ネタバレ
| クリックハウス | ドルイドまたはピノ |
|---|---|
| 組織にはC ++の専門家がいます | 組織にはJavaの専門家がいます |
| 小さなクラスター | 大規模なクラスター |
| いくつかのテーブル | 多くのテーブル |
| 1つのデータセット | 複数の無関係なデータセット |
| テーブルとデータは永続的にクラスター内にあります | テーブルとデータセットはクラスターに定期的に表示され、クラスターから削除されます。 |
| テーブルのサイズ(およびテーブルへのクエリの強度)は、長期にわたって安定したままです。 | テーブルの大幅な拡大と縮小 |
| 同種のリクエスト(タイプ、サイズ、時刻ごとの分布など) | 異種のリクエスト |
| データにはセグメント化できるディメンションがあり、いくつかのセグメントにあるデータに影響するクエリはほとんどありません。 | そのようなディメンションはなく、クエリは多くの場合、クラスタ全体にあるデータに影響します。 |
| クラウドは使用されません。クラスターは物理サーバーの特定の構成に展開する必要があります | クラウドにデプロイされたクラスター |
| 既存のHadoopまたはSparkクラスターはありません | HadoopまたはSparkクラスターは既に存在し、使用できます |
情報源
ClickHouseの実装の詳細は、プロジェクトの主要な開発者の 1人であるAlexei Zatelepinから知っています。 英語版のドキュメントはほとんどありません。 このドキュメントページの最後の4つのセクションは、最良の情報源です。
私自身はドルイドの開発に関わっていますが、このシステムには個人的な関心はありません。実際、近い将来、開発をやめるでしょう。 したがって、読者はバイアスがないことを期待できます。
Pinotについて書き続けるものはすべて、Pinot wikiのArchitectureページと、「Design Documentation」セクションの他のwikiページに基づいています。 2017年6月に最後に更新されたのは、半年以上前です。
元の記事の校閲者は、アレクセイ・ザテレピンとビタリー・ルドヴィチェンコ ( ClickHouseの開発者)、 ジャン・メルリーノ (ドルイドの最も活発な開発者)、 キショア・ゴパラクリシュナ (ピノの建築家)、 ジャン・フランソワ・イム (ピノの開発者)でした。 私たちは著者の感謝に加わり、これが記事の信頼性を大いに高めると信じています。
警告 :記事は十分に大きいので、最後に「結論」セクションを読むように制限することをお勧めします。
システム間の類似性
関連データとコンピューティング
基本的なレベルでは、ClickHouse、Druid、およびPinotはデータを保存し、同じノードにリクエストを処理し、「切断された」BigQueryアーキテクチャから遠ざかるという点で似ています。 最近、Druidの場合に関連するアーキテクチャに関するいくつかの継承された問題をすでに説明しました[ 1、2 ]。 現在、BigQueryに相当するものは存在しません(ただし、 Drillの例外は可能ですか?)。 このようなオープンシステムを構築するための可能なアプローチについては、私のブログの別の記事で説明しています。
ビッグデータSQLシステムとの違い:インデックスと静的データの分布
この記事で説明するシステムは、Hive、Impala、Presto、SparkなどのSQL-on-Hadoopファミリーのビッグデータシステムよりも高速にクエリを実行します。後者は、ParquetやKuduなどの列形式で保存されたデータにアクセスする場合でも同様です。 これは、ClickHouse、Druid、およびPinotで次の理由があります。
- インデックス付きのデータを保存する独自の形式があり 、クエリ処理エンジンと密接に統合されています。 SQL-on-Hadoopクラスのシステムは、通常、データ形式に関して不可知論と呼ばれることがあるため、ビッグデータバックエンドでは「侵入的」ではありません。
- データはノード間で比較的「静的に」分散され、分散クエリの実行ではこれを使用できます。 コインの裏返しは、ClickHouse、Druid、およびPinot は 、ノード間で大量のデータを移動する必要がある クエリ を サポートしていない ことです -たとえば、2つの大きなテーブル間で結合します。
ポイントの更新と削除の欠如
