それはすべて平凡に始まった...リヒターによって読まれ、集中的にシルトを研究した。 私は.NETの開発に携わると思ったが、運命は仕事の最初の1か月で別の方法で決定した。 従業員の1人が予期せずプロジェクトを去り、新しく形成された穴に彼らは新鮮な人間の素材を投げました。 それから、 SQL Serverについて知り合いになりました 。
それ以来、6年弱が経過し、多くのことを思い出すことができます...
タイでの休暇中に人生を再考したイギリスからのジョセフの前のクライアントについて、ジョセフィンはスカイプで私に署名し始めました。 同じ部屋に座っていなければならなかった陽気なオフィスの隣人について:1つは新鮮な空気に対するアレルギーに苦しみ、もう1つは日光に対するアレルギーで補完するC ++への片思いの愛に苦しんでいました。 かつて、上からの命令で、私はスキルで草に覆われたJSを装うために、一時的に2人の子供の父アレクサンダーにならなければなりませんでした。
しかし、最も激しいゴミは、おそらくゴム製のアヒルの鳴き声の物語に関係しています。 ある同僚は彼女をストレスから解放し、かつては感情にふけって頭をかじった。 それ以来、アヒルは以前の光沢を失い、すぐにボールに取って代わられました。
なぜこれが言われたのですか? データベースの操作に人生を捧げたい場合、最初に学ぶ必要があるのは...ストレス耐性です。 2つ目は、初心者開発者の多くが知らない、または単に無視するT-SQLクエリを作成するときにいくつかのルールを採用し、座って頭を悩ますことです...なぜ機能しないのですか?
内容:
1. データ型
2. *
3. エイリアス
4. 列の順序
5. NOT IN vs NULL
6. 日付形式
7. 日付フィルター
8. 計算
9. 暗黙の変換
10. LIKEおよび抑制されたインデックス
11. UnicodeとANSI
12. コレート
13. バイナリコレート
14. コードスタイル
15. [var] char
16. データ長
17. ISNULL対COALESCE
18. 数学
19. UNION vs UNION ALL
20. 再読み込み
21. サブクエリ
22. ケース
23. スカラー関数
24. ビュー
25. カーソル
26. STRING_CONCAT
27. SQLインジェクション
例付きのビデオ
1.データ型
SQL Serverで作業するときにほとんどの問題を引き起こす最も基本的なことは、データ型の選択の誤りです。 2つの基本的に同一のテーブルを使用した架空の例を考えます
DECLARE @Employees1 TABLE ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , BirthDate VARCHAR(20) ) INSERT INTO @Employees1 VALUES (123, 'YES', '2012-09-01')
DECLARE @Employees2 TABLE ( EmployeeID INT PRIMARY KEY , IsMale BIT , BirthDate DATE ) INSERT INTO @Employees2 VALUES (123, 1, '2012-09-01')
リクエストを実行して、違いを見てみましょう。
DECLARE @BirthDate DATE = '2012-09-01' SELECT * FROM @Employees1 WHERE BirthDate = @BirthDate SELECT * FROM @Employees2 WHERE BirthDate = @BirthDate

前者の場合、データ型は必要以上に冗長です。 なぜビット記号をYES / NO文字列として保存するのですか? なぜ日付を文字列として保存するのですか? 従業員がいるテーブルでBIGINTを使用する理由 単純なINTが収まらなかったのですか?
これにはいくつかの理由があります。テーブルがより多くのディスク領域を占有するため、ディスクからより多くのページを読み込む必要があり、このデータを処理するためにBufferPoolにより多くのページを配置する必要がある さらに、深刻なパフォーマンスの問題がある可能性があります-疑問符はこれを簡単に示唆しますが、これについては後で説明します。
2. *
多くの場合、「油絵」を満たす必要がありました。すべてのデータはテーブルから取得され、その後、実際に必要な列のみがDataReaderを介してクライアントで選択されます。 これは非常に非効率的であるため、このプラクティスを使用しないことをお勧めします。
USE AdventureWorks2014 GO SET STATISTICS TIME, IO ON SELECT * FROM Person.Person SELECT BusinessEntityID , FirstName , MiddleName , LastName FROM Person.Person SET STATISTICS TIME, IO OFF
違いは、クエリ実行の時間と、カバーするインデックスにより論理的な読み取りを少なくすることができるという事実の両方にあります。
Table 'Person'. Scan count 1, logical reads 3819, physical reads 3, ... SQL Server Execution Times: CPU time = 31 ms, elapsed time = 1235 ms. Table 'Person'. Scan count 1, logical reads 109, physical reads 1, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 227 ms.
3.エイリアス
テーブルを作成します。
USE AdventureWorks2014 GO IF OBJECT_ID('Sales.UserCurrency') IS NOT NULL DROP TABLE Sales.UserCurrency GO CREATE TABLE Sales.UserCurrency ( CurrencyCode NCHAR(3) PRIMARY KEY ) INSERT INTO Sales.UserCurrency VALUES ('USD')
両方のテーブルにある同一の行の数を返すクエリがあるとします:
SELECT COUNT_BIG(*) FROM Sales.Currency WHERE CurrencyCode IN ( SELECT CurrencyCode FROM Sales.UserCurrency )
予想どおり、テーブルSales.UserCurrencyの列の名前を変更するまで、すべてが機能します。
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
クエリを実行すると、返されるのは1行ではなく、すべてがSales.Currencyにあることがわかります。 実行プランを構築するとき、 SQL Serverはバインド段階でSales.UserCurrency列を調べ、 そこで CurrencyCodeを見つけず、この列がSales.Currencyテーブルに属しているとは考えません。その後、オプティマイザーはCurrencyCode = CurrencyCode条件を削除します。
道徳-エイリアスを使用:
SELECT COUNT_BIG(*) FROM Sales.Currency c WHERE c.CurrencyCode IN ( SELECT u.CurrencyCode FROM Sales.UserCurrency u )
4.列の順序
何らかの種類のテーブルがあるとします:
IF OBJECT_ID('dbo.DatePeriod') IS NOT NULL DROP TABLE dbo.DatePeriod GO CREATE TABLE dbo.DatePeriod ( StartDate DATE , EndDate DATE )
そして、列がどのように順序付けられているかを知っているという仮定から、常にデータを挿入します。
INSERT INTO dbo.DatePeriod SELECT '2015-01-01', '2015-01-31'
その後、誰かが列を並べ替えます:
CREATE TABLE dbo.DatePeriod ( EndDate DATE , StartDate DATE )
そして、データはすでに開発者が期待する間違った列に挿入されます。 したがって、 INSERT構造で列を明示的に指定することが常に推奨されます。
INSERT INTO dbo.DatePeriod (StartDate, EndDate) SELECT '2015-01-01', '2015-01-31'
別の興味深い例があります:
SELECT TOP(1) * FROM dbo.DatePeriod ORDER BY 2 DESC
