
侵入テスト中に適切な辞書を使用すると、さまざまな方法で資格情報の選択の成功が決まります。 この出版物では、辞書を作成し、特定のケースに合わせて最適化するために使用できる最新のツールと、明らかに誤った数千の組み合わせをソートする時間を無駄にしない方法を説明します。
ツール
クランチ
おそらく、辞書をすばやく作成するための最も有名なツールの1つです。 デフォルトでは、人気のあるKali Linux Pentestディストリビューションに含まれています。
このツールはいくつかのモードで動作します:
リストされた数字などの文字で構成される辞書の作成
crunch 4 5 1234567890 -o all_numbers_from_4_to_5.txt
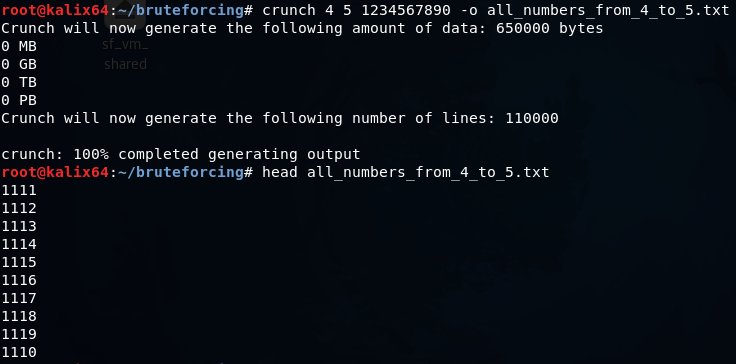
辞書は4〜5桁の長さで作成されます。
テンプレートによる辞書の作成
crunch 10 10 qwe RTY 123 \#\@ -t P^@@,ord%% -o Password_template.txt

最初に、パスワードの長さが指定されます-10文字。 次に、文字セットが一覧表示されます:小文字、大文字、数字、特殊文字。 -tスイッチは、パターンを指定します。
- ^-特殊文字
- @-小文字
- 、-大文字
- %-数字
そして、クランチの動作の3番目のモードは順列です。
crunch 1 1 -p Alex Company Position
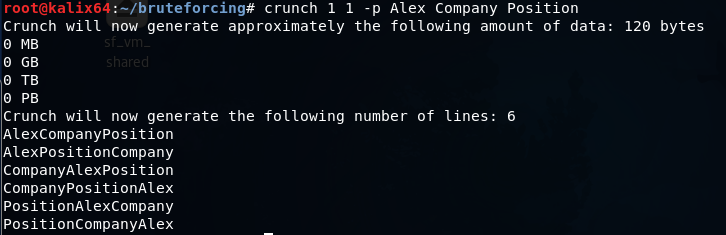
辞書は、Alex、Company、およびPositionという単語のすべての可能な組み合わせで構成されています。
ツールの詳細については、標準のマニュアルページをご覧ください。詳細はこちらです。
マスクプロセッサー
特定の種類の文字のセットだけでなく、一般的に文字、数字、特殊文字を含む独自のセットを指定する必要がある場合があります。 この場合、hashcat brute forceのmaskprocessorユーティリティを使用できます。 公式のhashcat githubからダウンロードできます。
最大4つのカスタム文字セットを指定し、事前定義されたセットを使用できます
?l = abcdefghijklmnopqrstuvwxyz ?u = ABCDEFGHIJKLMNOPQRSTUVWXYZ ?d = 0123456789 ?s = !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ ?a = ?l?u?d?s ?b = 0x00 - 0xff
使用例
mp64.bin -1 Pp -2 \@\#\$ ?1assw?2r?d
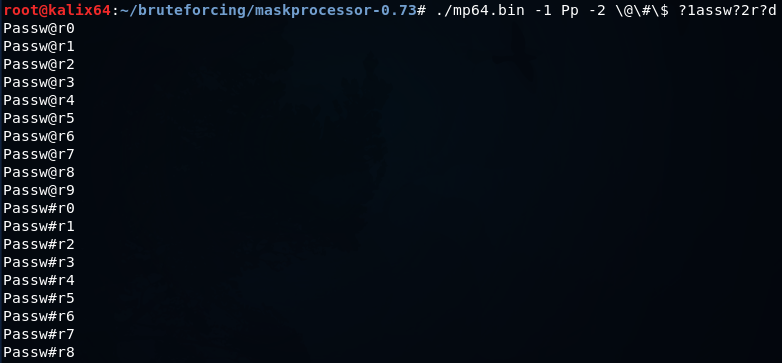