データベーススペクトルの反対側では、ClickHouse、Druid、およびPinot は 、Kudu、InfluxDB、Vertica(?)などのカラムシステムとは異なり、 ポイントの更新と削除をサポートしていません 。 これにより、ClickHouse、Druid、およびPinotは、より効率的な列圧縮とより積極的なインデックスを作成できるようになります。これは、リソース使用率の向上とクエリ実行の高速化を意味します。
Yandex ClickHouse開発者は、将来的に更新と削除のサポートを開始する予定ですが、これらが「実際の」ポイントクエリか、データ範囲の更新/削除かどうかはわかりません。
ビッグデータ吸収
3つのシステムはすべて、Kafkaからのストリーミングデータの吸収をサポートしています。 ドルイドとピノは、 ラムダスタイルのストリーミングデータと同じデータのバッチ吸収をサポートしています。 ClickHouseはバッチ挿入を直接サポートしているため、DruidやPinotで使用されているような個別のバッチ吸収システムは必要ありません。 詳細に興味がある場合は、さらに詳細を見つけることができます。
大規模にテスト済み
3つのシステムはすべて、大規模に操作性がテストされています。Yandex.Metricaには、約1万個のCPUコアで構成されるClickHouseクラスターがあります。 Metamarketsは、同様のサイズのDruidクラスターを使用します 。 1つのLinkedot Pinotクラスターには、 数千のマシンが含まれています。
未熟
この記事で説明するすべてのシステムは、 オープンビッグデータエンタープライズシステムの標準では未熟です 。 しかし、おそらく、彼らは平均的なオープンビッグデータシステムよりも未熟ではありませんが、これはまったく別の話です。 ClickHouse、Druid、およびPinotには明らかな最適化と機能がいくつか欠けており、バグがたくさんあります(ClickHouseとPinotについては、100%確信はありませんが、この点でDruidよりも優れている理由はわかりません)。
これにより、次の重要なセクションにスムーズに進みます。
パフォーマンスの比較とシステムの選択について
ビッグデータシステムの比較を行う人々をネット上で定期的に確認します。彼らはデータのセットを取得し、評価中のシステムに何らかの方法で「フィード」し、すぐにパフォーマンス(使用されるメモリまたはディスクスペースの量、実行速度)を測定しようとしますお問い合わせ。 さらに、テストするシステムが内部からどのように配置されているかについても理解していません。 次に、そのような特定のパフォーマンスデータのみを使用し、必要な機能のリストと現在システムにある機能のリストを使用する場合があります。ゼロ。
このアプローチは間違っているように思われますが、少なくともビッグデータ向けのオープンOLAPシステムには適用されません。 ほとんどのユースケースで効率的に動作し、必要な機能をすべて備えた入札データOLAPシステムを作成するタスクは非常に大きいため、少なくとも100人年の実装を評価しています。
現在、ClickHouse、Druid、およびPinotは、開発者が必要とする特定の使用シナリオに対してのみ最適化されており、ほとんどの場合、開発者自身が必要とする機能のみが含まれています。 検討中のOLAPシステムの開発者がまだ遭遇していないボトルネックや、関心のない場所に確実に「実行」されることを保証できます。
上記の「何も知らないシステムにデータを投入し、その有効性を測定する」というアプローチは言うまでもありませんが、実際には深刻な「ボトルネック」が原因で歪んだ結果をもたらす可能性が非常に高くなります簡単な構成変更 、データスキーマ、またはその他のクエリ構築によって修正されました。
CloudFlare:ClickHouseとDruid
上記の問題をよく示しているこのような例の1つは、CloudHoreのClickHouseとDruidの選択に関するMarek Wawrushの投稿です 。 4つのClickHouseサーバー(最終的には9台になりました)が必要でしたが、同様のDruidインストールを展開するには「数百のノード」が必要になると見積もっていました。 Marekは比較が不公平であることを認めていますが 、Druidには「主キーによるソート」がないため、「 摂取仕様 」で正しい測定順序を設定し、簡単な準備をするだけで、Druidでほぼ同じ効果が得られることさえ理解できないかもしれませんdata:Druidの
