Choosing between XML and SQL for rolling LiquiBase scripts using Java / Spring / H2 as an example
In the process of working on the next project, the team disputed over the use of XML or SQL format in Liquibase. Naturally, many articles have already been written about Liquibase, but as always, I want to add my observations. The article will present a small tutorial on creating a simple application with a database and consider the difference in meta-information for these types.
Liquibase is a database independent library for tracking, managing, and applying database schema changes. In order to make changes to the database, a migration file (* changeset *) is created, which is connected to the main file (* changeLog *), which controls versions and manages all changes. XML , YAML , JSON and SQL formats are used to describe the structure and changes of the database.
The basic concept of database migration is as follows:
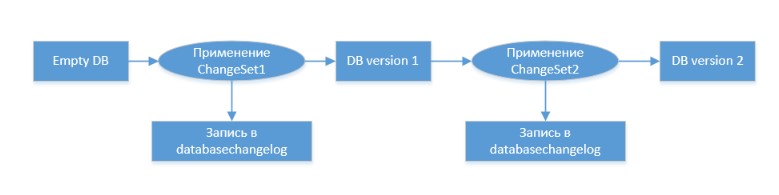
More information on Liquibase can be found here or here . I hope the overall picture is clear, so let's move on to creating the project.
The use of Spring-boot is not conditional here, you can do just a maven-plugin for rolling scripts. So let's get started.
1. Create a maven project in the IDE and add the following dependencies to the pom file:
2. In the resources folder, create the application.yml file and add the following lines:
Liquibase line: change-log: classpath: /db/changelog/db.changelog-master.yaml - tells us where the liquibase script file is located.
3. In the resources folder along the db.changelog-master path, create the following files:
4. Adding data to files:
For the test you need to create two unrelated t
tables and the minimum data set.
We add the well-known sql syntax to the sqlSchema.sql file:
Using sql as a changeet is driven by easy scripting. In the files, everyone understands the usual sql.
A comment is used to separate the changeset:
--changeset TestUsers_sql: 1 with the change number and last name
(parameters can be found here .)
In the xmlSchema.sql file, add the DSL that liquibase provides:
This format for describing the creation of tables is universal for different databases. Just like the slogan of Java: "It is written once, it works everywhere . " Liquibase uses the xml description and compiles it into specific sql code, depending on the selected database. Which is very convenient for general parameters.
Each operation is performed in a separate changeSet, indicating id and the name of the author. I think the language used in xml is very easy to understand and does not even need to be explained.
5. Upload the data to our plates, this is not necessary, but since the plates have been made, you need to put something in them. We fill in the data.xml file with the following data:
Files for rolling tables are created, data for tables is created. It's time to combine all this into a common rolling order and launch our application.
Add our sql and xml files to the db.changelog-master.yml file:
And now that we have everything created. Just run our application. You can use the command line or plugin to start, but we will create just the main method and run our SpringApplication.
Now that we have run our two scripts to create and populate the tables, we can look at the databaseChangeLog table and see what rolled up.

Xml rolling result:
Sql roll result:
Another important conclusion to using xml is rollback. Commands such as create table, alter table, add column have automatic rollback when using xml. For sql files, each rollback must be written manually.
Everyone chooses for himself what to use. But our choice fell on the xml side. Detailed meta-information and easy transition to other databases outweighed the scales from everyone's favorite sql-format.
Liquibase is a database independent library for tracking, managing, and applying database schema changes. In order to make changes to the database, a migration file (* changeset *) is created, which is connected to the main file (* changeLog *), which controls versions and manages all changes. XML , YAML , JSON and SQL formats are used to describe the structure and changes of the database.
The basic concept of database migration is as follows:
More information on Liquibase can be found here or here . I hope the overall picture is clear, so let's move on to creating the project.
The test project uses
- Java 8
- Spring boot
- Maven
- H2
- well liquibase itself
Project Creation and Dependencies
The use of Spring-boot is not conditional here, you can do just a maven-plugin for rolling scripts. So let's get started.
