最近の3つの作品「 AOPを使用したゼロからのオリエンテーリングトレーニング 」、「 PRM-RL:強化学習とパターンベースの計画の組み合わせを使用した長距離ロボットオリエンテーリングの実装 」、および「 PRM-RLによる長期オリエンテーリング 」、ディープOPと長期計画を組み合わせて、新しい環境に簡単に適応する自律型ロボットを研究しています。 ローカルプランナーエージェントに、オリエンテーションに必要な基本アクションを実行する方法と、移動するオブジェクトと衝突することなく短距離を移動する方法を教えます。 地元のプランナーは、障害物までの距離を提供し、ロボットを制御するための線形および角速度を提供する1次元ライダーなどのセンサーを使用して、ノイズの多い環境観測を行います。 OPおよびニューラルネットワークのアーキテクチャに対する報酬の検索を自動化する方法である自動強化学習(AOP)を使用して、シミュレーションでローカルプランナーをトレーニングします。 10〜15 mの限られた範囲にもかかわらず、現地のプランナーは、実際のロボットでの使用と、以前は未知であった新しい環境の両方にうまく適応します。 これにより、大きなスペースでのオリエンテーションのビルディングブロックとして使用できます。 次に、ロードマップ、ノードが個別のセクションであるグラフ、およびノイズの多いセンサーとコントロールを使用して実際のロボットをよく模倣したローカルプランナーがノード間を移動できる場合にのみエッジがノードを接続するグラフを作成します。
自動強化学習(AOP)
最初の作業では、小さな静的環境でローカルプランナーをトレーニングします。 ただし、標準のディープOPアルゴリズム(ディープ決定論的勾配( DDPG )など)で学習する場合、いくつかの障害があります。 たとえば、地元のプランナーの本当の目標は、与えられた目標を達成することであり、その結果、彼らは珍しい報酬を受け取ります。 実際には、これには研究者がアルゴリズムの段階的な実装と賞の手動調整にかなりの時間を費やす必要があります。 研究者はまた、明確で成功したレシピを持たずに、ニューラルネットワークのアーキテクチャについて決定する必要があります。 最後に、DDPGなどのアルゴリズムは不安定であり、しばしば壊滅的な忘却を示します。
これらの障害を克服するために、ディープラーニングを強化して自動化しました。 AOPは、 大規模なハイパーパラメーター最適化を通じて報酬とニューラルネットワークアーキテクチャを求めて、ディープOPの進化的な自動ラッパーです。 報酬の検索とアーキテクチャの検索の2つの段階で機能します。 報酬の検索中に、AOPは複数世代のDDPGエージェントの集団を同時にトレーニングしており、それぞれにローカルプランナーの真のタスクに最適化された、パスのエンドポイントに到達するために最適化された独自の報酬関数があります。 報酬検索フェーズの最後に、エージェントを目標に導く頻度が最も高いものを選択します。 ニューラルネットワークのアーキテクチャの検索フェーズでは、選択された賞を使用してネットワークレイヤーを調整し、累積賞を最適化するこのレースに対して、このプロセスを繰り返します。
