Identify cross-community on Instagram to identify user interests
How much can a profile on a social network tell about a person? Photos, posts, comments, subscriptions - an untouched field for analysis. Today we’ll talk about how we determine the interests of users based on their Instagram subscriptions.

Source
The obvious approach is to categorize a person’s subscriptions. For example, among the subscriptions of user Ivan we found two autobloggers and three accounts with funny pictures, the remaining profiles are not thematic (we assume that these are friends, relatives, colleagues, etc.). From this we conclude: Ivan is a cheerful person, fond of cars. Profit All we need is a “blogger + content theme” match, but it’s not so simple here.
Who is a blogger? A blogger on Instagram is no different from a regular account (and in general, it is something like a state of mind). Ideally, we are interested in thematic accounts with a large share of a live audience, while we would not want to simply cut off the number of subscribers, we might miss something.
Where to get a good taxonomy? If you come up with the categories yourself, then something interesting is sure to get lost in “different things”, and when everything is ready, it turns out that the categories are too broad. We want to get a natural partition, and therefore we will cluster bloggers.
Can one blogger belong to several categories? And how! Very often, he is simultaneously a Swiss, a reaper, and a dude playing dude (as well as travel, life style, wife and mother).
So, we need a dataset with a very large number of bloggers and a clustering algorithm with intersecting clusters at the output.
We are approached by customers who want to place their ads on opinion leaders on Instagram most effectively. Sometimes there is a list of bloggers, and then we solve the optimization problem - to reach more people for less money, and sometimes there is no list and relevant bloggers need to be found. This time they searched for profiles of ophthalmologists.
We used an approach similar to a recommendation system:
Now, more on the example.
Step 1. Using an Instagram search, we selected 6 accounts of ophthalmologists from different regions of Russia:

The list is quite random, but it was enough for us that the blog really matches the topic and subscribers are no less than 1000 people.
Step 2. After crossing all the subscribers, we look at the distribution.
Hurrah! There are intersections.
Moreover, there are two people who are subscribed to all six profiles! So, now you need to determine who we consider “enthusiastic” ophthalmology. We decided that we take everyone, starting with three subscriptions. As they say, 1 time is an accident, 2 times is a coincidence, 3 is a regularity. Thus, 131 (2 + 3 + 24 + 102) “enthusiastic” users were found.
Step 3. Download the subscriptions of “enthusiastic” people and again aggregate in every possible way.

We got an impressive list of accounts, from which we will now select new ophthalmologists. The right column shows how many of the 131 people who were selected in the second step are subscribed to the profile. In the top were profiles from our original six, which is not surprising. If we now select a threshold and say: “All profiles with a count value of more than ten are new doctors”, then we risk attributing popular accounts like Olga Buzova to ophthalmologists and at the same time lose small, but relevant profiles, so add one more column the number of subscribers and calculate the percentage of enthusiastic users among subscribers.

For convenience, the fraction is multiplied by 100 (so share is the percentage in fact). As a result, with the condition count> = 6 and share> = 0.05, 166 new ophthalmologists received. Class!
Step 4. 172 accounts became the new “core” of the community, this helped to find about 500 more new ophthalmologists, but the result was already shifted to foreign accounts.
This is all interesting, of course, and now we know how to find accounts that are similar to each other, but we still want to get a breakdown of all installers into categories. And then the idea came to my mind to look at the ready-made instagram recommendations.

The fact is that thematic accounts have recommendations, but ordinary people do not. Here's the answer to the question of who to consider bloggers and minus one headache. Hurrah!
In the recommendations, one blogger has up to 80 similar profiles. We had a list of 1000 Russian blogs, we started with it. They took similar ones, then similar ones, then ... well, you understand :)
The plan was that someday this process will end, since small profiles with a couple of hundreds of subscribers will not be included in the recommendations, but in fact we stopped when the patience ended. You can always continue to collect the dataset, but so far it has not come in handy, with a high probability we have covered almost all Russian bloggers, and okay.
