現在、6つの主要なメモリモデルがプログラミングを支配しています( Intel 8086メモリモデルと混同しないでください)。 それらの3つは、1950年代の歴史的に最も重要な3つのプログラミング言語であるCOBOL、LISP、およびFORTRANに由来し、残りは、磁気テープ、Unixスタイルの階層ファイルシステム、リレーショナルデータベースの3つの歴史的に重要なストレージシステムに関連付けられています。
これらのモデルは、構文や型システムよりもはるかに深いレベルで、プログラミング言語ができることまたはできないことを決定します。 これらのモデルを詳しく見て、考えられる代替案とそれらが興味深い理由を説明しましょう。
はじめに
現代の各プログラミング環境は、ある程度、6つのメモリモデルすべてを使用します。これが、システムが非常に複雑で理解しにくい理由の1つです。
ここで、これらの各メモリモデルを分析します。
- エンティティの属性を表します
- シリアル化と対話し、
- プログラムのモジュール性を実装および維持し、特定の側面へのアクセスを制限し、ローカルまたはプライベートにします。
プロローグ:アトミック変数のみを持つプログラム
単純なプログラミング言語から始めましょう。クロージャーがなく、ブール値と有限精度の数以外のデータ型が含まれていないため、データを構造化する可能性がありません。 以下に、通常のセマンティクスと通常の操作の優先度を使用したBNFの説明を示します。
program ::= def* def ::= "def" name "(" args ")" block args ::= "" | name "," args block ::= "{" statement* "}" statement ::= "return" exp ";" | name ":=" exp ";" | exp ";" | nest nest ::= "if" exp block | "if" exp block "else" block | "while" exp block exp ::= name | num | exp op exp | exp "(" exps ")" | "(" exp ")" | unop exp exps ::= "" | exp "," exps unop ::= "!" | "-" | "~" op ::= logical | comparison | "+" | "*" | "-" | "/" | "%" logical ::= "||" | "&&" | "&" | "|" | "^" | "<<" | ">>" comparison ::= "==" | "<" | ">" | "<=" | ">=" | "!="
この言語で温度を華氏から摂氏に変換する例:
def f2c(f) { return (f — 32) * 5 / 9; } def main() { say(f2c(-40)); say(f2c(32)); say(f2c(98.6)); say(f2c(212)); }
プログラミング言語では再帰が禁止されており、値による呼び出しを行う貪欲な(熱心な)計算戦略が使用されていることに同意しましょう。 また、すべての変数が暗黙的にローカルであり、サブプログラムを呼び出すときにゼロで初期化されることに同意します。 したがって、サブルーチンには副作用がありません。 この形式では、プログラミング言語は有限状態マシンのプログラミングにのみ適用できます。 レジスタを備えた実際のプロセッサ用にこのようなプログラムをコンパイルすると、プログラムテキスト内の各変数に1つのレジスタを割り当てることができます。 各ルーチンには、戻りアドレス用のレジスタを割り当てることもできます。 また、命令カウンタには別のレジスタが必要です。 ギガバイトのRAMを搭載したマシンでこの言語のプログラムを実行しても利点はありません。 彼女は最初に持っていた以上の変数を使用することはできませんでした。