__time
列の値を粗い詳細(1時間など)にトリムし、クエリがより正確な時間枠を必要とする場合は、オプションで別の「long-type」列「precise_time」を追加します。 はい、これはハックですが、たった今わかったように、Druidでは
__time
前に何らかの次元でデータをソートでき、実装は非常に簡単です。
ただし、ClickHouseを選択する最終決定については議論しません。なぜなら、約10ノードの規模とそのニーズのために、ClickHouseもDruidよりも良い選択だと思われるからです。 しかし、ClickHouseは(インフラストラクチャコストの基準で)ドルイドよりも少なくとも1桁効率的であるという彼らの結論は、重大な誤解です。 実際、今日検討しているシステムから、 Druidは本当に安価なインストールに最適な機会を提供します (以下の「Druidでの要求処理ノードのレベル」のセクションを参照)。
OLAPビッグデータシステムを選択する場合、現在のケースにどれだけ適しているかを比較しないでください。 現在、それらはすべて最適ではありません。 代わりに、これらのシステムをあなたに合った方向に動かすことができる速度を比較してください。
基本的なアーキテクチャ上の類似性により、ClickHouse、Druid、およびPinotは、効率とパフォーマンスの最適化に関してほぼ同じ「制限」を共有しています。 これらのシステムを他のシステムよりも高速にする「魔法の薬」はありません。 現在の状態では、システムがベンチマークごとに非常に異なって表示されるという事実に戸惑うことはありません。
DruidがClickHouseと同様に「主キーによるソート」をサポートしていないと仮定します。ClickHouseは、「逆索引」とDruidをサポートしていないため、これらのシステムに何らかの負荷をかける利点があります。 失われた最適化は 、 そのようなステップを決定する意思と能力があれば、 それほど 労力 をかけずに選択したシステムに実装できます 。
- 組織には、選択したシステムのソースコードを読み取り、理解し、変更できるエンジニアが必要です。また、このための時間も必要です。 ClickHouseはC ++で記述され、DruidとPinotはJavaで記述されていることに注意してください。
- または、選択したシステムのサポートを提供する会社と組織が契約に署名する必要があります。 これらは、 ClickHouseのAltinity、DruidのImplyおよびHortonworksになります。 現在、ピノにはそのような会社はありません。
考慮すべきその他のシステム設計情報:
- Yandexで働いているClickHouseの著者は、自分の時間の50%を社内で必要な機能の作成に費やし、さらに50%がほとんどの「コミュニティの声」が獲得する機能に費やしていると主張しています。 ただし、この事実から利点を得るためには、 ClickHouse コミュニティ が 最も必要とする機能を 要求する 必要があり ます 。
- ImplyのDruid開発者は、一般的に使用される機能に取り組む意欲があります。これにより、将来的にビジネスの範囲を最大限に広げることができます。
- Druidの開発プロセスはApacheソフトウェアと非常によく似ており、ソフトウェアは数年前からいくつかの企業によって開発されており、各企業はどちらかというと独特で異なる優先順位を持ち、その中にリーディングカンパニーはありません。 ClickHouseとPinotは、YandexとLinkedinだけがそれぞれに関与しているため、まだ同様の段階からはほど遠いです。 Druidの開発へのサードパーティの貢献は、主な開発者のビジョンとは異なるという事実により拒否される可能性が最小限です。結局のところ、Druidには「主な」開発会社はありません 。
- Druidは「Developer API」をサポートします。これにより、独自の列タイプ、集約メカニズム、「deep storage」などの可能なオプションなどを提供できます。これらはすべて、Druidコア自体とは別のコードベースに保持できます。 このAPIは、Druid開発者によって文書化されており、以前のバージョンとの互換性を監視しています。 ただし、それは「成熟」ではなく、Druidのほぼすべての新しいリリースで中断します。 私の知る限り、同様のAPIはClickHouseとPinotではサポートされていません。
