 テキスト情報を分析する技術は、機械学習の影響で急速に変化しています。 理論的な科学研究からのニューラルネットワークは現実に移行し、テキスト分析はソフトウェアソリューションに積極的に統合されています。 ニューラルネットワークは、自然言語処理の最も複雑なタスクを解決できます。機械翻訳、オンラインストアでのロボットとの「会話」、言い換え、質問への回答、対話の維持に誰も驚かされません。 では、Siri、Alexa、Aliceが私たちを理解したくなく、Googleが探しているものを見つけられず、機械翻訳者が中国語からアルバニア語への「翻訳の難しさ」の例で私たちを楽しませているのはなぜですか? 答えは詳細にあります-理論上は正しく機能するが、実際には実装が困難なアルゴリズムです。 Pythonの機能とライブラリを使用して、機械学習技術を使用して実際のタスクでテキストを分析する方法を学びます。 モデル検索とデータ前処理から、テキストの分類とクラスタリングの方法に進み、視覚的解釈、グラフ分析に進み、スケーリング手法に精通した後、ディープラーニングを使用してテキストを分析することを学びます。
テキスト情報を分析する技術は、機械学習の影響で急速に変化しています。 理論的な科学研究からのニューラルネットワークは現実に移行し、テキスト分析はソフトウェアソリューションに積極的に統合されています。 ニューラルネットワークは、自然言語処理の最も複雑なタスクを解決できます。機械翻訳、オンラインストアでのロボットとの「会話」、言い換え、質問への回答、対話の維持に誰も驚かされません。 では、Siri、Alexa、Aliceが私たちを理解したくなく、Googleが探しているものを見つけられず、機械翻訳者が中国語からアルバニア語への「翻訳の難しさ」の例で私たちを楽しませているのはなぜですか? 答えは詳細にあります-理論上は正しく機能するが、実際には実装が困難なアルゴリズムです。 Pythonの機能とライブラリを使用して、機械学習技術を使用して実際のタスクでテキストを分析する方法を学びます。 モデル検索とデータ前処理から、テキストの分類とクラスタリングの方法に進み、視覚的解釈、グラフ分析に進み、スケーリング手法に精通した後、ディープラーニングを使用してテキストを分析することを学びます。
この本には何が記載されていますか?
この本では、機械学習法を使用して、上記のPythonライブラリを使用してテキストを分析する方法について説明しています。 本の応用性は、アカデミックな言語や統計モデルではなく、アプリケーション内でのテキストトレーニングモデルの効果的な展開に焦点を当てていることを示唆しています。
提案されているテキスト分析モデルは、機械学習のプロセスに直接関連しています。これは、未知のデータを評価するために、トレーニングデータで最良の結果が得られる機能、アルゴリズム、ハイパーパラメーターで構成されるモデルの検索です。 このプロセスは、テキスト分析の分野ではコーパスと呼ばれるトレーニングデータセットの作成から始まります。 次に、属性を抽出し、機械学習方法で理解できる数値データの形式でテキストを表す前処理の方法を調べます。 さらに、いくつかの基本に精通しているので、テキストの分類とクラスタリングの方法の研究に移ります。その物語は本の最初の章を完了します。
以降の章では、より豊富な属性セットを使用してモデルを拡張し、テキスト分析アプリケーションを作成することに焦点を当てています。 最初に、記号の形でコンテキストを提示および実装する方法を見てから、モデル選択のプロセスを制御するための視覚的解釈に進みます。 次に、グラフ分析手法を使用して、テキストから抽出された複雑な関係を分析する方法を説明します。 その後、私たちは対話エージェントに注意を向け、テキストの構文および意味分析の理解を深めます。 結論として、この本では、Sparkを使用したマルチプロセッサシステムでのテキスト分析のためのスケーリング技術の実用的な議論を紹介し、最後に、テキスト分析の次の段階であるディープラーニングを検討します。
この本は誰のためですか?