これにより、このような言語が役に立たなくなります。 限られたスペースで行える多くの便利な計算があります。 しかし、これでは、そのような計算であっても、その抽象的なパワーを完全に使用することは実際には許可されません。
追加のメモリにアクセスするには、指定されたアドレスに対して1バイトを読み書きするpeek()およびpoke()関数を使用できます。 したがって、メモリを本当に効率的に使用できます。
def strcpy(d, s, n) { while n > 0 { poke(d + n, peek(s + n)); n := n — 1; } }
ただし、多くのプログラミング言語では、peek()およびpoke()も提供されていません。 代わりに、それらは禁欲的な同種のバイト配列の上にある種の構造を提供します。
たとえば、ステートマシン、ネストされたレコード、配列、およびユニオンをプログラミングする場合でも、すでに大きなメリットがあります。
ネストされたレコードとCOBOLメモリモデル:損益計算書としてのメモリ
COBOLでは、データオブジェクトは分割不可能なものです。
- 文字列や特定のサイズの数字などの基本的なオブジェクト、
- または次のようなオブジェクトのコレクション。
- レコード(並べて保存されたさまざまなタイプのオブジェクト);
- アソシエーション(同じ場所を占めて保存される代替オブジェクト);
- または配列(同じタイプの特定の数のオブジェクトを次々に並べて保存)。
(ここでは、この言語が提供するものの理解を簡素化するために、COBOLの用語と分類法から大幅に逸脱しています)。
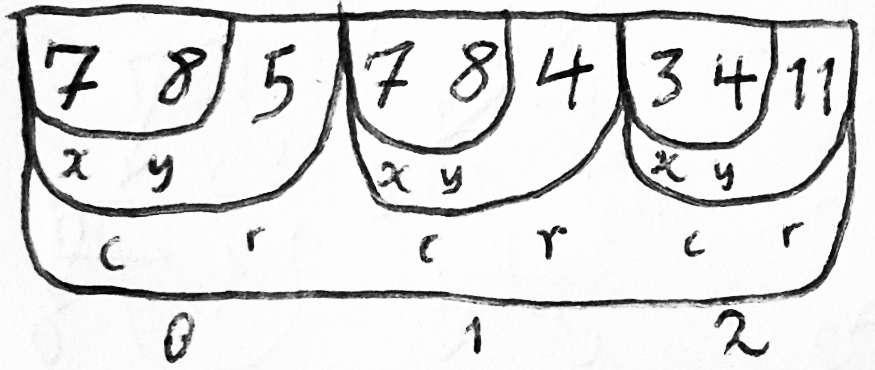
このようなメモリモデルでは、複数の類似したエンティティがある場合、各エンティティは情報を格納するために設計された同じタイプのレコード(サイズとサブフィールドの両方)を持ちます。 したがって、このエンティティに関するすべての情報はメモリ内に順番に配置されます。 これらの関連データをディスク、テープ、パンチカード、またはその他のストレージメディアに非常に簡単にダウンロードして保存できます。 これらのレコードのいくつかが同時にメモリ内にある場合、それらを配列に配置できます。
エンティティの属性は2バイトで定義されます。2バイトは、このエンティティのデータを格納するレコードのベースアドレスを基準とした、この属性の開始と終了のオフセットです。 たとえば、Accountオブジェクトには10〜35バイトの所有者フィールドがあり、その中には18〜26バイトのアカウント所有者のPatron名が格納されます。
このアプローチには、興味深い点がいくつかあります。
ポインタはまったくありません。 これは、動的なメモリ割り当てを行う方法がなく、nullポインタを逆参照できず、ダングリングポインタを使用してメモリ領域を上書きしないことを意味します(ただし、2つの変数がREDEFINESとして宣言されている場合は、もちろん互いに上書きして回避できます) タグ付きのユニオン )、メモリ不足、オーバーラップ、ポインターでのメモリの浪費は、この問題に役立ちません。
一方、これはまた、プログラム内のすべてのデータ構造には厳しい制限があり、異なる時間に異なるものに同じメモリを使用する唯一の方法は、それらを同時に使用するリスクがあることを意味します。
ネストされたエントリは非常に経済的で、メモリが節約されます。 現在作業しているエンティティのデータのみに留意する必要があります。 これは、キロバイトのメモリを搭載したマシンでメガバイトのデータを正常に処理できることを意味します。これは、COBOLプログラマーが1950年代に行ったことでした。
各データ(フィールド、サブフィールドなど)には1つの一意の親があり(最上位レベルを除く)、すぐにすべての子データが含まれます。
このメモリモデルでは、プログラムの一部に独自のメモリ(たとえば、スタックフレームや静的なプライベート変数)がある場合、この独自のメモリにデータを保存することで、一部のエンティティをプライベートにすることができます。 これは、ローカルの一時変数を作成する必要があり、それがプログラムの残りの部分に影響しないことを確認する場合に便利です。 ただし、このようなメモリモデルでは、プログラムのどの部分でも属性をプライベートにすることはできません。
