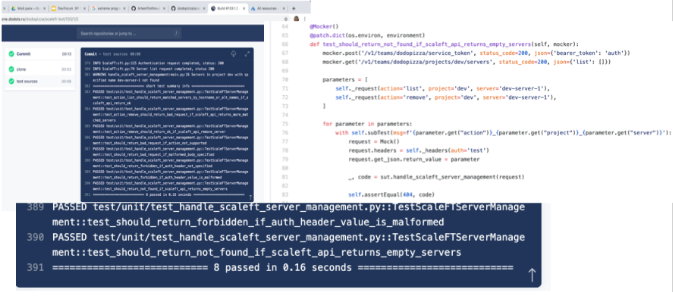
This is what integration tests look like.
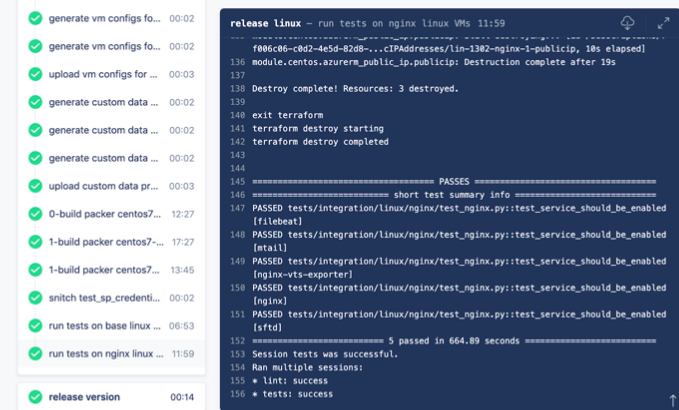
This is an example when assembling images in Drone CI. To reach them, you need to wait 30 minutes until the Packer image is assembled, then wait another 15 minutes until they pass. But they are!
Image Validation Algorithm- First, Packer must prepare the image completely.
- Next to the test there is a terraform with a local state, with which we deploy this image.
- When deploying, a small module is used lying next to it, so that it is easier to work with the image.
- When the VM is deployed from the image, you can start checking. Mostly checks are carried out by car. It checks how scripts worked at startup, how daemons work. To do this, through ssh or winrm, we go to the machine that has just been raised and check the configuration status or whether the services have risen.
- A similar situation with integration tests and in modules for terraform. Here is a brief table explaining the features of such tests.
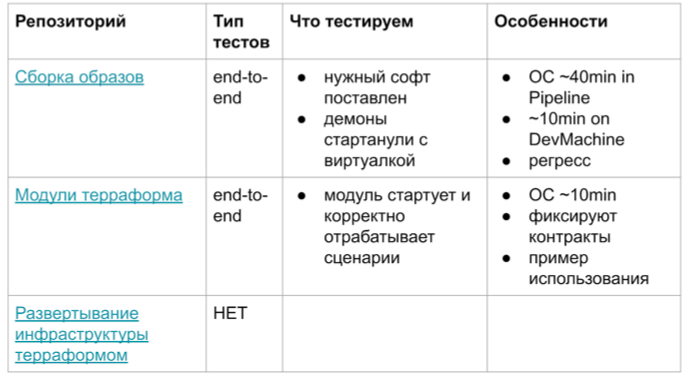
Pipeline feedback in the area of 40 minutes. Everything takes a very long time. It can be used for regression, but for a new development it is generally unrealistic. If you are very, very prepared for this, prepare running scripts, you can reduce it to 10 minutes. But this is still not Unit tests, which are 100 pieces in 5 seconds.
The absence of Unit-tests during the assembly of images or modules of the terraform makes it possible to shift work to separate services that can simply be pulled by REST, or to Python scripts.
For example, we needed to make it so that when the virtual machine started , it registered itself in the ScaleFT service, and when itself destroyed, it deleted itself.
Since ScaleFT is a service, we are forced to work with it through the API. There was written a wrapper that you can pull and say: "Come in and delete this, that." It stores all the necessary settings and accesses.
We can already write normal tests for this, since it does not differ from ordinary software in any way: some apiha gets wet, you pull, and look what happens.
Test results: Unit testing, which should give the OS in a minute, does not give it. And higher types of testing on the pyramid give an effect, but only a part of the problems are covered.
Pair programming
Tests are, of course, good. You can write a lot of them, they can be of different types. They will work at their levels and give us feedback. But the problem with poor Unit tests, which give the fastest OS, remains. At the same time, he continues to want a fast OS, it is easy and pleasant to work with it. Not to mention the quality of the solution. Fortunately, there are techniques to give even faster feedback than unit tests. This is pair programming.
When writing code, I want to get feedback on its quality as quickly as possible. Yes, you can write everything in the feature branch (so as not to break anything to anyone), make a pull request in the github, assign it to someone whose opinion has weight, and wait for an answer.