どの列がソートされますか? そして、それはすべてテーブル内の現在の順序に依存します。 誰かがそれを変更すると、リクエストは期待したものを表示しません。
5. NOT IN vs NULL
ジュニアDB開発者インタビューの質問の中で議論の余地のないリーダーは、 NOT IN構造です。
たとえば、いくつかのクエリを作成する必要があります。2番目のテーブルにない最初のテーブルからすべてのレコードを返します。 非常に多くの場合、初心者の開発者はわざわざINとNOT INを使用しません 。
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1)) INSERT INTO @t1 VALUES (1), (2) DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2)) INSERT INTO @t2 VALUES (1) SELECT * FROM @t1 WHERE t1 NOT IN (SELECT t2 FROM @t2) SELECT * FROM @t1 WHERE t1 IN (SELECT t2 FROM @t2)
最初のクエリはデュースを返し、2番目のクエリはユニットを返しました。 次に、2番目のテーブルに別の値-NULLを追加します 。
INSERT INTO @t2 VALUES (1), (NULL)
NOT INを使用してクエリを実行すると、結果が得られません。 本当にある種の魔法が介入しました-INは動作しますが、 NOT INは拒否します。 これは、比較操作中の3次ロジックによって導かれる、 TRUE 、 FALSE 、 UNKNOWNの SQL Serverを使用する場合に最初に「理解して許す」ことです。
実行されると、 SQL ServerはIN句を解釈します 。
a IN (1, NULL) == a=1 OR a=NULL
入っていない :
a NOT IN (1, NULL) == a<>1 AND a<>NULL
値をNULLと比較するとUNKNOWNが返されます。 1 = NULL 、 NULL = NULL 。 結果は1- UNKNOWNになります。 また、条件でAND演算子が使用されているため、式全体が未定義の値を返し、結果として空になります。
少し退屈に書かれています。 しかし、そのような状況は十分に一般的であることを理解することが重要です。 たとえば、列がNOT NULLとして宣言される前に、ある種の人がその列にNULL値を書き込むことを許可しました。 結論:クライアントは、少なくとも1つのNULL値がテーブルに入った後にレポートの動作を停止します。
どうする NULL値を明示的に削除できます。
SELECT * FROM @t1 WHERE t1 NOT IN ( SELECT t2 FROM @t2 WHERE t2 IS NOT NULL )
EXCEPTを使用できます:
SELECT * FROM @t1 EXCEPT SELECT * FROM @t2
多くのことを考えたくない場合は、 NOT EXISTSを使用する方が簡単です。
SELECT * FROM @t1 WHERE NOT EXISTS( SELECT 1 FROM @t2 WHERE t1 = t2 )
どのクエリオプションが最適ですか? NOT EXISTSを使用した最後のオプションは、2番目のテーブルのデータにアクセスするときに、より最適な述語プッシュダウンステートメントを生成することが望ましいようです。
一般に、 NULL値では多くの冗談があります。 次のリクエストで遊ぶことができます:
USE AdventureWorks2014 GO SELECT COUNT_BIG(*) FROM Production.Product SELECT COUNT_BIG(*) FROM Production.Product WHERE Color = 'Grey' SELECT COUNT_BIG(*) FROM Production.Product WHERE Color <> 'Grey'
NULL値に対して個別の比較演算子が提供されているという理由だけで、期待される結果が得られません。
SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NULL SELECT COUNT_BIG(*) FROM Production.Product WHERE Color IS NOT NULL
CHECK定数のある状況はさらに奇妙に見えます:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL DROP TABLE #temp GO CREATE TABLE #temp ( Color VARCHAR(15) --NULL , CONSTRAINT CK CHECK (Color IN ('Black', 'White')) )
白と黒の色のみを記録できるテーブルを作成します。
INSERT INTO #temp VALUES ('Black')
(1 row(s) affected)
すべてが期待どおりに機能します。
INSERT INTO #temp VALUES ('Red')
The INSERT statement conflicted with the CHECK constraint... The statement has been terminated.
しかし、 NULLを挿入しましょう:
INSERT INTO #temp VALUES (NULL)
(1 row(s) affected)
書き込みにはNOT FALSE条件で十分なので、 CHECK定数は機能しませんでした。 TRUEとUNKNOWNは甘い魂に適しています。 この動作を回避するためのいくつかのオプションがあります。明示的に列をNOT NULLとして宣言するか、制約でNULLを考慮します 。
6.日付形式
それでも、データ型のさまざまなニュアンスにつまずくことがよくあります。 たとえば、現在の時刻を取得する必要があります。 GETDATE関数を実行します。
SELECT GETDATE()
結果をコピーし、クエリにそのまま貼り付けて、時間を削除しました。
SELECT * FROM sys.objects WHERE create_date < '2016-11-14'
これは正しいですか?
日付は文字列定数で指定されますが、 SQL Serverでは、書き込み時にある程度の自由度が許可されます。
SET LANGUAGE English SET DATEFORMAT DMY DECLARE @d1 DATETIME = '05/12/2016' , @d2 DATETIME = '2016/12/05' , @d3 DATETIME = '2016-12-05' , @d4 DATETIME = '05-dec-2016' SELECT @d1, @d2, @d3, @d4
すべての値はほぼどこでも明確に解釈されます。
----------- ----------- ----------- ----------- 2016-12-05 2016-05-12 2016-05-12 2016-12-05
そして、このようなビジネスロジックのリクエストが別のサーバーで開始されるまで、問題は発生しません。別のサーバーでは、設定が異なる場合があります。
SET DATEFORMAT MDY DECLARE @d1 DATETIME = '05/12/2016' , @d2 DATETIME = '2016/12/05' , @d3 DATETIME = '2016-12-05' , @d4 DATETIME = '05-dec-2016' SELECT @d1, @d2, @d3, @d4
これらのオプションはすべて、日付の誤った解釈につながる可能性があります。
----------- ----------- ----------- ----------- 2016-05-12 2016-12-05 2016-12-05 2016-12-05
さらに、そのようなコードは、明示的および非表示の両方のエラーにつながる可能性があります。 たとえば、テーブルにデータを挿入する必要があります。 テストサーバーではすべて正常に動作します。
DECLARE @t TABLE (a DATETIME) INSERT INTO @t VALUES ('05/13/2016')
そして、クライアントは、サーバー設定の違いにより、そのようなリクエストは問題につながります:
DECLARE @t TABLE (a DATETIME) SET DATEFORMAT DMY INSERT INTO @t VALUES ('05/13/2016')
Msg 242, Level 16, State 3, Line 28 The conversion of a varchar data type to a datetime data type resulted in an out-of-range value.