Now we have a graph with 3,428,453 vertices (bloggers) and 96,967,974 edges (similarity of the two bloggers to each other).

This is how our graph looks on a very small sample
By the way, it turned out that we were not the first to choose this approach.
Apparently, the recommendations on Instagram are formed based on who the followers of this profile are still following, so the doctor from Bryansk will have popular Bryansk accounts and other doctors in the recommendations. This is similar to our search for ophthalmologists, but now we can take into account all the communities to which the blogger belongs at the same time. Plus, the processing speed increases significantly, because there is no need to analyze all the blogger’s subscribers, it’s enough to take only 80 recommended accounts.
Fine! The data has been prepared, now we need to choose a tool and an algorithm that can cope with such a large graph, preferably in an adequate time. Let me remind you that at the output we want to get a set of communities where one blogger can belong to several of them.
We opted for the Stanford Network Analysis Platform (SNAP) library
The main and rather intuitive thought: the more two nodes have common communities, the greater the likelihood of communication between these two nodes. Both algorithms are based on the Affilated Graph Model, so let's dwell on it in more detail:
Suppose we have a bipartite graph in which round peaks are communities ( and ), and square - users of the social network, and each person ( ) refers to different communities with specific weights ( and ) The more weight, the greater the likelihood that the participant is connected (familiar) with other members of the community.
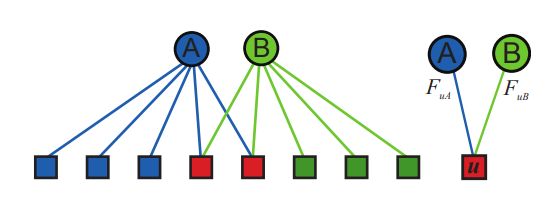
Example: colleagues who studied at the same university follow each other on Instagram. Both of them are graduates of the same university (community 1) and work in the same company (community 2), we do not know what caused the “friendship” on the network and when they met. Let one just graduate from university and get a job, and the second graduates five years ago and has been working in the company all this time, then the weight of belonging to the first community 1 will be more, and community 2 less and vice versa.
For each common community of a couple of people, we get an independent chance to be familiar:
Thus, the more common the communities are, the more likely they are to know each other:
If we calculate the likelihood of a connection between each pair of users, then at the output we get a graph where the vertices are people and the edges between them are a fact of acquaintance or subscription to each other.
Thus, from the view on the left, we moved on to the picture on the right.

Now let's understand how this model is used in community discovery.
We have a graph of similar bloggers and our goal is to discover communities using the model described above, by selecting the most appropriate weight matrix (its dimension nodes on communities) so that the graph obtained at the output is similar to our original one. This is done by maximizing the likelihood function.
And yet this whole thing can be represented as a non-negative matrix decomposition, which just gives a plus in the scalability of the BIGCLAM algorithm compared to AGMfit.
Read more here and here .
In BIGCLAM, you can specify both the exact number of communities and the interval. The algorithm selects 20% of the pairs of nodes for the test, and 80% is the fit of the model with a different number of communities.
We formed an input file with a list of edges and run:
The parameters allow you to specify the number of attempts, the minimum and maximum number of communities (or exact, if necessary), the number of threads for parallelization and the prefix of the output files. In our case, we set the interval from 50 to 200 thousand communities with 20 attempts on 10 threads. All this splendor was counted five days on 2 Intel® Xeon® Gold 6150 CPU @ 2.70GHz. The output received two files, one for Gephi, the second text, in which each line is a community.
In fact, we ran the algorithm twice and for the first time we ran into the upper limit of 50 thousand communities, the result was not bad, but mixed communities often came across. This time we again reached the maximum value of 200 thousand communities, but they were much better, and we stopped at that. You could probably get the result even better, but two hundred thousand unnamed communities scared our imagination.

Nice picture
What now to do with all this?
