
飛行、不可視性、テレパシーのどれを選択しますか? 後者の生きた、ある意味での具体化は、常にスタンリーのペンから1963年に登場したXメン漫画、チャールズ・ザビエル教授のキャラクターでした。 しかし、漫画では、そのような超大国は見つけることができません。 現実はどうですか? 別の存在の心を読むことができますか? 判明したように、今では可能ですが、想像どおりではありません。 今日、私たちはこの研究に精通します。その主な成果は、実験ラットの脳ニューロンの電子活動を、迷路をリアルタイムで読むことです。 科学者はどのようにしてネズミの頭に入ってきましたか、彼らは何を達成し、彼らの技術の展望はどうでしたか? 研究者のレポートは、これらの質問やその他の質問への回答を提供します。 行こう
研究の基礎
科学者は、現時点では、脳を研究する分野の主要なタスクの1つは、複雑な構造として、データの収集と分析のための方法と関連ツールの改善であることに注意しています。 より正確には、神経系の時空間的活動の収集データに隠された情報を解読することが重要です。 言い換えれば、科学者は何かが起こったことを確認し(グラフのスパイク)、このイベントに対応する情報を取得する必要があります。
科学者によると、最も難しいことは、そのような観察を行い、リアルタイムでデータを収集および分析することです。 これは、マルチ電極センサーを備えたNKI(ニューロコンピューターインターフェイス)を介して行われます。
NQIを使用した脳研究の最も一般的な形式は、循環実験です(試行ごとに同じ条件を繰り返します)。 この場合、注意、記憶、学習などの特定の認知機能を十分に研究することができます。
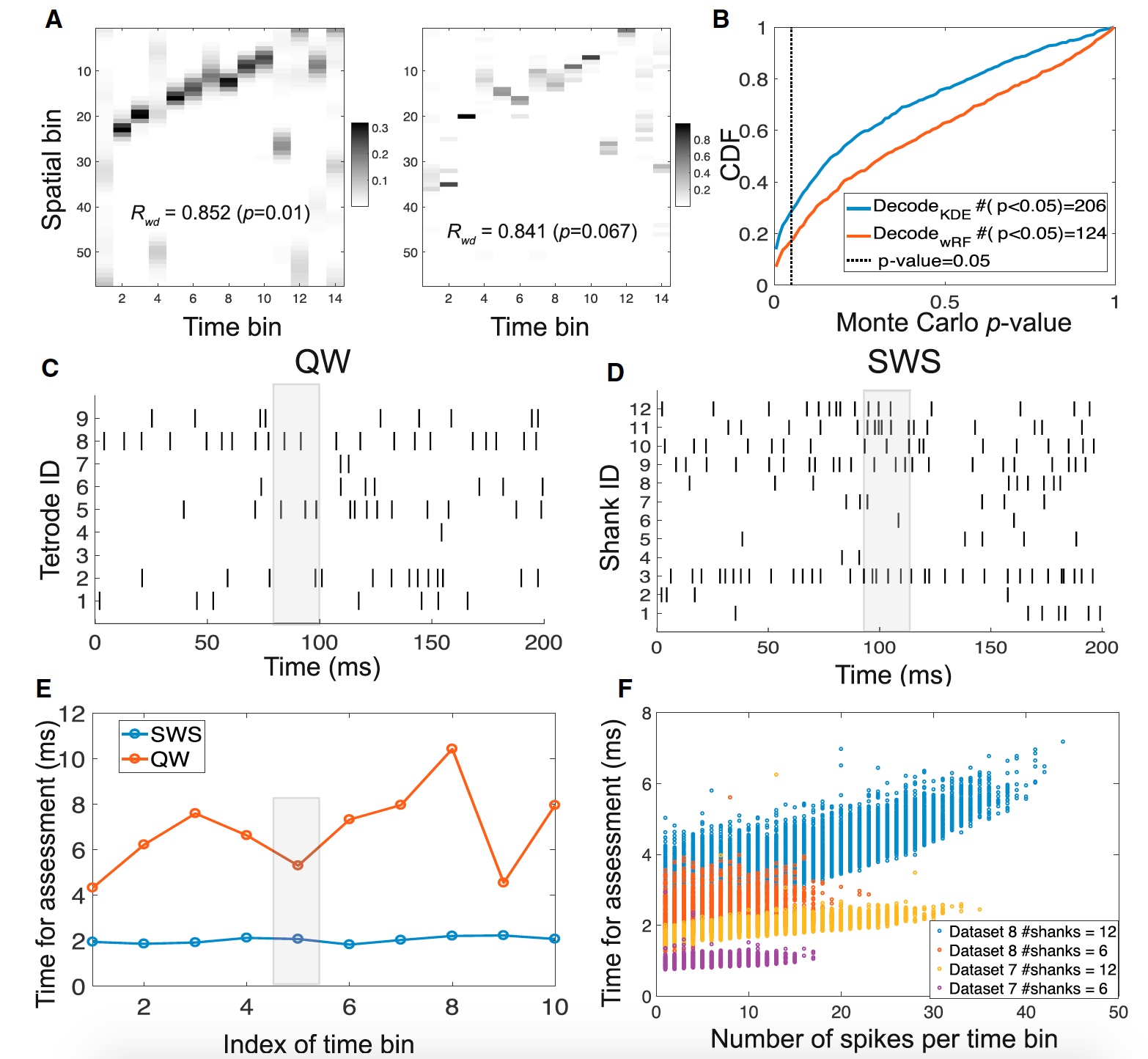
