Sizing Elasticsearch
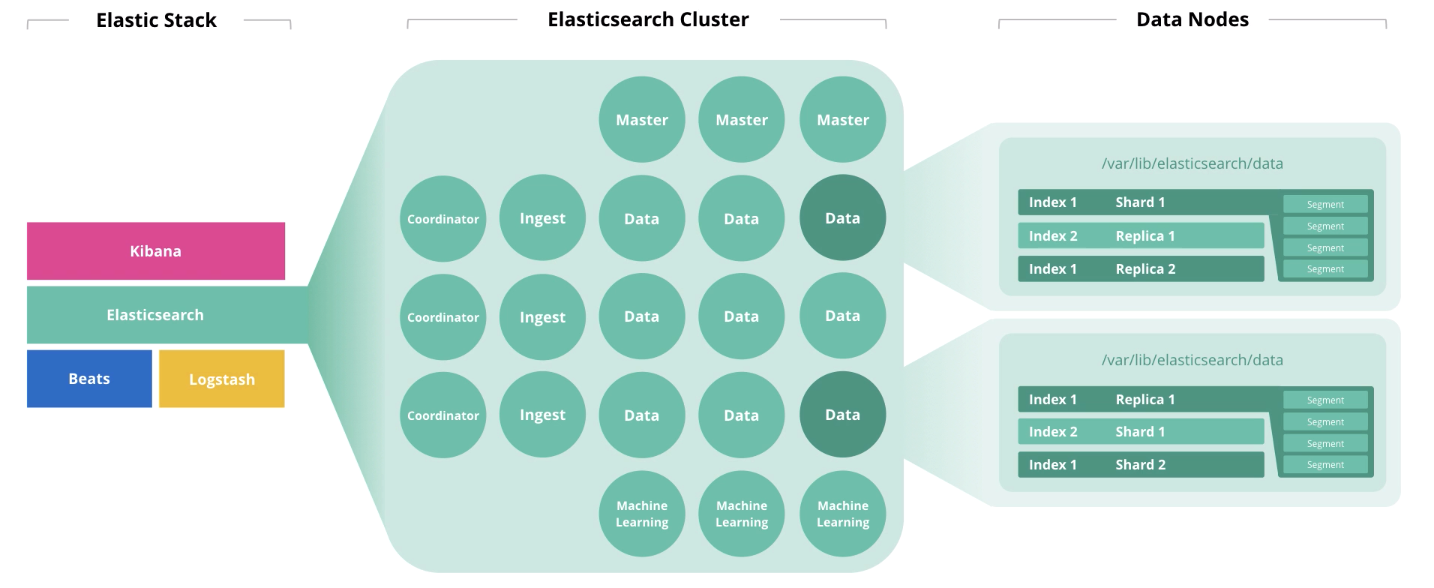
- How big a cluster do I need?
- Well, it depends ... (angry giggle)
Elasticsearch is the heart of the Elastic Stack, in which all the magic with documents takes place: issuing, receiving, processing and storage. The performance depends on the correct number of nodes and the architecture of the solution. And the price, by the way, too, if your subscription is Gold or Platinum.
The main characteristics of the hardware are disk (storage), memory (memory), processors (compute) and network (network). Each of these components is responsible for the action that Elasticsearch performs on documents, which, respectively, are storage, reading, computing and receiving / transmitting. Let's talk about the general principles of sizing and reveal the very “it depends”. And at the end of the article are links to webinars and related articles. Go!
This article is based on David Moore’s webinar, Sizing and Capacity Planning . We supplemented his reasoning with links and comments to make it a little clearer. At the end of the article, a bonus track is links to Elastic materials for those who want to better immerse themselves in the topic. If you have good experience with Elasticsearch, please share in the comments how to design a cluster. We and all colleagues would be interested to know your opinion.
Elasticsearch Architecture and Operations
At the beginning of the article, we talked about 4 components that form the hardware: disk, memory, processors, and network. The role of a node affects the disposal of each of these components. One node can perform several roles at once, but with the growth of the cluster, these roles must be distributed across different nodes.
Master nodes monitor the health of the cluster as a whole. In the work of the master node, a quorum must be observed, i.e. their number should be odd (maybe 1, but better 3).