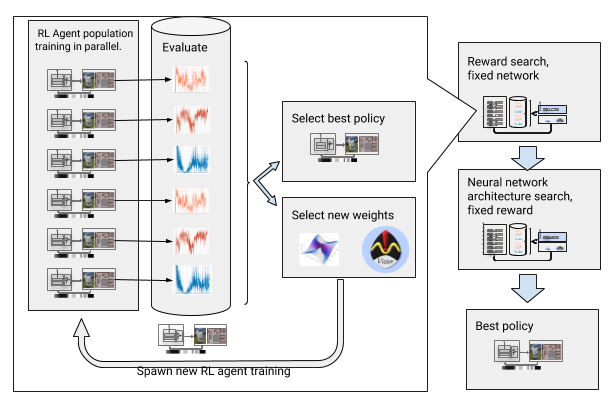
賞の検索とニューラルネットワークのアーキテクチャを備えたAOP
ただし、この段階的なプロセスにより、AOPはサンプル数の点で無効になります。 100エージェントの10世代のAOPトレーニングには、32年間の研究に相当する50億のサンプルが必要です! 利点は、AOPの後、手動学習プロセスが自動化され、DDPGに壊滅的な忘却が生じないことです。 最も重要なことは、最終ポリシーの品質が高いことです。センサー、ドライブ、およびローカリゼーションからのノイズに耐性があり、新しい環境に十分に一般化されています。 私たちの最善のポリシーは、テストサイトで他のオリエンテーション方法よりも26%成功していることです。
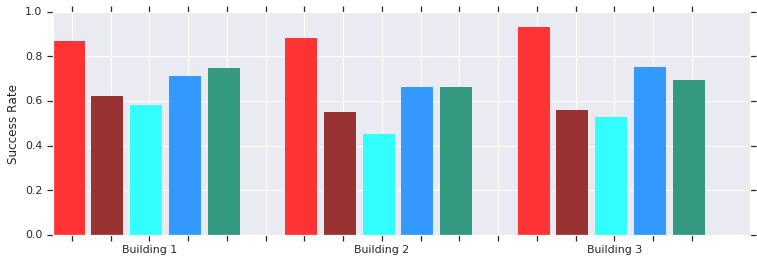
赤-以前は未知だったいくつかの建物で、AOPは短距離(最大10 m)で成功します。 手動でトレーニングされたDDPG(濃い赤)、人工ポテンシャルフィールド(青)、動的ウィンドウ(青)、および行動クローン(緑)との比較。
ローカルAOPスケジューラポリシーは、実際の非構造化環境のロボットとうまく機能します
これらの政治家は、ローカルオリエンテーションのみが可能ですが、移動する障害物に耐性があり、非構造化環境で実際のロボットが十分に許容します。 また、静的オブジェクトを使用したシミュレーションのトレーニングを受けていますが、移動オブジェクトに効果的に対処します。 次のステップは、AOPポリシーをサンプルベースの計画と組み合わせて、業務分野を拡大し、長距離のナビゲート方法を教えることです。
PRM-RLを使用した長距離のオリエンテーション
パターンベースのプランナーは 、ロボットの動きを概算して、長距離のオリエンテーションで動作します。 たとえば、ロボットは、セクション間に実装された遷移パスを描画することにより、 確率的ロードマップ (PRM)を構築します。 ICRA 2018カンファレンスで賞を受賞した2番目の作品では、PRMと手動で調整されたローカルOPスケジューラー(AOPなし)を組み合わせて、ロボットをローカルでトレーニングし、他の環境に適合させます。
まず、ロボットごとに、一般的なシミュレーションでローカルスケジューラポリシーをトレーニングします。 次に、使用される環境のマップに基づいて、このポリシー(いわゆるPRM-RL)を考慮してPRMを作成します。 同じカードは、建物で使用したい任意のロボットに使用できます。
PRM-RLを作成するには、ローカルのOPスケジューラがサンプル間で確実に繰り返し移動できる場合にのみ、サンプルからノードを結合します。 これは、モンテカルロシミュレーションで行われます。 結果のマップは、特定のロボットの機能とジオメトリに適合します。 形状が同じでセンサーとドライブが異なるロボット用のカードは、接続性が異なります。 エージェントは角を回って回転できるため、直視線にないノードもオンにできます。 ただし、壁や障害物に隣接するノードは、センサーノイズのためマップに含まれる可能性が低くなります。 実行中、OPエージェントはマップ上のあるセクションから別のセクションに移動します。

