ファイルシステムを含むパーティションのイメージ構造。 パート2
パート1で公開を開始します。
目次
続行するには...
5.結論。
6.情報源。
パート2
3.2._sparsechunkファイル。
3.2.1。_sparsechunkファイルの構造。
3.2.2。_sparsechunkファイルの使用例。
4. datファイルの作成。
4.1.Datファイルの構造
4.1.1。transfer_listファイルの構造。
4.1.2。new_dataファイルの構造。
4.1.3。patch_dataファイルの構造。
4.2。データ構造の説明。
4.2.1。情報ブロックの範囲の説明の構造(範囲のセット[rangeset])
4.2.2スタッシュ範囲構造(stash_rangeset)
4.2.3入力データセットの構造<...>
4.3。transfer_listファイルコマンドの構造と説明。
4.3.1。コマンド「erase」、「new」、「zero」
4.3.2。「移動」コマンド
4.3.3。bsdiffおよびimgdiffコマンド
4.3.4。隠しコマンド
4.3.5。「無料」コマンド
3.2.1。_sparsechunkファイルの構造。
3.2.2。_sparsechunkファイルの使用例。
4. datファイルの作成。
4.1.Datファイルの構造
4.1.1。transfer_listファイルの構造。
4.1.2。new_dataファイルの構造。
4.1.3。patch_dataファイルの構造。
4.2。データ構造の説明。
4.2.1。情報ブロックの範囲の説明の構造(範囲のセット[rangeset])
4.2.2スタッシュ範囲構造(stash_rangeset)
4.2.3入力データセットの構造<...>
4.3。transfer_listファイルコマンドの構造と説明。
4.3.1。コマンド「erase」、「new」、「zero」
4.3.2。「移動」コマンド
4.3.3。bsdiffおよびimgdiffコマンド
4.3.4。隠しコマンド
4.3.5。「無料」コマンド
続行するには...
パート3
4.4。datファイルの使用例。
5.結論。
6.情報源。
3.2._sparsechunkファイル
なぜなら スパースファイルは圧縮されたソースデータファイルですが、非常に大きくなる場合があり、その変更は_sparsechunkのようなファイルと呼ばれます。境界線(ファイル切断アルゴリズムによる)。
このアドオンを使用すると、圧縮されたスパースファイルを使用して、OTA経由で更新を送信したり、 fastbootモードでダウンロードしたりできます。
3.2.1 _sparsechunkファイルの構造
構造上、 _sparsechunkタイプの各ファイルは通常のスパースファイルですが、パーティションイメージなど、入力ファイルのすべてではなく一部のみが含まれています。 圧縮状態でのこの部分のサイズ、つまり 疎ビューでは、事前に定義された値または境界を超えてはなりません。 現在、 _sparsechunkファイルのサイズの「境界」は通常256MB( 268,435,456バイト)です。
スパースファイルの次の部分は、次の_sparsechunkファイルなどに含まれます。
外部では、これらのファイルは名前のインデックスによって区別され、デコード中の処理の順序を決定します。 インデックスは、単に序数にすることも、ピースへの入力ファイルのオフセットとして表すこともできます。
T.O. 最初に、パーティションイメージがスパースファイルにエンコードされ、次にそれが既に_sparsechunkファイルのセットに変換(カット)されます。
_sparsechunkファイルを作成するプロセスは、次のアルゴリズムで説明できます。
- 完成したスパースファイルがスキャンされ、RawおよびFillタイプの連続して配置されたすべてのチャンクが「データ」と呼ばれるグループに収集され、その長さは常に監視されます。 この手順は、グループサイズが境界に達するまで実行されます。境界の値は事前に指定されており、ファイルを分割するプロセスを説明するときに上記の要件によって決定されます。
- 次のピースを追加すると境界を超える場合、それはグループに含まれず、すでにグループ化されたピースから別のファイルが形成されます。このファイルには、「終了」と呼ばれるDontCareタイプのピースが追加され 、出力ファイルの終わりまでのデータオフセットがChunk_Sizeフィールドに示されます このファイルの名前は_sparsechunk.1です。
- スパースファイルは項目1〜2の手順に従って引き続き検査され、次の_sparsechunkファイルが形成されます。形成される前にのみ、「初期」と呼ばれるDontCareタイプのスパースピースがデータオフセットがChunk_Sizeフィールドに示され、 スパースチャンクのグループに追加されますこのファイルに含まれる、元の画像の先頭から。 最後に、上記のアルゴリズムによって形成された「最終」ピースが追加されます。
- これは、 スパースファイルの終わりに達するまで続きます。
したがって、各_sparsechunkファイルは、3つの部分で構成できます。
- OFFSET_TO_START- 「初期」ピースが含まれます。
- INFO- 「データ」を含む部分。
- OFFSET_TO_END- 「最終」ピースが含まれます。
