翻訳者から:
わずかな追加と修正を加えて、適応した翻訳を準備しました。 私は元の記事のややプロパガンダのスタイルを保持しましたが、それ自体、その中の情報は興味深いので、それにもかかわらず、それを翻訳することにしました。
人々はしばしば私に尋ねます:
Streams、CompletableFutures、Optionalsで同じことができるのに、なぜRxJavaまたはReactorを使用する必要があるのですか?

実際、問題は、ほとんどの場合、単純なタスクを処理しており、これらのライブラリは本当に必要ないということです。 しかし、事態が複雑になると、,いコードを書かなければなりません。 その後、このコードはますます複雑になり、保守が難しくなります。 RxJavaとReactorには、今後何年もあなたのニーズを満たす多くの便利な機能があります。
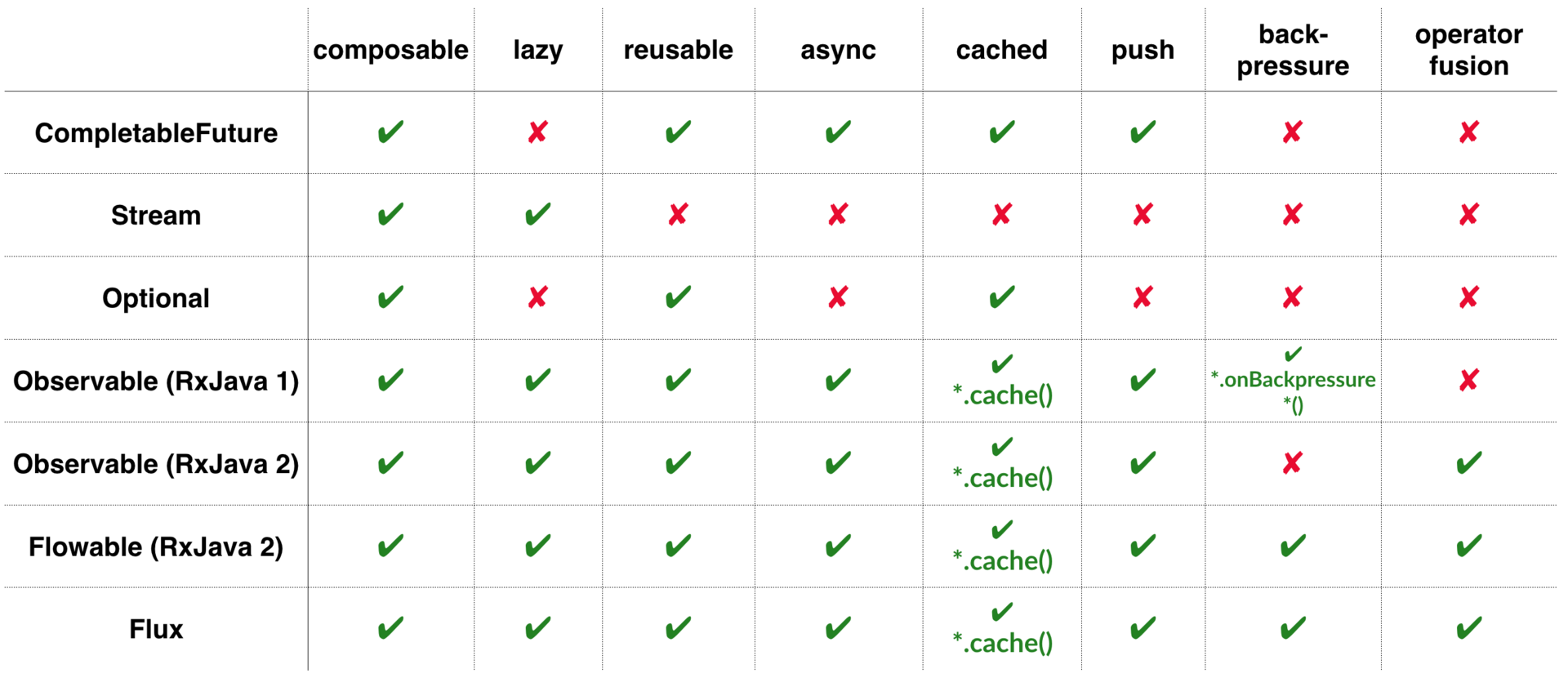
これらのライブラリと標準のJava機能の違いを理解するのに役立つ8つの基準を定義しましょう。
- コンポーザブル
- レイジー(遅延/レイジー)
- 再利用可能
- 非同期
- キャッシュ可能
- プッシュまたはプル(受信者または受信者)
- 背圧
- 演算子融合
そして、比較するクラスを選択しましょう。
- CompletableFuture
- ストリーム
- オプショナル
- 観測可能(RxJava 1)
- 観測可能(RxJava 2)
- 流動性(RxJava 2)
- フラックス(リアクターコア)
準備はいい? 集まって運転した!
