We accelerate the distributed processing of large graphs using probabilistic data structures and not only

One of the most valuable resources of any social network is the “graph of friendships” - information is disseminated through connections in this column, interesting content is sent to users, and constructive feedback is sent to content authors. At the same time, the graph is also an important source of information that allows you to better understand the user and continuously improve the service. However, in those cases when the graph grows, it is technically more and more difficult to extract information from it. In this article we will talk about some tricks used to process large graphs in OK.ru.
To begin, consider a simple task from the real world: determine the age of the user. Knowing the age allows the social network to select more relevant content and better adapt to the person. It would seem that age is already indicated when creating a page on a social network, but in fact, quite often, users are cunning and indicate an age different from the real one. The social graph can help to rectify the situation :).
Take Bob, for example (all the characters in the article are fictional, any coincidence with reality is the result of the creativity of a random house):

On the one hand, half of Bob's friends are teenagers, suggesting that Bob is also a teenager. But he also has older friends, so confidence in the answer is low. Additional information from the social graph can help clarify the answer:

Adding into consideration not only the arcs in which Bob is directly involved, but also the arcs between his friends, we can see that Bob is part of a dense community of adolescents, which allows us to make a conclusion about his age with a greater degree of confidence.
Such a data structure is known as an ego network or ego subgraph; it has been used for a long time and successfully used in solving many problems: searching for communities, identifying bots and spam, recommending friends and content, etc. However, the calculation of the ego of a subgraph for all users in a graph with hundreds of millions of nodes and tens of billions of arcs is fraught with a number of "small technical difficulties" :).
The main problem is that when considering information about the "second step" in the graph, a quadratic explosion of the number of connections occurs. For example, for a user with 150 direct ego links, a subgraph may include up to links, and for an active user with 5,000 friends, the ego subgraph can grow to more than 12,000,000 links.
An additional complication is the fact that the graph is stored in a distributed environment, and no node has a complete image of the graph in memory. Work on balanced graph partitioning is carried out both in the academy and in the industry, but even the most top-level results in collecting the ego subgraph lead to "all with all" communication: in order to get information about friends of friends of a user, you will have to go to all "partitions" In most cases.
One of the working alternatives in this case will be forced data duplication (for example, algorithm 3 in an article from Google ), but this duplication is also not free. Let's try to figure out what can be improved in this process.
Naive algorithm
First, consider the “naive” algorithm for generating an ego subgraph:

The algorithm assumes that the original graph is stored as an adjacency list, i.e. Information about all the friends of the user is stored in a single record with the user ID in the key and the list of friends ID in the value. In order to take the second step and get information about friends you need:
- Convert the graph to the list of edges, where each edge is a separate entry.
- Make the list of edges join on itself, which will give all the paths in a graph of length 2.
- Group by start of path.
At the output for each user, we get lists of paths of length 2 for each of the users. It should be noted here that the resulting structure is actually a two-step neighborhood of the user , while the ego subgraph is its subset. Therefore, to complete the process, we need to filter out all arcs that go outside the immediate friends.
This algorithm is good because it is implemented in two lines on Scala under Apache Spark . But the advantages end there: for a graph of industrial size, the volume of network communication is beyond the limit and the operating time is measured in days. The main difficulty is created by two shuffle operations that occur when we do join and grouping. Is it possible to reduce the amount of data sent?
Ego subgraph in one shuffle
Given that our graph of friendships is symmetrical, you can use the optimizations proposed by Tomas Schank :
- You can get all paths of length 2 without join - if Bob has friends Alice and Harry, then there are Alice-Bob-Harry and Harry-Bob-Alice paths.
- When grouping, two paths at the entrance correspond to the same new edge. The path Bob-Alice-Dave and Bob-Dave-Alice contains the same information for Bob, which means that you can send only every second path, sorting users by their ID.
After applying optimizations, the work scheme will look like this:

- At the first stage of generation, we get a list of paths of length 2 with a filter of order ID.
- On the second, we group by the first user on the way.
In this setting, the algorithm fulfills one shuffle operation, and the size of the data transmitted over the network is halved. :)
Lay out the ego subgraph in memory
An important issue that we have not yet considered is how to decompose the data in the ego of a subgraph into memory. To store the graph as a whole, we used an adjacency list. This structure is convenient for tasks where it is necessary to go through the finished graph as a whole, but it is expensive if we want to build a graph from pieces and do more subtle analytics. The ideal structure for our task should effectively perform the following operations:
- The union of two graphs obtained from different partitions.
- Getting all human friends.
- Checking whether two people are connected.
- Storage in memory without the overhead of boxing.
One of the most suitable formats for these requirements is the analogue of a sparse CSR matrix :
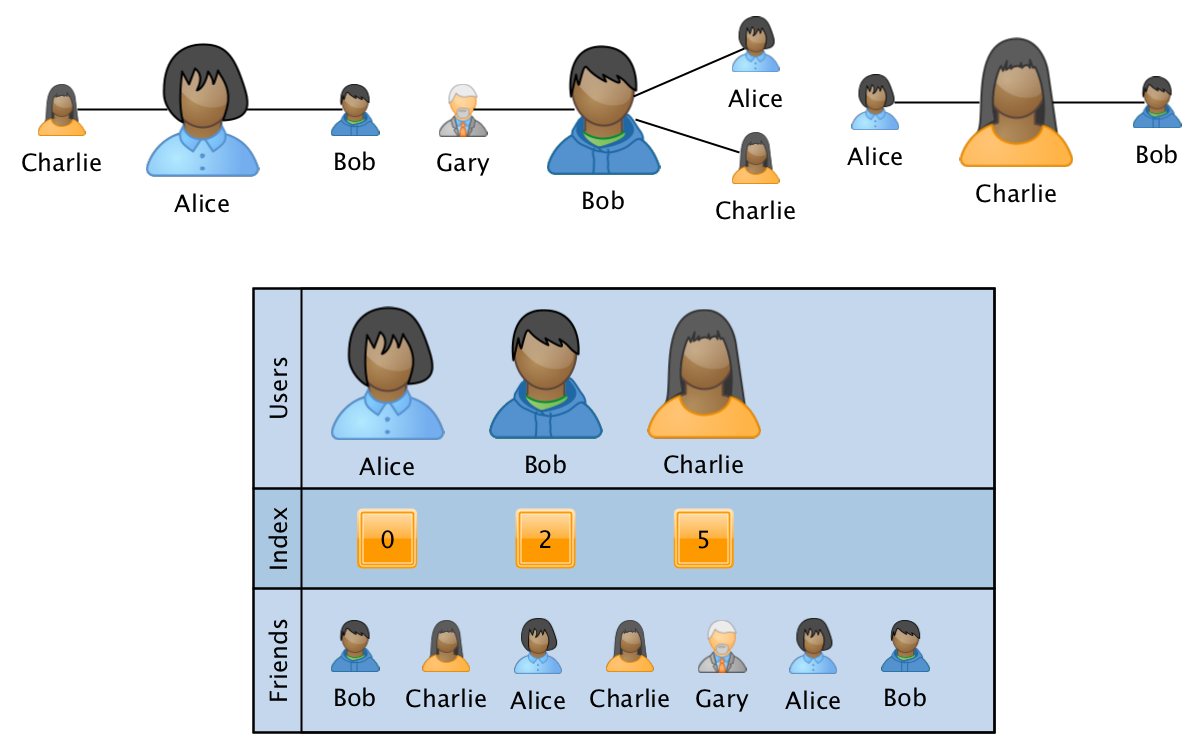
The graph in this case is stored in the form of three arrays:
- users - a sorted array with the ID of all users participating in the graph.
- index - an array of the same size as users, where for each user is stored an index-pointer to the beginning of information about user relationships in the third array.
- friends - an array of size equal to the number of edges in the graph, where the IDs of related users are sequentially shown for the corresponding IDs from users. The array is sorted for speed of processing within the information about the relationships of a single user.
In this format, the operation of merging two graphs is performed in linear time, and the operation of obtaining information on a specific user or on a pair of users per logarithm of the number of vertices. In this case, the overhead in memory does not depend on the size of the graph, since a fixed number of arrays are used. By adding a fourth data array of size equal to the size of friends, you can save additional information associated with the relationships in the graph.
Using the graph symmetry property, only half of the “upper triangular shape” arcs can be stored (when arcs are stored only from a smaller ID to a larger one), but in this case, reconstruction of all connections of an individual user will take linear time. A good compromise in this case may be an approach that uses "upper triangular" coding for storage and transfer between nodes, and symmetric coding when loading the subgraph's ego into memory for analysis.
Reduce shuffle
However, even after implementing all the optimization mentioned above, the task of constructing all ego subgraphs still works too long. In our case, about 6 hours with a high utilization of the cluster. A closer look shows that the main source of complexity is still the shuffle operation, while a significant part of the data involved in the shuffle is thrown out in the following stages. The fact is that the described approach builds a complete two-step neighborhood for each user, while the ego subgraph is only a relatively small subset of this neighborhood containing only internal arcs.
For example, if, by processing Bob's direct neighbors - Harry and Frank - we knew that they were not friends of each other, then already at the first step we could filter out such external paths. But in order to find out for all Gary and Frenkov whether they are friends, you will have to drag the friendship graph into memory at all computing nodes or make remote calls while processing each record, which, according to the conditions of the task, is impossible.
Nevertheless, there is a solution if we allow ourselves, in a small percentage of cases, to make mistakes when we find friendship where it actually does not exist. There is a whole family of probabilistic data structures that make it possible to reduce the memory consumption during data storage by an order of magnitude, while allowing a certain amount of error. The most famous structure of this kind is the Bloom filter , which for many years has been successfully used in industrial databases to compensate for cache misses on the "long tail".
The main task of the Bloom filter is to answer the question "is this element included in the many previously seen elements?" Moreover, if the filter answers “no”, then the element probably is not included in the set, but if it answers “yes” - there is a small probability that the element is still not there.
In our case, the "element" will be a pair of users, and the "set" will be all edges of the graph. Then the Bloom filter can be successfully applied to reduce the size of the shuffle:

Having prepared the Bloom filter in advance with information about the graph, we can look through Harry’s friends to find out that Bob and Ilona are not friends, which means that we don’t need to send Bob information about the connection between Gary and Ilona. However, the information that Harry and Bob are friends on their own will still have to be sent so that Bob can fully restore his graph of friendship after grouping.
Remove shuffle
After applying the filter, the amount of data sent is reduced by about 80%, and the task completes in 1 hour with a moderate cluster load, allowing you to freely perform other tasks in parallel. In this mode, it can already be taken "into operation" and put on a daily basis, but there is still potential for optimization.
Paradoxical as it may sound, the problem can be solved without resorting to shuffle, if you allow yourself a certain percentage of errors. And the Bloom filter can help us with this:

If looking through Bob’s friends list using a filter, we find out that Alice and Charlie are almost certainly friends, we can immediately add the corresponding arc to Bob’s ego subgraph. The whole process in this case will take less than 15 minutes and will not require data transmission over the network, however, a certain percentage of arcs, depending on the filter settings, may be absent in reality.
The extra arcs added by the filter do not introduce significant distortions for some tasks: for example, when counting triangles, we can easily correct the result, and when preparing attributes for machine learning algorithms, the ML correction itself can be learned in the next step.
But in some problems, extra arcs lead to a fatal deterioration in the quality of the result: for example, when searching for connected components in the ego subgraph with a remote ego (without the top of the user), the probability of a “phantom bridge” between the components grows quadratically relative to their size, which leads to that almost everywhere we get one big component.
There is an intermediate area where the negative effect of extra arcs needs to be evaluated experimentally: for example, some community search algorithms can quite successfully cope with a little noise, returning an almost identical community structure.
Instead of a conclusion
Ego user subgraphs are an important source of information that is actively used at OK to improve the quality of recommendations, refine demographics, and fight spam, but their calculation is fraught with a number of difficulties.
In the article, we examined the evolution of the approach to the task of constructing ego subgraphs for all users of a social network and were able to improve the working time from the initial 20 hours to 1 hour, and if a small percentage of errors were allowed, up to 10-15 minutes.
The three “pillars” on which the final decision is based are:
- Using the graph symmetry property and Tomas Schank algorithms.
- Efficiently store ego subgraphs using a sparse CSR matrix .
- Use a Bloom filter to reduce data transfer over the network.
Examples of how the algorithm code has evolved can be found in the Zeppelin notebook .
All Articles