この本は、ソフトウェア製品で自然言語処理と機械学習方法を使用することに興味があるPythonプログラマー向けに書かれています。 読者が特別な学術的または数学的な知識を持っているとは思わず、代わりに長い説明ではなくツールとテクニックに焦点を合わせます。 まず、この本では英語のテキストの分析について説明しているため、読者は少なくとも名詞、動詞、副詞、形容詞などの文法的実体の基本的な知識と、それらの関連性が必要になります。 機械学習と言語学の経験はないが、Pythonのプログラミングスキルをお持ちの読者は、紹介する概念の学習に迷うことはありません。
抜粋 テキストからグラフを抽出する
テキストからグラフを取得するのは難しい作業です。 通常、その解決策はサブジェクト領域に依存し、一般的に言えば、非構造化データまたは半構造化データの構造化要素の検索は、状況依存分析の質問によって決定されます。
図に示すように、単純なグラフ分析プロセスを編成することにより、このタスクを小さなステップに分割することを提案します。 9.3。
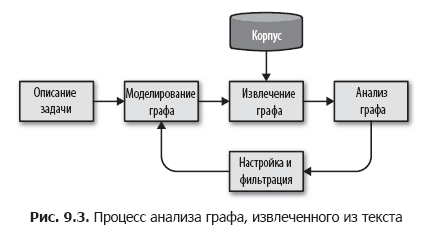
このプロセスでは、まずタスクの説明に基づいて、エンティティとエンティティ間の関係を決定します。 さらに、このスキームに基づいて、メタデータ、コーパス内のドキュメント、ドキュメント内のフレーズまたはトークンを使用してコーパスからグラフを選択し、データとそれらの間の関係を抽出する方法を決定します。 グラフを選択する手法は、身体に適用してグラフを生成し、このグラフをディスクまたはメモリに保存してさらに分析処理することができる周期的なプロセスです。
分析段階では、抽出されたグラフに対して、クラスタリング、構造分析、フィルタリング、評価などの計算が実行され、アプリケーションで使用される新しいグラフが作成されます。 分析段階の結果に基づいて、サイクルの最初に戻り、方法論とスキームを明確にし、より正確な結果を達成するためにノードまたはエッジのグループを抽出または折りたたみます。
ソーシャルグラフの作成
ニュース記事の本文と、テキスト内のさまざまなエンティティ間の関係をモデル化するタスクを検討してください。 報道機関ごとの報道の違いの問題を考慮すると、出版物の名前、著者の名前、情報源を表す要素からグラフを作成できます。 そして、目標が人口統計の詳細に加えて多くの記事で1つのエンティティへの参照を結合することである場合、当社のネットワークはアピールの形式(敬意とその他)を修正できます。 興味のあるエンティティは、ドキュメント自体の構造にある場合もあれば、テキストに直接含まれている場合もあります。
私たちの目標は、ドキュメント内で互いに関連する人、場所、その他を見つけることだとしましょう。 つまり、図に示すように、一連の変換を実行してソーシャルネットワークを構築する必要があります。 9.4。 第7章で作成したEntityExtractorクラスを使用してグラフの構築を開始します。次に、トランスフォーマーを追加します。トランスフォーマーの1つは関連するエンティティのペアを検索し、2番目はこれらのペアをグラフに変換します。
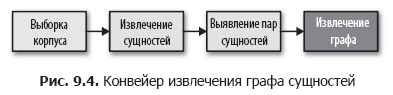
エンティティペアを検索する
次の手順では、EntityPairsクラスを作成します。このクラスは、エンティティのリストの形式でドキュメントを受け取ります(第7章のEntityExtractorクラスによって作成されます)。 このクラスは、Scikit-LearnからのPipelineパイプラインでコンバーターとして機能する必要があります。したがって、第4章で説明するように、BaseEstimatorクラスとTransformerMixinクラスを継承します。 .permutationsを使用して、1つのドキュメントにエンティティのすべての可能なペアを作成します。 変換メソッドは、本文内の各ドキュメントのペアを呼び出します。
