「ミュージカルチェア」(子供の遊び。子供たちは音楽を聴きながら椅子の列を歩きます。音楽が止まると、プレーヤーは椅子に座ります。
言うまでもなく、これは雇用の問題を引き起こしています。 多くの候補者がいることは喜ばしいことです。 しかし、この事実の裏側は、成長するスタートアップのフレームワーク内で高度な資格を持つエンジニアを適切なマインドセットで保持するという問題です。 同時に、候補者の選択と承認は迅速である必要があります。それは、たとえ部分的に適切な候補者であっても、1〜2日以内に彼の損失に悩まされるためです。
これにより、候補者のリストが多数ある場合にどの方法が最適であるかがわかり、最終的には最高のエンジニアを選択するか、いずれにしても、このリストで最高のエンジニアを選択します。
HWルイスは、 「コインをフリップする理由:善意の芸術と科学 」 という本で、知人に関連する同様の(より厳密ではあるが)問題について書いています。 候補者を選ぶ代わりに、本は妻を選ぶことについて話します、そして、インタビューをする代わりに、デートの問題は考慮されます。 ただし、一度に1人しか会えないと想定されている本とは異なり、私の状況では、明らかに複数の候補者にインタビューすることができます。 ただし、発生する問題はほとんど変わっていません。多くの候補者にインタビューし、意思決定に多くの時間を費やすと、それらは他の企業によって傍受されます。 おそらく、その前でさえ、コミュニケーションの過剰から口の中で泡で死ぬという事実は言うまでもありません。
本の中で、ルイスは次の戦略を提案しました-20の候補者のリストから選択するとしましょう。 全員にインタビューする代わりに、4つの候補者をランダムに選択してインタビューし、このサンプルリストから最適な候補者を選択します。 これら4つの候補者の中から最高の候補者が揃ったので、リストの残りの部分を1人ずつ面接して、より良い人に会い、最終的にこの候補者を採用します。
ご想像のとおり、この戦略は確率的であり、最適な候補の選択を保証するものではありません。 実際、2つの最悪のシナリオがあります。 まず、誤って4つの最悪候補をサンプルリストとして選択し、リストの残りから選択された最初の候補が5 m最悪の場合、5番目に悪い候補を採用します。 良くない。 逆に、最良の候補者がサンプルリストに載っている場合、プロセス全体に時間がかかりすぎたため、20回のインタビューのリスクを負い、この最高の候補者を失います。 また悪い。
これは良い戦略ですか? さらに、この戦略を最大限に活用するために必要なリスト(候補の総数)とサンプルリストの最適なサイズはどれくらいですか? 優秀なエンジニアになり、モンテカルロシミュレーションを使用して答えを見つけましょう。
20個の候補のリストのサイズから始めて、0〜19のサンプルリストの番号でソートします。各サンプルリストについて、選択した候補がリスト内の最良の候補である確率を見つけます。 実際、サンプルリストが0または19の場合、この確率は既にわかっています。サンプルリストが0の場合、インタビューする最初の候補が選択されます(比較する人がいないため)。したがって、確率は1/20です。そして5%です。 同様に、サンプルリストが19の場合、最後の候補を選択する必要があり、この確率も1/20に等しく、5%です。
