
約6年前、私は北米の大手医療会社向けに鉄とソフトウェアを製造するプロジェクトに参加しました。 いくつかのデバイスがロードされているテストスタンドの近くに立って、 「何か問題が発生した場合、検索を高速化してエラーを修正するにはどうすればよいですか?」
この質問が発生した瞬間から今日まで、多くのことが行われました。ソフトウェアとハードウェアでのテレメトリーの収集と分析が、私が参加したプロジェクト全体のエラーを検出および修正するための時間を大幅に短縮するのにどのように役立ったかを共有したいと思います。
はじめに
テレメトリは、古代ギリシャ語のτῆλε「遠い」+μέτρεω-「測定」に由来します。
すべてが非常に単純で、さまざまなエンジニアや科学者のスタッフが考えることができる測定値は、ターゲットシステムが視覚的および自動制御および処理のために処理センターに送信します。
このようなもの:

サーバー側では、次のようになります。
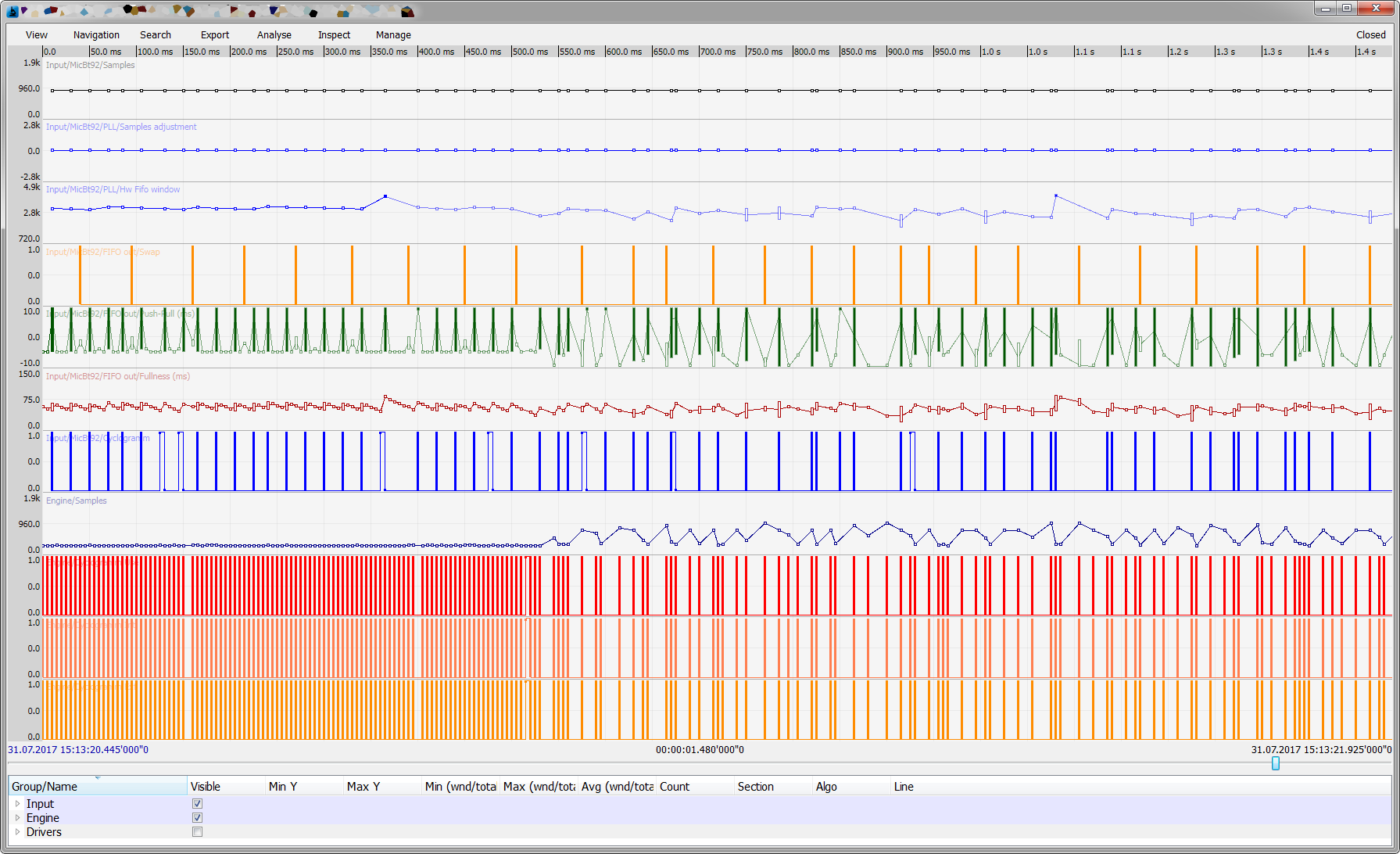
背景
どういうわけか、QAエンジニアの仕事を見ながら、なぜ衛星、ロケット、車などの複雑なデバイスにテレメトリーがあり、実際、手術室、ロボット、複雑なソフトウェアソリューションのプログラム部分を作成しても、それについても考えない方向?