空間ナビゲーションは、前述の認知機能を学習するための最もよく知られた最も効果的な方法です。 このチェックはどのようなものですか? 非常にシンプル-迷路。 そのような実験中に、いわゆる脳の神経コーディング(または「空間コード」)がラット脳の多くの部分で発見されました:海馬、嗅内皮質、一次視覚皮質(V1)、脾臓後皮質および頭頂皮質。 これらの「コード」は、ラットが迷路のどこにいるか、どこに移動してどこから来たかについての情報を保存する特定の信号です。 実験後だけでなく、ラットが休息または睡眠の状態(ゆっくりとした睡眠の段階)にあるときに、リアルタイムで読み取る必要があるのはこの情報です。
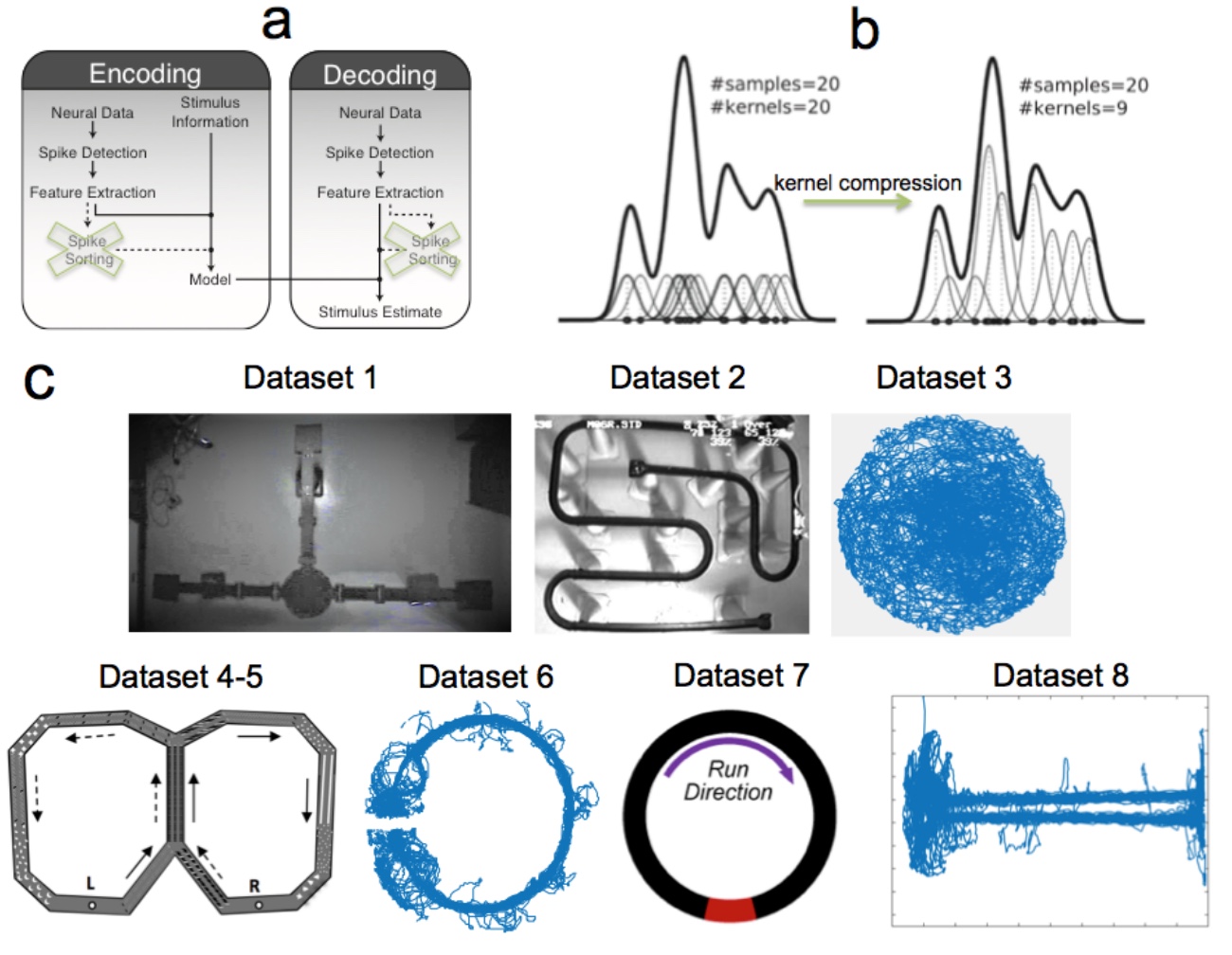
提案された手法は、エンコードとデコードの2つの主要なステージ(上の図のスキームA)で構成されています。 コーディング段階で、 スパイク* (神経信号)と空間的位置の符号のベクトルの全体的な確率密度が作成されます。 装飾段階は、前の段階で得られたものに可能な限り近い空間位置の形でのデータの再構築を担当します。
スパイク*(ピーク) -電気活動の細胞外登録中のニューロンの活動電位。科学者は、鉄の観点から、リアルタイムデータ分析の問題は、マルチコアセントラルプロセッサ(以下、CPUと呼びます)上のマルチスレッドソフトウェアを使用して解決できると指摘しています。 このようなシステムの欠点は、コアの数であり、ニューロコンピューターインターフェイスのシステム全体のスケーラビリティを制限します。 研究者は、通常のクアッドコアコンピューターにグラフィックプロセッサ(GPU)を組み込むことにしました。 GPUを使用すると、デコードプロセスが大幅に加速され、システムのスケーラビリティが拡張されます。 センサー自体も、四極管から高密度シリコンセンサーに変更されました。
