
はじめに
プレフィックスツリーの低レベル実装を試みたという記事が公開されてから4か月が経過しました。 私のすべての努力にも関わらず、プレフィックスツリーの以前の実装が可能なことが判明した上限は、1秒あたり約8万語でした。 その後、私は多くの時間とエネルギーを費やしましたが、結果はコンピューターサイエンスの実験室作業としてのみ適しています。
多くの人が私に言った:「私たちがすでに発明した自転車を発明しないでください! ターンキーソリューションを使用してください。」 難点は、少なくとも一般的な用語では理解できないものを使用できなかったことです。
プレフィックスツリーは理解できたと思いますが、これが達成できたものです。
動作原理
私は英語をあまりよく知らないので、接頭辞ツリーのトピックについて読んだ多くの記事のうち、おそらく私に届いていない情報もありました。 そのため、プレフィックスツリーの基本原理のみを理解し、すべてを整理する方法を思いつきました。 知らない人のために、ウィキペディアに書かれているよりも明確に説明しようとします。 それで、私は自分のやっていることを妻に説明しました。
プレフィックスツリーは、図書館の書籍のカードインデックスとして表すことができるデータを格納するための論理構造です。 各ボックスには番号があります。 各ボックスは、アルファベットの特定の文字に対応しています。 内部には次の引き出しの番号があり、次の引き出しなどを見つけることができます。 ボックス内に何もない場合、これはこのボックスの文字が単語の最後であることを意味します。 問題は、1つまたは2つの数字が含まれ、残りのスペースが空であるため、一部のボックスがほとんど空のままであることです。
この問題を解決するために、HAT-trie、double-array trie、triple-array trieなど、さまざまなプレフィックスツリーが登場しました。 私が彼らの仕事の原理を完全に理解できなかったという事実は、私を図書館カードファイルのような単純な木に追いやった。
前回は、単純なプレフィックスツリーのかなり経済的なメモリ消費実装を実装できました。 この比phorをライブラリファイルキャビネットに続けて、さまざまなサイズのファイルキャビネットに引き出しを作成しました。フルアルファベットの場合はボックスが最大で、1文字の場合は最小です。
Cでまったく同じPHPスキームを実装できました。
1.確立されたテーブルに基づく単語の各文字は、2〜95の数字でエンコードされます。たとえば、単語「abv」は、11、12、13の3つの数字でエンコードされます。
uint8_t abc[256][256] = {};
変換のために、プログラムは1バイトずつ行を読み取り、配列内の各バイトの値を取得しようとします。 たとえば、数字コードは1 = 49なので、
abc[49][0];
見えます
abc[49][0];
。 「\ 0」以外の値がある場合、これはレターのコードです。覚えて、次のバイトに進みます。 この場合、「abv」という単語は6バイトのシーケンスで構成され、1文字につき2バイト:208、176、208、177、208、178。utf-8エンコーディングは、シングルバイト文字の最初のバイトがマルチバイトの最初のバイトと決して一致しないように設計されているため、配列
abc[208][0] = 0;
。
ただし、バイトペアにはいくつかの一致があります。
/* [11] */ abc[208][176] = 11; /* [12] */ abc[208][177] = 12; /* [13] */ abc[208][178] = 13;
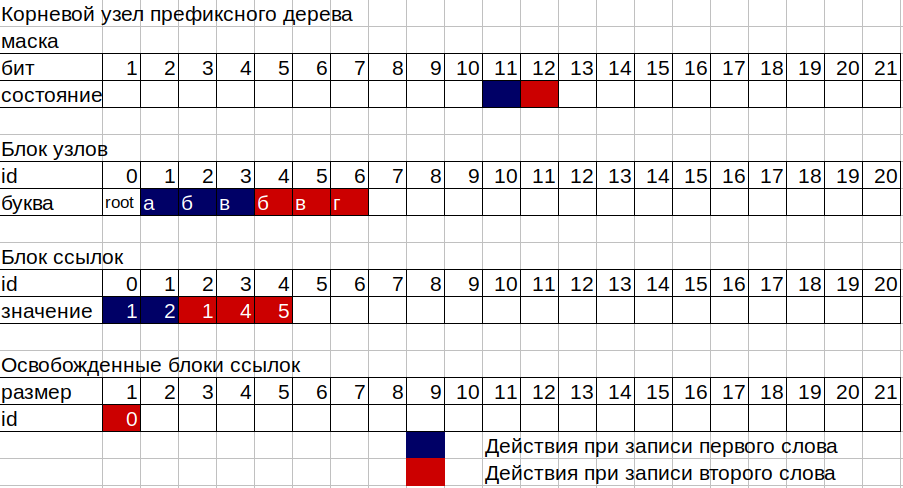
2.次に、ツリーのボックスに11、12、13の数字を書き留める必要があります。 ツリーは、2つの独立した非破壊メモリブロックで構成されます。1つ目はノードのブロック、2つ目はリンクのブロック、およびリンクブロックの占有ノードと占有セルの2つのカウンタです。 各ツリーノードは、16バイト、12バイトのビットマスク、およびリンクブロックのIDを格納する4バイトで構成されます。 マスクを使用すると、2〜96ビットの数値を保存できます。 マスクの最初のビットは、このノードの単語の終わりを示すために使用されます。 このノードに少なくとも1文字が書き込まれている場合、各ノードはリンクブロックのIDに対応できます。または、ノードがツリーの「葉」である場合、つまり単語が単に終わる場合は対応しません。 ライブラリで表現された、空の引き出し。