コードの量は膨大ですが、何かが間違っていることを片方の指よりも少ないことを理解する方法があります。
- ブレークポイントを設定しますが、このためにはクエストを完了する必要があります。
1)十分に幸運で、ターゲットシステムにアクセスできる
2)幸運でバグを正確に再現する方法を知っているか、しばらく待ってからもう一度待つ
3)ブレークポイントがシステムの内部状態を破壊しないように祈る(リアルタイムプロセスが内部で進行している場合)
- クライアントは、あなたのコードの例外が、患者がテーブルの上にいるときではなく、テストベンチで彼のエンジニアに捕まったという少し面白くなくて良いと電話に叫びます。
- Zenオプション-ログ分析
- クラッシュダンプ分析
QAエンジニアの仕事を見ながら、患者の心拍曲線、圧力、体温、その他のパラメーターを実行する画面の1つを見て、信頼できる監督の下で製品をこの患者のようにしたかったのです。 そのため、何か問題が発生した場合でも、時間を巻き戻して、どのような状況で発生したかを確認できます。
自転車または乗車
教えられたとおり、自転車は有益でエキサイティングですが、最初に既存のソリューションを探してみました。
良い伝統により、私は要件から始めました:
- クライアント/サーバーアーキテクチャー(サーバーがない場合、データをローカルに保存する機能)
- オープンソース
- クロスプラットフォーム(少なくともLinux + Win)
- リモート制御(リソースを節約するためのオン/オフカウンター)
- 高性能(C / C ++プログラムの標準による)
- 合理的なメモリ要件、およびこのパラメーターを制御する能力の向上
- 少なくともC / C ++ / Pythonをサポート
- リアルタイムモードおよび/またはオフラインモードでテレメトリー分析用のスクリプトまたは独自のコードを作成する機能
- リアルタイムモードとオフラインモードでの表示の利便性(主観的な要件)
私は長い間探して、思慮深く...しかし、悲しいかな、それはただ悪いだけでなく、それはすべてひどいものでした!
2011年の初めの時点では、私が見つけたプロジェクトのうち、要件の半分に近いものでさえ、これらの要件に該当するものはありませんでした。
既製のオープンなソリューションの形でのソフトウェアのテレメトリは、クラスとしてはほとんど存在せず、大企業は自分たちですべてを行い、急いで共有することはありませんでした。
2番目の驚きは同僚の反応でした-無関心、または最悪の場合は拒否ですが、幸いなことに、これは最初の結果まで長続きしませんでした。
そのとき(2011年)に見つけた唯一の解決策は、その時点でgoogleコードにあるP7ライブラリでした。 機能は貧弱で、プラットフォームのX86のみで、涙を流さずにサーバーを見るのは困難でしたが、次のような利点がありました。
- 高性能
- 無料で
- オープンソース
- リモートで(オン/オフ)カウンターを管理する機能(CPUを節約するという点で魅力的でした)
- そして最も重要なことは、プロジェクトの作者が改善のアイデアに興味を持って反応したことです。
一連の考え、研究の後、他の人の自転車に乗ることにした。
最初のステップ
