
8月11日、Mail.Ruは次のHighloadCupを発表します システムプログラマー バックエンド開発者。
簡単に言うと、タスクは次のとおりでした:docker、4コア、4GBのメモリ、10GBのHDD、 apiのセット 、そしてあなたは最短時間でクエリに答える必要があります。 言語とテクノロジーのスタックは無制限です。 ファントムエンジンを搭載したYandexタンクがテストシステムでした。
このような状況でファイナルで13位に達する方法については、この記事になります。
問題の声明
タスクの詳細な説明は、ハブの参加者の 1人の出版物 、または競技の公式ページにあります。 テストの実行方法はここに書かれています 。
Apiは、データベースから単純にレコードを返すための3つのgetリクエスト、データ集約のための2つのgetリクエスト、データ変更のための3つのpostリクエスト、およびデータを追加するための3 postリクエストで構成されました。
次の条件がすぐに合意され、生活を大きく促進しました。
- ネットワーク損失なし(データはループバックを通過します)
- メモリに収まることが保証されたデータ
- 競合する投稿リクエストはありません(つまり、同じレコードを同時に変更しようとすることはありません)
- リクエストの投稿と取得が同時に行われることはありません(リクエストの取得のみまたはリクエストの投稿のみ)
- データは削除されず、変更または追加されるだけです
リクエストは3つの部分に分けられました。まず、ソースデータに対するget-request、次にデータの追加/変更に対する一連のpost-request、変更されたデータに対する最後の最も強力な一連のget-requestです。 第二段階は非常に重要でした、なぜなら 誤ってデータを追加または変更すると、第3フェーズで多くのエラーが発生する可能性があり、結果として大きな罰金になります。 この段階では、最後の段階では、リクエスト数が100から2000rpsに直線的に増加しました。
別の条件は、1つの要求が1つの接続であるということでした。 キープアライブはありませんが、ある時点で拒否しました。get-requestはすべてキープアライブからのもので、ポストリクエストはそれぞれ新しい接続に対するものでした。
私の夢は、Linux、C ++、およびシステムプログラミング(現実はひどいものですが)であり、私自身は何も否定せず、頭から飛び込むことにしました。
行こう
なぜなら 高負荷については何も知らないよりも少し知っていましたが、最近までウェブサーバーを作成する必要がないことを望んでいましたが、問題を解決するための最初のステップは適切なウェブサーバーを見つけることでした。 私の視線はproxygenをつかみました。 一般的に、サーバーは良好であると想定されていました-Facebookと同じくらいハイロイドについて知っている人は他にいますか?
ソースコードには、このサーバーの使用方法の例がいくつか含まれています。
HTTPServerOptions options; options.threads = static_cast<size_t>(FLAGS_threads); options.idleTimeout = std::chrono::milliseconds(60000); options.shutdownOn = {SIGINT, SIGTERM}; options.enableContentCompression = false; options.handlerFactories = RequestHandlerChain() .addThen<EchoHandlerFactory>() .build(); HTTPServer server(std::move(options)); server.bind(IPs); // Start HTTPServer mainloop in a separate thread std::thread t([&] () { server.start(); });
そして、受け入れられた接続ごとに、ファクトリメソッドが呼び出されます
class EchoHandlerFactory : public RequestHandlerFactory { public: // ... RequestHandler* onRequest(RequestHandler*, HTTPMessage*) noexcept override { return new EchoHandler(stats_.get()); } // ... private: folly::ThreadLocalPtr<EchoStats> stats_; };
new EchoHandler()
、すべてのリクエストに対してnew EchoHandler()
が、私はこれを重要視しませんでした。
EchoHandler
自体は、 proxygen::RequestHandler
実装する必要がありproxygen::RequestHandler
。
class EchoHandler : public proxygen::RequestHandler { public: void onRequest(std::unique_ptr<proxygen::HTTPMessage> headers) noexcept override; void onBody(std::unique_ptr<folly::IOBuf> body) noexcept override; void onEOM() noexcept override; void onUpgrade(proxygen::UpgradeProtocol proto) noexcept override; void requestComplete() noexcept override; void onError(proxygen::ProxygenError err) noexcept override; };
すべてが美しく美しく見えますが、受信データを処理するだけです。
APIセットは単純で小さいため、 std::regex
を使用してルーティングを実装しました。 std::stringstream
を使用して、即座に回答を生成しました。 現時点では、パフォーマンスに煩わされることはありませんでした。目標は、実用的なプロトタイプを取得することでした。
データはメモリに配置されるため、メモリに保存する必要があります!