調査結果
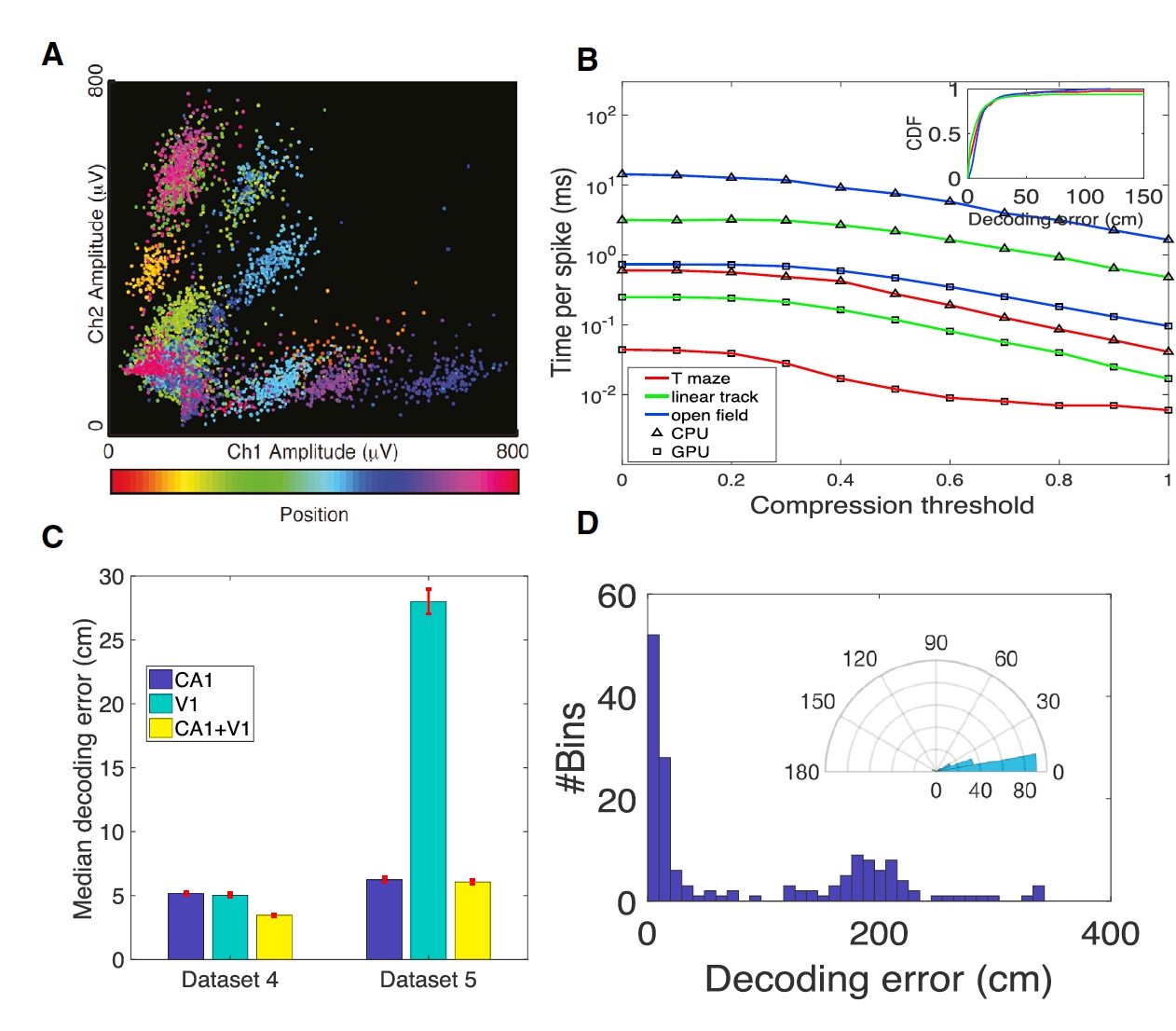
テスト中に、すべてのシステムオプションがテストされました。CPUに基づいて、CPU + GPに基づいて、四極管とシリコンセンサーが使用されました。 データベースは、2次元空間の空間ナビゲーション時に固定された海馬、新皮質、視床のスパイクで構成されていました。 データベースオプションは上の画像( C )に示されています。
イメージNo. 1
科学者が予想したように、グラフィックプロセッサを使用したシステムは、CPUシステムと比較して非常に優れた結果を示しました。
したがって、データベースNo. 1の場合、GPUを備えたシステムは、0.02 ms /スパイクのデコード速度で0.5のデータ圧縮しきい値(スパイクエンコーディング)を示しました。 同じ条件下で、CPUシステムのデコード速度は0.44 ms /スパイク(1V)でした。 また、データ圧縮の「増幅」によりデコード速度が向上するだけでなく、このプロセスの精度が低下することにも注意してください。
コア帯域幅は、デコードプロセスでも重要な役割を果たします。 このパラメーターが小さい場合、圧縮率はデコードの精度にわずかに影響しました。
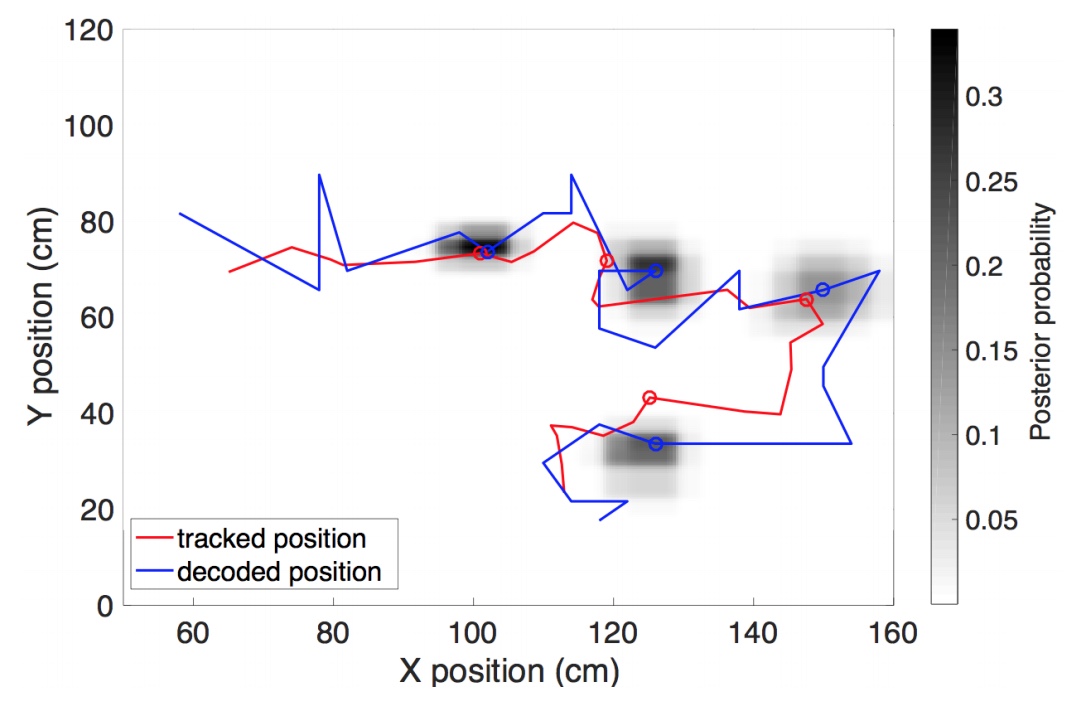
実際のデータと比較した、デコードされたデータの精度のグラフ。
科学者は、データの優れたデコード速度に加えて、高度なデコード精度も誇っています。
次に、研究者は、ラットが8の字の形で迷路を移動することになっており、四足動物は海馬のCA1セクションだけでなく、一次視覚野V1も読み取る実験を行いました。