Data nodes perform storage functions. To increase cluster performance, nodes must be divided into “hot”, “hot”, and “cold” (frozen) . The first are for online access, the second for storage, and the third for archive. Accordingly, for "hot" it is reasonable to use local SSD-drives, and for "warm" and "cold" HDD array is suitable locally or in SAN.
To determine the storage capacity of nodes for storage, Elastic recommends using the following logic: “hot” → 1:30 (30GB of disk space per gigabyte of memory), “warm” → 1: 100, “cold” → 1: 500). Under the JVM Heap, no more than 50% of the total memory capacity and no more than 30GB to avoid garbage collector raid. The remaining memory will be used as the cache of the operating system.
Elastisearch instance performance indicators such as thread pools and thread queues are more affected by processor core utilization . The former are formed on the basis of the actions that the node performs: search, analyze, write, and others. The second is a queue of corresponding requests of various types. The number of Elasticsearch processors available for use is determined automatically, but you can specify this value manually in the settings (it can be useful when you have 2 or more Elasticsearch instances running on the same host). The maximum number of thread pools and thread queues of each type can be set in the settings. The thread pools metric is the primary performance indicator for Elasticsearch.
Ingest nodes take input from collectors (Logstash, Beats, etc.), perform conversions on them, and write to the target index.
Machine learning nodes are intended for data analysis. As we wrote in the article on machine learning in Elastic Stack , the mechanism is written in C ++ and works outside the JVM, in which Elasticsearch itself is spinning, so it is reasonable to perform such analytics on a separate node.
Coordinator nodes accept a search request and route it. The presence of this type of node speeds up the processing of search queries.
If we consider the load on the nodes in terms of infrastructure capacities, the distribution will be something like this:
| But yes | Disk | Memory | CPU | Network |
| Master | ↓ | ↓ | ↓ | ↓ |
| Data | ↑↑ | ↑ | ↑ | → |
| Ingest | ↓ | → | ↑ | → |
| Machine learning | ↓ | ↑↑ | ↑↑ | → |
| Coordinator | ↓ | → | → | → |
| ↑↑ - very high, ↑ - high, → - medium, ↓ - low | ||||
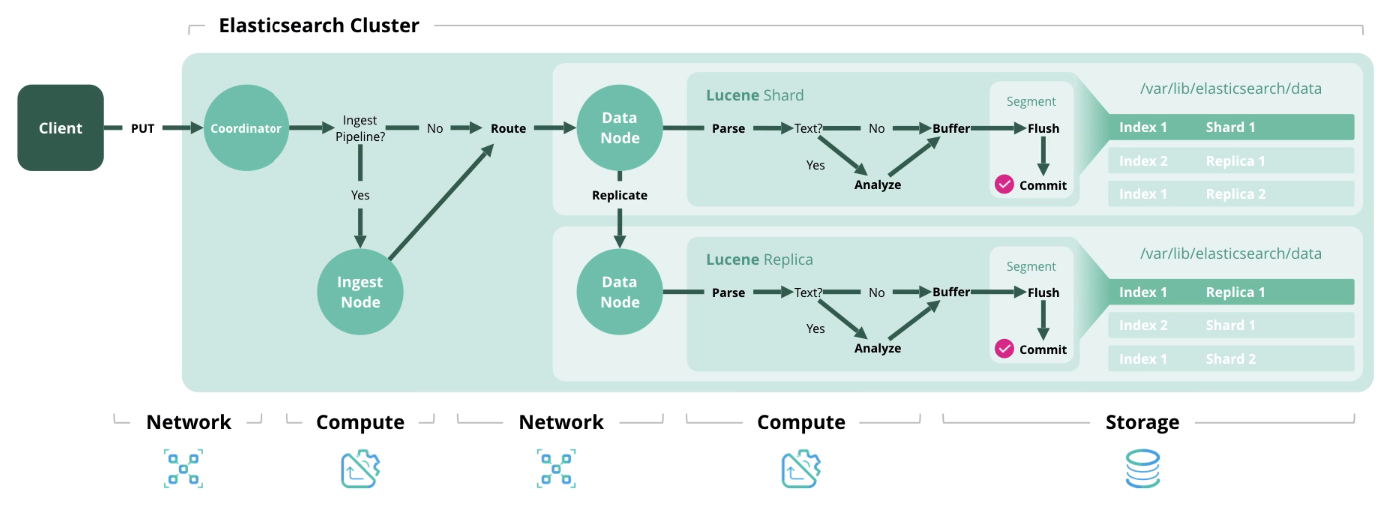
Next, we present 4 main types of operations in Elasticsearch, each of which requires a certain type of resource.