OFFSET_TO_START部分は、スパース形式の情報を含む「データ」部分の先頭への入力ファイル内のオフセットを表します。
INFO部分には、 FillやRawなどの疎な部分で構成される疎形式の情報のみが含まれます。
OFFSET_TO_END部分は、出力ファイルの終わりまでのオフセットです。 オフセットがゼロの場合、つまり 情報グループを含む問題の_sparsechunkファイルは_sparsechunkファイルのセットの最後であり、 OFFSET_TO_END部分は完全に存在しません。
3.2.2 _sparsechunkファイルの使用
_sparsechunkファイルの操作例として、system.img_sparsechunk.0ファイルセットをsystem.img_sparsechunk.4ファームウェアとしてMoto X [5]として使用して、 _sparsechunkファイルをスパースファイルに、またはその逆に変換することを検討してみましょう。
3.2.2.1 _sparsechunkファイルのリストを単一のファイルに変換する
上記で、 _sparsechunkファイルに変換するときに、元のスパースファイルの内容が情報部分に単純に分割され、必要に応じて追加の断片に変わることを示しました。 したがって、元のスパースファイルを復元するには、各_sparsechunkファイルからラッパーピースがあればそれを破棄し、すべての情報部分を単純に追加して、 スパースピースの総数を計算する必要があります。
- 16進エディターでsystem.img_sparsechunk.0を開きます。
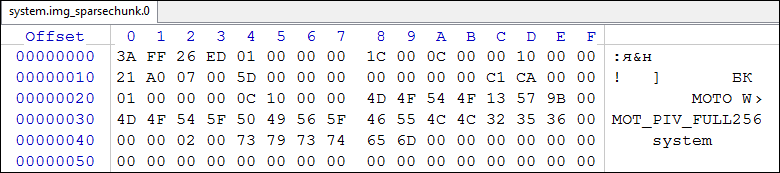
図8 sparsechunk_0
アドレス0x0000からアドレス0x001Bまで、 スパースファイルのヘッダーが配置されていることがわかります。 さらに、アドレス0x001Cから、ヘッダー0x100C (アドレス0x0024 )とともにデータ領域の長さを持つタイプ0xCAC1で始まる情報グループが続きます。 したがって、次のピースはアドレスから始まります。
0001 + 0100 = 01028
このアドレスにあるものを見てみましょう:

図9 。 ピース2
アドレス0x1028には、長さが0x1000 (アドレス0x1030 )のタイプ0xCAC2があります。 次に(アドレス0x1038 )再びタイプ0xCAC1などの断片
このファイルの最後の部分は0x0FFFF524にあり、タイプは0xCAC3です。 これは、 OFFSET_TO_ENDタイプの断片であり 、 0x067AD4を測定します 。 不要なものとして削除します。

図10 。 最初の_sparsechunk_end
したがって、最初の_sparsechunkファイルから、 スパースファイルのヘッダーと「データ」のみを残しました。 また、「データ」のピースの数-0x005D ( 0x0014のフィールドを参照 )を覚えておきましょうが、これはタイプOFFSET_TO_ENDのピースと一緒なので、実際には「取得」しただけです
0x005D - 00001 = 0005
- 次の_sparsechunkファイルを16進エディターで開きます-system.img_sparsechunk.1 :

図11a。2番目のピースの始まり

図11b。2番目のピースの終わり
コンテンツをコピーし、ヘッダー、タイプ0xCAC3の最初と最後の部分、つまりアドレス0x0028からアドレス0xFBFC46Cを破棄し 、それを前の部分の最後のタイプ0xCAC3の最後に削除された部分(アドレス0xFFFF524 )の場所に追加します。 これは次のようになります。

図12 。 2つの部分
すなわち このような「パイ」があります。
- スパースヘッダー
- 最初の_sparsechunkファイルの「データ」。
- 2番目の_sparsechunkファイルの「データ」。

図13 。 折り畳まれたファイルの終わり
ピースの合計数を合計することを忘れないでください。 追加した「データ」にピースの数を追加します
0x005 + (0x0050 - 00002) = 0x00A
- 最後を除く、残りのすべての_sparsechunkファイルに対して手順2を実行し続けます。 新しいファイルをそれぞれ処理した後、「データ」自体が追加されるため、「パイ」が大きくなります。

図14 2番目のファイルを追加する
そして、私たちはピースの数を要約し続けます... - 最後の_sparsechunkファイルを「パイ」に追加するには、 ステップ 2の手順に従って、ヘッダーとタイプ0xCAC3の最初の部分のみをドロップします。 取得したものは次のとおりです。

図15 結果
このファイルのサイズは0x4173FBD4 ( 1098120148または約1047MB)であり、ピースの総数は0x01FB ( 507 )であり、 0x0014 ( Total_Chunksヘッダーのピースの数をフィールド)に書き込みます。 合計数から取得した8個は、タイプ0xCAC3の個です。_sparsechunkファイルのパート0からの1個、パート1〜3からの2個、最後の(4番目)部分からの1個です。
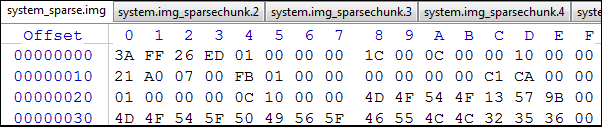
図16 。 すべての_sparsechunkファイルの断片の総数を記録します