3.最初の(ルート)ノードのマスクを取得します。 trie-> nodes [0] .mask; このマスクで発生したビットを、2番目(単語の終わりのフラグの最初)からカウントします。 マスク内のビットが発生しない場合、つまり ノードは空なので、番号11を格納するためにサイズ1のリンクブロックが必要です。ブロックのリンク参照カウンターから番号を取得し、古い値を1つ増やします(サイズ1が必要なため)。 ノードカウンターから数値を取得し、古い値を1増やします。ルートブロックにリンクブロックのidを書き込みます。これは、リンクブロックのカウンターから取得した数値です。 そして、このリンクブロックのIDに、新しいノードのID、つまりノードカウンターから取得した番号を書き込みます。 これで、ルートノード(id 0)に加えて、文字「a」(id 1)のノードができました。 文字「b」に対応する番号12を書き込むには、文字「a」のノードを使用して同じ操作を行います。
4.最後の文字「c」では、ブランチまたはノード-リーフの最後のノードがあるため、リンクブロック内の場所は必要ありません。 このようなノードでは、マスクの1ビットのみが発生します。
5.ツリーの作業の最も難しい部分は、いくつかの文字がすでに書き込まれているノードで記録が行われるときに発生します。 この場合、操作スキームは次のとおりです。
単語「bvg」(12、13、14)をツリーに追加するとします。このツリーには、単語「abv」(11、12、13)がすでに書き込まれています。 ルートノードのマスクのビットを、関心のある文字のビットにカウントします。 コード「12」の文字「b」があります。これは、文字「a」のビット11が1から12ビットまでのマスクで既にこの文字のビットが12であることを意味します。 ルートノード1の現在のリンクブロックサイズがあります。2番目の文字を書くので、サイズ2のリンクブロックが必要になります。ここで、解放されたブロックのレジストリが機能します。リンクブロック内のセクションのIDとサイズはノードによって使用されなくなりますツリー。 ルートノードには大きなサイズが必要なため、サイズ1のルートノードの古いリンクブロックIDは、サイズ1の空きセクションのレジストリに入ります。 レジストリにはサイズ2の適切なセクションがなく、リンクブロックのカウンターから値をリンクブロックの新しいIDとして再度取得し、カウンターを2増やします。ノードのマスクにビットが配置されているのと同じ順序でリンクブロックの新しいアドレスに、ID値を書き込みます最初の単語の文字「a」の古いリンクブロックからのノードと、2番目の単語の文字「b」の作成されたばかりのノードの意味。
作業速度
ドラムロールが鳴ります...最後の結果を覚えていますか? 1秒あたり約8万語。 ツリーは、すべてのロシア語の単語OpenCorpora 3 039 982単語の辞書から作成されました。 そして、これが今起こったことです:
yatrie creation time: 4.588216s (666k wps) yatrie search time 1 mln. rounds: 0.565618s (1.76m wps)
更新2018年11月1日:
バージョン0.0.2では、本格的な関数をマクロ関数に置き換え、ノードマスクの構造をuint32_tマスク[3]、以前はuint8_tマスク[12]に変更することにより、速度をほぼ2倍に上げることができました。
また、可能であれば、if()ブロックで期待される結果を予測するためのマクロLIKELY()UNLIKELY()を追加しました。
更新2018年5月11日:
もう少しひねりました。 -O3と-Ofastをコンパイルするときでもうまく動作しました。 ツリーの検索速度は、約0.2μsまたは100万回の繰り返しごとに0.2cです。 マスクの異なるフォーマットへの移行により、この速度が得られたようです。 以前は、8ビットの12バイトがあり、現在は3つのint32と、int32のビットをカウントするための非常に高速な関数がありました。
これはどれくらいコンパクトですか?
指定されたOpenCorporaディクショナリは〜84MBを必要とし、これは〜80MBを提供するlibdatrieよりもそれほど悪くありません。
→ ソースコード
ようこそ