または、一連の数字を指定できますが、このようにいくつかの特殊文字を追加します
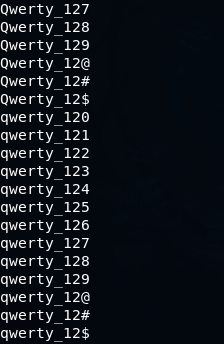
mp64.bin -1 Qq -2 ?d\@\#\$ ?1werty_12?2
この結果が得られます
ジョン・ザ・リッパー
人気のブルートフォーサーであるジョン・ザ・リッパー(JTR)を使用すると、ルールベースの辞書を生成することもできます。 これは--rulesスイッチを使用して行われ、ルール自体はjohn.confで説明されています
これは、NTLMハッシュをクラックするために使用される標準的なルールです。
[List.Rules:NT] : -c T0Q -c T1QT[z0] -c T2QT[z0]T[z1] -c T3QT[z0]T[z1]T[z2] -c T4QT[z0]T[z1]T[z2]T[z3] -c T5QT[z0]T[z1]T[z2]T[z3]T[z4] -c T6QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5] -c T7QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6] -c T8QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7] -c T9QT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8] -c TAQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9] -c TBQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA] -c TCQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB] -c TDQT[z0]T[z1]T[z2]T[z3]T[z4]T[z5]T[z6]T[z7]T[z8]T[z9]T[zA]T[zB]T[zC]
最初の行は、ゼロ位置(T0)の文字の大文字と小文字を変更する必要があることを示しています。文字Qを使用すると、結果の辞書の重複を避けることができます。 2行目では、最初の位置の文字の大文字と小文字が変更され、角括弧でプリプロセッサが指定されているため、ヌル文字が変更されたパスワードなどが生成されます。
レジスターはLMにとって重要ではないため、LMハッシュをブルートフォースして値QWERTY123を取得するとします。
ただし、認証を行うには、大文字と小文字が区別されるNTLMハッシュのブルートフォースを実行する必要があります。 上記のルールを使用すると、次の辞書を取得できます