必要に応じて、ヘッダーのImage_Checksumフィールド(アドレス0x0018)に、ファイル全体に対してCrc32アルゴリズムによって計算されたチェックサムを追加します。 見出し+すべての部分。 通常、このフィールドは埋められず、ゼロのままです。 - 結果のスパースファイルを、 system.sparseなどの名前で保存します。
これで、断片からスパースファイルのアセンブリが完了しました。
3.2.2.2スパースファイルを一連の_sparsechunkファイルに変換するか、パーツに分割(分割)する(チャンク)
次に、作成したスパースファイルを_sparsechunkファイルにカットしてみましょう。 境界の値として、256MB(0x10000000)を取ります。
- system.sparseファイルを開き、以下で説明するすべてのアクションを16進エディターで実行します。
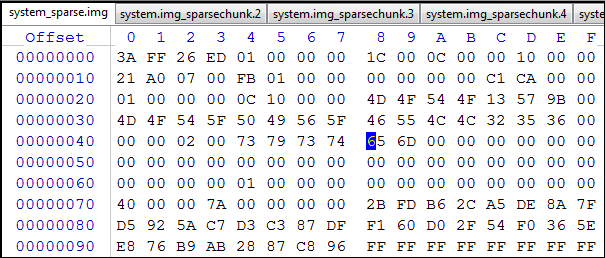
図17 system.sparseファイル
「データ」のみを含む個別の_sparsechunk部分に分割します。 - 最初の_sparsechunkファイルを作成します。 これを行うには、現在のマーカー位置からオフセット0x10000000に移動します(最初のファイルの場合は0x0000です)。 将来の_sparsechunkファイルの最大サイズに到達しましょう。 最初のファイルの場合、これはアドレス0x10000000になります。

図18 。 _Sparsechunkファイルの境界線
そして、あらゆるタイプのピースの始まりを下方向から見始めます。 0xCAC1または0xCAC2コード。 タイプ0xCAC1の最も近い部分は0xFFFF524にあります。

図19 _Sparsechunk filesセクションの境界
「境界」の寸法に「適合する」最後のピースを見つけるために、このピースのサイズ+ヘッダーのサイズを、見つかったオフセットに追加して、次のピースの始まりを見つけます。
0xFFFF524 + 0x41D2000 + 0x000C = 0x141D1530
なぜなら 次のピースのオフセットが「境界」を横切ると、 _sparsechunkファイルのセクションポイントが見つかりました。 system.sparseファイルのコードを0x00000000から0xFFFF524のファイルに保存します(例: system_new_sparsechunk_0.img) 。 - ステップ2を繰り返します。現在のマーカーの位置について、前のステップで見つかった最後のピースの先頭、つまり 0xFFFF524 。 現在位置からオフセット0x10000000にステップします。

図20 2番目のファイルの境界線
最大値、つまり 次の_sparsechunkの開始アドレスは、 部分0x1FFFF524です。 下側に最も近い部分、すなわち _sparsechunkファイルの一部の意図されたパーティション境界:

図21 _sparsechunkファイルの2番目のセクション境界
最後のピースが正しく検出されたかどうか、つまり 次のピースへのオフセットを決定します。
0x1FBFB968 + 0x01897000 + 0x000C = 0x21492968
なぜなら シフトは次のパートの開始の推定シフトを超えるため、 _sparsechunkパーツのセクションポイントを正しく見つけました。 system.sparseファイルの次のコードを0xFFFF524から0x1FBFB968に保存します(例: system_new_sparsechunk_1.img) 。 - system.sparseファイルの終わりまで手順3を繰り返します。 その結果、次のファイルのセットが得られました。
=========================================================================== | № | | | | | | / | | | | | | |=====|===================|========|============|============|==============| | 1 | new_sparsechunk_0 | 256 | 0x00000000 | 0x0FFFF523 | 0x005C ( 92) | | 2 | new_sparsechunk_1 | 252 | 0x0FFFF524 | 0x1FBFB967 | 0x004E ( 78) | | 3 | new_sparsechunk_2 | 242 | 0x1FBFB968 | 0x2EE61403 | 0x00C2 (194) | | 4 | new_sparsechunk_3 | 235 | 0x2EE61404 | 0x3D92DA5B | 0x0074 (116) | | 5 | new_sparsechunk_4 | 62 | 0x3D92DA5C | 0x4173FBD3 | 0x001B ( 27) | |============================================================|==============| | : | 0x01FB (507) | ===========================================================================
