使用されるライブラリ: lxml 、 asyncio 、 aiohttp (lxml-Pythonを使用してHTMLページを解析するためのライブラリ。非同期と迅速なデータ抽出のためにasyncioとaiohttpを使用します)。 また、XPathを積極的に使用します。 誰がそれが何であるか知らない、素晴らしいチュートリアル 。
すべてのゲームのページへのリンクを取得する
まず、小さなペンで作業する必要があります。 www.metacritic.com/browse/games/genre/metascore/action/all?view=detailedにアクセスして、すべてを収集します
このリストのURL:
そして、それらをgenres.jsonという.jsonファイルに保存します。 これらのリンクを使用して、サイトのすべてのゲームをジャンル別に解析します。
少し考えた後、ゲームへのすべてのリンクを.csvファイルに収集し、ジャンルに分類することにしました。 各ファイルには、ジャンルに対応する名前が付けられます。 上記のリンクに移動すると、すぐにアクションジャンルのページが表示されます。 ページネーションがあることに気づきます。
htmlページを確認します。

最大ページ数を含む目的の要素aは、一意の属性class = page last_pageを持つli要素の子孫であり、最初のページを除くすべてのページのURLが <url of the 1st page> + <&page = page_number>、およびリクエストパラメータの2番目のページは1番です。
最大ページ番号を取得するためにXPathをまとめる:
// li [@ class = 'page last_page'] / a / text()
次に、このシートからすべてのゲームへのすべてのリンクを取得する必要があります。
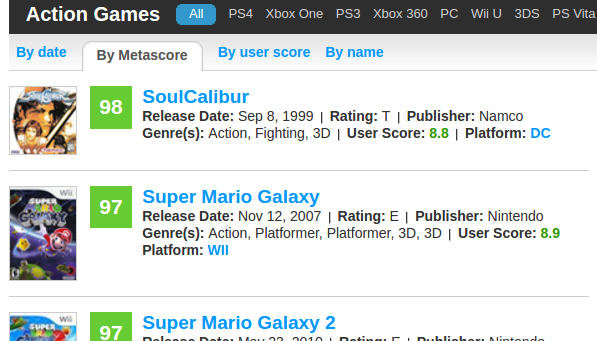
シートのレイアウトを見て、htmlを調べます。
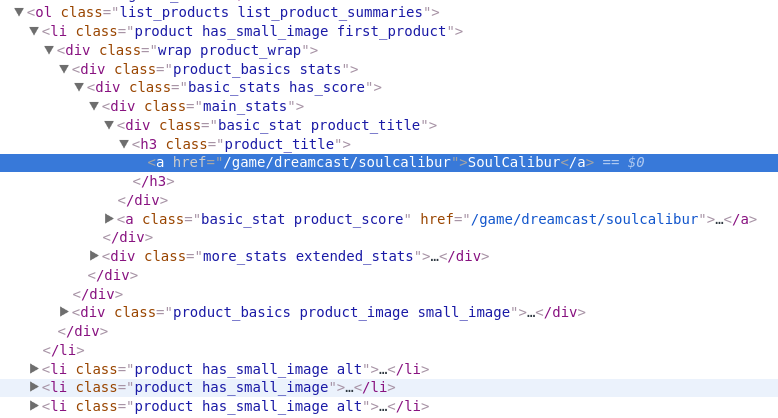
最初に、リスト自体(ol)を検索のルート要素として取得する必要があります。 class = list_products list_product_summaries属性があり、これはページのhtmlコードに固有です。 次に、 liには、ゲームへの目的のリンクがあるhref属性に子要素aを持つ子要素h3があることがわかります。
すべてをまとめる:
// ol [@ class = 'list_products list_product_summaries'] // h3 [@ class = 'product_title'] / a / @ href
いいね! 戦いの半分は完了しました。次に、プログラムでページをループし、リンクを収集してファイルに保存する必要があります。 高速化するために、PCのすべてのコアで操作を並列化します。
# get_games.py import csv import requests import json from multiprocessing import Pool from time import sleep from lxml import html # . root = 'http://www.metacritic.com/' # Metacritic 429 'Slow down' # , . SLOW_DOWN = False def get_html(url): # Metacritic User-Agent. headers = {"User-Agent": "Mozilla/5.001 (windows; U; NT4.0; en-US; rv:1.0) Gecko/25250101"} global SLOW_DOWN try: # - 429, # 15 . if SLOW_DOWN: sleep(15) SLOW_DOWN = False # html requests html = requests.get(url, headers=headers).content.decode('utf-8') # html , SLOW_DOWN true. if '429 Slow down' in html: SLOW_DOWN = True print(' - - - SLOW DOWN') raise TimeoutError return html except TimeoutError: return get_html(url) def get_pages(genre): # Games with open('Games/' + genre.split('/')[-2] + '.csv', 'w') as file: writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL) # url > 1 genre_page_sceleton = genre + '&page=%s' def scrape(): page_content = get_html(genre) # lxml html . document = html.fromstring(page_content) try: # int. lpn_text = document.xpath("//li[@class='page last_page']/a/text()" last_page_number = int(lpn_text)[0]) pages = [genre_page_sceleton % str(i) for i in range(1, last_page_number)] # . pages += [genre] # . for page in pages: document = html.fromstring(get_html(page)) urls_xpath = "//ol[@class='list_products list_product_summaries']//h3[@class='product_title']/a/@href" # url . games = [root + url for url in document.xpath(urls_xpath)] print('Page: ' + page + " - - - Games: " + str(len(games))) for game in games: writer.writerow([game]) except: # 429 . . scrape() scrape() def main(): # .json . dict = json.load(open('genres.json', 'r')) p = Pool(4) # . map . p.map(get_pages, [dict[key] for key in dict.keys()]) print('Over') if __name__ == "__main__": main()
すべてのファイルとリンクを1つのファイルにマージします。 Linuxの場合は、catを使用して、STDOUTを新しいファイルにリダイレクトするだけです。 Windowsでは、小さなスクリプトを作成し、ジャンルファイルのあるフォルダーで実行します。
from os import listdir from os.path import isfile, join onlyfiles = [f for f in listdir('.') if isfile(join(mypath, f))] fout=open("all_games.csv","a") for path in onlyfiles: f = open(path) f.next() for line in f: fout.write(line) f.close() fout.close()