ランダムに選択されたノードのペアごとに3つのモンテカルロシミュレーションでマップが作成されます
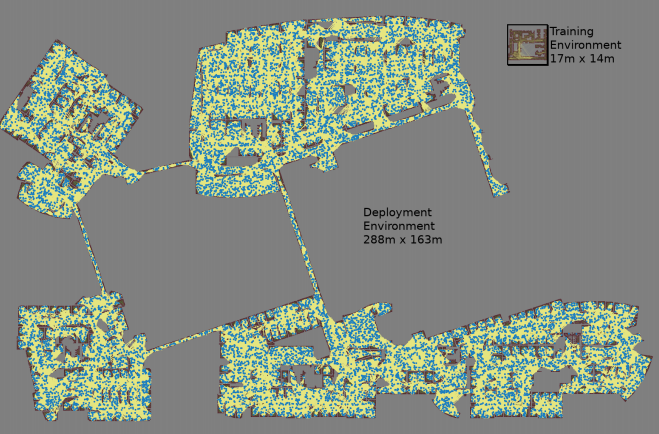
最大のマップのサイズは288x163 mで、70万近くのエッジが含まれていました。 300人の作業員が4日間収集し、11億の衝突チェックを実施しました。
3番目の作業は、元のPRM-RLにいくつかの改善を提供します。 まず、手動で調整されたDDPGをローカルAOPスケジューラーに置き換えています。これにより、長距離での向きが改善されます。 第二に、 同時ローカライズとマーキング ( SLAM )のマップが追加されます。これは、ロボットが実行時にロードマップを構築するためのソースとして使用します。 SLAMカードはノイズの影響を受けやすく、これにより、シミュレーションで訓練されたエージェントが実際の世界ではるかに悪い動作をするため、ロボット工学でよく知られている問題である「シミュレータと現実のギャップ」が閉じられます。 シミュレーションの成功レベルは、実際のロボットの成功レベルと一致しています。 そして最後に、分散された建物マップを追加したため、最大700,000個のノードを含む非常に大きなマップを作成できます。
AOPエージェントを使用してこの方法を評価しました。AOPエージェントは、20回の試行で90%のケースで正常に完了したrib骨のみを含むトレーニング環境を200倍の面積で建物の図面に基づいて作成しました。 PRM-RLを100 mまでの距離でさまざまな方法と比較しましたが、これはローカルプランナーの範囲を大幅に超えていました。 PRM-RLは、ロボットの機能に適したノードの正しい接続により、従来の方法よりも2〜3倍頻繁に成功を収めました。
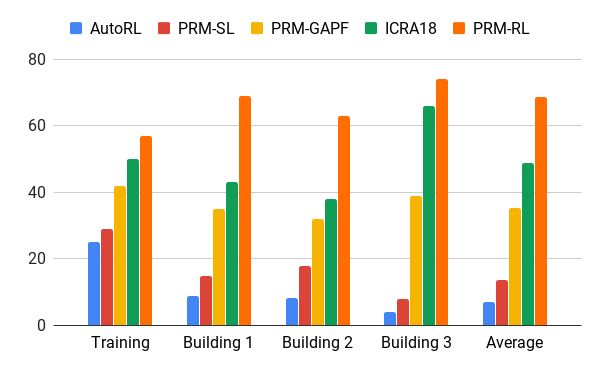
さまざまな建物で100 m移動した場合の成功率。 青-ローカルAOPスケジューラー、最初のジョブ。 赤-元のPRM。 黄色-人工電位場; 緑は2番目の仕事です。 赤-3番目のジョブ、AOPを使用したPRM。
多くの建物の多くの実際のロボットでPRM-RLをテストしました。 以下に、テストスイートの1つを示します。 ロボットは、SLAMカードを超える最も厄介な場所や領域を除き、ほぼどこでも確実に動きます。

おわりに
マシンオリエンテーションは、運動障害を持つ人々の自立を大幅に高めることができます。 これは、環境に簡単に適応できる自律ロボットと、既存の情報に基づいて新しい環境に実装できる方法を開発することで実現できます。 これは、AOPを使用して短距離向けの基本的なオリエンテーショントレーニングを自動化し、取得したスキルをSLAMカードと組み合わせて使用してロードマップを作成することで実現できます。 ロードマップは、ロボットが確実に移動できるリブで接続されたノードで構成されます。 その結果、1回のトレーニングの後、さまざまな環境で使用でき、特定のロボットに特別に適合したロードマップを発行できるロボット行動ポリシーが開発されました。