これをモデル化したRubyコードを次に示します。 シミュレーションを100,000回実行して確率を可能な限り正確に計算し、結果をCSVファイルOptimal.csvに保存します
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
require 'rubygems' require 'faster_csv' population_size = 20 sample_size = 0.. population_size - 1 iteration_size = 100000 FasterCSV. open ( 'optimal.csv' , 'w' ) do | csv | sample_size. each do | size | is_best_choice_count = 0 iteration_size. times do # population = ( 0.. population_size - 1 ) . to_a . sort_by { rand } # - sample = population. slice ( 0.. size - 1 ) rest_of_population = population [ size.. population_size - 1 ] # -? best_sample = sample. sort . last # best_next = rest_of_population. find { | i | i > best_sample } best_population = population. sort . last # ? is_best_choice_count + = 1 if best_next == best_population end best_probability = is_best_choice_count. to_f / iteration_size. to_f csv << [ size, best_probability ] end end
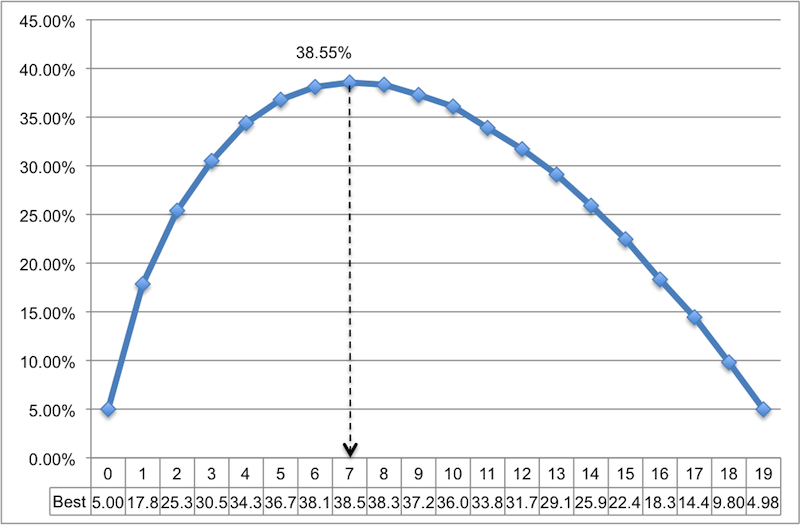
コードは非常に自明であるため(特にすべてのコメントが含まれているため)、詳細には触れません。 結果は、MS Excelでファイルを開いてマークした後の折れ線グラフに表示されます。 ご覧のように、サンプルリストとして4つの候補を選択した場合、3つのうち約1つの確率で最適な候補を選択できます。 サンプルリストとして7つの候補を選択すると、チャンスが増えます。 この場合、最適な候補を選択する確率は約38.5%です。 あまり良く見えません。
しかし、率直に言って、いくつかの候補者の場合、私は候補者が「最高」である必要はありません(いずれにしても、そのような評価は主観的です)。 リストの上位4分の1(上位25%)の候補者を取得するとします。 私のチャンスは何ですか?
これをモデル化した改訂コードを次に示します。
- 「rubygems」が 必要
- 'faster_csv'が 必要
- 母集団サイズ= 20
- sample_size = 0 .. 母集団サイズ-1
- 繰り返しサイズ= 100000
- top = ( population_size - 5 ) .. ( population_size - 1 )
- FasterCSV。 open ( 'optimal.csv' 、 'w' ) do | csv |