import itertools from sklearn.base import BaseEstimator, TransformerMixin class EntityPairs(BaseEstimator, TransformerMixin): def __init__(self): super(EntityPairs, self).__init__() def pairs(self, document): return list(itertools.permutations(set(document), 2)) def fit(self, documents, labels = None): return self def transform(self, documents): return [self.pairs(document) for document in documents]
これで、ドキュメントからエンティティを順番に抽出してペアにすることができます。 しかし、頻繁に発生するエンティティのペアを、一度だけ発生するペアと区別することはまだできません。 次のセクションで扱う各ペアのエンティティ間の関係の重みを何らかの方法でエンコードする必要があります。
プロパティグラフ
グラフの数学的モデルは、ノードとエッジのセットのみを定義し、さまざまな計算で使用できる隣接行列として表すことができます。 ただし、強度や関係の種類をモデル化するメカニズムはサポートしていません。 2つのエンティティが1つのドキュメントのみに表示されますか、それとも多くのドキュメントに表示されますか 特定のジャンルの記事で一緒に会いますか? このような推論をサポートするには、グラフのノードとエッジに意味のあるプロパティを保存する何らかの方法が必要です。
プロパティグラフモデルを使用すると、より多くの情報をグラフに埋め込むことができるため、機能が拡張されます。 プロパティグラフでは、ノードは受信エッジと送信エッジを持つオブジェクトであり、原則として、タイプフィールドを含み、リレーショナルデータベースのテーブルに似ています。 リブは、開始点と終了点を定義するオブジェクトです。 これらのオブジェクトには通常、接続のタイプを識別するラベルフィールドと、接続の強度を定義する重みフィールドが含まれています。 テキスト分析にグラフを使用する場合、多くの場合、ノードとして名詞を使用し、エッジとして動詞を使用します。 モデリング段階に移行した後、これによりノードのタイプ、リンクラベル、および提案されたグラフ構造を記述することができます。
著者について
ベンジャミンベンフォートは、ワシントンDCに拠点を置くデータサイエンスのスペシャリストであり、政治(コロンビア特別区でよくあること)を完全に無視し、テクノロジーを好みます。 現在、メリーランド大学で博士論文に取り組んでおり、そこでは機械学習と分散コンピューティングを研究しています。 彼の研究室にはロボットがありますが(これは彼のお気に入りのエリアではありませんが)、彼の悔しさの多くに、アシスタントはこれらのロボットにナイフと道具を常に装備します。 ロボットがトマトを切り刻もうとしているのを見て、ベンジャミンは自分でキッチンをホストし、フランス料理とハワイ料理、そしてあらゆる種類のバーベキューとバーベキューを調理することを好みます。 専門教育プログラマ、職業データ研究者であるベンジャミンは、自然言語処理からPythonデータ研究、分析でのHadoopとSparkの使用まで、幅広いトピックをカバーする記事を頻繁に執筆しています。
レベッカビルブロ博士-データサイエンスのスペシャリスト、Pythonプログラマー、教師、講師、記事の著者。 ワシントンDCに住んでいます。 機械学習の結果の視覚的評価に特化しています:特徴分析からモデル選択およびハイパーパラメーター設定まで。 自然言語処理、セマンティックネットワークの構築、エンティティの解決、および多数の次元を持つ情報の処理の分野で研究を行っています。 オープンソースソフトウェアのユーザーと開発者のコミュニティへの積極的な参加者として、RebeccaはYellowbrick(予測ブラックボックスモデリングを目的としたPythonパッケージ)などのプロジェクトで他の開発者と協力しています。 空き時間には、家族と自転車に乗ったり、ウクレレを演奏したりすることがよくあります。 イリノイ大学アーバナシャンペーン校で博士号を取得し、実践的なコミュニケーションと視覚化のテクニックを学びました。
»本の詳細については、出版社のウェブサイトをご覧ください
» コンテンツ
» 抜粋
ホーカーの20%割引クーポン-Python
本の紙版が支払われると、電子版の本が電子メールで送信されます。
PS:本のコストの7%が新しいコンピューター本の翻訳に費やされます 。印刷会社に渡された本のリストはこちらです。