データ構造は次のようになりました。
struct Location { std::string place; std::string country; std::string city; uint32_t distance = 0; std::string Serialize(uint32_t id) const { std::stringstream data; data << "{" << "\"id\":" << id << "," << "\"place\":\"" << place << "\"," << "\"country\":\"" << country << "\"," << "\"city\":\"" << city << "\"," << "\"distance\":" << distance << "}"; return std::move(data.str()); } };
「データベース」の初期バージョンは次のとおりです。
template <class T> class InMemoryStorage { public: typedef std::unordered_map<uint32_t, T*> Map; InMemoryStorage(); bool Add(uint32_t id, T&& data, T** pointer); T* Get(uint32_t id); private: std::vector<std::forward_list<T>> buckets_; std::vector<Map> bucket_indexes_; std::vector<std::mutex> bucket_mutexes_; }; template <class T> InMemoryStorage<T>::InMemoryStorage() : buckets_(BUCKETS_COUNT), bucket_indexes_(BUCKETS_COUNT), bucket_mutexes_(BUCKETS_COUNT) { } template <class T> bool InMemoryStorage<T>::Add(uint32_t id, T&& data, T** pointer) { int bucket_id = id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); Map& bucket_index = bucket_indexes_[bucket_id]; auto it = bucket_index.find(id); if (it != bucket_index.end()) { return false; } buckets_[bucket_id].emplace_front(data); bucket_index.emplace(id, &buckets_[bucket_id].front()); if (pointer) *pointer = &buckets_[bucket_id].front(); return true; } template <class T> T* InMemoryStorage<T>::Get(uint32_t id) { int bucket_id = id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); Map& bucket = bucket_indexes_[bucket_id]; auto it = bucket.find(id); if (it != bucket.end()) { return it->second; } return nullptr; }
概念は次のとおりです。慣例により、インデックスは整数の32ビット数です。つまり、この範囲内で任意のインデックスを持つデータを追加する必要はありません(ああ、なんて間違っているのでしょう!)。 したがって、スレッドのmutexのタイムアウトを減らすために、BUCKETS_COUNT(= 10)ストレージがありました。
なぜなら データサンプリングのリクエストがあり、ユーザーがusers -> visits
すべての場所、およびその場所に残ったすべてのレビューをすばやく検索する必要があり、 users -> visits
とlocations -> visits
インデックスが必要でした。
同じイデオロギーで、インデックス用に次のコードが作成されました。
template<class T> class MultiIndex { public: MultiIndex() : buckets_(BUCKETS_COUNT), bucket_mutexes_(BUCKETS_COUNT) { } void Add(uint32_t id, T* pointer) { int bucket_id = id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); buckets_[bucket_id].insert(std::make_pair(id, pointer)); } void Replace(uint32_t old_id, uint32_t new_id, T* val) { int bucket_id = old_id % BUCKETS_COUNT; { std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); auto range = buckets_[bucket_id].equal_range(old_id); auto it = range.first; while (it != range.second) { if (it->second == val) { buckets_[bucket_id].erase(it); break; } ++it; } } bucket_id = new_id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); buckets_[bucket_id].insert(std::make_pair(new_id, val)); } std::vector<T*> GetValues(uint32_t id) { int bucket_id = id % BUCKETS_COUNT; std::lock_guard<std::mutex> lock(bucket_mutexes_[bucket_id]); auto range = buckets_[bucket_id].equal_range(id); auto it = range.first; std::vector<T*> result; while (it != range.second) { result.push_back(it->second); ++it; } return std::move(result); } private: std::vector<std::unordered_multimap<uint32_t, T*>> buckets_; std::vector<std::mutex> bucket_mutexes_; };
当初、オーガナイザーはデータベースを初期化するテストデータのみをレイアウトしましたが、サンプルリクエストはなかったため、 Insomniaを使用してコードのテストを開始しました。これにより、リクエストの送信と変更、および回答の確認が容易になりました。
少し後に、主催者は参加者に同情し、戦車の弾薬と完全な評価と砲撃データを投稿しました。私は簡単なスクリプトを書いて、ローカルでソリューションの正確性をテストできるようにし、将来的に非常に役立ちました。
高負荷スタート
そして最後に、プロトタイプが完成し、ローカルではテスターがすべては問題ないと言い、決定を送信する時が来ました。 最初の打ち上げは非常に刺激的で、何かが間違っていたことを示しました...
