日常のコードに影響を与える8つの便利な変更について説明します。 4つの変更は言語自体に関係し、さらに4つ-標準ライブラリに関係します。
すべてのC ++開発者が使用すべき10のC ++ 11機能の記事にも興味があるかもしれません。
謝辞
ロシアのC ++ユーザーグループ会議でのレポートからいくつかの例を取り上げました。そのためのオーガナイザーとスピーカーに感謝します。 私は例を挙げました:
1.宣言時の分解(eng。構造バインディング)
- 変数を宣言するときに分解を使用します:auto [a、b、c] = std :: tuple(32、 "hello" s、13.9)
- パラメータを割り当てる代わりに、関数から構造体またはタプルを返します
新しい構文を使用して、 std::pair
、 std::tuple
および構造体を分解すると便利です。
#include <string> struct BookInfo { std::string title; // In UTF-8 int yearPublished = 0; }; BookInfo readBookInfo(); int main() { // title year, auto [title, year] = readBookInfo(); }
C ++ 17では、宣言時の分解に制限があります。
- 分解可能な要素のタイプは明示的に指定できません
-
auto [title, [header, content]] = ...
という形式のネストされた分解は使用できませんauto [title, [header, content]] = ...
宣言時の分解は、原則として、任意のクラスを分解することができますtuple_element
、 tuple_size
、およびget
特殊tuple_element
することにより、ヒントを一度書くだけget
。 詳細については、 クラスへのC ++ 17構造化バインディングサポートの追加(blog.tartanllama.xyz)の記事を参照してください。
宣言時の分解は、 std::map<>
およびstd::unordered_map<>
コンテナで、古い.insert()
メソッドと2つの新しいメソッドで.insert()
ます。
- try_emplaceメソッドは、指定されたキーがまだコンテナにない場合にのみ挿入します
- 指定されたキーが既にコンテナ内にある場合、何も起こりません。特に、右辺値は移動しません
- insert_or_assignメソッドは、既存の要素に値を挿入または割り当てます
try_emplaceを使用した分解の例と、マップを横断するときのキー値分解:
#include <string> #include <map> #include <cassert> #include <iostream> int main() { std::map<std::string, std::string> map; auto [iterator1, succeed1] = map.try_emplace("key", "abc"); auto [iterator2, succeed2] = map.try_emplace("key", "cde"); auto [iterator3, succeed3] = map.try_emplace("another_key", "cde"); assert(succeed1); assert(!succeed2); assert(succeed3); // key value range-based for for (auto&& [key, value] : map) { std::cout << key << ": " << value << "\n"; } }
2.テンプレートパラメータの自動出力
主なルール:
-
std::make_pair
という形式の関数std::make_pair
不要になりましたstd::make_pair
std::pair{10, "hello"s}
式を自由に記述してください。コンパイラは型を推測します -
std::lock_guard<std::mutex> guard(mutex);
という形式のテンプレートRAII 短くなります:std::lock_guard guard(mutex);
- 関数
std::make_unique
およびstd::make_shared
はまだ必要です
テンプレートパラメータを自動的に表示するための独自のヒントを作成できます: Automatic_deduction_guidesを参照してください
興味深い機能: initializer_list<>
コンストラクターinitializer_list<>
、1つの要素のリストでinitializer_list<>
スキップされます。 一部のJSONライブラリ(json_spiritなど)の場合、これは致命的です。 再帰型とSTLコンテナーを使用しないでください!
#include <vector> #include <type_traits> #include <cassert> int main() { std::vector v{std::vector{1, 2}}; // vector<int>, vector<vector<int>> static_assert(std::is_same_v<std::vector<int>, decltype(v)>); // assert(v.size() == 2); }
3.ネストされた名前空間の宣言
名前空間のネストを回避し、回避しない場合は、次のように宣言します。
namespace product::account::details { // ... ... }
4.属性nodiscard、fallthrough、maybe_unused
主なルール:
-
[[fallthrough]]
属性またはbreak;
ステートメントのいずれかで最後を除くすべてのcaseブロックを完了しbreak;
- エラーコードを返す関数またはポインターを所有する関数に
[[nodiscard]]
を使用します(スマートかどうかに関係なく) - assertでの検証にのみ必要な変数に
[[maybe_unused]]
を使用します
属性の詳細については、記事「C ++ 17の属性を使用する方法」を参照してください。 ここに短い抜粋があります。
C ++では、switch構造体の各ケースの後にブレークを追加する必要があり、これは経験豊富な開発者にとっても忘れがちです。 フォールスルー属性は、空の命令に接着できる救助に来ます。 実際、属性は空のステートメントに続くケースに接着されています。
