
デジタル変革シリーズ
技術記事:
1. 始まり 。
2. 銀行のブロックチェーン 。
3. 機械に人間の遺伝子を理解するように教えます。
4. 機械学習とチョコレート 。
5.読み込み中...
DZ OnlineチャンネルでのDmitry Zavalishinへの一連のインタビュー:
1. MicrosoftのAlexander Lozhechkin:将来、開発者が必要ですか?
2. Robot VeraのAlexey Kostarev:HR-aをロボットに置き換える方法は?
3. Dodo PizzaのFedor Ovchinnikov:レストランディレクターをロボットに置き換える方法は?
4. ELSE Corp SrlのAndrei Golub:膨大な時間の買い物を無駄にするのを止める方法は?
私たちは最近、若い有望な医学研究会社であるミロクルスとパートナーシップを結びました。 ミロクルスは、迅速な血球計数のための安価なキットを開発しています。 このプロジェクトのフレームワークでは、科学的および医学的文書を分析することにより、マイクロRNAと遺伝子間のリンクを特定する問題に焦点を当て、他の多くの分野に適用できる解決策を見つけました。
問題
Miroculusシステムのタスクは、個々のマイクロRNAと特定の遺伝子または疾患との関係を特定することです。 これらのデータに基づいて、ツールが開発され、絶えず改善されているため、研究者はマイクロRNA、遺伝子、疾患の種類(腫瘍など)の関連性をすばやく特定できます。
個々のマイクロRNA、遺伝子、および疾患間の相互依存性に関する医学文献には多くの研究がありますが、そのような情報を順序付けられた構造形式で含む単一の集中型データベースはありません。
さまざまなタイプのマイクロRNAと遺伝子が存在する可能性がありますが、データが不足しているため、結合を抽出する問題はバイナリ分類に縮小されており、その目的は単にマイクロRNAと遺伝子間の接続の存在を判断することです。
非構造化テキスト内のオブジェクト間の関係の識別は、関係の抽出と呼ばれます。
厳密に言えば、タスクは構造化されていないテキスト入力とオブジェクトのグループを受け取り、「第1オブジェクト、第2オブジェクト、コミュニケーションタイプ」という形式のトライアドの結果グループを表示します。 つまり、これは、 情報を抽出する大きなタスク内のサブタスクです。
バイナリ分類を扱っているため、センテンスとオブジェクトのペアを受け取り、2つのオブジェクト間の関係の可能性を反映して0から1の範囲で結果のスコアを表示する分類子を作成する必要があります。
たとえば、「mir-335規制BRCA1」文とオブジェクトのペア(mir-335、BRCA1)を分類子に渡すと、分類子は結果「0.9」を返します。
このプロジェクトのソースコードは、 ページで入手できます 。
データセットを作成
PMCとPubMedの 2つのデータソースからの医療記事のテキストを使用しました。
示されたソースからダウンロードされたドキュメントのテキストは、 TextBlobライブラリを使用して文に分割されました。
各文はGNATオブジェクト認識ツールに転送され、文に含まれるマイクロRNAと遺伝子の名前が抽出されました。
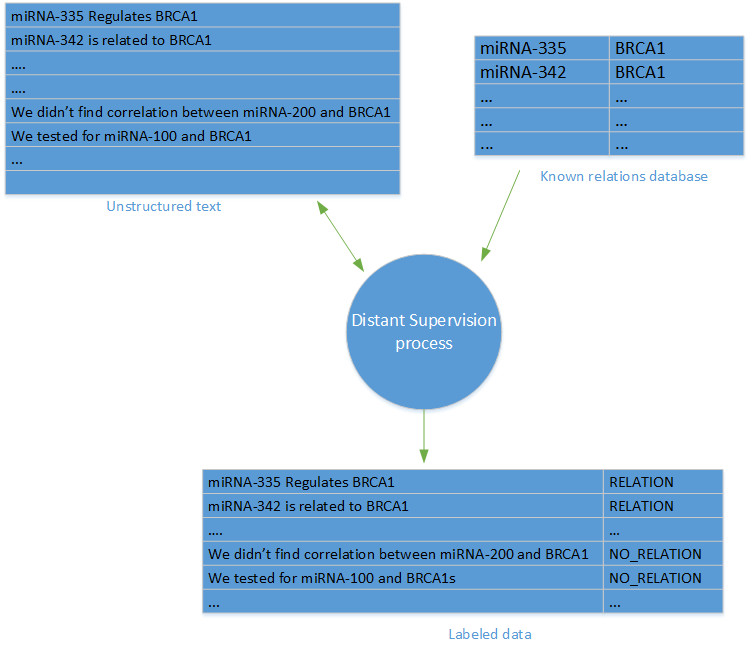
関係の抽出(または機械学習の基本タスク)に関連する最も難しいタスクの1つは、ラベル付きのデータの可用性です。 私たちのプロジェクトでは、そのようなデータは利用できませんでした。 幸いなことに、「リモート監視」方式を使用できます。
リモート監視
「リモートモニタリング」という用語は、Mintz et alによる「タグ付きデータを使用せずにリレーションシップを取得する際のリモートモニタリング」という研究で初めて導入されました リモート観測方法では、オブジェクト間の既知の関係のデータベースと、これらのオブジェクトが言及されている記事のデータベースに基づいたラベル付きのデータセットを作成します。
オブジェクトの各ペアおよびオブジェクトのデータベース内の各リンクに対して、オブジェクトが言及されているデータベース記事のすべてのオファーに対してリンクラベルが作成されます。
ネガティブパターン(コミュニケーション不足)を生成するために、リレーションシップデータベースに表示されていないリレーションシップを含むオファーをランダムに選択しました。 場合によっては、データサンプルのランダムサンプリングの結果として、誤ったネガティブな結果が得られる可能性があるため、リモートモニタリング方法の主な批判はネガティブサンプルの可能性のある不正確さに基づいていることに注意してください。
テキスト変換
ラベル付きのトレーニングセットを作成した後、 scikit-learn Pythonライブラリと自然言語処理(NLP)テクノロジに基づくいくつかのPythonライブラリを使用してリンク分類子が作成されます。 実験として、いくつかの異なる識別機能と分類子を使用しようとしました。