- Githubによると、 最も多くの人がPinotに取り組んでいます。明らかに、昨年、 少なくとも10人年がPinotに投資されたようです。 ClickHouseの場合、この数値は約6人年、Druid-7の場合です。理論上、これはPinotが検討している他のすべてのシステムよりも速く改善することを意味するはずです。
ドルイドとピノのアーキテクチャはほぼ同じですが、クリックハウスはわずかに離れています。 したがって、まずClickHouseを「一般化された」Druid / Pinotアーキテクチャと比較してから、DruidとPinotのわずかな違いについて説明します。
ClickHouseとDruid / Pinotの違い
データ管理:ドルイドとピノ
DruidとPinotでは、各「テーブル」内のすべてのデータ(これらのシステムの用語でどのように呼ばれているかに関係なく)は、指定された数のパーツに分割されます。 時間軸では、データは通常、所定の間隔で分割されます。 次に、これらのデータは「セグメント」と呼ばれる独立した独立したエンティティに個別に「封印」されます。 各セグメントには、テーブルメタデータ、圧縮列データ、およびインデックスが含まれます。
セグメントは「ディープストレージ」ストレージ(たとえば、HDFS)のファイルシステムに格納され、リクエスト処理ノードにアップロードできますが、後者はセグメントの安定性に責任を負わないため、リクエスト処理ノードは比較的自由に交換できます。 セグメントは特定のノードに固定されておらず 、これらのノードまたは他のノードにロードできます。 専用サーバー(Druidでは「コーディネーター」、Pinotでは「コントローラー」と呼ばれますが、以下では「ウィザード」と呼びます)は、必要に応じてノードにセグメントを割り当て、ノード間でセグメントを移動します。
これは私が上で述べたことと矛盾しません、セグメントをロードしてそれらをドルイドで移動する-そして私がピノで理解しているように-3つのシステムはすべてノード間でデータを静的に分散しているため、個々のキューに対して実行されませんが、発生しますが、通常、数分/時間/日ごと。
セグメントのメタデータは、ZooKeeperに保存されます-Druidの場合は直接、PinotのHelixフレームワークを使用します。 Druidでは、メタデータもSQLデータベースに保存されます。詳細については、「DruidとPinotの違い」セクションを参照してください。
データ管理:ClickHouse
ClickHouseには、特定の時間範囲内のデータを含む「セグメント」はありません。 その中にデータ用の「深いストレージ」はありません。ClickHouseクラスター内のノードは、リクエストの処理、およびそれらに保存されたデータの永続性/安定性も担当します。 したがって、 HDFSやAmazon S3のようなクラウドストレージは必要ありません 。
ClickHouseには、指定されたノードのセットで構成されるパーティションテーブルがあります。 「中央機関」またはメタデータサーバーはありません。 特定のテーブルが分割されるすべてのノードには、このテーブルのセクションが格納される他のすべてのノードのアドレスを含む、メタデータの完全で同一のコピーが含まれます。
パーティションテーブルのメタデータには、新たに記録されたデータを配布するためのノードの「重み」が含まれます。たとえば、データの40%がノードAに、30%がノードBに、30%がCになります。通常、このように均等に「スキュー」する必要がありますたとえば、パーティションテーブルに新しいノードを追加する場合にのみ必要であり、いくつかのデータをすばやく入力する必要があります。 これらの重みの更新は、ClickHouseクラスターの管理者が手動で実行するか、ClickHouseの上に構築された自動システムで実行する必要があります。
データ管理:比較
ClickHouseでデータを管理する方法は、DruidやPinotよりも簡単です。「ディープストレージ」は不要で、1種類のノードのみ、データ管理専用サーバーは不要です。 しかし、ClickHouseアプローチでは、データテーブルが非常に大きくなり、10以上のノードに分割する必要がある場合、いくつかの困難が生じます。クエリゲインは、小さなデータ間隔をカバーするクエリでも、パーティション化係数と同じになります。
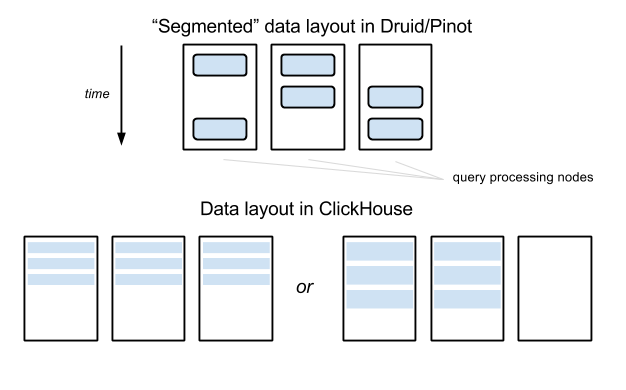
ClickHouseデータ配布の侵害