装飾は、CA1、V1、CA1 + V1の別々の形式で行われました。 V1データの分析により、この領域の癒着には空間変位に関する情報の印象的な割合が含まれていることが示されました。 V1データとCA1データを組み合わせることにより、科学者は全体的なデコード精度( 1C )を向上させることができました。
コアパラメーターは、相互検証データに基づいて、脳の各部分(CA1およびV1)に個別に最適化されました。 さらに、デコードの精度は高かった。 また、データ圧縮がゼロの場合、予想どおり、デコード速度は非常に低かった。
次の実験は迷路の中で行われましたが、迷路のように見えますが、見た目は単純なリングです。 ラットは円を描いて走り、四足動物は視床の前核のデータを読みました。 脳のこの領域は、記憶形成のプロセスおよび空間の向きにおいて最も重要なものの1つです。
重要なポイント-視床の前核のニューロンのほとんどは、頭部方向のニューロンです。 したがって、データ分析のプロセスでは、身体の位置に対応する脳のローブの活動だけでなく、頭の位置も考慮されました。これら2つのパラメーターは異なる可能性があるためです。
視床の前核のニューロンの活動の分析により、頭部の位置だけでなく、試験中の被験者の空間的方向との関係が確認されました。 しかし、円内を移動するテストの場合、頭部位置データのデコードの精度の低下が観察されました。これは、ラットの速度とは関係ありません。 これは、移動の方向によるものです。 より正確には、計算では、両方のオプションが考慮されます-時計回りと反時計回り。
このテスト(円で実行)は、移動の軌跡や迷路の複雑さではなく重要です(実際にはリングではありません)。 ここで重要な要素は、ラットの速度です。 ランニング中、ニューロンの活動も加速され、それによりラットの動きを監視します。 グラフィックスプロセッサを使用するシステムは、CPUのみに基づく従来のシステムよりもはるかに高速に(トレーニングの試行回数を減らして)海馬ニューロンのスパイクをデコードできました。