ALGOL(およびALGOL-58とALGOL-60)は、配列に加えて、データ構造化メカニズムをメインとしてCOBOLからレコードを借用しました。 そして、ほとんどすべての他のプログラミング言語が何らかの形でそれを継承したのは、アルゴルからでした。
C言語には、データを構造化するためのほぼすべてのツールセット(プリミティブ型(char、intなど)、構造体、共用体、配列)があります。 ただし、Cには、引数を受け入れるだけでなく、再帰的なポインターとルーチンもあり、スタックを割り当てるようなものが必要です。 COBOLモデルに対するこれらの拡張機能はどちらもLISPから提供されました。
オブジェクトグラフとLISPメモリモデル:マーク付き指向グラフとしてのメモリ
LISP(現在はLispであり、1959年にはLISPでした)は、COBOLとほとんど変わらないでしょう。 ポインタがあるだけでなく、LISPには他にほとんど何もありません。 LISPでデータを構造化するための唯一のメカニズムはconsと呼ばれるもので、2つのポインターで構成されます。1つは「car」、もう1つは「cdr」です。 任意の変数の値はポインターです。 短所へのポインタ、シンボルへのポインタ、数値へのポインタ、またはサブプログラムへのポインタの場合もありますが、ポインタです。
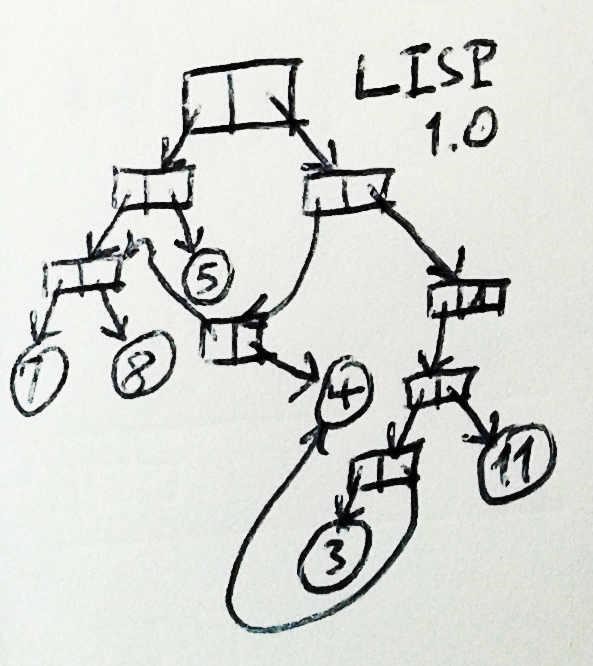
さらに、引数付きの再帰ルーチンがあり、これとテールテール再帰最適化のおかげで、変数の値を変更することなく何かをするプログラムを書くことができます。
任意のオブジェクトは、任意の数のポインターによって参照でき、そのポインターを使用してオブジェクトを変更できます。 したがって、オブジェクトには一意の親はありません。
このモデルは、自然言語の処理、プログラムの解釈とコンパイル、 徹底的な検索、およびシンボリック計算のためのプログラムをかなり簡単に作成できるという意味で、非常に柔軟性があります 。 また、データ構造( 赤黒木など )を一度作成して、それをさまざまなタイプのオブジェクトに簡単に適用することもできます。 対照的に、CなどのCOBOL派生言語には、この種の一般化に大きな困難があります。その結果、プログラマーは、新しいデータ型に同じよく知られているデータ構造とアルゴリズムを実装するために、膨大な量の反復コードを何度も書く必要があります。
ただし、同時に、このモデルはメモリの制限にうまく対応できず、エラーが発生しやすく、効果的な実装には多くの工夫が必要です。 各オブジェクトはポインターによってのみ識別されるため、各オブジェクトはエイリアスを持つことができます。 各変数はNULLポインターにすることができます。 ポインターは何でも指すことができるため、型エラー(1つの型のオブジェクトへのポインターが他の型を指すと予想される変数に格納されている場合)はいたるところにあり、オブジェクトグラフ言語は従来、チェックを使用してデバッグ時間を短縮します実行時にタイプします。
このオブジェクトグラフメモリモデルでは、同じタイプのオブジェクトが複数ある場合、それぞれがポインターによって識別され、オブジェクトの特定の属性を見つけるには、このポインターから開始してオブジェクトのグラフをナビゲートする必要があります。 たとえば、Accountオブジェクトがある場合、連想リストの形式で表示できます。 次に、その所有者(他のアカウントオブジェクトと組み合わせて使用できるオブジェクト)を見つけるには、ACCOUNT-HOLDERになる車の短所を見つけてそのcdrを取得するまでリストを調べます。 次に、アカウント所有者のミドルネームを見つけるために、おそらくアカウント所有者の属性のベクトルを探している場合、対応する名前へのポインターを取得します。これは、行が存在しない古いLispのように、文字列または記号のいずれかです。 ミドルネームの更新には、この所有者オブジェクトが他のアカウントオブジェクトで使用されているかどうか、および、他のアカウント。ミドルネームも更新されます。