では、日付の定数を設定する形式は何ですか? 別の例を見てみましょう。
SET DATEFORMAT YMD SET LANGUAGE English DECLARE @d1 DATETIME = '2016/01/12' , @d2 DATETIME = '2016-01-12' , @d3 DATETIME = '12-jan-2016' , @d4 DATETIME = '20160112' SELECT @d1, @d2, @d3, @d4 GO SET LANGUAGE Deutsch DECLARE @d1 DATETIME = '2016/01/12' , @d2 DATETIME = '2016-01-12' , @d3 DATETIME = '12-jan-2016' , @d4 DATETIME = '20160112' SELECT @d1, @d2, @d3, @d4
インストールされている言語に応じて、定数はさまざまな方法で解釈することもできます。
----------- ----------- ----------- ----------- 2016-01-12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ----------- ----------- 2016-12-01 2016-12-01 2016-01-12 2016-01-12
そして、結論は最後の2つのオプションを使用することを要求します。 月を明示的に設定することは、「No crap sis jour」エラーに遭遇する良い機会であるとすぐに言わなければなりません。
SET LANGUAGE French DECLARE @d DATETIME = '12-jan-2016'
Msg 241, Level 16, State 1, Line 29 Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
合計-最後のオプションが残ります。 月の設定や位相に関係なく、日付を含む定数をシステムで明確に解釈する場合は、チルダ、引用符、スラッシュなしでYYYYMMDD形式で指定します。
また、一部のデータ型の動作の違いに注意する価値があります。
SET LANGUAGE English SET DATEFORMAT YMD DECLARE @d1 DATE = '2016-01-12' , @d2 DATETIME = '2016-01-12' SELECT @d1, @d2 GO SET LANGUAGE Deutsch SET DATEFORMAT DMY DECLARE @d1 DATE = '2016-01-12' , @d2 DATETIME = '2016-01-12' SELECT @d1, @d2
DATETIMEとは異なり、 DATEタイプはサーバーのさまざまな設定で正しく解釈されます。
---------- ---------- 2016-01-12 2016-01-12 ---------- ---------- 2016-01-12 2016-12-01
しかし、このニュアンスを念頭に置く必要がありますか? ほとんどない。 覚えておくべき主なことは、 YYYYMMDDの形式で日付を設定する必要があり、問題がないことです。
7.日付フィルター
次に、データを効率的にフィルタリングする方法を検討します。 何らかの理由で、 DATETIME / DATE列の松葉杖の数が最も多いため、このデータ型から始めます。
USE AdventureWorks2014 GO UPDATE TOP(1) dbo.DatabaseLog SET PostTime = '20140716 12:12:12'
次に、特定の日にクエリが返す行数を調べてみましょう。
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime = '20140716'
要求は0を返します。なぜですか? プランを作成する際、 SQL Serverは文字列定数をフィルター処理する列のデータ型に変換しようとします 。
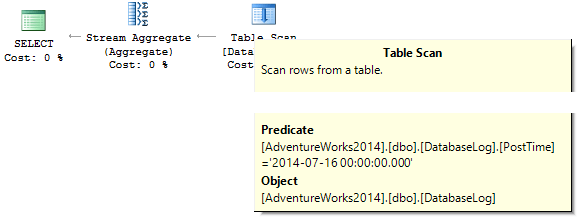
インデックスを作成します。
CREATE NONCLUSTERED INDEX IX_PostTime ON dbo.DatabaseLog (PostTime)
必要なデータを表示するための正しいオプションと間違ったオプションがあります。 たとえば、切り取り時間:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CONVERT(CHAR(8), PostTime, 112) = '20140716' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CAST(PostTime AS DATE) = '20140716'
または、範囲を設定します。
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140716' AND PostTime < '20140717'
最適化に関してより正確なのは、最後の2つのクエリです。 実際、検索対象のインデックス列でのすべての変換と計算は、パフォーマンスを大幅に低下させ、論理読み取り値を増やします(最初と最後の3つのクエリオプション)。
Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 2, ...
PostTimeフィールドは以前はインデックスに含まれていなかったため、フィルタリング時に「正しい」アプローチを使用しても特別な効果は見られませんでした。 もう1つは、1か月間のデータを表示する必要がある場合です。 ただ見る必要がなかったもの:
SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE DATEPART(YEAR, PostTime) = 2014 AND DATEPART(MONTH, PostTime) = 7 SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE YEAR(PostTime) = 2014 AND MONTH(PostTime) = 7 SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE EOMONTH(PostTime) = '20140731' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140701' AND PostTime < '20140801'
繰り返しますが、最後のオプションは他のすべてのオプションよりも受け入れられます。

さらに、いつでも計算フィールドを作成し、それに基づいてインデックスを作成できます。
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDay GO ALTER TABLE dbo.DatabaseLog ADD MonthLastDay AS EOMONTH(PostTime) --PERSISTED GO CREATE INDEX IX_MonthLastDay ON dbo.DatabaseLog (MonthLastDay)
前のクエリと比較して、論理読み取り値の違いは重要です(大きなテーブルについて話している場合)。
SET STATISTICS IO ON SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE PostTime >= '20140701' AND PostTime < '20140801' SELECT COUNT_BIG(*) FROM dbo.DatabaseLog WHERE MonthLastDay = '20140731' SET STATISTICS IO OFF
Table 'DatabaseLog'. Scan count 1, logical reads 7, ... Table 'DatabaseLog'. Scan count 1, logical reads 3, ...
8.計算
先ほど言ったように、インデックスフィールドの計算はパフォーマンスを低下させ、論理読み取り値の増加につながります。
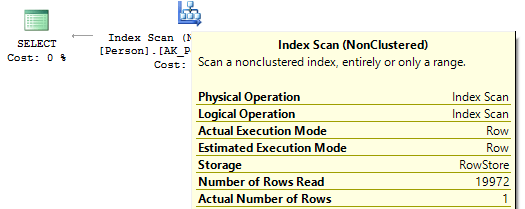
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID * 2 = 10000 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 2500 * 2 SELECT BusinessEntityID FROM Person.Person WHERE BusinessEntityID = 5000
Table 'Person'. Scan count 1, logical reads 67, ... Table 'Person'. Scan count 0, logical reads 3, ...
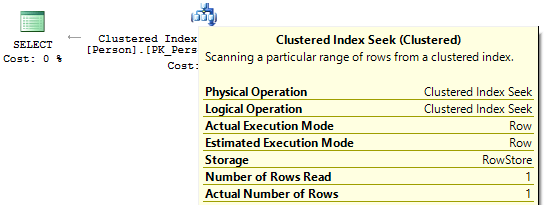
実行計画を見ると、最初のケースでは、 SQL ServerはIndexScanを実行する必要があります 。
2番目と3番目のケースでは、インデックスフィールドに計算がない場合、 IndexSeekが表示されます 。
9.暗黙の変換
最初に、同じ値でフィルタリングするこれら2つのクエリを見てください。
USE AdventureWorks2014 GO SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = 30845 SELECT BusinessEntityID, NationalIDNumber FROM HumanResources.Employee WHERE NationalIDNumber = '30845'
実装計画を見ると:
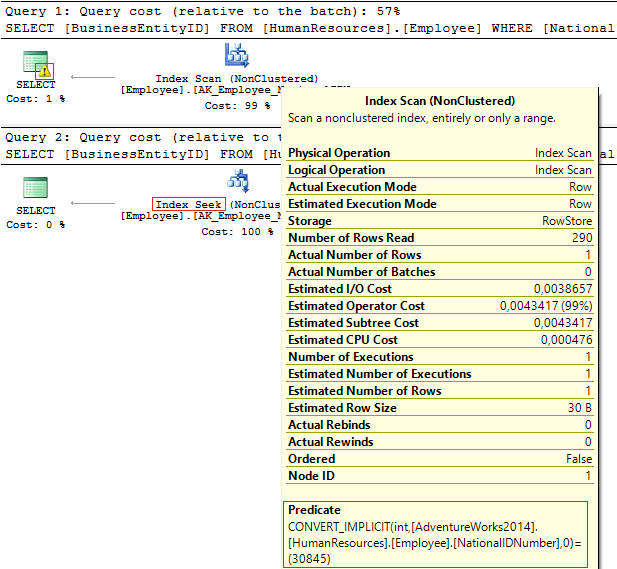
前者の場合-警告とIndexScan、後者の場合-IndexSeek :
Table 'Employee'. Scan count 1, logical reads 4, ... Table 'Employee'. Scan count 0, logical reads 2, ...