On the one hand, the resulting communities help us quickly search for narrow groups of bloggers (as with ophthalmologists then). If there is a couple of bloggers as an example, then we take all the communities into which they belong, discard unnecessary ones and that’s it. You can use a search by name, for example, one of the communities about decor and interior design:

On the other hand, in order to determine the interests of users, all these communities must be somehow meaningfully called. Or maybe all is not necessary.
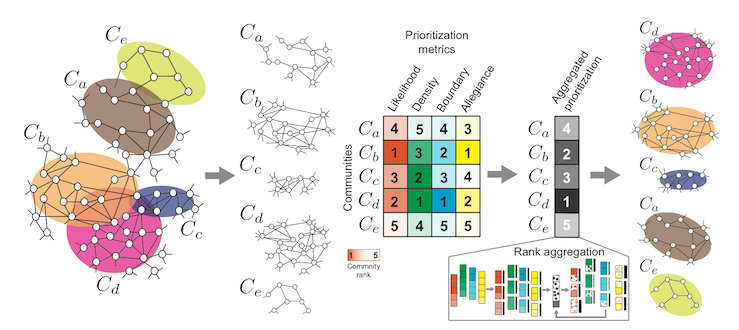
Unfortunately, not all the communities received are equally good, and to find the most interesting ones, we decided to try using the CRank prioritization method from the same SNAP library. It is called automatically based on the structure of the graph to match each community rank: the greater the value, the better the community.
At the input of the program, we submit the communities we found earlier, for each of them, prioritization metrics (4 pieces) are calculated, then these metrics are aggregated, and we get an estimate.
Read more here .
Launch
During the launch, they encountered a compatibility problem with Ubuntu 18.04, they offer a solution here .
Since our bloggers_cmtyvv.txt community file and the query_graph_all.edgelist list of edges initially contained nicknames (of type string), we had to hash them so that it was int, otherwise crank swears.
Let's see how this works with an example:
We’ll select several communities where there are profiles that contain the string “lokomotiv” in the name, as planned, this should be the community of football fans of the Lokomotiv club, and let's see what it really is. Members of the community are marked in red, under each picture there is a corresponding score.
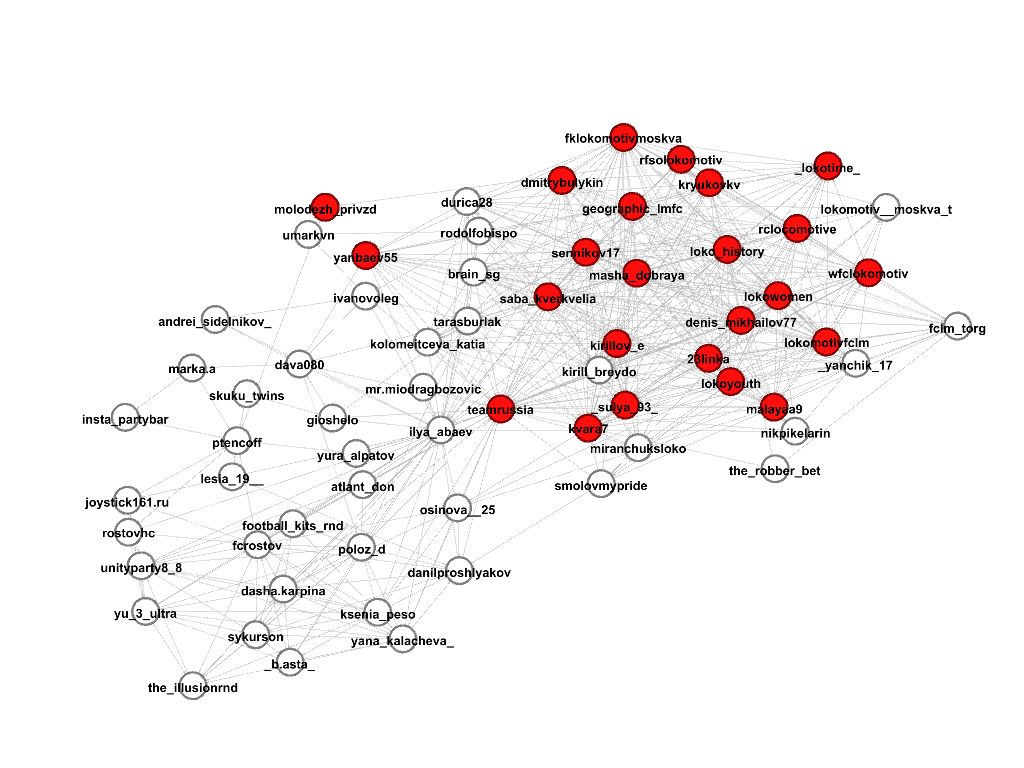
Community 1, score 0.4
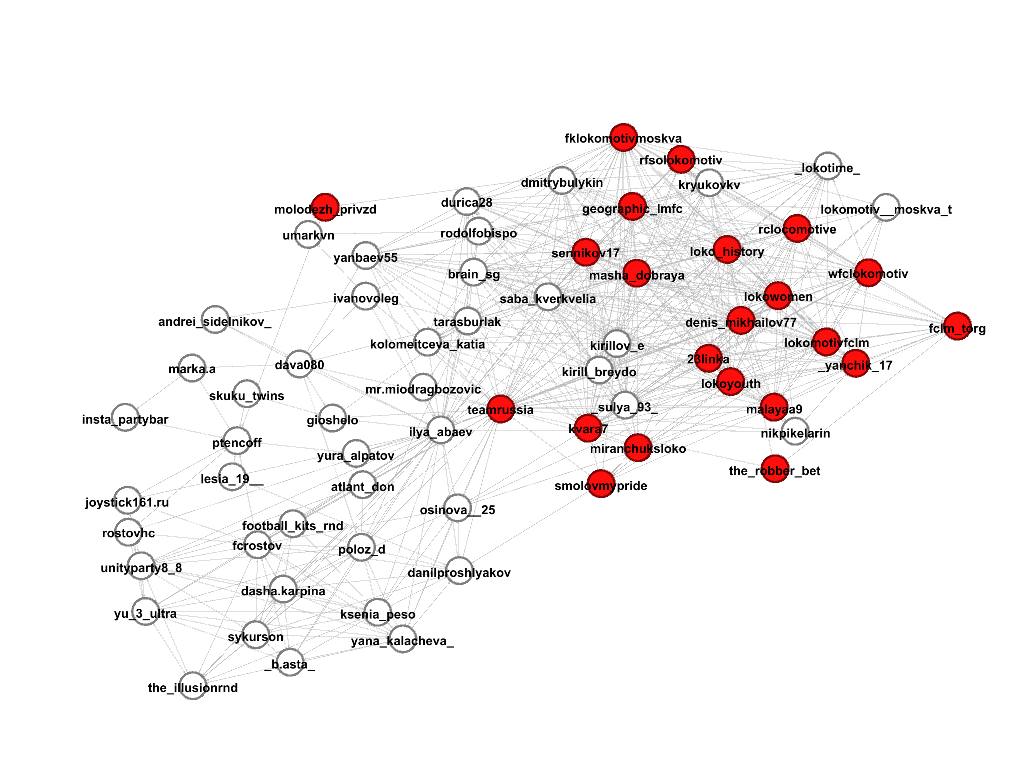
Community 2, score 0.41

Community 3, score 0.34
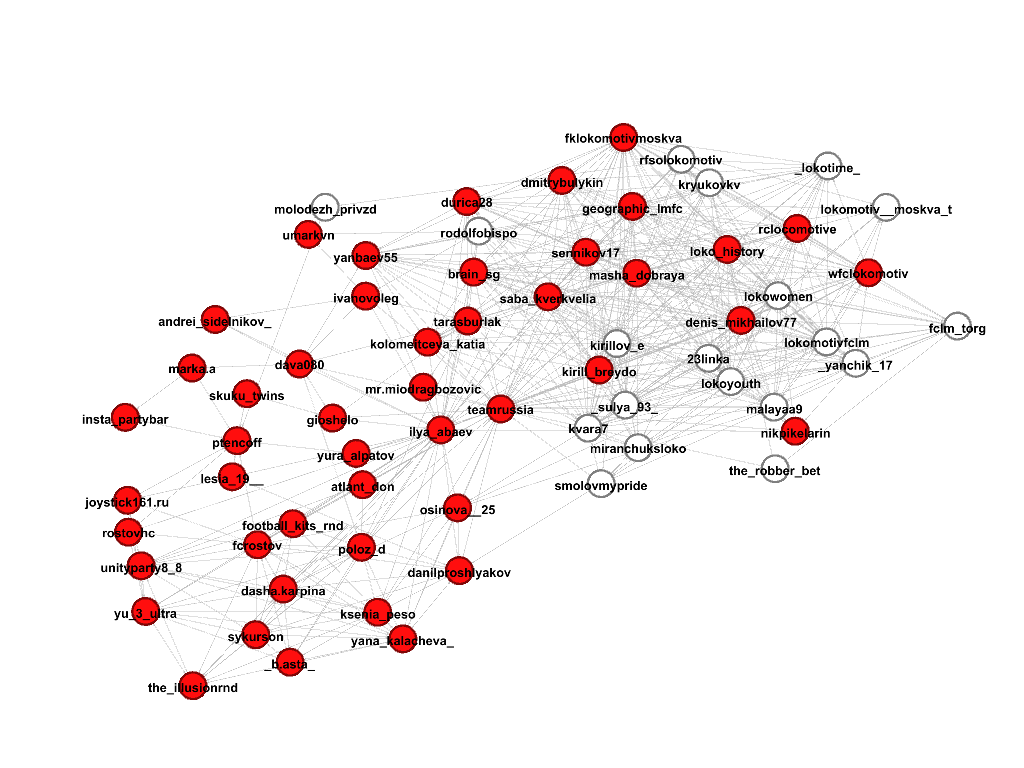
Community 4, score 0.13
Then, after looking at all the profiles from this subgraph, we select those who really belong to the desired community, it turned out like this:

It turns out that the first two communities actually contain what we need, practically without errors (except for the profile of the Russian football teamrussia), the third community is good, but covers fewer accounts than the first two, therefore the score is smaller, and the fourth the community, although it consists of accounts on a football topic (here are the players of other clubs, their wives, and managers), but by, it does not suit us.
It can be concluded that CRank works quite well.
To solve the problem of coloring users by interests, we also analyze the texts of the posts and we wanted to see where the result is better / more interesting (in texts or in subscriptions) and whether there are any matches at all. For a small sample of people, about 800 communities had to be independently labeled. We were more than satisfied with the result and decided that this approach should be developed. The community detection method allows you to find very narrow and unusual interest categories, for example, subscribing to rat profiles (in the sense of small gray rodents) and other amazing things, you can find out what kind of sport a person is supposedly interested in, and not push everything into the “extreme” category etc
We probably won’t mark all 200 thousand communities, but maybe we’ll play around with the CRank results and leave only communities with high speed, and maybe we will mark them as necessary. So it goes :)
Thank!
The article was written jointly with my supervisor Artyom Korolev ( korolevart ) R&D Dentsu Aegis Network Russia

Source
Source
The obvious approach is to categorize a person’s subscriptions. For example, among the subscriptions of user Ivan we found two autobloggers and three accounts with funny pictures, the remaining profiles are not thematic (we assume that these are friends, relatives, colleagues, etc.). From this we conclude: Ivan is a cheerful person, fond of cars. Profit All we need is a “blogger + content theme” match, but it’s not so simple here.
Who is a blogger? A blogger on Instagram is no different from a regular account (and in general, it is something like a state of mind). Ideally, we are interested in thematic accounts with a large share of a live audience, while we would not want to simply cut off the number of subscribers, we might miss something.
Where to get a good taxonomy? If you come up with the categories yourself, then something interesting is sure to get lost in “different things”, and when everything is ready, it turns out that the categories are too broad. We want to get a natural partition, and therefore we will cluster bloggers.