Index - processing and saving a document in the index. The diagram below shows the resources used at each stage.
Delete - delete a document from the index.
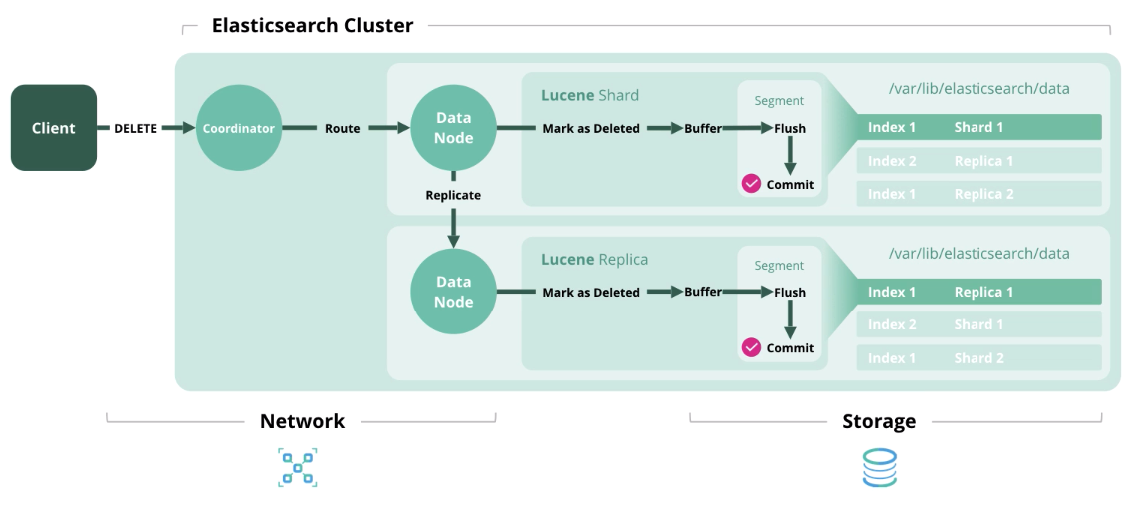
Update - Works like Index and Delete, because documents in Elasticsearch are immutable.
Search - getting one or more documents or their aggregation from one or more indexes.
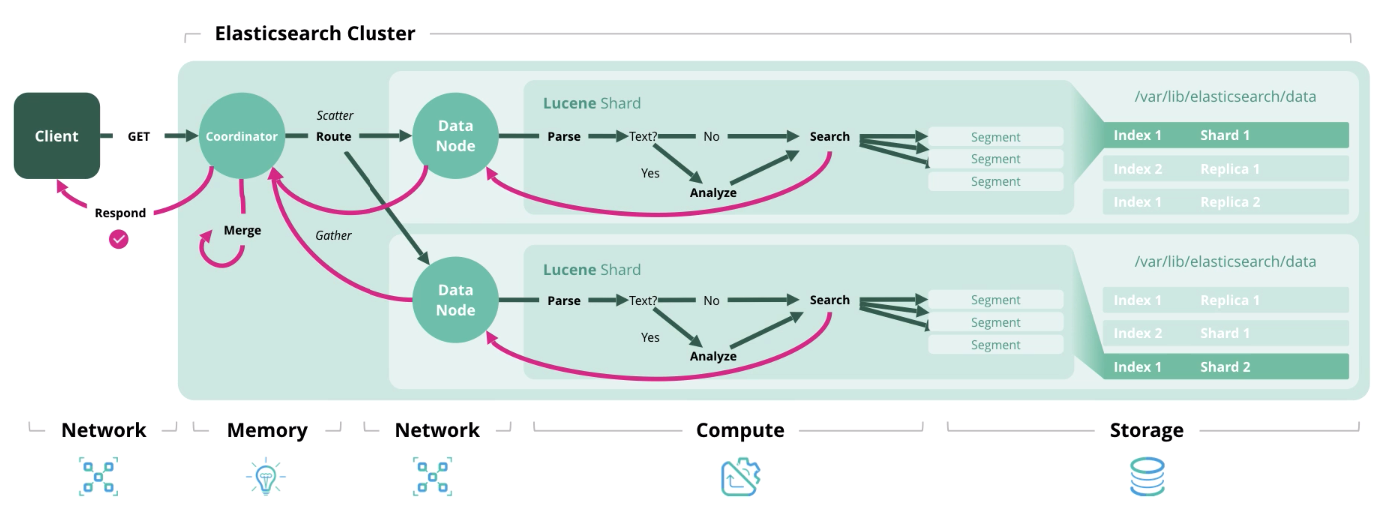
We figured out the architecture and types of loads, now let's move on to the formation of a sizing model.