ライブラリをコードに埋め込むのは簡単で、問題はありませんでしたが、疑問が生じました。どのような美しいグラフィックを表示し、どの読み取り値を記録するのかということです。 質問は単純であるように思えますが、実際は複雑で潜行性があります。
最初は、経験がなくても、比較的重要でない量のテレメトリーを書き始めました。
- コアおよびメインスレッドによるCPU使用率
- ハンドル、スレッド、オブジェクトなどの数
- メモリ消費
- 異なるバッファがいっぱいです
- クリティカルフローのいくつかのサイクログラム
残念ながら、その年のスクリーンショットはありませんでした。最も近い近似値を示します。

火の最初の洗礼は素晴らしい結果をもたらしました:数日間の目立たない作業といくつかのバグの再現の後、私たちはついにそれらの多くの性質を理解することができました:
- ディスクがビジーであるため、ディスクからの読み取りが停止しませんでした-別のスレッドがビジーでした(最初のスレッドと接続されていないようです)。 私たちはすでに顧客にもっともらしい説明をすることができ、その後テレメトリーを追加しました...そして...それは不便でした。
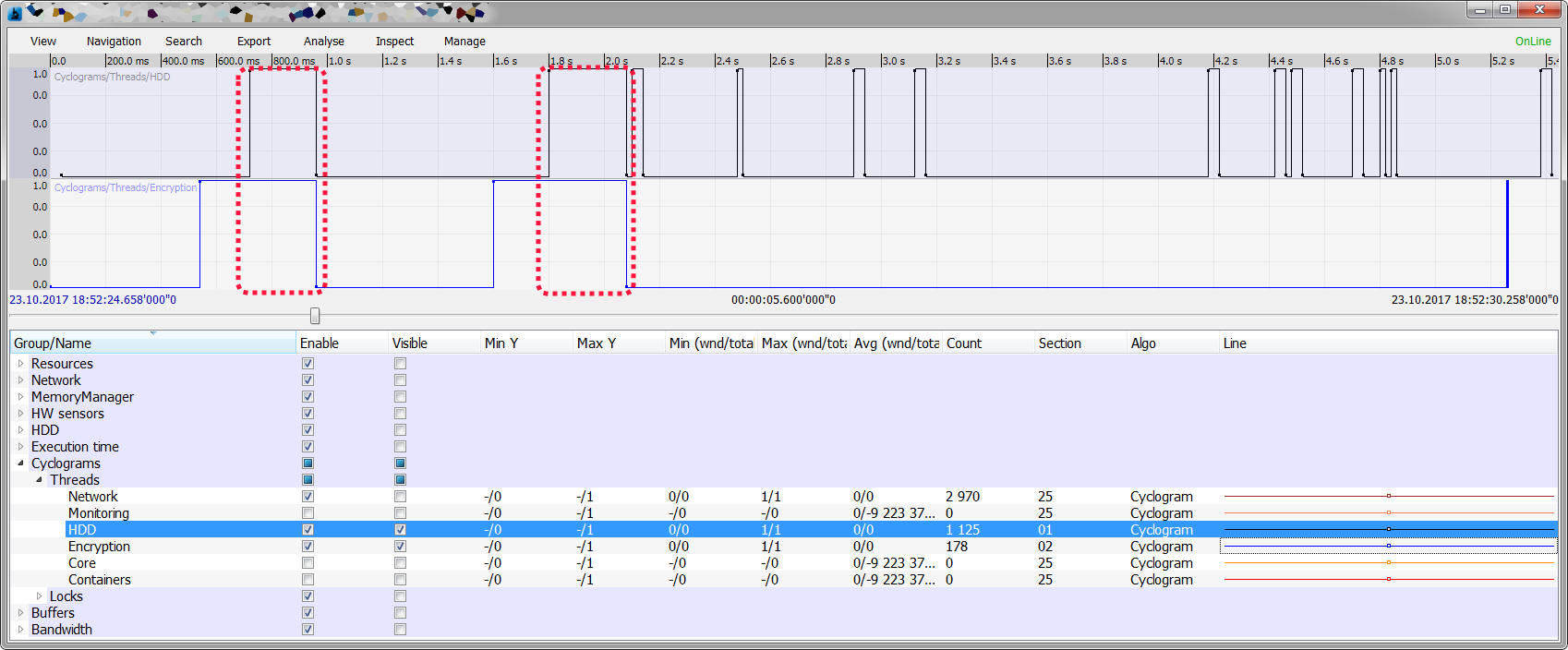
グラフ(クリック可能)は、HDDからのストリーム読み取りの遅延が、他のストリームの遅延と驚くほど一致することを示しています。コードを10分ピアリングした後、そのような依存関係を引き起こす断片が見つかりました。
- メモリマネージャーが返された数千のアイテムをダイジェストしようとしたため、メモリが数秒間だけ定期的にジャンプし、その後のリリースでリリースがハングすることがありました。
エンジニアのマシンのテストコードが実稼働に入り、1秒間、スレッドの1つを定期的に1秒間ハングさせたことが判明しました。 この問題はグラフでもはっきりとわかりました-CPUがオフになり、メモリ、メモリマネージャのクレイジーな作業が発生し、途中で突然数百ミリ秒(場合によっては数秒)ハングしました:

- バッファが空であり、最初のバグによりバッファが空だったためにディスクからの処理データがスタックしました。これもグラフにはっきりと表示されており、テレメトリとログの一致するタイムマークがこれらのイベントの関係について話していました。
1日目または2日目にはまだ修正されたものがいくつかありましたが、何年も処方した後、私はそれが何であったかをもはや思い出すことができません。
同僚と熱心にモニターを指でつまんで「¿Quépasa?」と尋ねた後、答えを見つけて子供として幸せでした-有用性の質問はもうなくなったので、新しいおもちゃを手に入れて遊びました。
走りに行く
最初の成功の後、必要なカウンターの数を一貫して増やし始めました。
- テレメトリーは、メインフローにサイクログラムの形で追加され、すぐに作業の頻度、大小のフリーズが明らかになりました
- テレメトリが同期プリミティブ(ミューテックス、セマフォ、クリティカルセクション)に追加されました。
- 考えられるすべてのハードウェアセンサーを追加しました-「判明」温度ジャンプは多くの問題と相関します
- さまざまなハードウェアコンポーネントのロードカウンターを追加-メモリ帯域幅、レジスタアクセス、PCI、および世界が新しい色でプレイし始めました