どうした NationalIDNumber列のデータ型はNVARCHAR(15)です。 INTとしてデータをフィルター処理する必要がある値で定数を渡すと、結果として暗黙的な型変換が行われ、パフォーマンスが低下する可能性があります。 これは、誰かが列のデータ型を変更したときに頻繁に発生しますが、クエリは同じままです。
ただし、パフォーマンスの問題だけが待っているわけではないことを理解することが重要です。 暗黙的な型変換は、実行時エラーにつながる可能性があります。 たとえば、PostalCodeフィールドが数値になる前に、郵便番号に文字が含まれている可能性があるという指示が上から来ました。 データ型は変更されましたが、英数字の郵便番号が挿入されるとすぐに、古いリクエストは機能しなくなります。
SELECT AddressID FROM Person.[Address] WHERE PostalCode = 92700 SELECT AddressID FROM Person.[Address] WHERE PostalCode = '92700'
Msg 245, Level 16, State 1, Line 16 Conversion failed when converting the nvarchar value 'K4B 1S2' to data type int.
さらに興味深いことに、プロジェクトがEntityFrameworkを使用する場合、デフォルトですべての文字列フィールドをUnicodeとして解釈します。
SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = N'AW00000009' SELECT CustomerID, AccountNumber FROM Sales.Customer WHERE AccountNumber = 'AW00000009'
その結果、最適なクエリは生成されません。
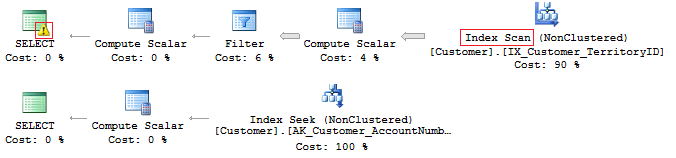
問題の解決策は非常に簡単です-比較中にデータ型が一致するように制御する必要があります。
10. LIKEおよび抑制されたインデックス
カバリングインデックスがある場合でも、それが効果的に使用されるという事実ではありません。 たとえば、...で始まるすべての行を印刷する必要があります。
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT AddressLine1 FROM Person.[Address] WHERE SUBSTRING(AddressLine1, 1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE LEFT(AddressLine1, 3) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE CAST(AddressLine1 AS CHAR(3)) = '100' SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '100%'
次の論理読み取り値を取得します。
Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 216, ... Table 'Address'. Scan count 1, logical reads 4, ...
すぐに勝者を見つけることができる実装計画:
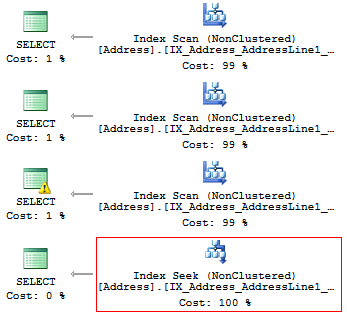
結果は、私たちが長い間話し合ってきた結果です。 インデックスが存在する場合、型や関数などの計算や変換は行われません。 そうして初めて、 SQL Serverによって効率的に使用されます 。
しかし、文字列内の部分文字列のすべての出現を見つける必要がある場合はどうでしょうか? このタスクは明らかに興味深いものです。
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'
しかし、最初に、文字列とそのプロパティについて多くの興味深いことを学ぶ必要があります。
11. UnicodeとANSI
最初に覚えておくべきことは、文字列がUNICODEとANSIであることです。 前者の場合、 NVARCHAR / NCHARデータ型が提供されます(文字あたり2バイト-残念ながら、 UTF8は配信されませんでした)。 ANSI文字列を格納するには-VARCHAR / CHAR (1バイト-1文字)。 TEXT / NTEXTもありますが、最初はそれらを忘れておく方がよいでしょう(それらを使用するとパフォーマンスが大幅に低下する可能性があるため)。
そして、これは終了する可能性がありますが、いいえ...
ユニコード定数がリクエストで指定されている場合、シンボルNの前にそれが必要です。 違いを示すには、単純なクエリで十分です。
SELECT '文本 ANSI' , N'文本 UNICODE'
------- ------------ ?? ANSI 文本 UNICODE
定数の前にNを指定しない場合、 SQL ServerはANSIエンコーディングで適切な文字を探します。 見つからない場合は、疑問符に置き換えます。
12.コレート
ミドル/シニアDB開発者のポジションの面接時に彼らが尋ねたいと思う非常に興味深い例を思い出しました。 次のクエリはデータを返しますか?
DECLARE @a NCHAR(1) = '' , @b NCHAR(1) = '' SELECT @a, @b WHERE @a = @b
そして、はい...そしていいえ...ここに幸運があります。 私は通常そのように答えます。
なぜそんな曖昧な答えなのでしょうか? まず、文字列定数にはNがないため、 ANSIとして解釈されます。 2つ目-現在のCOLLATEに大きく依存します。これは、文字列データの並べ替えと比較のための一連のルールです。
USE [master] GO IF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE test END GO CREATE DATABASE test COLLATE Latin1_General_100_CI_AS GO USE test GO DECLARE @a NCHAR(1) = '' , @b NCHAR(1) = '' SELECT @a, @b WHERE @a = @b
このCOLLATEでは、キリル文字の代わりに疑問符が表示されます。疑問符の文字が等しいためです。
---- ---- ? ?