実際にメソッドをテストして機能を区別する前に、以下で説明する手順で構成されるテキスト変換を実行しました。
オブジェクト置換
モデルトレーニングは特定のオブジェクトの名前に従って必要ではなく、テキストの構造に従って必要であるという考え方です。
例:
miRNA-335 was found to regulate BRCA1
への変換:
ENTITY1 was found to regulate ENTITY2
つまり、実際には各オファーからオブジェクトのすべてのペアを取得し、それぞれについて、目的のオブジェクトをプレースホルダーに置き換えました。 この場合、OBJECT1は常にmicro-RNAを置き換え、OBJECT2は遺伝子です。 また、別の特別なプレースホルダーを使用して、提案の一部であるが目的の関係に関与していないオブジェクトをマークしました。
したがって、次の文の場合:
High levels of expression of miRNA-335 and miRNA-342 were found together with low levels of BRCA1
以下の変換されたオファーのセットを受け取りました。
High levels of expression of ENTITY1 and OTHER_ENTITY were found together with low levels of ENTITY2 High levels of expression of OTHER_ENTITY and ENTITY1 were found together with low levels of ENTITY2
この時点で、オブジェクトを置き換える場合はPythonのstring.replace()メソッドを使用でき、可能な組み合わせをすべて表示する必要がある場合はitertools.combinationsまたはitertools.productメソッドを使用できます。
マークアップ
マークアップは、単語のシーケンスを小さなセグメントに分割するプロセスです。 この場合、文を単語に分割します。
これを行うには、 nltkライブラリを使用します。
import nltk tokens = nltk.word_tokenize(sentence)
切り捨て
科学文献で提示された推奨事項に従って、各文を小さなセグメントに切り捨てました。このセグメントには、オブジェクト間の単語とオブジェクトの前後のいくつかの単語が含まれています。 このような切り捨ての目的は、関係を抽出するときに重要ではない文の部分を削除することです。
前の段階でマークアップが実行された単語の配列のスライスを作成し、対応するインデックスを提供しました。
WINDOW_SIZE = 3 # make sure that we don't overflow but using the min and max methods FIRST_INDEX = max(tokens.index("ENTITY1") - WINDOW_SIZE , 0) SECOND_INDEX = min(sentence.index("ENTITY2") + WINDOW_SIZE, len(tokens)) trimmed_tokens = tokens[FIRST_INDEX : SECOND_INDEX]
正規化
すべての文字を小文字に変換するだけで、文章の正規化が完了しました。 気分や感情の分析などの問題を解決するためにケース作成方法を使用することをお勧めしますが、関係を抽出するという意味ではありません。 文の個々の単語を強調するのではなく、テキストの情報と構造に関心があります。
ストップワード/数字の削除
この場合、ストップワードとストップワードを文から削除する標準プロセスを使用します。 ストップワードは、高頻度のワードです。たとえば、前置詞「in」、「k」、および「on」です。 これらの単語はセンテンスでは非常に一般的であるため、センテンス内のオブジェクト間の接続に関するセマンティックの負荷はありません。
同じ理由で、数字のみで構成されるトークンと、2文字未満の短いトークンを削除します。
ルート選択
ルートの強調表示は 、単一の単語をルートに減らすプロセスです。
その結果、単語の意味空間の量が減り、単語自体の意味に集中できます。
実際には、このステップは精度を高めるという点で特に効果的ではありません。 この理由と、このプロセスの生産性が比較的低いため(実行時間の観点から)、ルート割り当ては最終モデルに含まれていませんでした。
正規化、単語の削除、およびルート抽出は、マークされた文と切り捨てられた文を繰り返し処理して実行されます。 必要に応じて、単語の正規化と削除が実行されます。
cleaned_tokens = [] porter = nltk.PorterStemmer() for t in trimmed_tokens: normalized = t.lower() if (normalized in nltk.corpus.stopwords.words('english') or normalized.isdigit() or len(normalized) < 2): continue stemmed = porter.stem(t) processed_tokens.append(stemmed)