これらの言語では、ガベージコレクションがほぼ必要です。 McCarthyがLispを作成した1959年から、LiebermanとHewittが世代を使用してガベージを収集するというアイデアを思いついた1980年まで、このメモリモデルを使用するプログラムは作業の3分の1から半分をガベージコレクションに費やしていました。 一部のコンピューターは、ガベージコレクターを別のプロセッサーで実行できるように、複数のプロセッサーで特別に設計されています。
オブジェクトグラフィカル言語は、既存のオブジェクトを変更するよりも新しいオブジェクトを作成することを好むためだけでなく、通常多くのポインターを持っているため、ガベージコレクターに高い要求を行いました。 CやGolangなどのCOBOL派生言語では、ガベージコレクターで実行されるメモリ操作が少なくなるため、ガベージコレクターが動作しやすくなります。 これらの言語は、変更されたバージョンのメモリを再割り当てするのではなく、オブジェクトを変更する傾向があります。 そしてプログラマーは、原則として、可能な場合はネストされたレコードを使用し、ポインターに関連付けないようにします。そのため、ポインターは、ポリモーフィズム、空のポインターの許容性(ポリモーフィズムの特殊なケースと見なすことができる)が望ましい場合にのみ見つかります。
オブジェクトグラフのシリアル化は、循環参照を含めることができるため、またシリアル化する必要のない部分へのリンクが含まれる可能性があるため、少し複雑になります。両方のケースを特定のケースと見なす必要があります。 たとえば、一部のシステムでは、クラスのインスタンスにそのクラスへのリンクが含まれ、クラスにはすべてのメソッドの現在のバージョンだけでなく、親クラスへのリンクも含まれます。 そして、おそらくオブジェクトのすべてのシリアル化でクラスのバイトコード全体をシリアル化する必要はありません。 さらに、以前にリンクを共有していた2つのオブジェクト(同じアカウント所有者の2つのアカウント)を逆シリアル化する場合、おそらくそれらを共有し続ける必要があります。 一般に、これに関する特定のポリシーは、データをシリアル化する目的によって異なる場合があります。
ネストされたエントリを持つメモリモデルのように、オブジェクトグラフモデルを使用すると、特定のエンティティのすべての属性をプログラムの特定の部分にローカルにすることができます。プログラムの残りの部分のデータ構造への参照を与えることはできませんが、特定の属性をプライベートにすることはできませんすべてのエンティティ。 ただし、ネストされたエントリを持つメモリモデルとは異なり、オブジェクトグラフモデルは、ノードのメモリサイズへの依存性を減らします。これにより、多くの深刻な問題にもかかわらず、オブジェクト指向の継承への扉が開かれ、属性をプライベートにすることができます。
このモデルは、現在最も一般的なプログラミング言語で使用されています。 現在のLispだけでなく、Haskell、ML、Python、Ruby、PHP5、Lua、JavaScript、Erlang、Smalltalkもあります。 それらはすべて、メモリ内に存在するオブジェクトのタイプのセットを単純なペアを超えて拡張しました。 通常、ポインタの配列と文字列のハッシュテーブル、または他のポインタへのポインタが含まれます。 それらの一部には、タグ付き共用体と不変エントリも含まれます。 特に、ハッシュテーブルは、ほとんどの場合、これらのオブジェクトを使用する他のコードに影響を与えずに、既存のオブジェクトに新しいプロパティを追加する一種の方法を提供します。

一般に、これらの言語では、グラフのエッジを指す方向にのみ追跡でき、エッジのラベルはソースノード内で一意である必要があります(consには1台の車のみがあり、2台ではなく10台)。目的地。 Ted NelsonのZigZagデータ構造は、送信元と送信先の両方で一意である必要がある状況の研究です。 UnQLは、ある意味、一意性を完全に排除する研究です。