enum class option { A, B, C }; void choice(option value) { switch (value) { case option::A: // ... case option::B: // warning: unannotated fall-through between // switch labels // ... [[fallthrough]]; case option::C: // no warning // ... break; } }
この属性を利用するには、GCCおよびClangに-Wimplicit-fallthrough
警告を含める必要があります。 このオプションを有効にすると、フォールスルー属性を持たない各ケースで警告が生成されます。
パフォーマンス要件の高いプロジェクトでは、(少なくとも一部のコンポーネントでは)例外をスローしないことを実践できます。 そのような場合、操作エラーは、関数から返された戻りコードによって報告されます。 ただし、このコードをチェックするのを忘れることは非常に簡単です。
[[nodiscard]] std::unique_ptr<Bitmap> LoadArrowBitmap() { /* ... */ } void foo() { // warning: ignoring return value of function declared // with warn_unused_result attribute LoadArrowBitmap(); }
たとえば、エラークラスを使用する場合、宣言で属性を1回指定できます。
class [[nodiscard]] error_code { /* ... */ }; error_code bar(); void foo() { // warning: ignoring return value of function declared // with warn_unused_result attribute bar(); }
プログラマーは、呼び出された関数のエラーコードを格納するために、デバッグバージョンでのみ使用される変数を作成することがあります。 おそらくこれは単なるコード設計エラーであり、戻り値は常に処理する必要があります。 ただし:
// ! ! auto result = DoSystemCall(); (void)result; // unused variable assert(result >= 0); // [[maybe_unused]] auto result = DoSystemCall(); assert(result >= 0);
5.文字列パラメーターのstring_viewクラス
ルール:
-
const string&
代わりにすべての関数とメソッドのパラメーターでconst string&
値によって非所有string_view
を取得しよう
- 以前のように
string
所有する関数およびメソッドから戻る
- 以前のように
- 関数からstring_viewを返すときは注意してください:これにより、ぶら下がりリンクの問題(ぶら下がりポインタ)が発生する可能性があります
string_viewがパラメーターにのみ最適に使用される理由の詳細については、記事std :: string_viewは文字列の一時インスタンスから構築される記事を参照してください。
string_view
クラスstring_view
、追加のメモリ割り当てなしでstd::string
とconst char*
両方から簡単に構築できるという点で優れています。 constexprのサポートもあり、std :: stringインターフェイスを繰り返します。 ただし、マイナスがありますstring_view
、末尾にヌル文字が存在string_view
ことは保証されません。
6.オプションのクラスとバリアント
optional<>
およびvariant<>
非常に広いため、この記事ではそれらを完全に説明しようとはしません。 主なルール:
- 所有者の存続期間よりも短い存続期間を持つオブジェクトTを作成するために、
unique_ptr<T>
optional<T>
ではなくoptional<T>
好む
- Impl定義はクラス実装ファイルに隠されているため、PIMPLの場合は
unique_ptr<Impl>
使用します
- Impl定義はクラス実装ファイルに隠されているため、PIMPLの場合は
- ライセンス状態などの状態が、各状態に追加データが存在するために列挙定数で記述できない状況では、enumまたはpolymorphicクラスの代わりにバリアント型を使用します
- 例外のエラーコードなどのデータをすべてのバリアントで処理する必要があり、バリアントの不完全な処理でコンパイルエラーが発生する場合は、enumではなくバリアントタイプを使用します
- 可能な限り代わりにバリアントを使用する
- optionalは、寿命が所有者の寿命より短いオブジェクトを作成するために使用できます
- エラー処理に
optional
を使用しないでください。エラー情報は含まれません。
- 値またはエラーを返すには、
boost::variant<...>
基づいて独自のクラスExpected<Value, Error>
を記述できます - ただし、完成したものを作成して取得することはできません: github.com/martinmoene/expected-lite
- 値またはエラーを返すには、
オプションのサンプルコード:
// nullopt - nullopt_t, // optional ( nullptr ) std::optional<int> optValue = std::nullopt; // ... optValue ... // , -1 const int valueOrFallback = optValue.value_or(-1);
- オプションには、
operator*
とoperator->
、および便利なメソッド.value_or(const T &defaultValue)
- optionalにはvalueメソッドがあり、
operator*
とは異なり、値がない場合に例外std::bad_optional_access
スローします - オプションには比較演算子「==」、「!=」、「<」、「<=」、「>」、「> =」がありますが、
std::nullopt
有効な値より小さい - オプションにはboolへの明示的な変換演算子があります
バリアントを含むサンプルコード:ここでは、バリアントが異なる状態に異なるデータを持っている場合に、いくつかの状態の1つを保存するためにバリアントを使用