- 主な機能とコードブロックの実行時間の測定、およびテストで変更を行った後、パフォーマンスの低下が明らかになった場合-関係者は、コード変更後の回帰を示すカウンターが記載された自動怒りの電子メールを受信しました
- もちろん、エンジニアはこれらのカウンターに加えて、一時的および永続的に他のヒープを追加しました。
次に、カウンターを3つのグループに分けました。
- 最大のデータフローを生成する-サーバーとの接続があり、エンジニアの1人の手によってサーバーからこのカウンターがオンになった場合にのみ、ソフトウェアがこれらのカウンターを処理しました
- 平均データストリームの生成-サーバーとの接続が存在しない場合、サーバーとの接続が存在する場合にのみソフトウェアが処理したこれらのカウンター-カウンターはCPUサイクルを消費しませんでしたが、接続が表示されるとすぐに-データの送信が開始されました
- 重要-サーバーとの接続がなく、HDDに接続されていない場合、このデータはどのような場合でも保存されているはずです。
最後のステップは、テストプロセスを更新し、QAによって記録されたエラーに、正式な説明、可能であれば再生方法とログファイルだけでなく、テレメトリも付随させるというプラクティスを導入することでした。
おわりに
結論として、いくつかの事実を紹介しましょう。
- 今では、CからC#、Python、そしてハードウェアまでのあらゆるソフトウェアから膨大な量のテレメトリを収集しています。タスクによっては、集中的に収集しています。
- テレメトリー分析は、3つのブロックに分かれています。
- 自動(サーバーへのプラグイン)
- 半自動-サーバーは追加の分析にLuaスクリプトを使用する機能を備えており、エンジニアがどのスクリプトを決定し、ニーズに合わせて変更/作成します
- ビジュアル(注意深いピアリングの方法)はばかげているように聞こえますが、多くの場合、特に何を探すべきかわからない場合でも非常に効果的ですが、問題があります
- QAエンジニアからのエラーレポートには、テレメトリリンクが伴います
- 問題をより早く解決し始めました
この記事は非常に表面的であり、「スレッドのCPU負荷をどのように取得するか」、「スレッドのサイクログラムを作成する方法」、「プラグインを作成する方法」など、多くの技術的な質問が残されています。 しかし、トピックが十分に興味深い場合は、これらすべての点について別々の記事を作成できます。
この記事が「テレメトリーが当社の製品に役立つか」と同じ質問をすることを望みます。ソフトウェア業界ではこの質問は信じられないほどまれであるため、私はそれを書いたと言えますこれは多くのスペースと防御です。
読んでくれてありがとう!
PS:私は故意に私たちの会社について話し始めたわけではありません。この記事は彼女に関するものではありません。
PPS:興味がある場合は、Jenkins + Baical + P7 バンドル ( www.baical.net )を使用します。ニーズによく合います。プロジェクトの作成者は、1つまたは2つの改善ではなく、私たちのリクエストで実装された長年にわたる協力に加えて、P7を使用しますロギング( https://habrahabr.ru/post/313686/ )