- 最初の部分を除く各_sparsechunk部分に作成します。 彼はすぐそこにいた、 スパースファイルのヘッダー。 これを行うには、 system.sparseからヘッダーをコピーし、ファイルの先頭の各部分に貼り付けます。 前の表のデータを使用して、「 個数 」列の値を各ファイルのアドレス0x0014の Total_Chunksフィールドに入力します。
これで、 _sparsechunkの切断プロセスは部分的に完了しました。
PSオフセットによる遷移、必要なピースの検索、ファイルサイズの計算などを伴うこれらすべての「ホラー」。 スパースファイルと_sparsechunkファイルの処理に関する作業を完了するために必要な手順をMU開発者に示すためだけに説明しました。 私自身はこれをしません 私が書いたコンピューターとアプリケーションがあります。
上記の資料を研究した希望者は、自分の好みや色に応用することができます。
4. datファイルを作成する
datファイルは、パーティションイメージの圧縮における次のステップです。 スパースファイルとは異なり、情報部分のみが含まれています。 また、ソースファイルのアセンブリを確実にするために、 transfer_listというファイルが作成されます。
この場合、ソースファイルは有用な情報を含む部分に分割されます。 情報ブロック、および「空の」ブロック、つまり ゼロを含む。 次に、情報を持つすべての部分がnew_dataという名前の出力ファイルに行でコピーされ、ソースファイルでの配置とこれらの部分のサイズに関する情報がtransfer_listファイルに記録されます。
したがって、最終情報ファイル( new_data )にはゼロのブロックは含まれません。 「縮小」、元のサイズよりもはるかに小さくなります。
このようなデータ変換の可能性、およびそれに応じてtransfer_listファイル形式は、時間の経過とともにいくつかの変更を受けています。 このファイルにはいくつかのバージョンがあります。
最初、 new_dataファイルにはすべての情報ブロックが含まれ、 transfer_listには「解凍」にのみ必要な情報が含まれていました。 完全なソースファイルを復元します。 バージョン5.0.0以降、Android OSでファイルを圧縮するために使用されるバージョン1でした。
次に、単純な圧縮に加えて、 datおよびtransfer_list-ファイルの機能により、パッチファイルを作成してソースファイルの一部のみ、たとえばリカバリ用のパッチを置き換える機能が追加されたため、バージョン5.1.0以降、Android OSで使用されるバージョン2が導入されました。 これにより、元の画像がさらに圧縮されました。 パッチでは変更のみが送信されます。
Android 6.0では、セキュリティシステムへのアプローチが大きく変わり、暗号化が広く使用され、それに応じて、 stashコマンドを使用して即座に復号化できるtransfer_listファイルのバージョン3が誕生しました。
4.1.Datファイルの構造
datファイル(.dat)への変換後のRAW形式ファイル(.img)の画像は、次のファイルのセットです。
- transfer_listファイル。 このファイルには、情報部分の配置の説明と、それらの回復と検証のためのコマンドが含まれています。
- new_dataファイル。 これには、ソースファイルの情報部分のみが含まれており、継続的に配置されています。 隙間や整列なし;
- patch_dataファイル。 このファイルには、その中に継続的に配置されているソースファイルの情報部分を置き換える部分のみが含まれています。 隙間や整列なし。
RAWソースファイルで実行される変換のタイプに応じて、ファイルセットの構成は変更される可能性がありますが、 new_dataファイルとpatch_dataファイルの両方を一緒に使用することも個別に使用することもできますが、 transfer_listファイルは常に存在する必要があります。
変換が単に「空の」ブロックを削除することで構成されている場合、 transfer_listファイルに加えて、 new_dataファイルのみがセットに含まれます(例[7]) 。
変換がパッチを適用する場合、つまり 一部のブロックが他のブロックに置き換えられると、セットにはpatch_dataファイルのみが存在します(例: [8]) 。
変換が「空の」ブロックの削除とパッチの適用の両方で構成されている場合、つまり 一部のブロックが他のブロックに置き換えられた場合、セットにはnew_dataファイルとpatch_dataファイルの両方が含まれます(例[6]) 。
各dat-ファイルの構造をより詳細に検討し、常に使用されるtransfer_list-ファイルから始めます。 ソースファイルで実行される変換と、それに応じて、ソースファイルを「取得」するために実行する必要があるアクションを説明するのは、彼です。 「回復」とは言いませんでした 厳密に言えば、変換を受けたソースファイルは、処理後に取得された最終ファイルと一致しない場合があります。 これは、たとえば、パッチを適用した後に発生する可能性があります。 ソースファイルに変更を加えます。
4.1.1 transfer_listファイルの構造
ファイルtransfer_listは4行以上の行のセットで、各行は1つのデータフィールドを記述し、次の構造を持ちます。