Can one blogger belong to several categories? And how! Very often, he is simultaneously a Swiss, a reaper, and a dude playing dude (as well as travel, life style, wife and mother).
So, we need a dataset with a very large number of bloggers and a clustering algorithm with intersecting clusters at the output.
How it all started
We are approached by customers who want to place their ads on opinion leaders on Instagram most effectively. Sometimes there is a list of bloggers, and then we solve the optimization problem - to reach more people for less money, and sometimes there is no list and relevant bloggers need to be found. This time they searched for profiles of ophthalmologists.
We used an approach similar to a recommendation system:
- Choose 3-7 suitable profiles with your hands (“core community”)

- Using the intersection of subscribers, we identify people who are interested in the topic (“enthusiastic”)

- We are looking for new doctors in the subscriptions of “enthusiastic” people
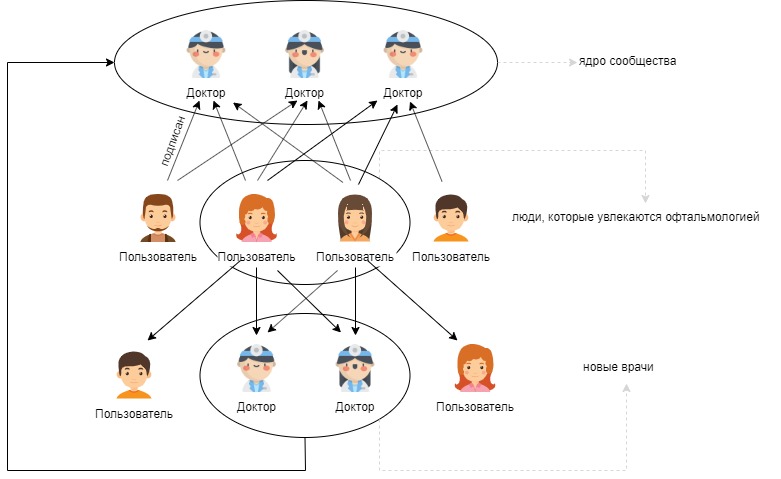
- If necessary, repeat steps 1-3 (adding new doctors to the “core” or changing it)
Now, more on the example.
Step 1. Using an Instagram search, we selected 6 accounts of ophthalmologists from different regions of Russia:
The list is quite random, but it was enough for us that the blog really matches the topic and subscribers are no less than 1000 people.
Step 2. After crossing all the subscribers, we look at the distribution.
| Number of mutual followings | Number of accounts |
|---|---|
| 6 | 2 |
| 5 | 3 |
| four | 24 |
| 3 | 102 |
| 2 | 693 |
| one | 30025 |
Hurrah! There are intersections.
Moreover, there are two people who are subscribed to all six profiles! So, now you need to determine who we consider “enthusiastic” ophthalmology. We decided that we take everyone, starting with three subscriptions. As they say, 1 time is an accident, 2 times is a coincidence, 3 is a regularity. Thus, 131 (2 + 3 + 24 + 102) “enthusiastic” users were found.
Step 3. Download the subscriptions of “enthusiastic” people and again aggregate in every possible way.
We got an impressive list of accounts, from which we will now select new ophthalmologists. The right column shows how many of the 131 people who were selected in the second step are subscribed to the profile. In the top were profiles from our original six, which is not surprising. If we now select a threshold and say: “All profiles with a count value of more than ten are new doctors”, then we risk attributing popular accounts like Olga Buzova to ophthalmologists and at the same time lose small, but relevant profiles, so add one more column the number of subscribers and calculate the percentage of enthusiastic users among subscribers.
For convenience, the fraction is multiplied by 100 (so share is the percentage in fact). As a result, with the condition count> = 6 and share> = 0.05, 166 new ophthalmologists received. Class!
Step 4. 172 accounts became the new “core” of the community, this helped to find about 500 more new ophthalmologists, but the result was already shifted to foreign accounts.