これで、Metacriticのすべてのゲームへのリンクを含む1つの大きな.csvファイルができました。 十分に大きい、25,000レコード。 さらに、1つのゲームが複数のジャンルを持つことができるため、重複があります。
すべてのゲームに関する情報を取得する
次の計画は? 各リンクをたどり、各ゲームに関する情報を抽出します。
たとえば、 Portal 2ページに移動します。
取得します:
- ゲーム名
- プラットフォーム
- 説明
- メタスコア
- ジャンル
- 発売日
投稿を短くするために、この情報を抽出したxpathをすぐにリストします。
ゲーム名:
// h1 [@ class = 'product_title'] // span [@ itemprop = 'name'] // text()
複数のプラットフォームを使用できるため、2つのクエリが必要です。
// span [@ itemprop = 'device'] // text()
// li [@ class = 'summary_detail product_platforms'] // a //テキスト()
私たちが持っている説明は要約にあります:
// span [@ itemprop = 'description'] // text()
メタスコア:
// span [@ itemprop = 'ratingValue'] // text()
ジャンル:
// span [@ itemprop = 'description'] // text()
発売日:
// span [@ itemprop = 'datePublished'] // text()
25,000ページあり、頭を抱えていることを思い出します。 どうする 複数のスレッドがあっても長くなります。 解決策があります-非同期および非ブロッキングコルーチン。 PyConのすばらしいビデオをご覧ください 。 Async-awaitは、Python 3.5.2の非同期プログラミングを簡素化します。 Habréのチュートリアル 。
パーサー用のコードを書いています。
from time import sleep import asyncio from aiohttp import ClientSession from lxml import html # , . games_urls = list(set([line for line in open('Games/all_games.csv', 'r')])) # . result = [] # . total_checked = 0 async def get_one(url, session): global total_checked async with session.get(url) as response: # . page_content = await response.read() # . item = get_item(page_content, url) result.append(item) total_checked += 1 print('Inserted: ' + url + ' - - - Total checked: ' + str(total_checked)) async def bound_fetch(sm, url, session): try: async with sm: await get_one(url, session) except Exception as e: print(e) # 30 429. sleep(30) async def run(urls): tasks = [] # . . sm = asyncio.Semaphore(50) headers = {"User-Agent": "Mozilla/5.001 (windows; U; NT4.0; en-US; rv:1.0) Gecko/25250101"} # User-Agent, Metacritic async with ClientSession( headers=headers) as session: for url in urls: # . task = asyncio.ensure_future(bound_fetch(sm, url, session)) tasks.append(task) # . await asyncio.gather(*tasks) def get_item(page_content, url): # lxml html . document = html.fromstring(page_content) def get(xpath): item = document.xpath(xpath) if item: return item[-1] # - , None return None name = get("//h1[@class='product_title']//span[@itemprop='name']//text()") if name: name = name.replace('\n', '').strip() genre = get("//span[@itemprop='genre']//text()") date = get("//span[@itemprop='datePublished']//text()") main_platform = get("//span[@itemprop='device']//text()") if main_platform: main_platform = main_platform.replace('\n', '').strip() else: main_platform = '' other_platforms = document.xpath("//li[@class='summary_detail product_platforms']//a//text()") other_platforms = '/'.join(other_platforms) platforms = main_platform + '/' + other_platforms score = get("//span[@itemprop='ratingValue']//text()") desc = get("//span[@itemprop='description']//text()") # . return {'url': url, 'name': name, 'genre': genre, 'date': date, 'platforms': platforms, 'score': score, 'desc': desc} def main(): # . loop = asyncio.get_event_loop() future = asyncio.ensure_future(run(games_urls)) loop.run_until_complete(future) # . - . print(result) print('Over') if __name__ == "__main__": main()
私のコンピューターIntel i5 6600K、16 GB RAM、lan 10 mb / sでは、10ゲーム/秒あたりのどこかで非常にうまくいきました。 コードを微調整して、スクリプトを音楽や映画に適合させることができます。