==================================================== | № | | | | / | | | | | | | |=====|=================|============================| | 1 | Version | | | 2 | Size New Data | new_dat | | 3 | Stash Entries | stash- | | 4 | Stash Max Block | . stash- | | 5 | Commands | | ====================================================
バージョンフィールド文字列は、ファイルtransfer_listのバージョンを説明し、1〜3の値をとることができます。ファイルバージョンは機能が異なり、ファイル自体の行数に影響します。 バージョン1は、Androidバージョン5.0以降で作成されたファイルに使用されます。 Android 5.1.0以降、バージョン2が使用されています。 Android 6.0.1以降、バージョン3が使用されています。
バージョン1には、3行目と4行目に記載されている値は含まれていませんが、少なくとも2つのコマンドが含まれている必要があります。 したがって、 transfer_listファイルの長さは少なくとも4行です。
- バージョン
- 新しいデータのサイズ設定
- コマンド1 ;
- コマンド2 。
バージョン2および3はすでにstashコマンドを実行できるため、 transfer_listファイルには少なくとも6行が含まれます。
- バージョン
- 新しいデータのサイズ設定
- スタッシュエントリ
- スタッシュマックスブロック ;
- コマンド1 ;
- コマンド2 。
Size New Data行フィールドは、情報ファイルのみを含む出力ファイルnew_datのブロック単位のサイズを示します。 移動されるデータのブロック数。 デフォルトでは、ブロックサイズは4096バイトです。
Stash Entries行フィールドは、 stashコマンドで同時に使用されるソースファイルの部分へのオフセットのセットを含むstashテーブル内のエントリの数を示します。
Stash Max Block行フィールドは、ソースファイルのそのようなstash部分の最大サイズを示します。
[ コマンドライン]フィールドには、最終ファイルを取得するために実行する必要があるコマンドが含まれています。
transfer_listファイルバージョン1の例を次に示します。
1 140333 erase 2,0,190108 new 236,0,56,57,164,517,523,3717,21738,21739,32767,32768,32770,32825,32826,33285...
ここで、最初の行はファイルのバージョン(1)を示し、2行目は移動されるデータのサイズ、つまり ブロック単位のファイルサイズnew.dat (140333)。 3行目と4行目にはコマンド( eraseおよびnew )が含まれています。 これらの行は削減されます、なぜなら 長すぎます。
次に、 transfer_listバージョン2 ファイルを示します 。
2 317984 129 24931 move 2,117767,117787 20 2,128537,128557 move 2,113788,117574 3786 2,124558,128344 imgdiff 0 2187 2,117631,117633 2 2,128401,128403 imgdiff 2187 2210 2,117788,117902 114 2,128558,128672 move 2,117903,121984 4081 2,164515,168596 move 2,117609,117630 21 2,128379,128400 imgdiff 4397 2229 2,117575,117602 27 2,128345,128372 imgdiff 6626 16212 2,117636,117759 123 2,128406,128529 imgdiff 22838 2170 2,117760,117766 6 2,128530,128536 imgdiff 25008 2198 2,117603,117608 5 2,128373,128378 move 2,125336,125341 5 2,129329,129334 ... move 2,383166,383179 13 2,392851,392864 move 2,383475,383496 21 2,393160,393181 erase 70,32770,32929,32931,33443,65535,65536,65538,66050,98303,98304,98306,98465,98467,98979,131071,131072,131074,131586,163839,163840,163842...,589826,622592,622594,655360
ここでも、最初の行はバージョン番号、2行目は移動するデータのサイズです。 3行と4行は0です。 stash-テーブルは使用されません。 5行目以降には、erase 、 move、およびimgdiffコマンド が含まれてい ます 。 一部の行は切り捨てられます 長すぎます。