Java(およびC#)は、このメモリモデルのわずかに変更されたバージョンを使用します。たとえば、Javaには、ポインターではない「プリミティブ型」などがあります。
並列配列とFORTRANメモリモデル:配列のグループとしてのメモリ
Fortranは、コンピューターの最も初期のアプリケーションの1つである物理現象(いわゆる「科学計算」)を数値的にモデル化するために設計されました。 当時、科学コンピューターは、COBOL言語の「ビジネスコンピューター」とは多くの機能が異なりました。10進数ではなく2進数を使用していました。 バイトデータ型はありませんでした-単語だけ。 浮動小数点演算をサポートしていました。 そして、彼らはより速い計算と遅いI / Oを持っていました

通常、このようなシミュレーションには、できるだけ早く処理する必要のある数の大きな配列を持つ多くの線形代数が含まれていました。 そして、FORTRANは、これのためだけに最適化されました-多次元配列の効率的な使用のため。 FORTRANには、再帰的なルーチン、ポインター、およびレコードがなかっただけでなく、最初はまったくルーチンがありませんでした!
ルーチンがその中に現れたとき、それらは配列であり得るパラメータを持っていました。 Algol 60では、これは実際には実現していませんでした。 配列は唯一の非プリミティブ型であるため、配列に使用できる要素タイプは、整数や浮動小数点数などのプリミティブ型のみでした。

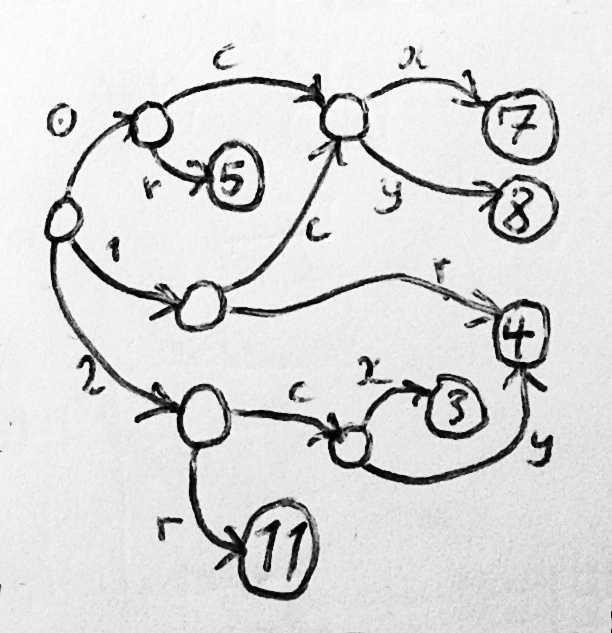
FORTRAN環境で開発された並列配列のメモリモデルでは、同じタイプのオブジェクトが複数ある場合、それらはそれぞれ、複数の配列で有効な数値オフセットによって識別されます。 また、特定のオブジェクトのプライベート属性の検索には、このオブジェクトのインデックスを使用してこの属性の配列にインデックスを付けることが含まれます。 1950年代から少し離れて、データを構造化するために並列配列に付着して配列を形成できるプリミティブタイプのシンボルを使用できるようにした場合、次のように前の例から口座名義人の2番目の名前を決定できます。
- IM = IMDNAM(ICCHLD(IACCTN))
IA = ISTR(IM)
IE = ISTR(IM + 1)
配列のインデックス付けのこれら4つの操作の後、アカウント所有者の2番目の名前はCCHARS配列の文字[IA、IE)になります。 - IM = IMDNAM(IACCTN)、アカウント所有者の属性に個別の文字セットがない場合は、以前のバージョンのように進みます。
- IMDNAMの代わりに、各アカウント所有者の2番目の名前に1つの12文字の列を持つ、N * 12の文字の配列であるCMDNAMを使用します。
このメモリモデルでは、サブルーチンは、引数として渡された配列内の任意のインデックスにアクセスしたり、他の方法でアクセスしたり、ランダムな順序で何度でも読み書きしたりできます。
これはまさに「どの言語でもFORTRANで記述できる」というフレーズの意味です。ほとんどすべてのプログラミング言語にはプリミティブ型の配列があります。 アセンブラーやForthでも、配列を作成するのは簡単です。 Awk、Perl4、およびTclは、オブジェクトグラフ言語ではないため、ファーストクラスオブジェクトではない辞書も提供しますが、配列の代わりに正常に機能してオブジェクトの属性を格納し、整数ではなく文字列でオブジェクトを識別できます。
興味深いことに、マシンレベルでは、単純な場合、並列配列は、ネストされたモデルのように、ポインターを介して参照される構造要素とほぼ同じコードを生成します。 たとえば、ここで
b->foo
、ここでbは32ビットメンバーfooを持つ構造体へのポインタです。