コンポーザブル
これらのクラスはすべて構成可能であり、機能的に考えることができます( 著者のタイプミスは修正されます-約 。 このために私たちは彼らを愛しています。
CompletableFuture-多くの.then*()
メソッドにより、何もまたは単一の+スロー可能値がステージ間で渡されるチェーンを構築できます。
ストリーム -入力データを変換できる連結演算子の束。 ステージからステージにN値を渡すことができます。
オプション -中間演算子のペア: .map()
.flatMap()
.filter()
。
Observable、Flowable、Flux - Streamに似ています 。
怠け者
CompletableFutureは、非同期の結果を単純に保存するため、レイジーではありません。 このようなオブジェクトは、すでに開始されている作業を表すために作成されます。 ( 数値の調整は修正されます-約。 )彼らは仕事について何も知りませんが、結果はわかっています。 したがって、上流に移動してチェーンの実行を上から下に開始する方法はありません。 CompletableFuture
値が設定されると、次のステップが開始されCompletableFuture
。
( 結論は正しいが、理由は議論の余地がある。実際、 CompletableFuture
ない。なぜなら、結果を求める前にその値の検索と設定が始まるからである-およそper )
ストリーム -すべての中間操作は遅延します。 すべての最終操作により、コンピューティングプロセスが開始されます。
オプション -遅延ではなく、すべての操作がすぐに実行されます。
Observable、Flowable、Flux-サブスクライバー(サブスクライバー)がいるまで何も起こりません。
再利用可能
CompletableFuture-値の単なるラッパーであるため、再利用可能です。 ただし、このラッパーは可変であるため、慎重に使用する必要があります。 誰も.obtrude*()
を呼び出さないことが確実な場合、これは安全です。
ストリーム -再利用不可。 JavaDocで述べられているように :
ストリーム(中間または最終)の操作は1回だけ実行する必要があります。 スレッドの実装は、スレッドが再利用されていることを検出した場合、IllegalStateExceptionをスローする場合があります。 ただし、ストリームの一部の操作は、Streamクラスの新しいオブジェクトではなく、受信者に戻る場合があるため、再利用を常に検出できるとは限りません。
Optionalは不変であり、すべての作業がすぐに行われるため、 Optionalは完全に再利用可能です。
観察可能、流動可能、フラックス -再利用可能に設計。 すべてのステージは、サブスクライバーが存在する場合にのみ、開始点から実行され始めます。
非同期
CompletableFuture-まあ、このクラスのポイントは、操作を非同期にバインドすることです。 CompletableFuture
は、一部のExecutor
関連付けられた作業を表します。 タスクを作成するときにExecutor
を明示的に指定しない限り、通常のForkJoinPool
ます。 このプールはForkJoinPool.commonPool()
を使用して取得できます。デフォルトでは、システム内のハードウェアスレッドと同じ数のスレッド(通常はコアの数、コアがハイパースレッディングをサポートしている場合は2倍)を作成します。 ただし、JVMパラメーターを使用してこのプールのスレッド数を設定できます
-Djava.util.concurrent.ForkJoinPool.common.parallelism=?