new_dataファイルの構造に移りましょう。
4.1.2 new_dataファイルの構造
このファイルには、処理中に取得されたソースimgファイルコードの情報ブロックのみが含まれます。 これらは、隙間なく厳密に順番に配置され、 新しいコマンドのデータソースとして使用されます。
特定の例を使用して、 new_dataファイルの構造を見てみましょう。 OTAファームウェアMU A7010a40 [6]には、ファイルsystem.new.datおよびsystem.transfer.listが含まれています 。
最後のファイルでは、 新しいコマンドが1901、1945、および1946行で3回発生します。 コマンドの実行は厳密にシーケンシャルに実行され、神経コマンドの実行は行1901で新規
new 2,226365,226468
は、読み取りポインタの現在の位置から開始して、最初の103ブロックのnew_datファイルから読み取りを行います。 0で、出力ファイルに範囲[226365.226468]の103ブロックを書き込みます。 この場合、ソースの読み取りポインタはアドレス103に移動します。1945行で次のコマンドを実行します
new 2,294901,294902
は、読み取りポインタの現在の位置から開始して、次の1ブロックのnew_datファイルから読み取りを行います。 103で、範囲[294901,294902]のブロックの出力ファイル1に書き込みます。 この場合、ソースの読み取りポインタはアドレス104に移動します。1946行目の次のコマンド
new 2,294902,294903
は、読み取りポインタの現在の位置から開始して、次の1ブロックのnew_datファイルから読み取りを行います。 104で、範囲[294902,294903]のブロックの出力ファイル1に書き込みます。 この場合、ソースの読み取りポインタはアドレス105に移動します。
したがって、 new_datファイルには105個のデータブロックが含まれている必要があるため、その長さは105 * 4096 = 430080である必要があります。
次に、 patch_dataファイルの構造に目を向けます。
4.1.3 patch_dataファイルの構造
すべてのパッチデータは、サービスパック内の1つのpatch_dataファイルに結合されます。 このファイル内のデータは、bsdiffおよびimgdiffコマンドのソースです。
4.2データ構造の説明
すべての構造はデータ範囲を記述しますが、単位値はデータの単位、つまり 4096バイト。 次のデータ記述構造が存在します。
- レンジセット[レンジセット]
- スラッシュ範囲セット[stash_rangese]
- 入力データセット<...>
それらの構造を順番に検討してください。
4.2.1。情報ブロックの範囲の説明の構造(範囲のセット[rangeset])
range_setは transfer_listファイルコマンドで使用され、ソースとデータレシーバーの両方の情報ブロックの範囲を記述します。 また、 stashストレージエリアの範囲を記述するためにstashコマンドで使用されます。
単純なデータ範囲は、2つの値で記述されます。たとえば、[23,56)のように、範囲の最初と最後の要素へのポインターです。 この場合、左の境界線は範囲に含まれますが、右の境界線は含まれません。 複数の範囲がある場合、それらを説明するには、もう1つの要素(セット内の範囲の数)を含む範囲のセットが必要です。
transfer_listファイルのバージョンに関係なく、範囲の範囲の説明は次の構造になります。
[count,posStart1,posEnd1,posStart2,posEnd2,...] ,
どこで
- count-範囲セット内のオフセットの数、つまり 範囲セットの行の最初の番号なし。 情報ブロックの範囲の数は、この値の半分に等しくなります。 各範囲は、値のペアで記述されます。範囲の開始と終了。
- posStart1-最終ファイルの情報ブロックの最初の範囲の先頭のオフセット、ブロック単位。
- posEnd1-最終ファイルのブロック内の情報ブロックの最初の範囲の最後のブロックのオフセット。
- posStart2-ブロック内の最終ファイルの情報ブロックの2番目の範囲の開始のオフセット。
- posEnd2-ブロック内の最終ファイルの情報ブロックの2番目の範囲の最後のブロックのオフセット。
ご覧のとおり、セットにはデータ範囲の列挙が含まれており、それぞれが列挙の始まりの境界と終わりの境界で構成されています。 さらに、右の境界線はリストに含まれていません。 範囲の長さは次のように計算されます:length = end-begin。
たとえば、上のtransfer_listファイルの例から、 moveコマンドで範囲のセットがどのように記述されるかを見てみましょう。
move 2,117767,117787 20 2,128537,128557
範囲の2つのセットはここにリストされています:
- ソース範囲:2.117767.1117787。 範囲に2つのオフセットが含まれることを意味します。 この行には、1つのデータ範囲を表す2つのオフセット番号117767と117787が含まれています。 したがって、カウント=2。次は範囲の先頭へのオフセット(posStart = 117767)で、次は範囲の末尾へのオフセット(posEnd = 117787)です。 したがって、範囲には117787-117767 = 20要素、つまり その長さは20です。