40050c: 8b 47 08 mov 0x8(%rdi),%eax</code> <code>foos[b]</code>, b — foos, 32- : <source>400513: 8b 04 bd e0 d8 60 00 mov 0x60d8e0(,%rdi,4),%eax
どちらの場合も、必要な属性を表す即時定数をレジスタ内の変数に追加します。これは、検討しているオブジェクトを示します。 2番目の場合の違いは、インデックスに要素のサイズを掛けて、直接定数がわずかに大きくなることです。
( , , , , ).
. . , , , .
, cache-friendly, , , , ( — , ). , , , : sum covariance, .
: , .
, . , , , . , (type error) — , — . (, ). , , , , ( ), , (nested-record model).
, , , , .
FORTRAN — , . Octave, Matlab, APL, J, K, PV-WAVE IDL, Lush, S, S-Plus R . Numpy, Pandas OpenGL — «» , Perl4, awk, Tcl, , - . , . Pandas, K - (parallel-dictionary variant) , .
: CPU , GPU SIMT-, CPU SIMD- ALU . , «, » (data-oriented design) ( ) « » (entity systems). , «» .
: Lua, Erlang Forth?
: (record), . , , :
- Lua (finite maps) (, «»),
- Erlang , ( , (Hewitt) (Agha)),
- Forth .
Lua Erlang - . Forth . , , - -- , . -- Linda, .
.
Unix — ( ). , — (, , ), , , ( ). ( , ). , .
, . MapReduce , lex, , .
Python, (forward iterators) C++ STL, (forward ranges) D, Golang — , .
, ? (, ) . . empty, get, ``put, , , Python - :
def merge(in1, in2, out) { have1 := 0; have2 := 0; while !empty(in1) || !empty(in2) { if 0 == have1 && !empty(in1) { val1 := get(in1); have1 := 1; } if 0 == have2 && !empty(in2) { val2 := get(in2); have2 := 1; } if 0 == have1 { put(out, val2); have2 := 0; } else { if 0 == have2 || val1 < val2 { put(out, val1); have1 := 0; } else { put(out, val2); have2 := 0; } } } }
, , . , . , . in1, out .. - , . ( Unix- Unix-: ). , , .
(multithreaded) (control flow system), (threads), , (empty streams block), . ; , . , , .
- (π-calculus) — , . , (concurrent) - (channel-oriented) λ-. :
Q . この場合:
- P|Q , P Q, ;
- a(x).P , , , , ;
- ā〈x〉.P , , , - , .
- (νa)P , — ;
- ! , ;
- P + Q , P Q;
- 0 , .
-:
!incr(a, x).ā〈x+1〉 | (νa)( i̅n̅c̅r̅〈a, 17〉 | a(y) )
«» , incr , , +1 . , «». 17 incr, , , y.