COLLATEを他のいくつかに変更する必要があります。
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
また、キリル文字が正しく解釈されるため、クエリは何も返しません。
したがって、ここでの教訓は単純です。文字列定数がUNICODEを受け入れる必要がある場合、その前にNを置くのを怠らないでください。 Nが可能な限りスタックしている場合、コインの裏側もあり、オプティマイザーは型変換を実行する必要があります。
行に言及することを他に何を忘れましたか? 「レッツインタビュー」サイクルからの別の良い質問:
DECLARE @a VARCHAR(10) = 'TEXT' , @b VARCHAR(10) = 'text' SELECT IIF(@a = @b, 'TRUE', 'FALSE')
これらの線は等しいですか? そして、はい...そしていいえ...再び私は答えます。 明確な比較が必要な場合は、明示的にCOLLATEを指定する必要があります。
DECLARE @a VARCHAR(10) = 'TEXT' , @b VARCHAR(10) = 'text' SELECT IIF(@a COLLATE Latin1_General_CS_AS = @b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
COLLATEは、文字列を比較およびソートするときに、大文字と小文字を区別する( CS )か、大文字と小文字を区別しない( CI )ことができるためです。 クライアントとテストベースの異なるCOLLATEは、ビジネスロジックの論理エラーだけでなく潜在的な原因です。
ターゲットベースとtempdbの間のCOLLATEが一致しない場合、さらに楽しくなります 。 デフォルトとは異なるCOLLATEでベースを作成しましょう:
USE [master] GO IF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE test END GO CREATE DATABASE test COLLATE Albanian_100_CS_AS GO USE test GO CREATE TABLE t (c CHAR(1)) INSERT INTO t VALUES ('a') GO IF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL DROP TABLE #t1 IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL DROP TABLE #t2 IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL DROP TABLE #t3 GO CREATE TABLE #t1 (c CHAR(1)) INSERT INTO #t1 VALUES ('a') CREATE TABLE #t2 (c CHAR(1) COLLATE database_default) INSERT INTO #t2 VALUES ('a') SELECT c = CAST('a' AS CHAR(1)) INTO #t3 DECLARE @t TABLE (c VARCHAR(100)) INSERT INTO @t VALUES ('a') SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation') UNION ALL SELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation') UNION ALL SELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM t UNION ALL SELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t1 UNION ALL SELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t2 UNION ALL SELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FROM #t3 UNION ALL SELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FROM @t
テーブルが作成されると、 COLLATEはデータベースから継承されます。 唯一の違いは、 COLLATEを指定せずに構造を明示的に定義する最初の一時テーブルです。 この場合、 tempdbベースからCOLLATEを継承します 。
------ -------------------------- tempdb Cyrillic_General_CI_AS test Albanian_100_CS_AS t Albanian_100_CS_AS #t1 Cyrillic_General_CI_AS #t2 Albanian_100_CS_AS #t3 Albanian_100_CS_AS @t Albanian_100_CS_AS
COLLATEが一致しない場合、潜在的な問題につながる可能性があるため、 #t1を使用した例について説明します。
たとえば、 COLLATEでは大文字と小文字が区別されないため、データは正しくフィルタリングされません。
SELECT * FROM #t1 WHERE c = 'A'
または、 SQL Serverは、 COLLATEが異なるためにテーブルを結合できないことを誓います 。
SELECT * FROM #t1 JOIN t ON [#t1].c = tc
後者の例は非常に一般的です。 テストサーバーではすべてが完璧であり、バックアップをクライアントサーバーに展開すると、エラーが発生します。
Msg 468, Level 16, State 9, Line 93 Cannot resolve the collation conflict between "Albanian_100_CS_AS" and "Cyrillic_General_CI_AS" in the equal to operation.
それから、どこでも松葉杖を作らなければなりません:
SELECT * FROM #t1 JOIN t ON [#t1].c = tc COLLATE database_default
13.バイナリコレート
軟膏のフライが終わったので、 COLLATEをどのように活用できるかを見てみましょう。 文字列内の部分文字列を見つける例について覚えていますか?
SELECT AddressLine1 FROM Person.[Address] WHERE AddressLine1 LIKE '%100%'
この要求は大幅に最適化され、実行時間が短縮されます。
しかし、違いを見えるようにするには、大きなテーブルを生成する必要があります。
USE [master] GO IF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE test END GO CREATE DATABASE test COLLATE Latin1_General_100_CS_AS GO ALTER DATABASE test MODIFY FILE (NAME = N'test', SIZE = 64MB) GO ALTER DATABASE test MODIFY FILE (NAME = N'test_log', SIZE = 64MB) GO USE test GO CREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL ) GO ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b) INSERT INTO t SELECT v, v FROM ( SELECT TOP(50000) v = REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8 ) t
インデックスの作成を忘れずに、バイナリCOLLATEを使用して計算列を作成します。
ALTER TABLE t ADD ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2 ALTER TABLE t ADD unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2 CREATE NONCLUSTERED INDEX ansi ON t (ansi) CREATE NONCLUSTERED INDEX unicod ON t (unicod) CREATE NONCLUSTERED INDEX ansi_bin ON t (ansi_bin) CREATE NONCLUSTERED INDEX unicod_bin ON t (unicod_bin)
フィルタリングを実行します。
SET STATISTICS TIME, IO ON SELECT COUNT_BIG(*) FROM t WHERE ansi LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE unicod LIKE '%AB%' SELECT COUNT_BIG(*) FROM t WHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SELECT COUNT_BIG(*) FROM t WHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2 SET STATISTICS TIME, IO OFF
そして、実行の結果を見ることができます。これは嬉しい驚きです。
SQL Server Execution Times: CPU time = 350 ms, elapsed time = 354 ms. SQL Server Execution Times: CPU time = 335 ms, elapsed time = 355 ms. SQL Server Execution Times: CPU time = 16 ms, elapsed time = 18 ms. SQL Server Execution Times: CPU time = 17 ms, elapsed time = 18 ms.
全体のポイントは、バイナリ比較に基づいた検索がはるかに高速であり、行の出現を迅速かつ迅速に検索する必要がある場合、データはBINで終わるCOLLATEで格納できることです。覚えておくべき唯一のことは、比較する際に大文字と小文字を区別するすべてのバイナリCOLLATEです。
14.コードスタイル
コードの記述スタイルは厳密に個別ですが、開発に混乱をもたらさないために、誰もが特定のルールを長く守ってきました。最も逆説的なことは、クエリを作成するときに、1つのまともなルールセットを見たことがないということです。それらのすべては、「主なことは働くことです」という原則に従って書いています。ただし、クライアントサーバーにデータベースを展開する場合、休憩を取るリスクがあります。
別のデータベースとその中のテーブルを作成しましょう:
USE [master] GO IF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE test END GO CREATE DATABASE test COLLATE Latin1_General_CI_AS GO USE test GO CREATE TABLE dbo.Employee (EmployeeID INT PRIMARY KEY)
次のクエリを作成します。
select employeeid from employee
動作しますか?COLLATEを大文字と小文字を区別して変更してみてください。
ALTER DATABASE test COLLATE Latin1_General_CS_AI
そして、リクエストを再実行してみてください:
Msg 208, Level 16, State 1, Line 19 Invalid object name 'employee'.
オプティマイザーは、実行プランを作成するときに現在のCOLLATEルールを使用します。より正確には、バインディング段階で、テーブル、列、その他のオブジェクトの存在を確認し、構文ツリーの各オブジェクトをシステムカタログの実際のオブジェクトと比較するとき。
どこでも動作するペンを使用してクエリを生成する場合は、クエリで使用されるオブジェクトの名前の正しいレジスタに常に準拠する必要があります。
物事は変数でさらにおもしろい...
それらのために、COLLATEはマスターベースから継承されます。したがって、変数を操作するときは正しいレジスターに従う必要があります。
SELECT DATABASEPROPERTYEX('master', 'collation') DECLARE @EmpID INT = 1 SELECT @empid
そのエラーはほとんどの場合そうではありません:
----------------------- Cyrillic_General_CI_AS ----------- 1
同時に、別のサーバーでは、登録のエラーが感じられる場合があります。
-------------------------- Latin1_General_CS_AS
Msg 137, Level 15, State 2, Line 4 Must declare the scalar variable "@empid".
