機械学習とディープラーニングは、多くの投資ファンドが収入を増やすために使用する新しい効果的な戦略になりました。 この記事では、ニューラルネットワークが株式市場の状況(たとえば株価(またはインデックス)など)を予測する方法を説明します。 テキストの中心にあるのは、Pythonで書かれた私のプロジェクトです。 完全なコードとプログラムガイドはGitHubにあります。 Medium Blogの他の関連記事を読んでください。
経済学におけるニューラルネットワーク
金融分野の変化は線形ではなく、株価が完全にランダムに形成されているように見えることもあります。 ARIMAやGARCHモデルなどの従来の時系列手法は、系列が静止している場合に効果的です-その基本的な特性は時間とともに変化しません。 そして、これは
log returns
を使用してシリーズを前処理するか、別の方法で定常性に減らす必要があり
log returns
。 ただし、新しいデータを追加する際に定常性は保証されないため、これらのモデルを実際の取引システムに実装すると、主な問題が発生します。
この問題の解決策は、定常性を必要としないニューラルネットワークです。 ニューラルネットワークは、最初はデータ間の関係を見つけるのに非常に効果的であり、それらに基づいて新しいデータを予測(または分類)できます。
通常、データサイエンスプロジェクトは次の操作で構成されます。
- データ収集-必要なプロパティのセットを提供します。
- 多くの場合、データの前処理は、データを使用する前に威圧的ですが必要な手順です。
- モデルの開発と実装は、ニューラルネットワークのタイプとそのパラメーターの選択です。
- モデルのバックテスト(履歴データのテスト)は、取引戦略の重要なステップです。
- 最適化-適切なパラメーターを検索します。
ニューラルネットワークへの入力-過去10日間の株価データ。 彼らの助けを借りて、翌日価格を予測します。
データ収集
幸い、このプロジェクトに必要なデータはYahoo Financeにあります。 データは、Python API
pdr.get_yahoo_data(ticker, start_date, end_date)
使用して、またはサイトから直接収集できます。
データの前処理
私たちの場合、データは過去の10個の価格と翌日の価格で構成されるトレーニングセットに分割する必要があります。 これを行うために、トレーニングデータとテストデータで機能する
Preprocessing
クラスを定義しました。 クラス内で
get_train(self, seq_len)
を定義し
get_train(self, seq_len)
。これは、トレーニングの入力データと出力データを
NumPy
配列に変換し、特定のウィンドウ長(この場合は10)を設定します。 コード全体は次のようになります。
def gen_train(self, seq_len): """ Generates training data :param seq_len: length of window :return: X_train and Y_train """ for i in range((len(self.stock_train)//seq_len)*seq_len - seq_len - 1): x = np.array(self.stock_train.iloc[i: i + seq_len, 1]) y = np.array([self.stock_train.iloc[i + seq_len + 1, 1]], np.float64) self.input_train.append(x) self.output_train.append(y) self.X_train = np.array(self.input_train) self.Y_train = np.array(self.output_train)
同様に、テストデータ
X_test
および
Y_test
を変換するメソッドを定義しました。
ニューラルネットワークモデル
このプロジェクトでは、ニューラルネットワークの2つのモデル、多層パーセプトロン(MLP)とロングショートタームモデル(LSTM)を使用しました。 これらのモデルの仕組みについて簡単に説明します。 MLPの詳細については別の記事を 、LSTMの作業についてはJacob Aungiersの記事をご覧ください。
MLPは、ニューラルネットワークの最も単純な形式です。 入力データはモデルに分類され、特定の重みを使用して、出力データを取得するために値が非表示レイヤーを介して送信されます。 アルゴリズムの学習は、各ニューロンの重み値を変更するための隠れ層を介した逆伝播から得られます。 このモデルの問題は、「メモリ」の不足です。 以前のデータが何であったか、および新しいデータにどのように影響する可能性があり、どのように影響するかを判断することは不可能です。 モデルのコンテキストでは、2つのデータセットのデータ間の10日間の違いは重要かもしれませんが、MLPはそのような関係を分析できません。