john -w:QWERTY123.dict --stdout --rules:NT
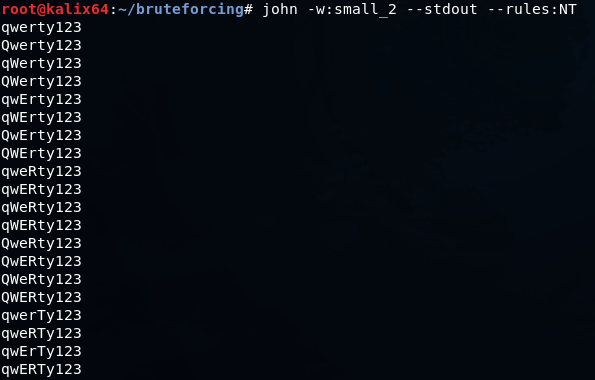
JTRにはデフォルトで多くの既製のルールが含まれていますが、独自のルールを作成することも、すでに作成されているものをベースにして現在の状況に合わせて調整することもできます。
ここで規則の構文に関する詳細を見つけることができます 。
hashcat-tools
別の便利なツールは、人気のあるハッシュキャットブルートフォースからのユーティリティのセットです。
公式サイトからダウンロードできます。
それらのいくつかを検討してください。 すべてのユーティリティの説明は英語でここにあります 。
combinanor.bin-他の2つの辞書の単語から辞書を生成できます。
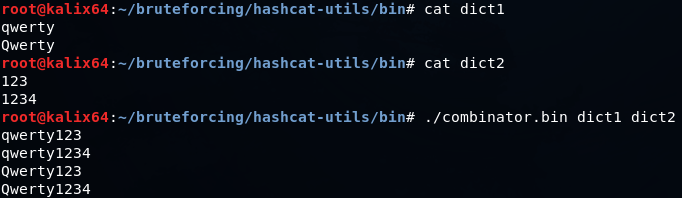
combinanor3.binも同様ですが、2つではなく3つのファイルを入力として受け入れます。
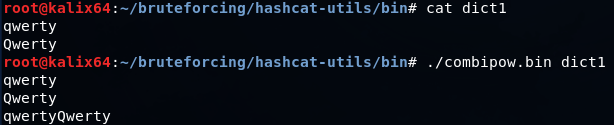
combipow.bin-ファイルにリストされている単語からすべての可能な組み合わせを作成します(crunchの-pスイッチと同様)
cutb.bin-辞書内の単語を指定された長さにトリミングします。 オフセットを指定できます

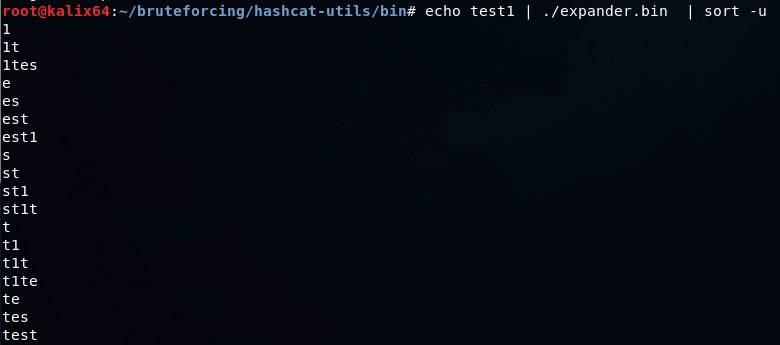
expander.bin-入力用の単語を受け取り、それらを文字に解析し、結合してSTDOUTに送信します
permute.bin-hashcatがPermutation攻撃のように攻撃するときに使用する辞書を作成します。 辞書を使用する前に、準備ユーティリティを通過する必要があります。
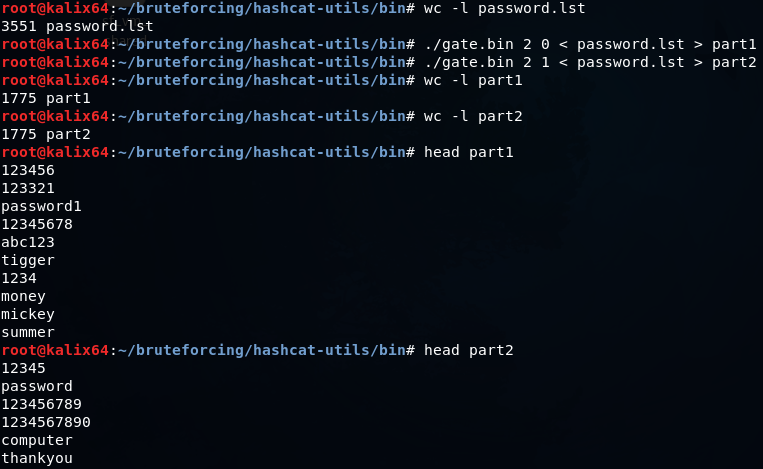
gate.bin-辞書を複数の部分に分割し、複数のコアまたは複数のマシンで並列処理します。 以下の例では、標準のJTR辞書を2つの部分に分けています。 最初の部分には、0、2、4、6、...と番号付けされた単語が含まれます。 2番目の1、3、5、7、...
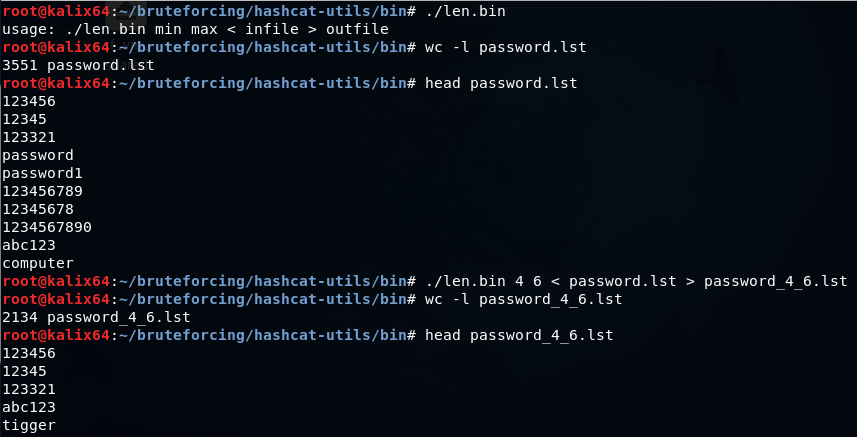
len.bin-最小から最大までの特定の長さの単語のみを辞書に残します
mli2.bin-2つの辞書を組み合わせます。
req-include.binは、ルールに適合しないものをすべて辞書から削除する非常に便利なツールです。 たとえば、パスワードポリシーに従って、パスワードには大文字、数字、および特殊文字が含まれている必要があることがわかっています。

番号は表に基づいて選択されます

この方法で有名なrockyou辞書を正規化すると、そのサイズを270倍減らすことができます! 故意に誤った組み合わせにリソースを浪費しないでください。