15. [var] char
, ( CHAR , NCHAR ) ( VARCHAR , NVARCHAR ):
DECLARE @a CHAR(20) = 'text' , @b VARCHAR(20) = 'text' SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"' SELECT [a = b] = IIF(@a = @b, 'TRUE', 'FALSE') , [b = a] = IIF(@b = @a, 'TRUE', 'FALSE') , [a LIKE b] = IIF(@a LIKE @b, 'TRUE', 'FALSE') , [b LIKE a] = IIF(@b LIKE @a, 'TRUE', 'FALSE')
20 , 4, SQL Server 16 ( LEN DATALENGTH -):
--- --- ---- ---- ---------------------- ---------------------- 4 4 20 4 "text " "text"
, — :
a = bb = aa LIKE bb LIKE a ----- ----- -------- -------- TRUE TRUE TRUE FALSE
LIKE :
SELECT 1 WHERE 'a ' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a ' -- !!! SELECT 1 WHERE 'a' LIKE 'a' SELECT 1 WHERE 'a' LIKE 'a%'
.
16. Data length
, :
DECLARE @a DECIMAL , @b VARCHAR(10) = '0.1' , @c SQL_VARIANT SELECT @a = @b , @c = @a SELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
この問題の本質は何ですか?型の次元を明示的に指定せず、小数値の代わりに「整数の並べ替え」を取得します。
---- ---- ---------- ----- ----- 0 0 decimal 18 0
まだ面白い文字列で:
DECLARE @t1 VARCHAR(MAX) = '123456789_123456789_123456789_123456789_' DECLARE @t2 VARCHAR = @t1 SELECT LEN(@t1) , @t1 , LEN(@t2) , @t2 , LEN(CONVERT(VARCHAR, @t1)) , LEN(CAST(@t1 AS VARCHAR))
次元が明示的に示されていない場合、文字列の長さは1文字になります。
----- ------------------------------------------ ---- ---- ---- ---- 40 123456789_123456789_123456789_123456789_ 1 1 30 30
この場合、型変換の動作には独自の特性があります。CAST / CONVERTでディメンションを指定しなかった場合、最初の30文字が使用されます。
17. ISNULL対COALESCE
他に潜在的に興味深いものは何を示すことができますか?ISNULLとCOALESCEの 2つの関数があります。一方では、すべてが単純です。最初の演算子がNULLの場合、2番目の演算子を返します。COALESCEについて話している場合は、次の演算子を返します。一方、2つの間には陰湿な違いがあります。
これらの関数は何を返しますか?
DECLARE @a CHAR(1) = NULL SELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL') DECLARE @i INT = NULL SELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
答えは本当に明白ではありません:
---- ---- N NULL ---- ---- 7 7.1
なんで?ISNULL関数は、2つのオペランドの最小タイプに変換します。COALESCEは最大の型に変換されます。だから私たちは、「何が間違っているのか」を理解しようとして非常に長い時間座ったのが初めてだ。
パフォーマンスの観点から、ISNULLは多くのケースで少し速く動作しますが、COALESCEはCASE WHENステートメントで拡張されます。これについては以下で説明します。
18.数学
SQL Serverで数学に出くわすと、さらに興味深いものになります。違いはないようです:
SELECT 1 / 3 SELECT 1.0 / 3
しかし実際には、違いがあることがわかります-それはすべて、リクエストに含まれるデータに依存します。整数の場合、結果は整数になります。
----------- 0 ----------- 0.333333
面接でよく見られる別の興味深い例:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val) FROM ( VALUES (1), (2), (2), (NULL), (NULL) ) t (val) SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT)) FROM ( VALUES (1), (2), (2), (NULL), (NULL) ) t (val)
何がリクエストを返しますか?COUNT(*)/ COUNT(1)は行の総数を返します。COUNT列は、非NULL行の数を返します。DISTINCTを追加すると、NULLでない一意の値の数。
平均の計算でより興味深い。AVG操作は、オプティマイザーによってSUMとCOUNTに分解されます。そして、ここで上記の例を思い出してください-平均を計算するとき、NULLは考慮されません。また、値が整数の場合、結果はどうなりますか?整数。これはしばしば忘れられます。
19. UNION vs UNION ALL
ここではすべてが単純です。データが交差しないことがわかっており、重複を気にしない場合は、パフォーマンスの観点から、UNION ALLを使用することをお勧めします。重複を削除する必要がある場合は、UNIONを大胆に使用します。
たとえば、重複が間違いなくUNION ALLを使用する方が適切でない場合:
SELECT [object_id] FROM sys.system_objects UNION SELECT [object_id] FROM sys.objects SELECT [object_id] FROM sys.system_objects UNION ALL SELECT [object_id] FROM sys.objects
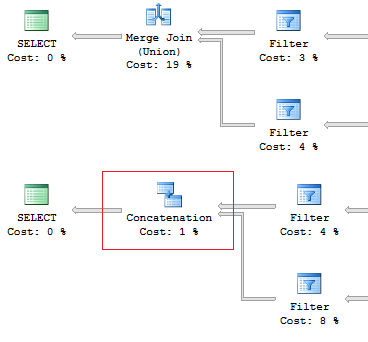
2つの構成要素の興味深い違いについて知ることは依然として重要です。UNIONステートメントは並列で実行され、UNION ALLは直列で実行されます。これは並列プランには当てはまりません。最適化に役立つのは、まさにこのようなデータアクセスの機能です。
異なる条件セットに基づいて1行を返す必要があるとします。
DECLARE @AddressLine NVARCHAR(60) SET @AddressLine = '4775 Kentucky Dr.' SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 = @AddressLine OR AddressLine2 = @AddressLine
次に、条件でORを使用して、IndexScanを取得します。

Table 'Address'. Scan count 1, logical reads 90, ...
UNION ALLを使用してクエリを書き換えます。
SELECT TOP(1) AddressID FROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 = @AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 = @AddressLine ) t
SQL Serverは、最初のサブクエリを実行した後、結果を返すのに十分な1行が返されたことを確認し、2番目の条件による検索を続行しません。
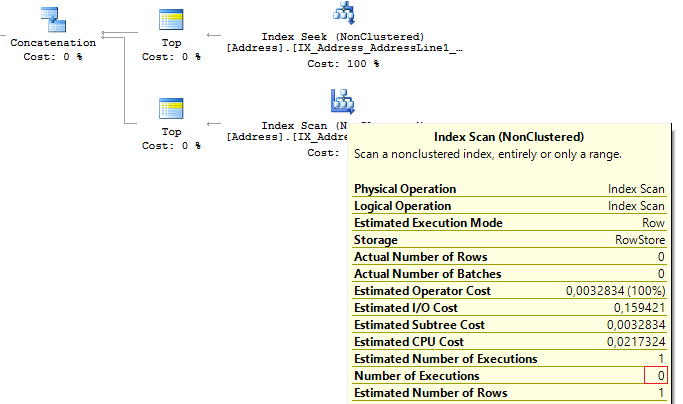
Table 'Worktable'. Scan count 0, logical reads 0, ... Table 'Address'. Scan count 1, logical reads 3, ...