これを行うには、LSTMまたはリカレントニューラルネットワーク(RNN)を使用します。 RNNは、後で使用するために特定のデータ情報を保存します。これは、ニューラルネットワークが株価データ間の複雑な関係構造を分析するのに役立ちます。 しかし、RNNでは、フェージング勾配の問題が発生します。 レイヤーの数が増加し、トレーニングのレベル(1未満の値)が数回乗算されるため、勾配が減少します。 効率を高めることにより、このLSTM問題を解決します。
モデルの実装
モデルを実装するために、
Keras
を使用しました。レイヤーが徐々に追加され、ネットワーク全体を一度に定義しないためです。 そのため、レイヤーの数とタイプをすばやく変更して、ニューラルネットワークを最適化できます。
株価を扱う際の重要なステップは、データの正規化です。 通常、このために平均誤差を減算し、標準誤差で除算します。 しかし、我々はこのシステムを一定期間、実際の取引で使用できるようにする必要があります。 したがって、統計を使用することは、データを正規化する最も正確な方法ではない場合があります。 そこで、すべてのデータを200に分割しました(他のすべての数値と比較して任意の数値)。 そして、そのような正規化は正当化されず、意味をなさないように見えますが、ニューラルネットワークの重みが大きくなりすぎないようにすることは効果的です。
より単純なモデル-MLPから始めましょう。 Kerasはシーケンスを作成し、その上に密なレイヤーを追加します。 完全なコードは次のようになります。
model = tf.keras.models.Sequential() model.add(tf.keras.layers.Dense(100, activation=tf.nn.relu)) model.add(tf.keras.layers.Dense(100, activation=tf.nn.relu)) model.add(tf.keras.layers.Dense(1, activation=tf.nn.relu)) model.compile(optimizer="adam", loss="mean_squared_error")
5行のコードでKerasを使用して、それぞれ100ニューロンの隠れ層を持つMLPを作成しました。 そして、オプティマイザーについて少し説明します。 Adam(適応モーメント推定)メソッドが人気を集めています- 確率的勾配降下法よりも効率的な最適化アルゴリズムです 。 確率的勾配降下法には、他にも2つの拡張機能があります。Adamの利点は、その背景にすぐに現れます。
AdaGrad-設定された学習速度を維持し、勾配が発散したときの結果を改善します(たとえば、自然言語とコンピュータービジョンの問題で)。
RMSProp-設定されたトレーニング速度を維持します。これは、重みの最近の勾配の平均値(たとえば、変化の速さ)によって異なる場合があります。 これは、アルゴリズムが非定常問題(ノイズなど)にうまく対処することを意味します。
Adamはこれらの拡張機能の利点を兼ね備えているため、私はそれを選択しました。
次に、モデルをトレーニングデータに適合させます。 Kerasはタスクを再び単純化します。次のコードのみが必要です。
model.fit(X_train, Y_train, epochs=100)
モデルの準備ができたら、テストデータでモデルをチェックし、どの程度うまく機能しているかを判断する必要があります。 これは次のように行われます。
model.evaluate(X_test, Y_test)
検証から取得した情報を使用して、モデルが株価を予測する能力を評価できます。
LSTMモデルにも同様の手順が使用されるため、コードを示して少し説明します。
model = tf.keras.Sequential() model.add(tf.keras.layers.LSTM(20, input_shape=(10, 1), return_sequences=True)) model.add(tf.keras.layers.LSTM(20)) model.add(tf.keras.layers.Dense(1, activation=tf.nn.relu)) model.compile(optimizer="adam", loss="mean_squared_error") model.fit(X_train, Y_train, epochs=50) model.evaluate(X_test, Y_test)