But you can wait a long time. People are all busy, and the answer, even if it is, may not be the highest in quality. Suppose that the answer came right away, the reviewer instantly understood the whole idea, but the answer still comes belatedly, after the fact. But I want something earlier. Here is pair programming and is aimed at this - so that immediately, at the time of writing.
The following are the pair programming styles and their applicability in working on IaC:
1. Classic, Experienced + experienced, timer change. Two roles - driver and navigator. Two people. They work on one code and change roles after a certain predetermined period of time.
Consider the compatibility of our problems with style:
- Problem: imperfection of tools, tools for code development.
Negative influence: to develop longer, we slow down, the pace / rhythm of work goes astray.
How to fight: we use another tuling, a common IDE and still learn shortcuts. - Problem: Slow Deployment.
Negative impact: increases the time to create a working piece of code. We miss while waiting, hands are drawn to do something else while you wait.
How to fight: did not overcome. - Problem: lack of approaches and practices.
Negative impact: there is no knowledge of how to do good, but how bad. Extends feedback.
How to fight: the exchange of opinions and practices in pairing almost solves the problem.
The main problem with applying this style to IaC at an uneven pace. In traditional software development, you have a very uniform movement. You can spend five minutes and write N. Spend 10 minutes and write 2N, 15 minutes - 3N. Here you can spend five minutes and write N, and then spend another 30 minutes and write a tenth of N. Here you do not know anything, you have a plug, dumbass. The trial takes time and distracts from the programming itself.
Conclusion: in its pure form does not suit us.2. Ping-pong. This approach assumes that one participant is writing a test and the other is doing an implementation for him. Given that everything is complicated with Unit tests, and you have to write a long integration test, the whole ping-pong ease goes away.
I can say that we tried sharing responsibilities for designing a test script and implementing code for it. One participant came up with a script, in this part of the work he was responsible, he had the last word. And the other was responsible for the implementation. It worked out well. The quality of the scenario with this approach increases.
Conclusion: alas, the pace of work does not allow the use of ping-pong, as the practice of pair programming in IaC.
3. Strong Style. Difficult practice . The idea is that one participant becomes a directory navigator, and the second takes on the role of an executing driver. In this case, the right to make decisions exclusively with the navigator. The driver only prints and in a word can affect what is happening. Roles do not change for a long time.
Well suited for training, but requires strong soft skills. On this we faltered. The technique was difficult. And the point here is not even infrastructure.
Conclusion: potentially it can be applied, we do not give up attempts.
4. Mobbing, swarming and all the well-known, but not listed here styles are not considered, because did not try and say about it in the context of our work will not work.
General results on the use of pair programming:5. Despite this, there have been successes. We came up with our own method of convergence - divergence. I will briefly describe how it works.
- We have an uneven pace of work, which knocks down.
- We ran into insufficiently good soft skills. And the subject area does not contribute to overcoming these of our shortcomings.
- Long tests, problems with tools make pair development viscous.
We have regular partners for several days (less than a week). We do one task together. For a while we sit together: one writes, the second sits and watches as support team. Then we disagree for a while, everyone does some independent things, then we converge again, synchronize very quickly, do something together and again diverge.
Planning and communication
The last block of practices through which OS problems are solved is the organization of work with the tasks themselves. This also includes the exchange of experience, which is outside pair work. Consider three practices:
1. Tasks through the goal tree. We organized the general management of the project through a tree that goes endlessly into the future. Technically, the lead is done at Miro. There is one task - it is an intermediate goal. Either smaller goals or groups of tasks go from it. From them are the tasks themselves. All tasks are created and conducted on this board.
This scheme also gives feedback that occurs once a day when we synchronize at rallies. The presence in front of everyone of a general plan, while structured and completely open, allows everyone to keep abreast of what is happening and how far we have progressed.
Advantages of visual vision of tasks:
- Causality. Each task leads to some kind of global goal. Tasks are grouped into smaller goals. The infrastructure domain itself is pretty technical. It is not always immediately clear what specific impact on the business is exerted, for example, by writing a rankbook on migration to another nginx. The presence of a nearby target card makes this more clear.