20.再読み込み
多くの場合、1つのJOINの助けを借りてデータを引き出すことができる状況が発生しましたが、多くのサブクエリが要求を誇っていました。
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID = p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID = p.BusinessEntityID ) FROM HumanResources.Employee e SELECT e.BusinessEntityID , p.LastName , p.FirstName FROM HumanResources.Employee e JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
実際、テーブルへの不必要なアクセスが少ないほど、論理的な測定値は少なくなります。
Table 'Person'. Scan count 0, logical reads 1776, ... Table 'Employee'. Scan count 1, logical reads 2, ... Table 'Person'. Scan count 0, logical reads 888, ... Table 'Employee'. Scan count 1, logical reads 2, ...
21.サブクエリ
前の例は、テーブル間の接続が1対1の場合にのみ機能するため、非常に明らかになっています。
テーブルPerson.PersonとSales.SalesPersonQuotaHistoryの間にこのような関係が生じる前に、1人の従業員について、クォータサイズごとに最大1つのレコードがあることが判明したとします。
USE AdventureWorks2014 GO SET STATISTICS IO ON SELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID = p.BusinessEntityID ) FROM Person.Person p
クライアントサーバーは異なる場合があり、この要求により次のエラーが発生します。
Msg 512, Level 16, State 1, Line 6 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.
このような問題はどのように解決されますか?TOP(1)とORDER BYが
追加され、問題はなくなりました。ただし、すべてが見た目ほど単純ではありません。TOP操作を使用すると、オプティマイザーはIndexSeekの使用を強制します。TOPと一緒にOUTER / CROSS APPLYを使用すると、同じ結果が生じます。
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID = p.BusinessEntityID ORDER BY s.QuotaDate DESC ) FROM Person.Person p SELECT p.BusinessEntityID , t.SalesQuota FROM Person.Person p OUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID = p.BusinessEntityID ORDER BY s.QuotaDate DESC ) t
それらが実行されると、同じ問題が発生します-複数のIndexSeek操作:

Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ... Table 'Person'. Scan count 1, logical reads 67, ...
ウィンドウ関数で武装して、リクエストを書き換えます:
SELECT p.BusinessEntityID , t.SalesQuota FROM Person.Person p LEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum = ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s ) t ON p.BusinessEntityID = t.BusinessEntityID AND t.RowNum = 1
そして、何が変わったのか見てみましょう:

Table 'Person'. Scan count 1, logical reads 67, ... Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
22.ケース
この言語構成体について何が言えるでしょうか?よく使用され、あまり知られていない機能について知っておく必要があります。かかわらず、我々はオペレータ書き方のCASEのを:
USE AdventureWorks2014 GO SELECT BusinessEntityID , Gender , Gender = CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' END FROM HumanResources.Employee
SQL Serverは式を次の形式に展開します。
SELECT BusinessEntityID , Gender , Gender = CASE WHEN Gender = 'M' THEN 'Male' WHEN Gender = 'F' THEN 'Female' ELSE 'Unknown' END FROM HumanResources.Employee
これが主な問題です。各条件は、そのうちの1つがTRUEを返すか、ELSEブロックに到達するまで順次実行されます。
問題をより明確に示しましょう。これを行うには、郵送先住所の右側を返すスカラー関数を作成します。
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrl GO CREATE FUNCTION dbo.GetMailUrl ( @Email NVARCHAR(50) ) RETURNS NVARCHAR(50) AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email)) END
SQL Profiler SQL:StmtStarting / SP:StmtCompleted ( XEvents : sp_statement_starting / sp_statement_completed ).
:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' END FROM Person.EmailAddress
10 . :
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' END FROM Person.EmailAddress
20 . , CASE . - . , CASE — .
:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' END FROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl = dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress ) t
関数は10回実行されます。
さらに、CASEステートメントを重複してロードしないようにする必要があります。
SELECT DISTINCT CASE WHEN Gender = 'M' THEN 'Male' WHEN Gender = 'M' THEN '...' WHEN Gender = 'M' THEN '......' WHEN Gender = 'F' THEN 'Female' WHEN Gender = 'F' THEN '...' ELSE 'Unknown' END FROM HumanResources.Employee
CASEの式は順番に計算されますが(記述したとおりの順序で)。場合によっては、このステートメントは集約された関数を使用してSQL Serverによって実行されます。
DECLARE @i INT = 1 SELECT CASE WHEN @i = 1 THEN 1 ELSE 1/0 END GO DECLARE @i INT = 1 SELECT CASE WHEN @i = 1 THEN 1 ELSE MIN(1/0) END
23.スカラー関数
特にOOPが好きな人- 多数の行を操作するT-SQLクエリではスカラー関数を使用しないでください。
これは、スカラー関数の潜在的な欠点についてまだ知らなかったときに苦しんだ人生の例です。
USE AdventureWorks2014 GO UPDATE TOP(1) Person.[Address] SET AddressLine2 = AddressLine1 GO IF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqual GO CREATE FUNCTION dbo.isEqual ( @val1 NVARCHAR(100), @val2 NVARCHAR(100) ) RETURNS BIT AS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 = @val2 THEN 1 ELSE 0 END END
クエリは同一のデータを返します:
SET STATISTICS TIME ON SELECT AddressID, AddressLine1, AddressLine2 FROM Person.[Address] WHERE dbo.IsEqual(AddressLine1, AddressLine2) = 1 SELECT AddressID, AddressLine1, AddressLine2 FROM Person.[Address] WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 = AddressLine2 SELECT AddressID, AddressLine1, AddressLine2 FROM Person.[Address] WHERE AddressLine1 = ISNULL(AddressLine2, '') SET STATISTICS TIME OFF
しかし、スカラー関数の各呼び出しはリソースを集中的に使用するため、この違いが生じます。
SQL Server Execution Times: CPU time = 63 ms, elapsed time = 57 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 1 ms.