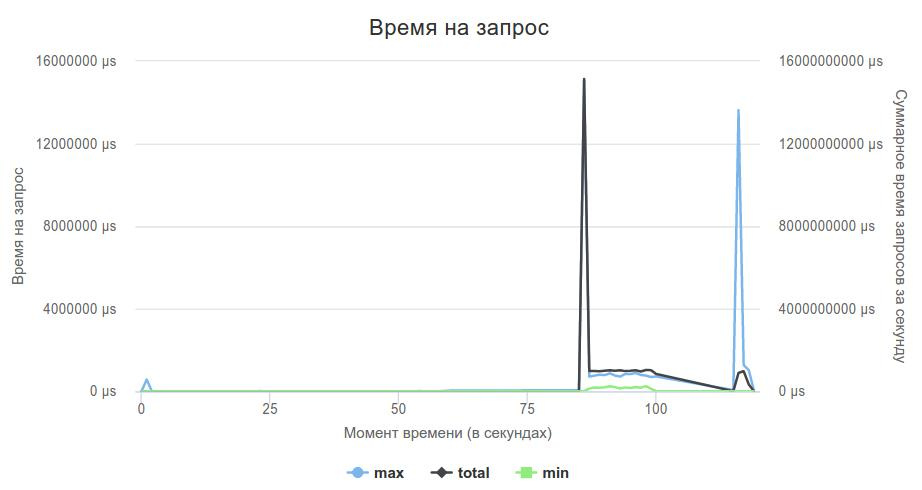
私のサーバーは2000rpsの負荷を保持していませんでした。 私が覚えている限り、この時点でのリーダーは約数百秒でした。
次に、サーバーが負荷にまったく対処しているかどうか、またはこれらが実装の問題であるかどうかを確認することにしました。 私はすべてのリクエストに空のjsonを単に与え、評価攻撃を開始し、proxygen自体が負荷に対処できないことを確認するコードを書きました。
void onEOM() noexcept override { proxygen::ResponseBuilder(downstream_) .status(200, "OK") .header("Content-Type", "application/json") .body("{}") .sendWithEOM(); }
これが、3番目のフェーズチャートの外観です。
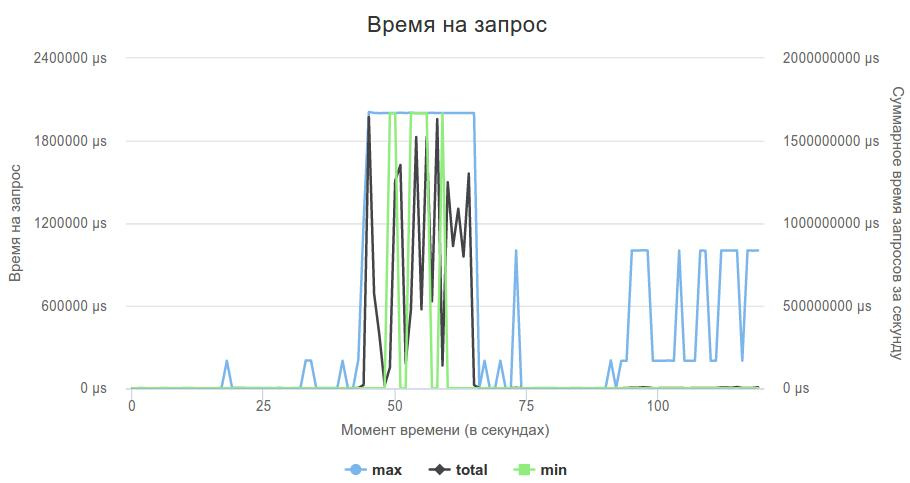
一方で、これが私のコードの問題ではないことは良かったのですが、他方では、サーバーで何をすべきかという疑問が生じました。 私はまだ自分で書くのを避けたいと思っていました。
次のテストはカラスでした。 私はそれが本当に好きだったとすぐに言わなければなりません、そして、突然、将来、私がプラスhttp-serverを必要とするならば、それは彼です。 ヘッダーベースのサーバー、proxygenの代わりにプロジェクトに追加し、リクエストハンドラーを少し書き直して、新しいサーバーで動作するようにしました。