- sample_size。 それぞれ が | サイズ|
- is_best_choice_count = 0
- is_top_choice_count = 0
- 繰り返しサイズ。 回 はやる
- 母集団= ( 0 .. 母集団 _サイズ-1 ) 。 to_a 。 sort_by { rand }
- サンプル=母集団。 スライス ( 0 .. サイズ -1 )
- rest_of_population =母集団[サイズ.. 母集団サイズ-1 ]
- best_sample =サンプル。 並べ替えます 。 最後の
- best_next = rest_of_population。 {を 見つける 私| i > best_sample }
- best_population =母集団。 並べ替えます 。 最後の
- top_population =母集団。 ソート [トップ]
- is_best_choice_count + = 1( best_next == best_populationの場合)
- is_top_choice_count + = 1( top_populationの場合 )。 含める ? best_next
- 終わり
- best_probability = is_best_choice_count。 to_f / iteration_size。 to_f
- top_probability = is_top_choice_count。 to_f / iteration_size。 to_f
- csv << [ size、best_probability、top_probability ]
- 終わり
- 終わり
Optimal.csvファイルに、候補者の上位4分の1(上位25%)を含む新しい列を追加しました。 以下は新しいチャートです。 比較のために、前のシミュレーションの結果が追加されます。
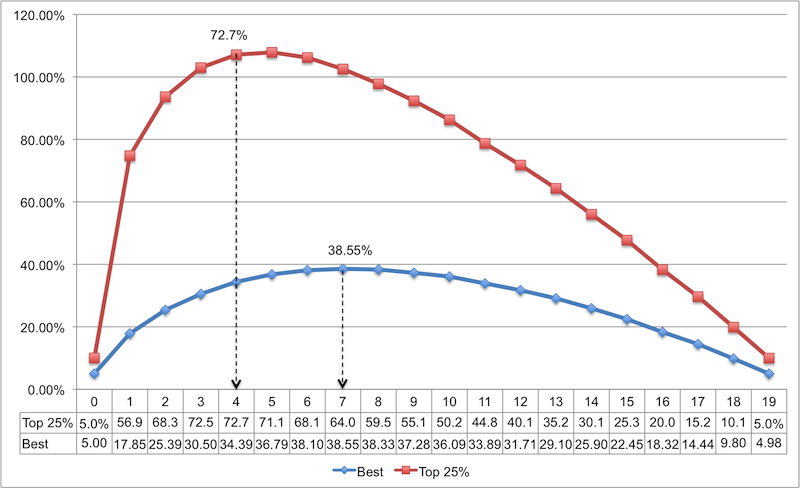
現在、結果は有望であり、サンプルリストの最適サイズは4です(ただし、3と4の差は小さいため、実際には3で十分です)。 この場合、リストの上位4分の1から候補を選択する確率は72.7%に急ぎます。 いいね!
次に、20人の候補者を扱います。 候補者が多いリストはどうですか? この戦略は、たとえば100人の候補者のリストをどのように維持できますか?
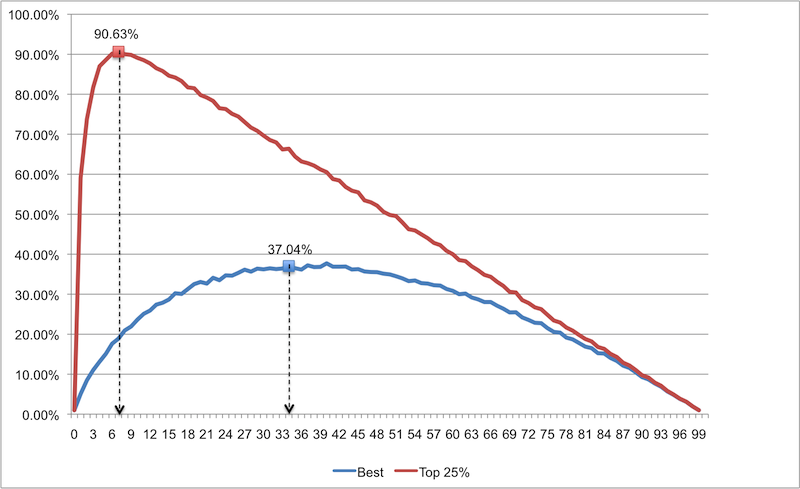
ご覧のとおり、この戦略は、大きなリストから最適な候補を決定するのには適していません(サンプルリストが大きすぎ、成功の確率が低すぎます)。 この結果は、小さい数のリストで得られた結果よりも悪いものです。 ただし、リストの上位4分の1の候補に満足している場合(つまり、要求が少なくなります)、サンプルリストの7つの候補で十分ですが、必要な結果を達成する確率は90.63%になります。 これらは驚くべきオッズです!
これは、あなたが何百人もの候補者を雇用するマネージャーであれば、全員にインタビューすることで自殺を試みる必要がないことを意味します。 7人の候補者のサンプルリストにインタビューし、最適な候補を選択し、サンプルリストで最高の候補よりも良い候補が見つかるまで、他の候補に1つずつインタビューします。 100人の候補者のリストの上位25%のいずれかを選択する可能性は90.63%です(これがおそらく必要なものです)。