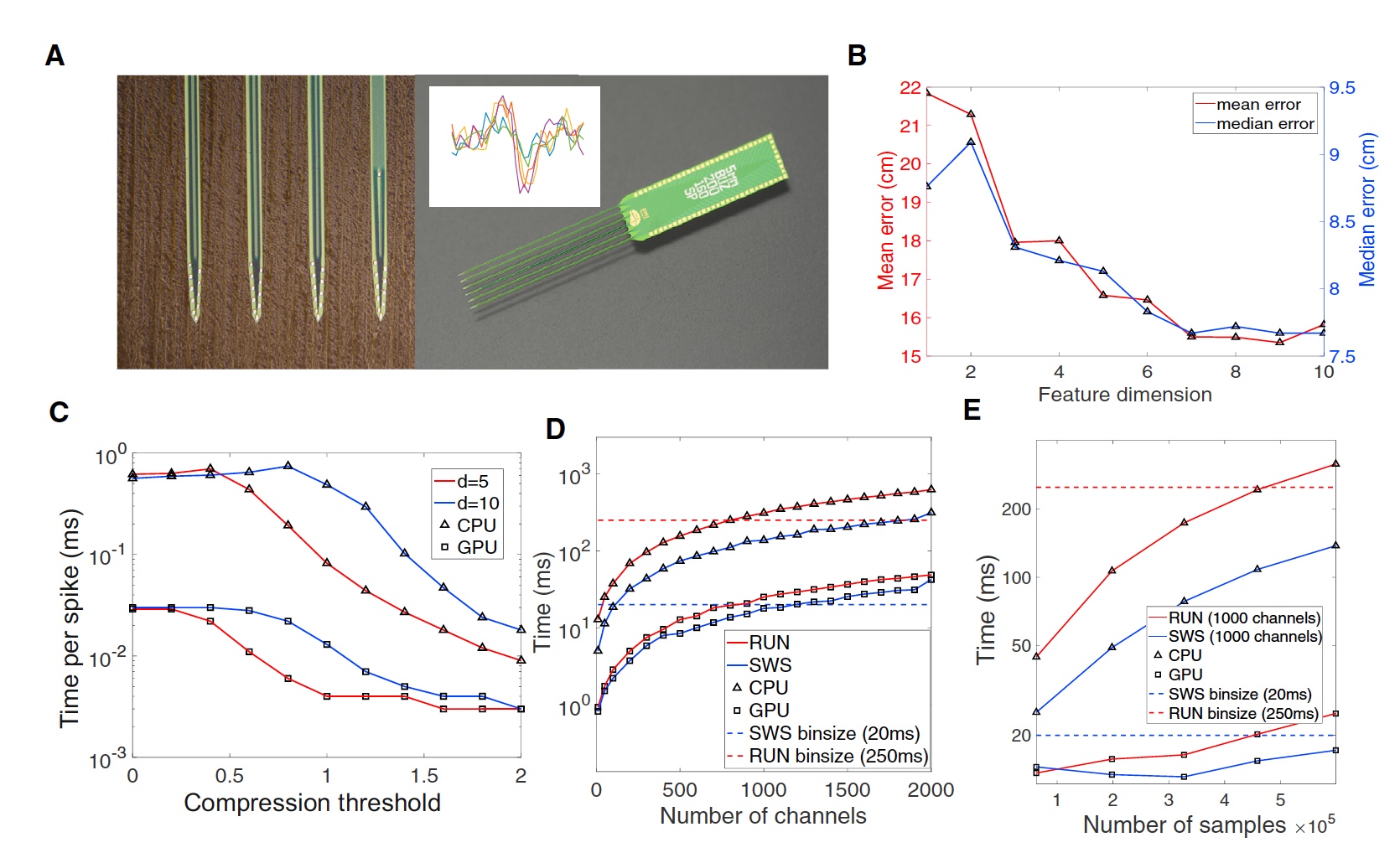
イメージNo. 2
実験で使用された四極管により、十分に正確なデータを取得することができましたが、これは望ましいことの限界ではありません。 そのため、シリコンマルチチャンネル電極もチェックすることにしました。 画像2Aは、64チャンネルのシリコン電極を示しています。 これらのセンサーのうち2つは、左右の海馬に配置されました。
また、システムのスケーラビリティを確認する必要もありました。 このため、仮想電極の数が2000に達するまで、シリコン電極のデータを「クローン」しました。さらに、システムは、移動(実行)および安静(スロースリープの段階)の間にこれらのデータをデコードする必要がありました。 結果は2Dグラフに表示されます。
GPUの最適化とメモリへの直接アクセスの使用により、移動中のデコード時間-250ミリ秒、静止中のデコード時間-20ミリ秒を達成することができました。 2番目のケースでは、データ圧縮はコーディング段階で実行されませんでしたが、合計で約1200のチャネルが含まれていました。
グラフ2Eは、システムがCPUのみを使用している場合、固定チャネル数でのデコードに必要な時間が大幅に増加することを示しています。 GPUを使用するときのデコードプロセスのスローダウンはそれほど重要ではなく、それほど急激には発生しません。
この研究の重要な特徴は、ニューロン活動データのリアルタイムでの読み取りと処理です。 GPシステムは、以前のテストで示されたように、非常に短い時間で大量のデータをデコードできるため、これに最適です。