使い方はとても簡単です。
crow::SimpleApp app; CROW_ROUTE(app, "/users/<uint>").methods("GET"_method, "POST"_method) ( [](const crow::request& req, crow::response& res, uint32_t id) { if (req.method == crow::HTTPMethod::GET) { get_handlers::GetUsers(req, res, id); } else { post_handlers::UpdateUsers(req, res, id); } }); app.bindaddr("0.0.0.0").port(80).multithreaded().run();
apiに適切な説明がない場合、サーバー自体が404を送信します。必要なハンドラーがある場合、この場合、リクエストからuintパラメーターを取り出して、パラメーターとしてハンドラーに渡します。
しかし、苦い経験から教えられた新しいサーバーを使用する前に、負荷に対処できるかどうかを確認することにしました。 前のケースと同様に、ハンドラーは、リクエストに対して空のjsonを返し、評価攻撃のために送信することを記述しました。
カラスが管理し、彼は負荷を保持し、今私は私のロジックを追加する必要がありました。
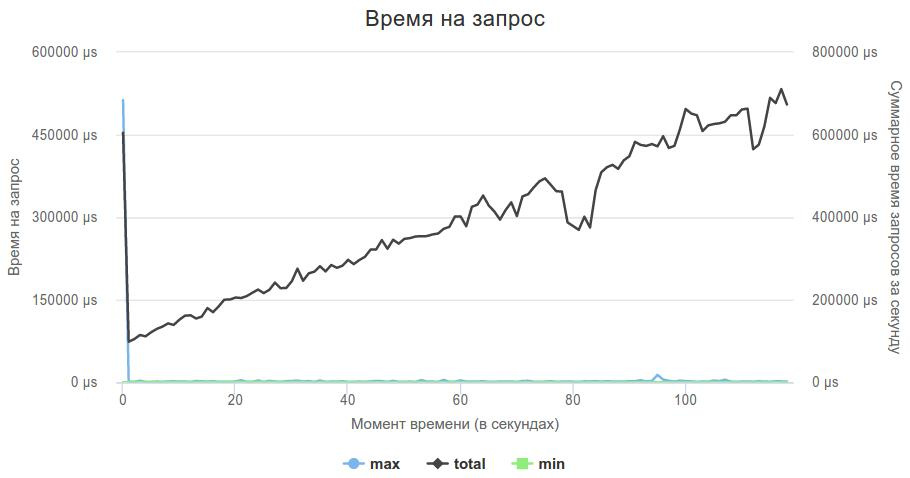
なぜなら ロジックは既に記述されているため、コードを新しいサーバーに適応させるのは非常に簡単でした。 すべてがうまくいきました!