上の画像に示されている例では、テーブルデータはDruid / Pinotの3つのノードに分散されていますが、通常、小さなデータ間隔のクエリはそのうちの2つだけに影響します(間隔がセグメント境界間隔を超えるまで)。 ClickHouseでは、テーブルが3つのノード間でセグメント化されている場合、クエリは3つのノードに影響を与えます。 この例では、違いはさほど重要ではありませんが、ノード数が100に達した場合にどうなるかを想像してください。セグメンテーションファクターは、たとえばDruid / Pinotで10に等しい場合があります。
この問題を緩和するために、Yandexで最大の数百のノードで構成されるClickHouseクラスターは、実際には、それぞれ数十のノードを持つ多数の「サブクラスター」に分割されます。 ClickHouseクラスターは、Webサイト分析を操作するために使用され、各データポイントには「WebサイトID」ディメンションがあります。 各サイトIDは特定のサブクラスターに厳格にバインドされており、このサイトIDのすべてのデータが送信されます。 ClickHouseクラスターの上部には、データキャプチャおよびクエリ実行中にこのデータ共有を管理するビジネスロジックレイヤーがあります。 幸いなことに、それらの使用シナリオでは、いくつかのサイト識別子に影響を与えるリクエストはほとんどなく、そのようなリクエストはサービスのユーザーによって送信されないため、サービスレベル契約に従ってリアルタイムへのハードリンクはありません。
ClickHouseアプローチのもう1つの欠点は、クラスターが非常に速く成長すると、分割テーブル内のノードの「重み」を手動で変更する人が参加しない限り、データを自動的に再調整できないことです。
ドルイド要求処理ノードレベル
「想像しやすい」セグメントでデータを管理します。この概念は認知能力によく適合します。 セグメント自体は、ノード間で比較的簡単に再配置できます。 これら2つの理由により、Druidはクエリ処理に関連するノードの「 レベリング 」を実装できました。古いデータは比較的大きなディスクを備えたサーバーに自動的に転送されますが、メモリとCPUは少なく、古いデータ。
この機能により、Metamarketsは「フラット」クラスターを使用するのではなく、毎月数十万ドルのDruidインフラストラクチャコストを節約できます。
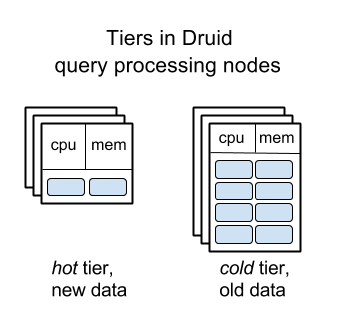
ドルイド要求処理ノードレベル
私の知る限り、ClickHouseとPinotにはまだ同様の機能はありません。クラスター内のすべてのノードが同じであると想定されています。
ピノのアーキテクチャはドルイドのアーキテクチャに非常に似ているという事実のため、ピノに同様の機能を追加することはそれほど難しくないように思えます。 ClickHouseの場合は、「セグメント」の概念がこの機能の実装に非常に役立つため、より困難になりますが、それでも可能です。
データ複製:ドルイドとピノ
ドルイドとピノの複製ユニットは単一のセグメントです。 セグメントは「ディープストレージ」レベル(たとえば、HDFSの3つのレプリカに、またはAmazon S3のBLOBストレージを使用して)、リクエスト処理レベルでレプリケートされます。通常、DruidとPinotで、各セグメントは2つの異なるノードにロードされます。 「マスター」サーバーは、各セグメントの複製レベルを監視し、複製係数が指定レベルを下回った場合(たとえば、ノードのいずれかが応答しなくなった場合)、セグメントをサーバーにアップロードします。
データ複製:ClickHouse
ClickHouseのレプリケーションユニットは、サーバー上のテーブルのセクションです(たとえば、サーバーに格納されているテーブルのすべてのデータ)。 パーティション化と同様に、ClickHouseレプリケーションは「クラウドスタイル」よりも「静的で特定」です。複数のサーバーは互いのレプリカであることを認識しています(特定のテーブルの場合。別のテーブルの場合、レプリケーション構成は異なる場合があります)。 レプリケーションは、復元力とクエリの可用性の両方を提供します。 1つのノードでディスクが破損しても、データは別のノードに保存されるため、データは失われません。 ノードが一時的に利用できない場合、リクエストをレプリカにリダイレクトできます。
Yandexの最大のClickHouseクラスターでは、異なるデータセンターに2つの同一のノードセットがあり、それらはペアになっています。 各ペアでは、ノードは互いのレプリカであり(複製係数2が使用されます)、異なるデータセンターに配置されています。