1. Create a maven project in the IDE and add the following dependencies to the pom file:
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.liquibase</groupId> <artifactId>liquibase-core</artifactId> <version>3.6.3</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> </dependencies>
2. In the resources folder, create the application.yml file and add the following lines:
spring: liquibase: change-log: classpath:/db/changelog/db.changelog-master.yaml datasource: url: jdbc:h2:mem:test; platform: h2 username: sa password: driverClassName: org.h2.Driver h2: console: enabled: true
Liquibase line: change-log: classpath: /db/changelog/db.changelog-master.yaml - tells us where the liquibase script file is located.
3. In the resources folder along the db.changelog-master path, create the following files:
- xmlSchema.xml - change script in xml format
- sqlSchema.sql - script of changes in sql format
- data.xml - add data to the table
- db.changelog-master.yml - list of changeSets
4. Adding data to files:
For the test you need to create two unrelated t
tables and the minimum data set.
We add the well-known sql syntax to the sqlSchema.sql file:
--liquibase formatted sql --changeset TestUsers_sql:1 CREATE TABLE test_sql_table ( name VARCHAR NOT NULL, description VARCHAR ); --changeset TestUsers_sql:2 CREATE TABLE test_sql_table_2 ( name VARCHAR NOT NULL, description VARCHAR );
Using sql as a changeet is driven by easy scripting. In the files, everyone understands the usual sql.
A comment is used to separate the changeset:
--changeset TestUsers_sql: 1 with the change number and last name
(parameters can be found here .)
In the xmlSchema.sql file, add the DSL that liquibase provides:
<?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="Create table test_xml_table" author="TestUsers_xml"> <createTable tableName="test_xml_table"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> <changeSet id="Create table test_xml_table_2" author="TestUsers_xml"> <createTable tableName="test_xml_table_2"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> </databaseChangeLog>
This format for describing the creation of tables is universal for different databases. Just like the slogan of Java: "It is written once, it works everywhere . " Liquibase uses the xml description and compiles it into specific sql code, depending on the selected database. Which is very convenient for general parameters.
Each operation is performed in a separate changeSet, indicating id and the name of the author. I think the language used in xml is very easy to understand and does not even need to be explained.
5. Upload the data to our plates, this is not necessary, but since the plates have been made, you need to put something in them. We fill in the data.xml file with the following data:
<?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="insert data to test_xml_table" author="TestUsers"> <insert tableName="test_xml_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_xml_table_2" author="TestUsers"> <insert tableName="test_xml_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table" author="TestUsers"> <insert tableName="test_sql_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table_2" author="TestUsers"> <insert tableName="test_sql_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> </databaseChangeLog>
Files for rolling tables are created, data for tables is created. It's time to combine all this into a common rolling order and launch our application.
Add our sql and xml files to the db.changelog-master.yml file:
databaseChangeLog: - include: # schema file: db/changelog/xmlSchema.xml - include: file: db/changelog/sqlSchema.sql # data - include: file: db/changelog/data.xml
And now that we have everything created. Just run our application. You can use the command line or plugin to start, but we will create just the main method and run our SpringApplication.
View metadata
Now that we have run our two scripts to create and populate the tables, we can look at the databaseChangeLog table and see what rolled up.
Xml rolling result:
- In the id field from the xml files, a header appears that the developer points to changeSet, each individual changeSet is a separate line in the database with a title and description.
- The author of each change is indicated.
Sql roll result:
- There is no detailed information about changeSet in the id field of sql files.
- The author of each change is not indicated.
Another important conclusion to using xml is rollback. Commands such as create table, alter table, add column have automatic rollback when using xml. For sql files, each rollback must be written manually.
Output
Everyone chooses for himself what to use. But our choice fell on the xml side. Detailed meta-information and easy transition to other databases outweighed the scales from everyone's favorite sql-format.
All Articles