100秒はすでに何かあります。サーバー検索ではなく、ロジックの最適化を開始できます。
なぜなら 私のサーバーはまだstd::stringstream
を使用して応答を生成していましたが、最初はこれを取り除くことにしました。 レコードをデータベースに追加した時点で、ヘッダー付きの完全な応答を含む行がすぐに形成され、要求時に返されました。
この時点で、次の2つの理由により、ヘッダーを完全に追加することにしました。
- 余分な
write()
が削除されます - データはわずか200MBで、十分なメモリがあります。
電報のチャットルームで私自身が多くのコピーを壊した別の問題は、年齢によるユーザーのフィルターです。 この問題によると、ユーザーの年齢はUNIXタイムスタンプに保存され、リクエストではfromAge=30&toAge=70
のように丸1年の形式で格納されていました。 年は秒にどのようにつながるのですか? うるう年を検討するかどうか? また、ユーザーが2月29日に生まれた場合はどうなりますか?
結果は、これらすべての問題を一挙に解決するコードでした:
static time_t t = g_generate_time; // get time now static struct tm now = (*localtime(&t)); if (search_flags & QueryFlags::FROM_AGE) { tm from_age_tm = now; from_age_tm.tm_year -= from_age; time_t from_age_t = mktime(&from_age_tm); if (user->birth_date > from_age_t) { continue; } }
その結果、生産性が100秒から50秒に2倍に増加しました。
一見悪くはありませんが、その時点でリーダーは20秒未満で、結果は20〜40位でした。
この時点で、さらに2つの観察が行われました。
- データインデックスは常にギャップなしで1から順になりました
- インデックスサイズは、ユーザーと場所で約1M、訪問で約10Mでした。
データストレージ用のハッシュ、ミューテックス、バケットは不要であり、データはベクター内のインデックスによって完全に保存できることが明らかになりました。 最終バージョンはここにあります (インデックスを処理するためのコードの一部は、それらが突然制限を超えた場合に最終に追加されました)。
私のロジックのパフォーマンスに強く影響する明らかな瞬間はないように見えました。 ほとんどの場合、最適化の助けを借りて、さらに数秒遅れる可能性がありますが、半分は捨てなければなりませんでした。
再び、私はネットワーク/サーバーでの作業に休み始めました。 サーバーのソースを駆け抜けて、残念な結論に至りました-送信時に、2つの不必要なデータコピーが発生しました。最初にサーバーの内部バッファーへ、次に送信バッファーへ。
自転車に乗りたい...
あなたのウェブサーバーを書き始めることほど、世界で無力で無責任で不道徳なものはありません。 そして、私はすぐにそれに突入することを知っていました。
そして、この瞬間が来ました。
サーバーを作成する際に、いくつかの仮定が行われました。
- タンクはループバックを介して発火します。つまり、損失はありません。
- タンクからのパッケージは非常に小さいため、1回の読み取りで差し引くことができます()
- 私の答えも小さいので、それらはwrite()の1回の呼び出しで記録され、書き込み呼び出しはブロックされません
- 有効なgetおよびpostリクエストのみがタンクから送信されます
一般に、いくつかの部分でread()およびwrite()を正直にサポートすることはできましたが、現在のバージョンは機能したため、これは「後で」のままでした。
一連の実験の後、メインスレッドでaccept()をブロックし、epollに新しいソケットを追加し、1つのepollfdでリッスンしてデータを処理するstd::thread::hardware_concurrency()
スレッドをブロックしました。