-, , , , . , (labeled graphs)! , .
« », NSA, Apache NiFi, Unix---.
Multics: (string-labeled tree) blob-
Unix ( Windows, MacOS, Multics) — , , shell-. - , — , «» - , « », ( ). , « », — .
() , ! , , , , . , () «» «». Unix , , , , .
— . , , , , , . , , .
.
, . - MUMPS, ( «» 4096 , «», « »). IBM IMS, , , «». . (Mark Lentczner) , - , Wheat. - PHP. Wheat «» «» ( , ). « » , . . Wheat , , - .
SQL: —
, .
« » «» «». cos — : θ cos(θ) . Cos-1 — : cos⁻¹(0.5) , , - . cos , : (0, 1), (π/2, 0), (π, -1), (3π/2, 0) . — : (1, 0), (0, π/2), (-1, π), (0, 3π/2) .
, , , , : n- n. , : (0, 1, 0), (π/2, 0, 1), (π, -1, 0) ..
cos, .
, , , permissions.sqlite Firefox:
sqlite> .mode column sqlite> .width 3 20 10 5 5 15 1 1 sqlite> select * from moz_hosts limit 5; id host type permi expir expireTime ai --- -------------------- ---------- ----- ----- --------------- — - 1 addons.mozilla.org install 1 0 0 2 getpersonas.com install 1 0 0 5 github.com sts/use 1 2 1475110629178 9 news.ycombinator.com sts/use 1 2 1475236009514 10 news.ycombinator.com sts/subd 1 2 1475236009514
, , id ; host(1) addons.mozilla.org, host(2) getpersonas.com, type(5) sts/use. -.
. , host(9), host⁻¹('news.ycombinator.com'), :
sqlite> select id from moz_hosts where host = 'news.ycombinator.com'; id --- 9 10
, :
sqlite> .width 0 sqlite> select min(expireTime) from moz_hosts where host = 'news.ycombinator.com'; min(expireTime) --------------- 1475236009514
, SQL, («» «»), , , id . - . :
select accountholder.middlename from accountholder, account where accountholder.id = account.accountholderid and account.id = 3201
, , , - .
SQL — , . .
Lisp, FORTRAN C, SQL , . , . SQL-, , , , (, - PL/SQL).
. , , .
SQL - : , ( , , ); ( , , COBOL). .
SQL, , :
for (int i = 0; i < moz_hosts_len; i++) { if (0 == strcmp(moz_hosts_host[i], "news.ycombinator.com")) { results[results_len++] = moz_hosts_id[i]; } }
, SQL : / (unmanageable) . SQL:
select accountholder.middlename from accountholder, account where accountholder.id = account.accountholderid
- :
int *fksort = iota(account_len); sort_by_int_column(account_accountholderid, fksort, account_len); int *pksort = iota(accountholder_len); sort_by_int_column(accountholder_id, pksort, accountholder_len); int i = 0, j = 0, k = 0; while (i < account_len && j < accountholder_len) { int fk = account_accountholderid[fksort[i]]; int pk = accountholder_id[pksort[j]]; if (fk == pk) { result_id[k] = fk; result_middle_name[k] = accountholder_middlename[pksort[j]]; k++; i++; // Supposing accountholder_id is unique. } else if (fk < pk) { i++; } else { j++; } } free(fksort); free(pksort);
iota :
int *iota(int size) { int *results = calloc(size, sizeof(*results)); if (!results) abort(); for (int i = 0; i < size; i++) results[i] = i; return results; }
sort_by_int_column :
void sort_by_int_column(int *values, int *indices, int indices_len) { qsort_r(indices, indices_len, sizeof(*indices), indirect_int_comparator, values); } int indirect_int_comparator(const void *a, const void *b, void *arg) { int *values = arg; return values[*(int*)a] — values[*(int*)b]; }
SQL- , , , . , .
, SQL — , , , . , , — , , , , . , , .
Prolog miniKANREN, . miniKANREN , , .
(constraint programming), («», ), . , , , SAT SMT.