- 受信範囲:2,128537,128557。 同様に、ターゲット範囲の場合:count = 2、posStart = 128537、posEnd = 128557、length-20 elements。
両方の範囲に同じ数の要素が含まれているという事実は、移動操作の属性です。 20個のソース要素が20個の受信要素に移動されます。
4.2.2スタッシュ範囲構造(stash_rangeset)
stash- rangeは、厳密に定義された場所にデータ要素を保存するように設計された情報ブロックのセットです。 この範囲には、要素のセット(どのオフセットからどの要素まで)だけでなく、ストアの名前またはポインターもあります。
stash範囲の情報ブロックのセットには、次の構造があります。
number:[range_set],
どこで
- number - stashストレージの識別番号、10進数。
- [range_set] -データ範囲のセット。
たとえば、コマンドラインは次のようになります。
stash 10 2,298306,298307
は、オフセット298306からオフセット298307(それを含まない)までの1つの(2/2)データ範囲が作成されたことを意味します。 サイズが1つの要素(298307-298306 = 1)、識別番号10のスタッシュストレージとしてマークされます。
別の例:
stash 11 2,295927,295960
は、オフセット295927からオフセット295960(それを含まない)までの1つの(2/2)データ範囲が作成されたことを意味します。 サイズが33要素(295960-295927 = 33)で、識別番号11のスタッシュストレージとしてマークされています。
別の例:
stash 8 6,247114,247116,247150,247155,247156,247156
3(6/2)のデータ範囲を意味します:
1)オフセット247114からオフセット247116まで(それを含まない)、つまり 2要素のサイズ(247116-247114 = 2);
2)オフセット247150からオフセット247155(それを含まない)、つまり 5要素のサイズ(247155-247150 = 5);
3)オフセット247156からオフセット247156(それを含まない)、つまり サイズ0の要素は、(247156から247156 = 0)に結合され、総称標識されているスタッシュ識別番号と-hranilische 8。
4.2.3入力データセットの構造<...>
バージョン1の場合、このセットは次のようになります。
[src_rangeset] [tgt_rangeset],
どこで
- [src rangeset] -ソースファイルの情報ブロックの範囲のセット(new_datまたはpatch_dat)、つまり データソース;
- [tgt rangeset] -出力ファイル(* .img)の情報ブロックの範囲のセット、つまり データ受信者。
バージョン2および3の場合、このセットは次のタイプになります。
- [tgt_rangeset] <src_block_count> [src_rangeset] ;
- [tgt_rangeset] <src_block_count> [stash_rangeset] ;
- [tgt_rangeset] <src_range> <src_loc> [stash_rangeset] ;
どこで
- [tgt rangeset] -出力ファイル(* .img)の情報ブロックの範囲のセット、つまり 受信機
- [src rangeset] -ソースファイルの情報ブロックの範囲のセット、つまり ソース;
- 【stash_rangeset] -レンジ設定情報ブロックスタッシュ -コマンド。
- <src_block_count> -ソースとレシーバーの範囲内の情報ブロックの数。
- <src_range> -の数スタッシュ Aの範囲;
- <src_loc> -。
4.3。transfer_listファイルのコマンドの構造と説明
transfer_listファイルでは、次のコマンドが使用されます。
- bsdiff、imgdiff-パッチを適用します;;
- 消去 -指定された領域を空としてマークします。
- 無料 - スタッシュエリアをクリアします。2から始まるバージョンで利用可能。
- 新しい -からの情報を埋めるためにNEW_DATA出力ファイルの-file指定された領域と、
- 移動 -指定された領域で情報ブロックを移動します。
- stash-前処理で指定された領域を移動します。2から始まるバージョンで利用可能。
- ゼロ -ファイルの指定された領域をゼロで埋めます。
4.3.1。コマンド「erase」、「new」、「zero」
これらのコマンドの構造は次のとおりです。
name [rangeset],
どこで
- name-チームの名前。
- [rangeset] -情報ブロックの範囲のセットを記述する構造。
eraseコマンドは、[rangeset]構造体で記述された空のブロックをマークします。たとえば、コマンドを実行する
erase 70,32770,32929,32931,33443,...