unsigned int thread_nums = std::thread::hardware_concurrency(); for (unsigned int i = 0; i < thread_nums; ++i) { threads.push_back(std::thread([epollfd, max_events]() { epoll_event events[max_events]; int nfds = 0; while (true) { nfds = epoll_wait(epollfd, events, max_events, 0); // ... for (int n = 0; n < nfds; ++n) { // ... } } })); } while (true) { int sock = accept(listener, NULL, NULL); // ... struct epoll_event ev; ev.events = EPOLLIN | EPOLLET | EPOLLONESHOT; ev.data.fd = sock; if (epoll_ctl(epollfd, EPOLL_CTL_ADD, sock, &ev) == -1) { perror("epoll_ctl: conn_sock"); exit(EXIT_FAILURE); } }
EPOLLET
は、1つのストリームのみがEPOLLET
されることを保証します。また、ソケットに未読データがある場合、すべてがEAGAIN
前に読み取られるまで、 epoll
はソケットで動作しません。 したがって、このフラグを使用するための次の推奨事項は、ソケットを非ブロッキングにし、エラーが返されるまで読み取ることです。 しかし、仮定に示されているように、要求は小さく、 read()
1回の呼び出しでread()
れます。ソケットにはデータがなく、 epoll
は通常、新しいデータが到着したときに機能しました。
ここで1つの間違いを犯しました: std::thread::hardware_concurrency()
を使用して使用可能なスレッドの数を決定しましたが、この呼び出しは10(サーバー上のコアの数)を返し、Dockerでは4つのコアしか使用できなかったため、これは悪い考えでした。 ただし、これは結果にほとんど影響しませんでした。
httpの解析には、 http-parser (Crowも使用)、url- libyuarelの解析、およびquery-request- qs_parseのパラメーターのデコードを使用しました。 qs_parseはCrowでも使用され、URLを解析できますが、たまたまパラメーターのデコードにのみ使用しました。
この方法で実装を書き直した後、なんとか10秒を投げることができ、今では40秒になりました。
モーア高負荷
競技会の終わりまで1週間半が残っていましたが、主催者は200 MBのデータと2000 rpで十分ではないと判断し、データサイズと負荷を5倍に増やしました:データはアンパック形式で1 GBを占有し始め、第3フェーズで発火率は10,000 rpsに増加しました。
全体の答えを保持した実装は、メモリに入るのをやめ、部分的に答えを書くための多くのwrite()呼び出しを行うことも悪い考えのように思われ、私は writev()を使用する決定を書き直しました :ストレージ中にデータを複製する必要はありませんでした記録は1つのシステムコールで行われました(最終版の改善も追加されました:writevはiovec配列の1024要素を一度に書き込むことができ、 /users/<id>/locations
実装は非常に高価であり、データレコードを分割する機能を追加しました2個に)。
実装を開始してから245秒の素晴らしい時間を(良い意味で)得ました。その結果、結果テーブルで2位になりました。
テストシステムは非常にランダムであり、同じソリューションでは数回変動する時間が示される可能性があり、評価攻撃は1日に2回しか実行できないため、次の改善のどれが最終結果につながったのか、どれがそうでなかったのかは明確ではありません。
残りの週にわたって、次の最適化を行いました。
フォームのコールチェーンを置換
DBInstance::GetDbInstance()->GetLocations()
ポインターへ
g_location_storage
それから、私は正直なhttpパーサーはgetリクエストには必要ないと思いました。getリクエストの場合、すぐにURLを取得でき、他のことは気にしません。 幸いなことに、修正されたタンクリクエストによりこれが許可されました。 また、バッファを台無しにできることも注目に値します(たとえば、URLの最後に\0
を書き込みます)。 Libyuarelも同じように機能します。