顕著な特徴の提示
以下に示す変換が完了したら、さまざまな種類の特徴を実験することにしました。
3種類の属性を使用しました:多数の単語、構文属性、および単語のベクトル表現。
たくさんの言葉
単語のマルチセット (MS) モデルは、テキストを数値ベクトル空間に変換する自然言語処理(NLP)タスクで使用される一般的な方法です。
MSモデルでは、辞書の各単語には一意の数値識別子が割り当てられます。 次に、各文が辞書のボリューム内のベクトルに変換されます。 ベクトル内の位置は、そのような識別子を持つ単語がテキストの場合は値「1」、それ以外の場合は値「0」で表されます。 別の方法として、テキスト内の特定の単語の出現回数のベクトルの各要素で表示を構成できます。 例はここにあります 。
それでも、上記のモデルでは、文中の異なる単語の順序は考慮せず、個々の単語の出現のみを考慮します。 モデルに単語の順序を含めるために、一般的なN-gramモデルを使用しました。このモデルは、長さNの連続する単語のコレクションを評価し、そのような各コレクションを単一の単語として扱います。
テキスト分析でのN-gramの使用の詳細については、「テキスト分析の際立った特徴の表現:1チャート、2チャート、トライグラム...どのくらい?」を参照してください。
幸いなことに、MCおよびN-gramモデルはCountVectorizerクラスを介してscikit-learnで実装されています。
次の例では、トライグラムモデルを使用してテキストをMS 1/0に変換します。
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer(analyzer = "word", binary = True, ngram_range=(3,3)) # note that 'samples' should be a list/iterable of strings # so you might need to convert the processes tokens back to sentence # by using " ".join(...) data_features = vectorizer.fit_transform(samples)
構文記号
2種類の構文機能を使用しました。 品詞 (CR)のマーカー と依存関係のある解析ツリーです。
spacy.ioを使用してPDマーカーと依存グラフの両方を抽出することにしました。このテクノロジーは、速度と精度の点で既存のPythonライブラリよりも優れており、他のNLPシステムに匹敵するからです。
次のコードスニペットは、指定された文のCRを取得します。
from spacy.en import English parser = English() parsed = parser(" ".join(processed_tokens)) pos_tags = [s.pos_ for s in parsed]
すべての文を変換した後、上記のCountVectorizerクラスとPDマーカーの単語のマルチセットのモデルを使用して、それらを数値ベクトル空間に変換できます。
同様の方法を使用して、各文の2つのオブジェクト間で検索された依存関係を持つ構文解析ツリーの特徴を処理し、それらの変換もCountVectorizerクラスを使用して実行されました。
単語のベクトル表現
単語のベクトル表現の方法は、NLPに関連する問題を解決するために最近非常に一般的になりました。 この方法の本質は、ニューラルモデルを使用して単語を特徴的な特徴の空間に変換し、類似した単語が互いにわずかな距離にあるベクトルで表されるようにすることです。
単語のベクトル表現の詳細については、次のブログ投稿を参照してください。
Paragraph Vectorドキュメントで説明されているアプローチを適用しました:特徴(特徴)の高次元空間に文(またはドキュメント)を導入します。 Doc2VecライブラリGensimの実装を使用しました。 詳細については、このチュートリアルをご覧ください 。
使用される出力ベクトルのパラメーターとサイズは両方とも、Paragraph VectorドキュメントとGensimチュートリアルの推奨事項に準拠しています。
タグ付きデータに加えて、Doc2Vecモデルでタグなしの文の大規模なセットを使用して、モデルに追加のコンテキストを提供し、モデルのトレーニングに使用される言語と機能を拡張しました。
モデルの作成後、各文は200を超える次元ベクトルで表され、分類器の入力として使用できます。
分類モデルの評価
テキストの変換と特徴的な特徴の抽出が完了したら、次のステップである分類モデルの選択と評価に進むことができます。