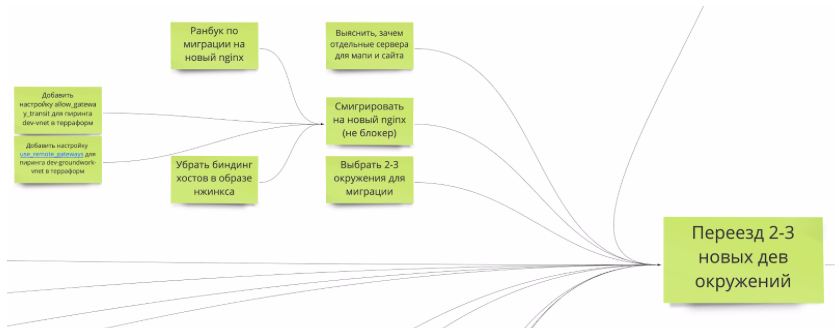
Causality is an important property of tasks. It directly answers the question: "Am I doing it?" - Parallelism. There are nine of us, and it’s impossible to attack everyone with one task simply physically. Tasks from one area also may not always be enough. We are compelled to parallel work between small working groups. At the same time, the groups sit on their task for some time, they can be strengthened by someone else. People sometimes fall off this working group. Someone goes on vacation, someone makes a report for the DevOps conf conference, someone writes an article on Habr. Knowing what goals and objectives can be done in parallel becomes very important.
2. Changeable presenters of morning rallies. At stand-ups, such a problem turned out - people do many tasks in parallel. Sometimes tasks are loosely coupled and there is no understanding of who is doing what. And the opinion of another team member is very important. This is additional information that can change the course of solving a problem. Of course, usually someone is paired with you, but consultation and tips are always not superfluous.
To improve this situation, we applied the technique of “Changing the leading stand-up”. Now they rotate on a specific list, and this has its effect. When it comes to you, you are forced to plunge and understand what is happening in order to conduct a scrum meeting well.
3. Internal demo. Help in solving a problem from pair programming, visualization on the task tree and help at scrum rallies in the morning is good, but not perfect. In a couple you are limited only by your knowledge. The task tree helps you globally understand who does what. And the host and colleagues at the morning meeting will not plunge deeply into your problems. Certainly they can miss something.
The solution was found in demonstrating the work done to each other and their subsequent discussion. We gather once a week for an hour and show the details of solutions to the tasks that we have done over the past week.
During the demonstration, it is necessary to reveal the details of the task and be sure to demonstrate its work.
The report can be kept on the checklist.
1. Enter in the context. Where did the task come from, why was it needed at all?
2. How was the problem solved before? For example, massive mouse clicks were required, or it was generally impossible to do anything.
3. How we improve it. For example: "Look, now there is a script player, here is a readme."
4. Show how it works. It is advisable to directly implement any user script. I want X, do Y, see Y (or Z). For example, deploy NGINX, smoke url, I get 200 OK. If the action is long, prepare in advance to show later. It is advisable not to break apart if fragile an hour before the demo.
5. Explain how well the problem was solved, what difficulties remained, what was not completed, what improvements are possible in the future. For example, now cli, then there will be full automation in CI.
It is advisable for each speaker to keep within 5-10 minutes. If your performance is obviously important and takes more time, coordinate it in the sre-takeover channel in advance.
2. How was the problem solved before? For example, massive mouse clicks were required, or it was generally impossible to do anything.
3. How we improve it. For example: "Look, now there is a script player, here is a readme."
4. Show how it works. It is advisable to directly implement any user script. I want X, do Y, see Y (or Z). For example, deploy NGINX, smoke url, I get 200 OK. If the action is long, prepare in advance to show later. It is advisable not to break apart if fragile an hour before the demo.
5. Explain how well the problem was solved, what difficulties remained, what was not completed, what improvements are possible in the future. For example, now cli, then there will be full automation in CI.
It is advisable for each speaker to keep within 5-10 minutes. If your performance is obviously important and takes more time, coordinate it in the sre-takeover channel in advance.
After the full-time part, there is always a discussion in the thread. This is where the necessary feedback on our tasks appears.
As a result, a survey is conducted to identify the usefulness of what is happening. This is already feedback on the essence of the speech and the importance of the task.
Long conclusions and what's next
It may seem that the tone of the article is somewhat pessimistic. This is not true. Two grassroots feedback levels, namely tests and pair programming, work. Not as perfect as in traditional development, but there is a positive effect from this.
Tests, in their current form, provide only partial coverage of the code. Many configuration functions are not tested. Their influence on direct work when writing code is low. However, there is an effect from integration tests, and it is they that make it possible to conduct refactorings without fear. This is a great achievement. Also, with the transfer of focus to development in high-level languages (we have python, go), the problem goes away. But there are a lot of checks on the “glue” and there is no need for a sufficiently general integration.
Work in pairs depends more on specific people. There is a task factor and our soft skills. It turns out very well with someone, worse with someone. There is definitely a benefit from this. It is clear that even with insufficient observance of the rules of pair work, the fact of joint performance of tasks positively affects the quality of the result. Personally, it’s easier and more pleasant for me to work together.
Higher-level methods for influencing the OS - planning and working with tasks precisely produce effects: a high-quality exchange of knowledge and an improvement in the quality of development.
Short conclusions in one line
- XP practices work in the IaC, but with less efficiency.
- Strengthen what works.
- Design your own compensatory mechanisms and practices.
All Articles