HttpData http_data; if (buf[0] == 'G') { char* url_start = buf + 4; http_data.url = url_start; char* it = url_start; int url_len = 0; while (*it++ != ' ') { ++url_len; } http_data.url_length = url_len; http_data.method = HTTP_GET; } else { http_parser_init(parser.get(), HTTP_REQUEST); parser->data = &http_data; int nparsed = http_parser_execute( parser.get(), &settings, buf, readed); if (nparsed != readed) { close(sock); continue; } http_data.method = parser->method; } Route(http_data);
また、電報のチャットルームで、ヘッダーのフィールドの数のみがサーバーでチェックされ、内容はチェックされず、ヘッダーは容赦なくカットされたという質問が発生しました。
const char* header = "HTTP/1.1 200 OK\r\n" "S: b\r\n" "C: k\r\n" "B: a\r\n" "Content-Length: ";
奇妙な改善のように見えますが、多くのリクエストではレスポンスのサイズが大幅に削減されています。 残念ながら、これが少なくともある程度の増加をもたらしたかどうかは不明です。
これらのすべての変更により、サンドボックスでのベストタイムは最大197秒であり、これは終盤 で 16位、 最終的には 188秒、13位でした。
ソリューションコードは次の場所にあります: https : //github.com/evgsid/highload_solution
最終時点の決定コード: https : //github.com/evgsid/highload_solution/tree/final
魔法の薬
それでは、魔法について少し話しましょう。
ランキングの最初の6位はサンドボックスで特に際立っていました。時間は約140秒で、次は約190秒、さらに時間は徐々に増加しました。
最初の6人が何らかの魔法の薬を見つけたことは明らかでした。
ユーザースペース->カーネルスペースからのコピーを除外する実験としてsendfileとmmapを試しましたが、テストではパフォーマンスの向上は見られませんでした。
そして今、決勝戦の最後の数分で、意思決定は終了し、リーダーたちは魔法の薬BUSY WAITを共有します。
他のすべてが等しい場合、 epoll(x, y, z, 0)
を使用する場合にepoll(x, y, z, -1)
180秒を与えたソリューションはすぐに150秒以下を与えました。 もちろん、これは運用ソリューションではありませんが、遅延を大幅に削減します。
このテーマに関する優れた記事は、10Gbpsイーサネットで低レイテンシを実現する方法をご覧ください。
私の解決策は、ビジー待機を使用したときの最終結果で188でしたが、すぐに136秒を示しました。これは、最終記事で4番目、この記事を書いている時点でサンドボックスで8位です。
これが最適なソリューションのグラフです。
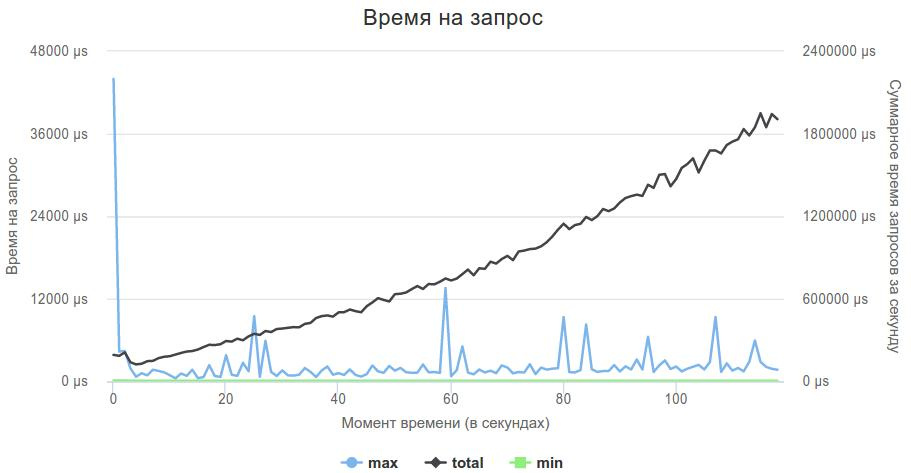
実際、ビジー待機は非常に慎重に使用する必要があります。 私の解決策は、メインスレッドが接続を受け入れ、4つのスレッドがソケットからのデータのみを処理する場合、ビジー待機を使用すると、ポストフェーズで強く低下し始めました。受け入れに十分なプロセッサ時間がなく、解決策が非常に遅かったためです。 処理スレッドの数を3に減らすと、この問題は完全に解決されました。
おわりに
主催者は素晴らしく、競技は面白いです。
とてもクールでした! これらは忘れられない3週間のシステムプログラミングでした。 妻と子供たちが休暇中だったことに感謝します。そうでなければ、家族は離婚に近づきます。 夜寝なかった主催者のおかげで、参加者を助け、戦車と戦った。 多くの新しいアイデアを提供し、新しいソリューションを探し求めた参加者に感謝します。
次のコンテストを楽しみにしています!