ClickHouseは、ZooKeeperに依存してレプリケーションを管理します。したがって、レプリケーションが必要ない場合は、ZooKeeperも必要ありません。 つまり、単一ノードにデプロイされたClickHouseにはZooKeeperは必要ありません。
データ吸収:ドルイドとピノ
DruidとPinotでは、クエリ処理ノードはセグメントの読み込みとセグメントでのデータ要求の処理に特化しています。 新しいデータを蓄積したり、新しいセグメントを作成したりすることはありません。
1時間以上の遅延でテーブルを更新できる場合、HadoopやSparkなどのバッチ処理エンジンを使用してセグメントが作成されます。 ドルイドとピノの両方は、箱から出してすぐに最高のHadoopをサポートします。 SparkにはDruidインデックス作成をサポートするサードパーティのプラグインがありますが、現時点では公式にはサポートされていません。 私の知る限り、PinotにはそのようなレベルのSparkサポートはありません。つまり、Pinotのインターフェースとコードを処理し、Java / Scalaコードを自分で記述する準備をする必要がありますが、これはあまり複雑ではありません。 (ただし、元の記事が公開されて以来、PinotのSparkサポートは寄稿者によって提供されています )。
テーブルをリアルタイムで更新する必要がある場合、次の3つのことを行う「リアルタイム」ノードのアイデアが役立ちます。Kafkaから新しいデータを受信し(Druidは他のソースもサポートします)、最近のデータでリクエストを処理し、バックグラウンドでセグメントを作成してから書き込みます「深い金庫室」で。
データ吸収:ClickHouse
ClickHouseは、すべてのデータを含み、指定された時間間隔内に収まる「セグメント」を準備する必要がないという事実により、より単純なデータ吸収アーキテクチャを構築できます。 ClickHouseは、Hadoopやリアルタイムノードなどのバッチ処理エンジンを必要としません。 通常のClickHouseノード(データを保存し、それらにリクエストを提供するものと同じノード)は、バッチデータレコードを直接受け入れます。
テーブルがセグメント化されている場合、パケットレコード(たとえば、1万行)を受信するノードは、「重み」に従ってデータを分散します(以下のセクションを参照)。 行は1つのパケットに書き込まれ、小さな「セット」を形成します。 多くはすぐに列形式に変換されました。 各ClickHouseホストは、行セットをさらに大きなセットに結合するバックグラウンドプロセスを実行します。 ClickHouseのドキュメントは、「MergeTree」と呼ばれる原則に強く結びついており、 LSMツリーとの作業の類似性を強調していますが、データはツリーに整理されていないため、少し気になります。
データ吸収:比較
ドルイドとピノのデータ吸収は「困難」です。複数の異なるサービスで構成されており、それらの管理は大変な作業です。
ClickHouseでのデータの吸収ははるかに簡単です(「履歴」データの管理の複雑さ、つまりリアルタイムではないデータで相殺されます)が、ここに1つのポイントがあります。ClickHouse自体までデータをパッケージに収集できる必要があります。 Kafkaからの自動吸収およびバッチデータ収集は「そのまま」利用できますが、異なるデータソースをリアルタイムで使用する場合(ここでは、クエリインフラストラクチャ、Kafkaの代替、ストリーミング処理エンジン、さまざまなHTTPエンドポイント)、パッケージを収集するための中間サービスを作成するか、ClickHouseにコードを直接入力する必要があります。
クエリ実行
ドルイドとピノには、システムへのすべてのリクエストを受け入れる「 ブローカー 」と呼ばれるノードの別個の層があります。 それらは、セグメントがロードされるノードへのセグメントのマッピングに基づいて、どの「履歴」( 非リアルタイムデータを含む )クエリ処理ノードのサブクエリを送信するかを決定します。 ブローカーはディスプレイ情報をメモリに保存します。 ブローカーノードはさらにサブクエリを送信して処理ノードを要求し、これらのサブクエリの結果が返されると、ブローカーはそれらを結合し、最終的な結合結果をユーザーに返します。
ドルイドとピノの設計中に、別のタイプのノードを導入することが決定された理由を推測することはできません。 , , , , . — . , Druid Pinot «» .