struct AnonymousUserState { }; struct TrialUserState { std::string userId; std::string username; }; struct SubscribedUserState { std::string userId; std::string username; Timestamp expirationDate; LicenseType licenceType; }; using UserState = std::variant< AnonymousUserState, TrialUserState, SubscribedUserState >;
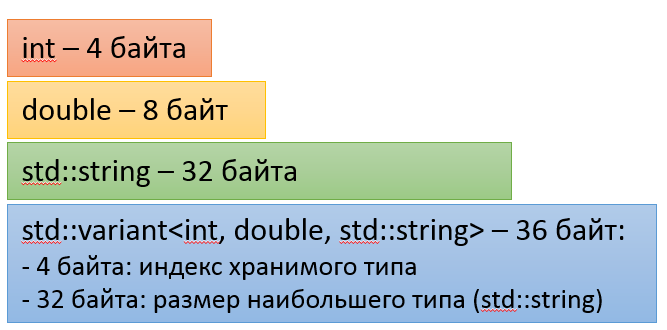
メモリ管理へのアプローチにおけるバリアントの利点:データは、追加のメモリ割り当てなしでバリアント型の値フィールドに格納されます。 これにより、バリアント型のサイズは、その構成に含まれる型に依存します。 これは、32ビットプロセッサ上のサイズテーブルのように見える場合があります(ただし、これは不正確です)。
7.関数std :: size、std :: data、std :: begin、std :: endを使用します
- std :: sizeを使用して、Cスタイルの配列の長さを測定します
- この関数は配列およびSTLコンテナで動作しますが、通常のポインタを渡そうとするとコンパイルエラーがスローされます
- std :: dataを使用して、文字列、配列、または
std::vector<>
の先頭への変数ポインターを取得します
- 以前、式
&text[0]
そのようなポインターを取得するため&text[0]
使用されましたが、空の行では未定義の動作があります
- 以前、式
バイトを操作するためにGSLライブラリ(C ++コアガイドラインサポートライブラリ)に依存する方が良い場合があります。
8. std ::ファイルシステムを使用する
主なルール:
- パスを意味するすべてのパラメーターの文字列の代わりに、
std::filesystem::path
渡します -
canonical
関数に注意してください:おそらくlexically_normalメソッドを意味します
- canonicalはシンボリックリンクを処理しますが、lexically_normalは処理しません
- canonicalはパスが存在することを要求しますが、lexically_normalは存在しません
- Windowsでは、ほぼ長すぎるパスと「..」を貼り付けてから、標準を適用しようとすると失敗する場合があります。ファイルへのパスが長すぎるため、Boostは例外をスローします
-
relative
関数に注意してください:おそらくlexically_relative - エラーが許容できる場合は、noexceptバージョンの関数(エラーコード付き)を使用してください。
- たとえば、 exists関数のnoexceptバージョンを使用すると、一部のネットワークパスで例外が発生します!
- ブーストを使用しない::ファイルシステム
Bad Boost ::ファイルシステムとは何ですか? 彼にはいくつかの設計上の問題があることがわかりました:
- Boostは2038問題を解決していません。 より正確には、このタスクはtime_tに転送されましたが、Linuxではまだ32ビットです!
- そのトピックに関する素晴らしい記事があります2038:残りわずか21年
- ファイルシステムのSTLバージョンには、エンコーディングを操作するためのすべてのツールがあります
経験のあるプログラマなら誰でも、WindowsシステムとUNIXシステムのパス処理の違いを認識しています。
- Windowsでは、パスはUTF-16文字列として受け入れられます(またはUCS-2文字列、つまりパスのサロゲートペアは避けてください!)、よく使用されるタイプwchar_tはUTF-16でエンコードされた2バイト文字を表し、パスセパレータとして機能しますバックスラッシュ「\」
- UNIXでは、パスはUTF-8行として受け入れられ、めったに使用されないwchar_tはUCS32でエンコードされた4バイト文字を表し、スラッシュ「/」はパス区切り文字です
もちろん、ファイルシステムはそのような違いから抽象化し、プラットフォーム固有の文字列とユニバーサルUTF-8の両方を簡単に操作できるようにします。
- パスのUTF-8バージョンを取得するには、 u8stringメソッドを使用します
- UTF-8文字列からパスを構築するには、無料のu8path関数を使用します
-
std::string
からのstd::filesystem::path
コンストラクターを使用しないでください-Windowsでは、コンストラクターはOSのエンコーディングを入力エンコーディングと見なします!
ボーナスルール:クランプ、int_to_stringおよびstring_to_intの再作成を停止
std :: clamp関数は、minおよびmax関数を補完します。 上と下の両方の意味を切り捨てます。 同様のboost::clamp
機能は、C ++の以前のバージョンで使用できます。
「クランプを再発明しない」ルールは一般化できます。大規模なプロジェクトでは、丸め、値のトリミングなどのために小さな関数や式を重複させないでください。 -これをライブラリに一度追加するだけです。
同様のルールは、文字列処理タスクに対して機能します。 文字列と解析のための独自の小さなライブラリを持っていますか? 解析または数値の書式設定はありますか? その場合、実装をto_charsおよびfrom_chars呼び出しに置き換えます
to_chars
およびfrom_chars
エラー処理をサポートします。 次の2つの値を返します。
- 最初の型はそれぞれ
char*
またはconst char*
あり、処理できなかった最初のコード単位(つまり、charまたはwchar_t)を指します - 2番目は
std::error_code
型であり、std :: system_error例外のスローに適した詳細なエラー情報を報告します
アプリケーションコードではエラーに対する反応の方法が異なる場合があるため、ライブラリとユーティリティクラス内でto_charsおよびfrom_charsを呼び出す必要があります。
#include <utility> // , 0 // ( atoi, ) template<class T> T atoi_17(std::string_view str) { T res{}; std::from_chars(str.data(), str.data() + str.size(), res); return res; }