分類には、 ロジスティック回帰アルゴリズムが使用されました。 サポートベクターマシンやランダムフォレストなどのアルゴリズムをテストしましたが、速度と精度の点でロジスティック回帰が最良の結果を示しました。
この方法の精度を評価する前に、データセットをトレーニングセットとテストセットに分割する必要があります。 これを行うには、train_test_splitメソッドを使用します。
from sklearn.cross_validation import train_test_split x_train, x_test, y_train, y_test = train_test_split(data, labels, test_size=0.25)
この方法では、データセットを任意に分割します。データの75%はトレーニングセットに関連し、25%はテストセットに関連します。
ロジスティック回帰に基づいて分類器をトレーニングするために、scikit-learn LogisticRegressionクラスを使用しました。 分類子のパフォーマンスを評価するために、 classification_reportクラスを使用します。このクラスは、 精度 、 戻り値の完全 性 、および分類のためのF1スコアに関するデータを出力します。
次のコードは、ロジスティック回帰分類器のトレーニングと分類レポートの印刷を示しています。
from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report clf = linear_model.LogisticRegression(C=1e5) clf.fit(x_train, y_train) y_pred = clf.predict(x_test) print classification_report(y_test, y_pred)
上記のコードフラグメントの結果の例は次のとおりです。
precision recall f1-score support 0 0.82 0.88 0.85 1415 1 0.89 0.83 0.86 1660 avg / total 0.86 0.85 0.85 3075
この例では、パラメーターC(正則化の度合いを示す)が任意に選択されていますが、以下に示すように、相互検証を使用して調整する必要があります。
結果
上記のすべての方法と手法を組み合わせ、さまざまな特徴的な機能と変換を比較して最適なモデルを選択しました。
LogisticRegressionCVクラスを使用してカスタムパラメーターを持つバイナリ分類子を作成し、別のテストスイートを分析してモデルのパフォーマンスを評価しました。
異なる特徴のさまざまなパラメーターを簡単かつ便利にテストするには、 GridSearchクラスを使用できます。
次の表は、さまざまな特徴的な機能を比較した主な結果をまとめたものです。
モデルの精度を確認するために、 F1-Scoreスケールが使用されました。これは、モデルのリターンの精度と完全性の両方を評価できるためです。
| 特徴 | F1-スコア |
|---|---|
| 単一のトライグラム(単語のマルチセット) | 0.87 |
| 単一のトライグラム(MS)およびトライグラム(チェコ共和国のマーカー) | 0.87 |
| シングルトライグラム(MS)およびDoc2Vec | 0.87 |
| シングルトーン(単語のマルチセット) | 0.8 |
| 2グラム(単語のマルチセット) | 0.85 |
| トライグラム(単語のマルチセット) | 0.83 |
| Doc2ec | 0.65 |
| トライグラム(チェコ共和国のマーカー) | 0.62 |
一般に、1トリグラムで単語のマルチセットを使用する場合、他の方法と比較して最大の精度が保証されるようです。
Doc2Vecモデルは、単語の類似性を判断する際の最大のパフォーマンスで注目に値しますが、関係を抽出するという点で適切な結果を保証するものではありません。
ユースケース
この記事では、マイクロRNAと遺伝子間の関係を処理するための関係を抽出するための分類子を作成するために使用された方法を検討しました。
この記事で説明した問題とサンプルは生物学の分野に属しますが、研究したソリューションと方法は他の分野に適用して、非構造化テキストデータに基づいて関係グラフを作成できます。
Azureを無料で試すことができます 。
広告の分 。 プロジェクトで新しいテクノロジを試してみたいが、実際に試していない場合は、Microsoft Tech Accelerationプログラムにアプリケーションを残してください。 その主な機能は、お客様と一緒に必要なスタックを選択し、パイロットの実装を支援し、成功した場合、市場全体がお客様について知るよう最大限の努力を払うことです。
 PSこの記事を説明してくれたKostya Kichinsky( Quantum Quintum )に感謝します。
PSこの記事を説明してくれたKostya Kichinsky( Quantum Quintum )に感謝します。