ClickHouse « » . , «» ClickHouse, , , - Druid Pinot. , , « » ClickHouse. , .
( ClickHouse, - Druid Pinot) , - , ClickHouse Pinot : , . Druid : , .
ClickHouse vs. Druid Pinot:
«» Druid Pinot ClickHouse . , , ( ) (, ), .
ClickHouse RDMBS, , PostgreSQL. , ClickHouse . — , 100 CPU 1 TB , , ClickHouse Druid Pinot , «», « », «». , ClickHouse InfluxDB, Druid Pinot.
Druid and Pinot Big Data HBase. , ZooKeper, ( , HDFS), , , . , ClickHouse, Druid Pinot . , , , .. « ».
-, . , . . , : , .
| ClickHouse | Druid Pinot |
|---|---|
| C++ | Java |
| ( ) | |
| ( , , ..) | |
| , , , , | , , |
| , | |
| Hadoop Spark | Hadoop Spark |
: , (), . , , , , Druid Pinot, ClickHouse. , Druid Pinot , ClickHouse, .
Druid Pinot
, Druid Pinot . , , , . , , , , .
Druid Pinot , , — -. , , «» «» — , .
Druid
- Druid ( Pinot) , , . ZooKeeper. , Druid SQL , Druid. , , :
- ZooKeeper . , , , ZooKeeper. , , , , .. — SQL .
- , ( — ClickHouse, Druid, Pinot), ZooKeeper, « » SQL. , «» , .
- , Druid ZooKeeper . ZooKeeper : , (, ). Consul . HTTP- , , ZooKeeper «» SQL.
SQL, , , - SQL. Druid MySQL PostgreSQL, Microsoft SQL Server. , Druid , RDBMS — , Amazon RDS.
Pinot
Druid, Curator ZooKeeper, Pinot Helix .
, , Pinot . Helix , Druid, , , .
, Helix Pinot « ». Helix, , Pinot, ZooKeeper .
Druid Pinot — , , .
« » Pinot
Kafka - , Pinot , , , - , .
« predicate pushdown » .
Druid , Hadoop, , . Druid « » .
«» Druid Pinot
Druid , «»:
- HDFS, Cassandra, Amazon S3, Google Cloud Storage Azure Blob Storage .. « »;
- Kafka, r RabbitMQ, Samza, Flink, Spark, Storm, .. ( Tranquility ) ;
- Druid, Graphite, Ambari, StatsD, Kafka «» Druid ().
Pinot LinkedIn , , , . « » HDFS Amazon S3, Kafka. - , , Pinot. , , Uber Slack Pinot.
Pinot
, Pinot Druid:
- , Druid.
- . Druid , , . Druid Pinot, Uber , .
- .
- . Druid ( «CloudFlare: ClickHouse Druid»). , Pinot — Druid Pinot ( !), Uber.
- , , Pinot, Druid.
, Druid. , Pinot , Druid, , . : Pinot ( Druid) ( Zstd) Gorilla .
Uber count (*) Druid Pinot [ 1 , 2 ], Druid , O(1) . « », .
,
GROUP BY,
Uber, Druid, .
Druid ()
Pinot , , . Druid ; , , , . Metamarkets 30–40% . , , - — .
, LinkedIn Pinot, , , , .
Pinot
« », - , , Pinot - .
Druid .
Druid
. Druid , «» « CPU, RAM / » , .
, Pinot .
おわりに
ClickHouse, Druid Pinot , Big Data- Impala, Presto, Spark, , , InfluxDB.
, ClickHouse, Druid Pinot « ». , . ( ) - .
— , , , .
, ClickHouse Druid Pinot — Druid Pinot , .
ClickHouse «» PostgreSQL. ClickHouse . ( 1 TB , 100 CPU), ClickHouse , Druid Pinot — — , ClickHouse . , InfluxDB Prometheus, Druid Pinot.
Druid Pinot Big Data Hadoop. «» ( 500 ), ClickHouse SRE. , Druid Pinot , , ClickHouse.
Druid Pinot , Pinot Helix ZooKeeper, Druid ZooKeeper. , Druid - SQL- . , Pinot , Druid.
, : ( ) . , , . ( 9 ) ++ : , , . , — , .