Similar accounts in Instagram recommendations
This is all interesting, of course, and now we know how to find accounts that are similar to each other, but we still want to get a breakdown of all installers into categories. And then the idea came to my mind to look at the ready-made instagram recommendations.
The fact is that thematic accounts have recommendations, but ordinary people do not. Here's the answer to the question of who to consider bloggers and minus one headache. Hurrah!
In the recommendations, one blogger has up to 80 similar profiles. We had a list of 1000 Russian blogs, we started with it. They took similar ones, then similar ones, then ... well, you understand :)
The plan was that someday this process will end, since small profiles with a couple of hundreds of subscribers will not be included in the recommendations, but in fact we stopped when the patience ended. You can always continue to collect the dataset, but so far it has not come in handy, with a high probability we have covered almost all Russian bloggers, and okay.
Now we have a graph with 3,428,453 vertices (bloggers) and 96,967,974 edges (similarity of the two bloggers to each other).
This is how our graph looks on a very small sample
By the way, it turned out that we were not the first to choose this approach.
Apparently, the recommendations on Instagram are formed based on who the followers of this profile are still following, so the doctor from Bryansk will have popular Bryansk accounts and other doctors in the recommendations. This is similar to our search for ophthalmologists, but now we can take into account all the communities to which the blogger belongs at the same time. Plus, the processing speed increases significantly, because there is no need to analyze all the blogger’s subscribers, it’s enough to take only 80 recommended accounts.
Selection and description of the algorithm
Fine! The data has been prepared, now we need to choose a tool and an algorithm that can cope with such a large graph, preferably in an adequate time. Let me remind you that at the output we want to get a set of communities where one blogger can belong to several of them.
We opted for the Stanford Network Analysis Platform (SNAP) library
Stanford Network Analysis Platform (SNAP) is a general purpose network analysis and graph mining library. It is written in C ++ and easily scales to massive networks with hundreds of millions of nodes, and billions of edges. It efficiently manipulates large graphs, calculates structural properties, generates regular and random graphs, and supports attributes on nodes and edges.Our attention was attracted by the AGMfit algorithm (AGM - Affilated Graph Model), and in the end we used BIGCLAM (Cluster Affiliation Model for Big Networks). They differ only in that in the first case the optimization problem is solved combinatorially, which makes it less scalable, and the second just allows you to submit graphs like ours to the input.
The main and rather intuitive thought: the more two nodes have common communities, the greater the likelihood of communication between these two nodes. Both algorithms are based on the Affilated Graph Model, so let's dwell on it in more detail:
Suppose we have a bipartite graph in which round peaks are communities ( and ), and square - users of the social network, and each person ( ) refers to different communities with specific weights ( and ) The more weight, the greater the likelihood that the participant is connected (familiar) with other members of the community.
Example: colleagues who studied at the same university follow each other on Instagram. Both of them are graduates of the same university (community 1) and work in the same company (community 2), we do not know what caused the “friendship” on the network and when they met. Let one just graduate from university and get a job, and the second graduates five years ago and has been working in the company all this time, then the weight of belonging to the first community 1 will be more, and community 2 less and vice versa.
For each common community of a couple of people, we get an independent chance to be familiar:
Thus, the more common the communities are, the more likely they are to know each other:
If we calculate the likelihood of a connection between each pair of users, then at the output we get a graph where the vertices are people and the edges between them are a fact of acquaintance or subscription to each other.
Thus, from the view on the left, we moved on to the picture on the right.
Now let's understand how this model is used in community discovery.
We have a graph of similar bloggers and our goal is to discover communities using the model described above, by selecting the most appropriate weight matrix (its dimension nodes on communities) so that the graph obtained at the output is similar to our original one. This is done by maximizing the likelihood function.
And yet this whole thing can be represented as a non-negative matrix decomposition, which just gives a plus in the scalability of the BIGCLAM algorithm compared to AGMfit.
Read more here and here .