Kerasには、モデルに応じて特定のサイズのデータが必要であることに注意してください。 NumPyを使用して配列の形状を変更することは非常に重要です。
バックテストモデル
トレーニングデータを使用してモデルを準備し、テストデータでテストすると、履歴データでモデルをテストできます。 これは次のように行われます。
def back_test(strategy, seq_len, ticker, start_date, end_date, dim): """ A simple back test for a given date period :param strategy: the chosen strategy. Note to have already formed the model, and fitted with training data. :param seq_len: length of the days used for prediction :param ticker: company ticker :param start_date: starting date :type start_date: "YYYY-mm-dd" :param end_date: ending date :type end_date: "YYYY-mm-dd" :param dim: dimension required for strategy: 3dim for LSTM and 2dim for MLP :type dim: tuple :return: Percentage errors array that gives the errors for every test in the given date range """ data = pdr.get_data_yahoo(ticker, start_date, end_date) stock_data = data["Adj Close"] errors = [] for i in range((len(stock_data)//10)*10 - seq_len - 1): x = np.array(stock_data.iloc[i: i + seq_len, 1]).reshape(dim) / 200 y = np.array(stock_data.iloc[i + seq_len + 1, 1]) / 200 predict = strategy.predict(x) while predict == 0: predict = strategy.predict(x) error = (predict - y) / 100 errors.append(error) total_error = np.array(errors) print(f"Average error = {total_error.mean()}")
ただし、これはテストの簡易バージョンです。 完全なバックテストシステムの場合、「サバイバーシップバイアス」、バイアス(先読みバイアス)、市場状況の変化、取引コストなどの要因を考慮する必要があります。 これは単なる教育プロジェクトであるため、単純なバックテストで十分です。
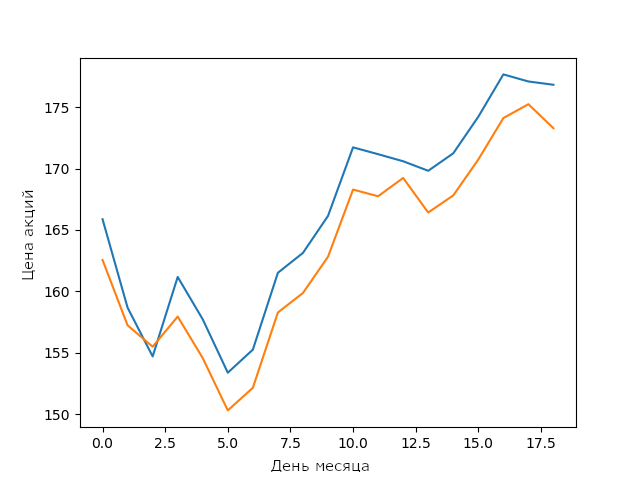
2月のApple株価に関する私のLSTMモデルの予測
最適化のない単純なLSTMモデルの場合、これは非常に良い結果です。 ニューラルネットワークと機械学習モデルが、パラメーター間の複雑で安定した接続を構築できることを示しています。
ハイパーパラメーター最適化
テスト後のモデル結果を改善するには、多くの場合、最適化が必要です。 読者が自分でモデルを最適化できるように、私はそれをオープンソースバージョンに含めませんでした。 最適化の方法を知らない人は、モデルのパフォーマンスを改善するハイパーパラメーターを見つける必要があります。 ハイパーパラメーターを見つけるには、グリッド上のパラメーターの選択から確率的手法まで、いくつかの方法があります。
モデルの最適化により、機械学習の分野での知識は新しいレベルに達すると確信しています。 私のモデルよりもうまく機能するようにモデルを最適化してください。 結果を上記のグラフと比較します。
おわりに
機械学習は常に進化しています-毎日新しい方法が登場しているため、常に学習することが非常に重要です。 これを行う最善の方法は、興味深いプロジェクトを作成することです。たとえば、株価を予測するためのモデルを作成します。 そして、私のLSTMモデルは実際の取引での使用には十分ではありませんが、そのようなモデルの開発に築かれた基盤は将来役に立つかもしれません。
編集者から
トピックに関するNetologyコース:
- データアナリストオンラインプロフェッショナル
- オンライン職業データサイエンティスト