Sizing Elasticsearch and questions before its formation
Elastic recommends using two sizing strategies: storage-oriented and throughput. In the first case, disk resources and memory are of paramount importance, and in the second case, memory, processor power and network.
Elasticsearch architecture sizing based on storage size
Before the calculations, we obtain the initial data. Need to:
- The amount of raw data per day;
- Period of data storage in days;
- Data Transformation Factor (json factor + indexing factor + compression factor);
- Number of shard replication;
- The amount of memory data nodes;
- The ratio of memory to data (1:30, 1: 100, etc.).
Unfortunately, the data transformation factor is calculated only empirically and depends on different things: the format of raw data, the number of fields in documents, etc. To find out, you need to load a portion of test data into the index. On the topic of such tests, there is an interesting video from the conference and a discussion in the Elastic community . In general, you can leave it equal to 1.
By default, Elasticsearch compresses data using the LZ4 algorithm, but there is also DEFLATE, which presses 15% more. In general, compression of 20-30% can be achieved, but this is also calculated empirically. When switching to the DEFLATE algorithm, the load on computing power increases.
There are additional recommendations:
- Deposit 15% to have a reserve on disk space;
- Pledge 5% for additional needs;
- Lay down 1 equivalent of a data node to ensure fast migration.
Now let's move on to the formulas. There is nothing complicated here, and, we think, it will be interesting for you to check your cluster for compliance with these recommendations.
Total amount of data (GB) = Raw data per day * Number of days of storage * Data transformation factor * (number of replicas - 1)
Total data storage (GB) = Total data (GB) * (1 + 0.15 stock + 0.05 additional needs)
Total number of nodes = OK (Total data storage (GB) / Volume of memory per node / ratio of memory to data + 1 equivalent of data node)
Elasticsearch architecture sizing to determine the number of shards and data nodes depending on the storage size
Before the calculations, we obtain the initial data. Need to:
- The number of index patterns you will create;
- The number of core shards and replicas;
- After how many days index rotation will be performed, if at all;
- The number of days to store the indices;
- The amount of memory for each node.
There are additional recommendations:
- Do not exceed 20 shards per 1 GB JVM Heap on each node;
- Do not exceed 40 GB of shard disk space.
The formulas are as follows:
Number of shards = Number of index patterns * Number of main shards * (Number of replicated shards + 1) * Number of days of storage
The number of data nodes = OK (The number of shards / (20 * Memory for each node))
Elasticsearch bandwidth sizing
The most common case when high bandwidth is needed is frequent and in large numbers search queries.
Necessary initial data for calculation:
- Peak searches per second;
- Average allowable response time in milliseconds;
- The number of cores and threads per processor core on data nodes.
Peak value of threads = OK (peak number of search queries per second * average amount of time to respond to a search query in milliseconds / 1000 milliseconds)
Volume thread pool = OKRUP ((number of physical cores per node * number of threads per core * 3/2) +1)
Number of data nodes = OK (Peak thread value / Thread pool volume)
Perhaps not all the initial data will be in your hands when designing the architecture, but after watching a webinar or reading this article, an understanding will appear that in principle affects the amount of hardware resources.
Please note that it is not necessary to adhere to the given architecture (for example, create coord coord nodes and handler nodes). It is enough to know that such a reference architecture exists and it can give a performance boost that you could not achieve by other means.
In one of the following articles, we will publish a complete list of questions that need to be answered to determine cluster size.
To contact us, you can use personal messages on Habré or the feedback form on the site .
Additional materials
Webinar "Elasticsearch sizing and capacity planning"
Capacity Planning Webinar Elasticsearch
Speech at ElasticON with the theme “Quantitative Cluster Sizing”
Webinar about Rally utility for determining cluster performance indicators
Elasticsearch Sizing Article
Elastic stack webinar
All Articles