システムをテストするために、スロースリープフェーズ中に海馬がデコードされました(メモリからの可能なイベントの741再現)。
イメージNo. 3
テスト後の標準的なデータ分析方法論とリアルタイムの方法論の比較により、科学者はラットの軌跡の再構築精度の向上(睡眠中)を発見しました。 つまり、システムは、テスト中にラットが移動した軌道を大幅に正確に再構築しました。 同時に、システムは、テスト後、安静時(遅い睡眠段階)のニューロンの活動を分析しました。
この研究の詳細については、科学者の報告書と追加資料をご覧になることを強くお勧めします。
エピローグ
この研究は主に、ニューロン活動のリアルタイムの読み取りが可能であることを確認しました。 神経系のような複雑なシステムになると、その活動の分析が遅れると、得られるデータの精度が大幅に低下します。 したがって、この研究は非常に重要です。
科学者は、彼らの方法論を使用して、脳の活動のみに依存してラットの運動経路を構築できるだけでなく、試験動物の記憶を使用してこの経路を再構築することもできました。 これは本当に信じられないほど複雑で、間違いなく有望です。
システムをさらに改善すると、データをより正確かつ迅速に分析できるようになります。これにより、脳の原理、ニューロン同士の関係、外的要因に対する反応を理解し、身体全体で発生する特定のイベントを、脳全体ではなく特定のニューロンの活動と比較することができます。
脳は、依然として世界で最も研究が不十分なシステムの1つです。 しかし、それを研究するための新しい方法を作成するという想像力は本当に無限である科学者の努力によって、私たちはより多くを理解することができるでしょう。 そして、脳機能について知れば知るほど、脳機能に影響を与えることができます。 もちろん、病気の早期診断、進行性脳疾患の治療など、良い意味で。 この場合、知識は力だけでなく健康でもあります。