[7、transfer_list file、line 2337]から、出力ファイルのブロックの35セットが番号[32770,32929]、[32931,33443]などでクリアされます。新しい
コマンドは、ソース情報ブロック、つまり new_datファイルを、[rangeset]の構造によって記述された範囲のセットに、レシーバ、つまり system.imgファイル。ソースからの情報ブロックは、厳密に順番に選択されます。たとえば、[7、transfer_list file]の行1901でのコマンドの実行
new 2,226365,226468
は、ポインター103ブロックの現在位置から開始し、範囲[226365,226468]の出力ファイルに書き込むnew_datファイルから読み取りを行います。zero
コマンドは、出力ファイルの指定された範囲のセットをクリアします。ゼロで埋めます。たとえば、コマンドを実行する
zero 2,226365,226366
受信ユニット226365をクリアします。
4.3.2。「移動」コマンド
このコマンドは、単純な構造を説明、ソースファイルから情報ブロックをコピー[src_rangeset]を出力ファイル範囲の既存のセットに構造を記述し、[tgt_rangeset] 。move
コマンドの構造は次のとおりです。
move <...>,
ここで、<...>は入力データセットであり、transfet_listファイルのバージョンによって異なります。
たとえば、コマンドが次の場合:
move 2,117767,117787 20 2,128537,128557
これは、情報ブロックを移動するコマンド(move)であり、2つの範囲のセットがここで説明されています。
- ソース範囲:2.117767.1117787。
これは、1つのデータ範囲を記述する2つのオフセット(カウント= 2)が範囲に含まれることを意味します。次は範囲の始まりのオフセット(posStart = 117767)で、次は範囲の終わりのオフセット(posEnd = 117787)です。 - 受信機範囲:2,128537,128557。
同様に、受信機の場合:count = 2、posStart = 128537、posEnd = 128557。
4.3.3。bsdiffおよびimgdiffコマンド
これらのコマンドを使用して、ソースファイルの情報ブロックが読み取られ、更新が実行され、変更された情報ブロックが出力ファイルに書き込まれます。コマンドの違いは、情報ブロックに適用される変換のタイプのみです。
両チームの構造は次のとおりです。
name <patchstart> <patchlen> <...>,
どこで
- name-チームの名前。
- patchstart- パッチ領域の先頭のオフセット(ブロック単位)。
- patchlen-ブロック単位のパッチ領域の長さ。
- <...>は入力データのセットです。
4.3.4。隠しコマンド
このコマンドは、スタッシュ領域に情報ブロックを保存します。次の構造になっています。
stash <stash_id> <src_range>,
どこで
- <stash_id> - ID スタッシュ Aの範囲;
- <src_range> -セットは、情報ブロックの範囲のstash -regionを。
4.3.5。「無料」コマンド
このコマンドは、スタッシュ領域をクリアします。次の構造になっています。
free <>,
どこで
<...> --入力データのセット。
続行するには...
5.結論
その使用のすべての資料と例は、「乗算表」であり、アクションのガイドではありません。もちろん、誰もパッチを手動で適用せず、システムファイルを変換しません...「スパース」ファイル(主にファイルシステムを含むファイルを含む)で変換を実行するための原則について説明しました。
もちろん、「スパース」ファイルの処理には、すでに多くのコンピュータープログラムが使用されます。手に入れたら、既存の変換ツールのレビューを書きます。
出版物を書き始めて、私はユーザーに、いわば「理論」だけの基本だけを持ってきたかったのです。なぜならソーステキストとファームウェアの「掘削」に関する作業のほとんどは2013年から2014年にかけて私が行ったもので、その過程で私は多くの作業をしなければなりませんでした。 Androidの新しいバージョン。次のパートでは、「スパース」ファイルの処理の例を説明します。
もちろん、多くの資料がありましたが、同化と準備を容易にするために、記事をすぐに2つまたは3つの部分に分割する必要がありました。しかし、それがどのように起こったか、それは起こりました。あなたは厳密に判断しないのは私です、私も何も知りませんが、何かを考慮に入れません...質問、提案があれば、私たちは大歓迎です。
6.情報源
1. Sparse_file。
2. Lenovo s90Aデバイスファームウェア
3. sparse_format.h
4. Lenovo Moto Z
5。 Victara_Retail_China_XT1085_5.1_LPE23.32-53_CFC.xml.zip-Lenovo Moto X.
6。 A7010a40_S111_150825_ROW_TO_A7010a40_S112_150901_ROW_WC15.zip
7。
8。 OTA更新の回復。