req-exclude.binはreq-includeと同じですが、まったく逆の動作をします。
rli.bin-このユーティリティは、2番目の辞書に値が見つかった場合、最初の辞書から値を削除します。 複数の辞書から1つの辞書を作成する場合に便利です。
手元にユーティリティがない場合
hashcat-utilsまたはcrunchセットを使用する方法はないことが判明するかもしれませんが、緊急に辞書を作成するか、正規化する必要があります。 一部のアルゴリズムは実装が非常に困難ですが、基本的な操作はコマンドラインで簡単に実行できます。
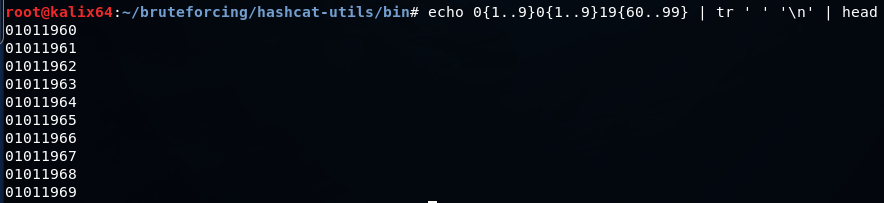
一連の同様のコマンドを使用して、日付付きの簡単な辞書を作成できます
echo 0{1..9}0{1..9}19{60..99} | tr ' ' '\n' >> dates
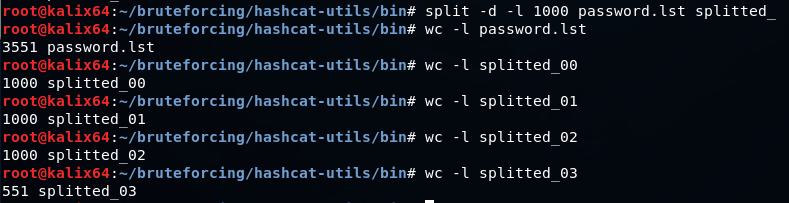
辞書を並列処理のために部分に分割する必要がある場合は、splitコマンドを使用できます
split -d -l 1000 password.lst splitted_
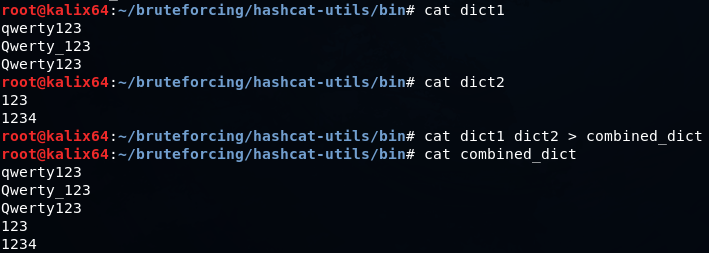
このような2つの辞書をすばやく組み合わせることができます
cat dict1 dict2 > combined_dict
各単語の最初または最後の文字を大文字にするには、それぞれコマンドを実行する必要があります
sed 's/^./\u&/' dict_file sed 's/.$/\u&/' dict_file
レジスタを下位に変換するには、「l」の「u」に注意する必要があります
このように辞書から各単語の先頭に何かを追加できます
sed 's/^./word/' dict_file
そして最後に単語を追加できます
sed 's/.$/word/' dict_file
次のコマンドは、辞書の各単語に0から99までの数字を先頭に追加できます
for i in $(cat dict_file) ; do seq -f %02.0f$i 0 99 ; done > numbers_dict_file
少なくとも2つの数字が存在しない値の辞書をクリアできます。
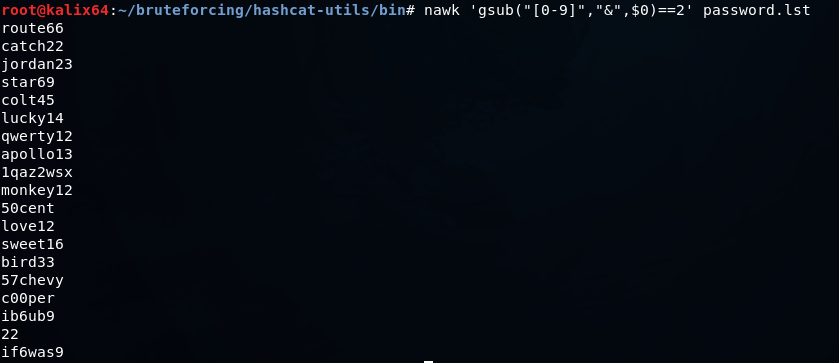
nawk 'gsub("[0-9]","&",$0)==2' password.lst
取得します
これらはほんの一例です。 Pythonや他のスクリプト言語でより複雑な処理を記述できます。 ただし、高品質の辞書を作成してターゲットプロトコルに正規化することは、侵入テストの重要な段階であることを常に覚えておく必要があります。