Community Numbering and Launch
In BIGCLAM, you can specify both the exact number of communities and the interval. The algorithm selects 20% of the pairs of nodes for the test, and 80% is the fit of the model with a different number of communities.
We formed an input file with a list of edges and run:
./bigclam -o:bloggers -i:query_graph_all.edgelist -c:-1 -nc:20 -mc:50000 -xc:200000 -nt:10
The parameters allow you to specify the number of attempts, the minimum and maximum number of communities (or exact, if necessary), the number of threads for parallelization and the prefix of the output files. In our case, we set the interval from 50 to 200 thousand communities with 20 attempts on 10 threads. All this splendor was counted five days on 2 Intel® Xeon® Gold 6150 CPU @ 2.70GHz. The output received two files, one for Gephi, the second text, in which each line is a community.
In fact, we ran the algorithm twice and for the first time we ran into the upper limit of 50 thousand communities, the result was not bad, but mixed communities often came across. This time we again reached the maximum value of 200 thousand communities, but they were much better, and we stopped at that. You could probably get the result even better, but two hundred thousand unnamed communities scared our imagination.
Nice picture
What now to do with all this?
On the one hand, the resulting communities help us quickly search for narrow groups of bloggers (as with ophthalmologists then). If there is a couple of bloggers as an example, then we take all the communities into which they belong, discard unnecessary ones and that’s it. You can use a search by name, for example, one of the communities about decor and interior design:
On the other hand, in order to determine the interests of users, all these communities must be somehow meaningfully called. Or maybe all is not necessary.
CRank
Unfortunately, not all the communities received are equally good, and to find the most interesting ones, we decided to try using the CRank prioritization method from the same SNAP library. It is called automatically based on the structure of the graph to match each community rank: the greater the value, the better the community.
At the input of the program, we submit the communities we found earlier, for each of them, prioritization metrics (4 pieces) are calculated, then these metrics are aggregated, and we get an estimate.
Read more here .
Launch
./crank -i:bloggers_cmtyvv.txt -c:query_graph_all.edgelist -o:bloggers_prioritization.txt
During the launch, they encountered a compatibility problem with Ubuntu 18.04, they offer a solution here .
Since our bloggers_cmtyvv.txt community file and the query_graph_all.edgelist list of edges initially contained nicknames (of type string), we had to hash them so that it was int, otherwise crank swears.
Let's see how this works with an example:
We’ll select several communities where there are profiles that contain the string “lokomotiv” in the name, as planned, this should be the community of football fans of the Lokomotiv club, and let's see what it really is. Members of the community are marked in red, under each picture there is a corresponding score.
Community 1, score 0.4
Community 2, score 0.41
Community 3, score 0.34
Community 4, score 0.13
Then, after looking at all the profiles from this subgraph, we select those who really belong to the desired community, it turned out like this:
It turns out that the first two communities actually contain what we need, practically without errors (except for the profile of the Russian football teamrussia), the third community is good, but covers fewer accounts than the first two, therefore the score is smaller, and the fourth the community, although it consists of accounts on a football topic (here are the players of other clubs, their wives, and managers), but by, it does not suit us.
It can be concluded that CRank works quite well.
Manual marking for coloring and results.
To solve the problem of coloring users by interests, we also analyze the texts of the posts and we wanted to see where the result is better / more interesting (in texts or in subscriptions) and whether there are any matches at all. For a small sample of people, about 800 communities had to be independently labeled. We were more than satisfied with the result and decided that this approach should be developed. The community detection method allows you to find very narrow and unusual interest categories, for example, subscribing to rat profiles (in the sense of small gray rodents) and other amazing things, you can find out what kind of sport a person is supposedly interested in, and not push everything into the “extreme” category etc
We probably won’t mark all 200 thousand communities, but maybe we’ll play around with the CRank results and leave only communities with high speed, and maybe we will mark them as necessary. So it goes :)
Thank!
The article was written jointly with my supervisor Artyom Korolev ( korolevart ) R&D Dentsu Aegis Network Russia
Source
All Articles