さらに、クエリでスカラー関数を使用すると、SQL Serverが並列実行プランを作成できなくなります。これにより、大量のデータがある場合、パフォーマンスが大幅に低下する可能性があります。
すべての場合において、スカラー関数は悪ですか?いや オプションを使用して関数を作成できます SCHEMABINDINGを使用して、入力パラメーターを使用せずにます。
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPI GO CREATE FUNCTION dbo.GetPI () RETURNS FLOAT WITH SCHEMABINDING AS BEGIN RETURN PI() END GO SELECT dbo.GetPI() FROM Sales.Currency
この場合、関数は確定的であると見なされ、1回だけ実行されます。
24.ビュー
誰かがパフォーマンスを愛しています...誰かは好きではありません。ビューを使用しないことについて意見を述べる方が費用はかかりますが、ビューを操作する際にはいくつかの機能について知る必要があります。
テストテーブルとそれに基づいたビューを作成します。
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tbl GO CREATE TABLE dbo.tbl (a INT, b INT) GO INSERT INTO dbo.tbl VALUES (0, 1) GO IF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tbl GO CREATE VIEW dbo.vw_tbl AS SELECT * FROM dbo.tbl GO SELECT * FROM dbo.vw_tbl
値は正しく返されます。
ab ----------- ----------- 0 1
次に、テーブルに新しい列を追加し、ビューからデータの減算を再試行します。
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2 GO SELECT * FROM dbo.vw_tbl
同じ結果が得られます。
ab ----------- ----------- 0 1
そして、すべて明示的に列を設定するか、スクリプトオブジェクトを再コンパイルする必要があるためです。
EXEC sys.sp_refreshview @viewname = N'dbo.vw_tbl' GO SELECT * FROM dbo.vw_tbl
正しい結果を得るには:
abc ----------- ----------- ----------- 0 1 2
テーブルへの直接参照では、このような冗談はありません。
すべてのデータを結合し、すべてを1つのビューにまとめるという1つの要求にアマチュアがいます。例を挙げて説明するのではなく、AdventureWorksの「良いパターン」を見てみましょう。
ALTER VIEW HumanResources.vEmployee AS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID = e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID = e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID = bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID = a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode = sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID = p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID = pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID = ea.BusinessEntityID
そして今、質問は...すべての情報ではなく、その一部のみを取得する必要がある場合はどうなりますか?たとえば、従業員の名前と姓を返します。
SELECT BusinessEntityID , FirstName , LastName FROM HumanResources.vEmployee SELECT p.BusinessEntityID , p.FirstName , p.LastName FROM Person.Person p WHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
ビューを使用する場合の実行計画を見てみましょう。

Table 'EmailAddress'. Scan count 290, logical reads 640, ... Table 'PersonPhone'. Scan count 290, logical reads 636, ... Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ... Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
そして、ペンで有意義に書いたクエリと比較します。

Table 'Person'. Scan count 0, logical reads 897, ... Table 'Employee'. Scan count 1, logical reads 2, ...
オプティマイザー SQL Server非常に巧妙に作成されており、実行プランを構築するときに演算子ツリーを簡素化する段階で、未使用の接続を破棄できます。
ただし、彼は常にこれを効率的に行うことはできません。「接続が選択結果に影響するかどうか」を確認する方法がない場合、テーブル間に有効な外部キーがないために妨げられることがあります。または、たとえば、接続が複数のフィールドを経由する場合...まあ、オプティマイザーはいくつかのことを知りませんが、これは不必要な作業でそれをロードする理由ではありません。
25.カーソル
SQL Serverを使用する場合、 1つの真実を覚えておいてください。カーソルを使用してデータを繰り返し変更しないでください。これはOracleではありません!
多くの場合、このコードを見つけることができます。
DECLARE @BusinessEntityID INT DECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.Employee OPEN cur FETCH NEXT FROM cur INTO @BusinessEntityID WHILE @@FETCH_STATUS = 0 BEGIN UPDATE HumanResources.Employee SET VacationHours = 0 WHERE BusinessEntityID = @BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityID END CLOSE cur DEALLOCATE cur
このコードは次のように書き換えることができます。
UPDATE HumanResources.Employee SET VacationHours = 0 WHERE VacationHours <> 0
ランタイムと論理読み取りの数をもたらす価値はありませんが、信じてください、本当に違いがあります。オプションとして、人生の最近の例についてお話しします。2つのネストされたカーソルが存在するスクリプトを満たしました。このコードを実行すると、クライアントでタイムアウトが発生し、合計で約38秒間実行されました。リクエストから最初のカーソルを放り出し、リクエストは600ミリ秒間実行され始めました。2番目のカーソル-200ミリ秒を捨てました。SQL Serverの
カーソル -悪!
26. STRING_CONCAT
— , . ?
STRING_CONCAT , … 2016 , , SQL Server . - ?
:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #t GO CREATE TABLE #t (i CHAR(1)) INSERT INTO #t VALUES ('1'), ('2'), ('3')
«» — :
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t SELECT @txt
-------- 123
, MS , , :
DECLARE @txt VARCHAR(50) = '' SELECT @txt += i FROM #t ORDER BY LEN(i) SELECT @txt
-------- 3
率直に言って、初めて、会計報告書に最後の行しか表示されない理由を自分で考えました。このジョークの後、CLR、UPDATE、一時テーブル、再帰、ループなど、さらに多くのことが行われました。それが行の接着です。
実際には、90%のケースで、XMLを使用するだけで十分です。
SELECT [text()] = i FROM #t FOR XML PATH('')
-------- 123
ただし、ここではいくつかのニュアンスが期待できます。最初に、すべてのデータではなく、一部のデータのコンテキストで行を接着する必要が非常に頻繁にあります。
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] = t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') FROM sys.objects t WHERE t.[type] = 'U'
------------------------ ------------------------------------ ScrapReason ScrapReasonID, Name, ModifiedDate Shift ShiftID, Name, StartTime, EndTime
XMLメソッドは構文解析に使用しないようにすることを強くお勧めします。XMLメソッドは非常にリソースを消費するためです。
低コストにすることができます:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] = t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '') FROM sys.objects t WHERE t.[type] = 'U'
しかし、これは本質を根本的に変えるものではありません。値メソッドを使用しないようにしてください:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] = t.[object_id] FOR XML PATH('')), 1, 2, '') FROM sys.objects t WHERE t.[type] = 'U'

, «». :
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] = t.[object_id] FOR XML PATH('')), 1, 2, '') FROM sys.objects t WHERE t.[type] = 'U'
, , , .
: , value , value('(./text())[1]'... .
27. SQL Injection
sql injection , . :
DECLARE @param VARCHAR(MAX) SET @param = 1 DECLARE @SQL NVARCHAR(MAX) SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = ' + @param PRINT @SQL EXEC (@SQL)
:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1
- :
SET @param = '1; select ''hack'''
:
SELECT TOP(5) name FROM sys.objects WHERE schema_id = 1; select 'hack'
, sql injection , - «». — :)
String.Format ( ), , sql injection :
using (SqlConnection conn = new SqlConnection()) { conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command = new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id = {0}", value), conn); using (SqlDataReader reader = command.ExecuteReader()) { while (reader.Read()) {} } }
, sp_executesql :
DECLARE @param VARCHAR(MAX) SET @param = '1; select ''hack''' DECLARE @SQL NVARCHAR(MAX) SET @SQL = 'SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id' PRINT @SQL EXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id = @param
, - .
:
using (SqlConnection conn = new SqlConnection()) { conn.ConnectionString = @"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command = new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id = @schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ... }
, …
38
— 8- . , T-SQL . , .
, « » SQL Server , , - . .
この記事を英語圏の聴衆と共有したい場合:
SQL Server: Useful Tips for Newbies
映像
, «» russianVC : . .
船外に残っているものは何ですか?
最初に、一時テーブルとテーブル変数の違いについて詳細に記述することを計画します。最終的に、私はこれを1月に完了するのを待っている別のポストに配置することにしました。
さらに、パラメータースニッフィングについてすぐに話したいと思いましたが、車輪を再発明せずに、Dmitry Pilyugin:Slowでアプリケーションの速度が遅い、優れた投稿へのリンクを提供する方が良いでしょう。
質問、建設的な提案、合理的な批判がある場合は、プロファイル内のすべての連絡先。