または、ワークステップを作成するたびに新しいExecutor
使用します。
ストリーム -非同期処理の可能性はありませんが、計算を並列に実行して、並列化されたストリームstream.parallel()
作成できます。
オプション -いいえ、それは単なるコンテナです。
Observable、Flowable、Flux-非同期システムの構築を目的としていますが、デフォルトでは同期です。 observeOn
とobserveOn
使用すると、サブスクリプションの登録と通知の受信を制御できます(つまり、オブザーバーでonNext
/ OnError
/ OnCompleted
をトリガーするスレッド)。
subscribeOn
Observable.create
を実行するScheduler
を決定Observable.create
ます。 自分でcreate
呼び出さない場合でも、内部的に同等のものがあります。 例:
Observable .fromCallable(() -> { log.info("Reading on thread: " + currentThread().getName()); return readFile("input.txt"); }) .map(text -> { log.info("Map on thread: " + currentThread().getName()); return text.length(); }) .subscribeOn(Schedulers.io()) // <-- setting scheduler .subscribe(value -> { log.info("Result on thread: " + currentThread().getName()); });
出力:
Reading file on thread: RxIoScheduler-2 Map on thread: RxIoScheduler-2 Result on thread: RxIoScheduler-2
一方、 observeOn()
は、 observeOn()
続く後続のステップを呼び出すために使用されるScheduler
制御します。 例:
Observable .fromCallable(() -> { log.info("Reading on thread: " + currentThread().getName()); return readFile("input.txt"); }) .observeOn(Schedulers.computation()) // <-- setting scheduler .map(text -> { log.info("Map on thread: " + currentThread().getName()); return text.length(); }) .subscribeOn(Schedulers.io()) // <-- setting scheduler .subscribe(value -> { log.info("Result on thread: " + currentThread().getName()); });
出力:
Reading file on thread: RxIoScheduler-2 Map on thread: RxComputationScheduler-1 Result on thread: RxComputationScheduler-1
キャッシュ可能
再利用とキャッシュの違いは何ですか? チェーンA
、チェーンB = A + O
およびC = A + O
を作成するために2回再利用するとしますC = A + O
B
& C
が成功した場合、クラスは再利用可能です。
B
& C
が成功し、チェーンA
各ステージが1回だけ呼び出されると、クラスがキャッシュされます。 キャッシュするには、クラスが再利用可能でなければなりません。
CompletableFutureは、再利用性と同じ答えです。
ストリーム -最終ステートメントが呼び出されるまで、中間結果をキャッシュする方法はありません。
すべての作業はすぐに行われるため、 オプションは「キャッシュ」です。
Observable、Flowable、Flux-デフォルトではキャッシュされません。 ただし、 .cache()
呼び出してA
キャッシュ可能にできます。
Observable<Integer> work = Observable.fromCallable(() -> { System.out.println("Doing some work"); return 10; }); work.subscribe(System.out::println); work.map(i -> i * 2).subscribe(System.out::println);
出力:
Doing some work 10 Doing some work 20
.cache()
:
Observable<Integer> work = Observable.fromCallable(() -> { System.out.println("Doing some work"); return 10; }).cache(); // <- apply caching work.subscribe(System.out::println); work.map(i -> i * 2).subscribe(System.out::println);
出力:
Doing some work 10 20
プッシュまたはプル
プルの原則に関するストリームおよびオプションの作業。 結果は、さまざまなメソッド( .get()
.collect()
など)を呼び出すことによってチェーンから取得されます。 プルは、多くの場合、ブロッキング、同期実行に関連付けられます。 メソッドを呼び出すと、スレッドはデータの到着を待機し始めます。 それまで、スレッドはブロックされます。
CompletableFuture、Observable、Flowable、FluxはPushの原則に基づいて動作します。 チェーンにサブスクライブし、処理が必要になると通知されます。 プッシュは、多くの場合、非ブロッキング非同期実行に関連付けられています。 チェーンがスレッドで実行されている間は何でもできます。 実行するコードについては既に説明しているため、次のステップで通知によりこのコードの実行が開始されます。
背圧
流れを抑えるためには、プッシュの原理に基づいてチェーンを構築する必要があります。
スレッドの封じ込めは、非同期ステップの一部が値を十分に速く処理できず、チェーンを上に移動する方法が必要な場合に、それらを遅くするように要求するチェーン内の状況です。 容認できない状況は、データが多すぎるために何らかの段階で拒否が発生する場合です( 著者の言葉遣いのあいまいさが保持されます-約Per。 )。
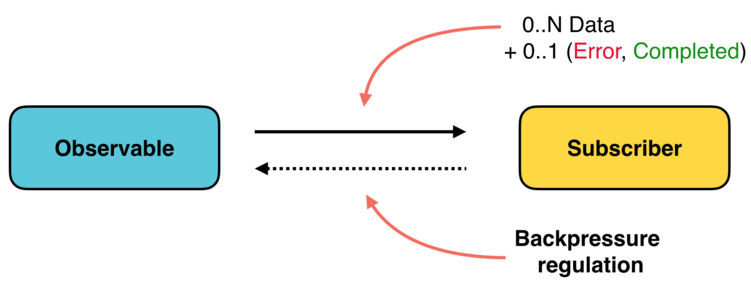
- Stream & Optionalは、Pullの原理に基づいて構築されているため、このメカニズムをサポートしていません。
- CompletableFutureは、結果として0または1を返すため、この問題を解決する必要はありません。
Observable(RxJava 1)、Flowable、Flux-この問題を解決します。 主な戦略は次のとおりです。
- バッファリング -チェーンの下流で必要になるまで、すべての
onNext
値をバッファに保存します。 - 新しいものを破棄 -チェーンの次の要素が失敗すると、
onNext
の最後の値onNext
破棄されます。 - 後者のストレージ -チェーンの次の要素が失敗した場合、以前の値を上書きして、
onNext
の最後の値のみを提供します。 - 封じ込めなし
onNext
イベントは、バッファリングまたは破棄せずに記録されます。 - 例外 -次の回路要素が失敗すると、 例外がスローされます。
Observable(RxJava 2) -この問題を解決しません。 多くのRxJava 1ユーザーは、不合理なイベントにObservable
を使用したか、戦略を使用しなかったため、予期しない例外が発生しました。 したがって、 RxJava 2では 、保持された( Flowable )クラスと抑制されていない( Observable
)クラスが明確に分離されています。
演算子融合
アイデアは、ライフサイクル全体のさまざまな時点でチェーンを変更して、ライブラリアーキテクチャによって作成される複雑さを軽減することです。 これらの最適化はすべて内部で行われるため、エンドユーザーにはすべてが明確になります。
RxJava 2 & Reactorのみが演算子のマージをサポートしますが、少し異なります。 一般に、最適化には2つのタイプがあります。
- マクロ融合-2つ以上の連続した演算子を1つの演算子に置き換えます。

- マイクロフュージョン-出力キューが最後にあるエージェントと、キューの先頭から作業を開始するエージェントは、キューの同じインスタンスを使用できます。 例として、request(1)を呼び出してからonNext()を処理する代わりに...

...サブスクライバーは親Observableから値を要求できます。

詳細については、 パート1とパート2を参照してください。
おわりに
Stream
、 CompletableFuture
およびOptional
は、特定の問題を解決するために作成されました。 そして、彼らはこれらの問題を解決するのが得意です。 ニーズを満たすのに十分であれば、先に進みます。
ただし、問題ごとに複雑さが異なり、その一部には新しいアプローチが必要です。 RxJava&Reactorは、そのような問題を解決するように設計されていないツールを使用して「ハック」を作成する代わりに、宣言的なスタイルで問題を解決するのに役立つ汎用ツールです。