そして、もちろん、金曜日のオフトピック:
「面白いがおかしな」カテゴリの広告、特に宣伝する製品を考慮して:)
見てくれてありがとう、好奇心を保ち、あなたの健康を大事にしてください。 良い週末をお過ごしください。
「面白いがおかしな」カテゴリの広告、特に宣伝する製品を考慮して:)
見てくれてありがとう、好奇心を保ち、あなたの健康を大事にしてください。 良い週末をお過ごしください。
ご滞在いただきありがとうございます。 私たちの記事が好きですか? より興味深い資料を見たいですか? 注文するか、友人に推薦することで、私たちをサポートします。私たちがあなたのために発明したエントリーレベルのサーバーのユニークなアナログのHabrユーザーのために30%の割引: VPS(KVM)E5-2650 v4(6コア)についての真実20ドルまたはサーバーを分割する方法? (オプションはRAID1およびRAID10、最大24コア、最大40GB DDR4で利用可能です)。
VPS(KVM)E5-2650 v4(6コア)10GB DDR4 240GB SSD 1Gbpsまで1月1日まで無料で、6か月間支払われた場合は、 こちらから注文できます 。
Dell R730xdは2倍安いですか? オランダと米国で249ドルからIntel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TVを2台持っているだけです! インフラストラクチャビルの構築方法について読んでください。 クラスRは、1米ドルで9,000ユーロのDell R730xd E5-2650 v4サーバーを使用していますか?