実際、この投稿は、以前の「技術」出版物[1、2、3、4、5]の結果と生じた議論をまとめた要約です。 後者は、Rの使用がビジネスに非常に役立つ可能性のあるタスクが非常に多いことを示しました。 ただし、Rが使用されている場合でも、Rの最新の機能がこれに常に使用されるとは限りません。
Rをビジネスに適用するためのニッチはオープンであり、西側でもロシアでも非常に重要です。
この声明がロシアにとって特に興味深いのはなぜですか?
1.省庁と政府のレベルで管理されているソフトウェアの輸入代替の積極的なプロセスがあります 。 多くの人は、正当な理由を考え出すよりも許可リストのソフトウェアを使用することを好み、外国のソフトウェアを購入する必要があることを証明します。 そして、国有企業への注目はずっと近い。
2.残念ながら、危機が終わり、上昇が始まっているという報告はありません。 ベルトを締めます-はい。 これは、高価な玩具の予算があまり予測されていないことを意味します。 同時に、誰もタスクの解決をキャンセルしませんでした;タスクの数と野心は増加するだけです。
3.ビジネスは、ITが競争上の優位性を生み出さない場合、少なくとも手動または自動の意思決定のために情報フィールドを迅速に準備するのに役立つはずであると非常に正しく信じています。 同時に、多くの場合、ビジネスリクエストは非常に散文的であり、ノーベル賞受賞者を惹きつけて解決することは控えめです。
実際、「デジタル」海で自信を持って泳ぐために、ビジネスは情報スペースのローカルな「ステッチ」とインタラクティブな表現の形成だけで、非常に限られた一連の問題とプロセスのコンテキストで意思決定プロセスを簡素化します。
一般的に、意思決定の状況は次のように説明できます。
- どの会社でも、すべての従業員は毎日多くの重要なビジネス上の決定を下しています。
- 決定を下す時間はわずかです(数時間)。
- 質問は常に明確で明確な形で定式化されるわけではありません。
- 決定を下すには、複雑な数学的データ処理が必要になる場合があります。
技術的には、このプロセスは「コレクション-処理-モデリングと分析-可視化/アンロード」というチェーンで記述されています。
「クロスリンク」の局所性は、強力な産業用ETL \ BI \ BigDataソリューションの使用が技術的および経済的な観点から完全に不当であるという事実につながります。
ニンジンのベッドを植えるために、数十ヘクタールの土地を耕さないでください。
一方、このようなコンテキストはエコシステムRにとって非常に快適であり、一度に実行されます。 ビジネスの場合、「1-2-3」アプローチは次の画像に要約できます(ビジネスは写真が大好きです)。

Rを使用する場合、技術的には、データソースの種類とフォーマット、クリーンさ、描画と表示の方法と方法はほぼ同じです。 ほとんどすべてが可能です。 主なものは、定式化されたビジネスタスクを持つことです。
実例に戻る
上記のアプローチの適用性の実証として、 「ITシステムの古典的統合の代替としてのデータサイエンスツール」で前述したトピック、つまり、現代の方向「精密農業」のサブタスクの一部としての農学者のコンソールの例をもう一度見てみましょう。
サブタスク自体は非常に散文的です。「 作物の特性、生物季節、気候条件(過去、現在、予測)を考慮に入れて畑の灌漑を最適化し、作物の品質を向上させ、コストを削減します 。」
当然、IT分析サブシステムはサブシステムの1つにすぎません。 完全な複合体は、最適な方法の選択と、土壌水分の物理的指標の直接測定(それ自体は簡単ではありません)および環境パラメーター、センサーの自律的な動作、およびフィールドの規模(数十キロメートル)を考慮した無線チャネルを介した遠隔測定の送信、低コスト+コンパクト性のタスクもカバーします+シーズンを通してバッテリーを変更せずに動作し、センサーの配置を最適化し、地元住民の関心の高まりを含むさまざまな影響からセンサーを保護し、また水のバランスを考慮します 植物(大体、吸収-蒸発)。 しかし、これらのタスクはすべてこの出版物の範囲外です。
したがって、コンソールは農学者です。 すべてはR + Shiny + DeployRで行われます。 次のスクリーンショットに、コンソールの動作バージョンの例を示します。
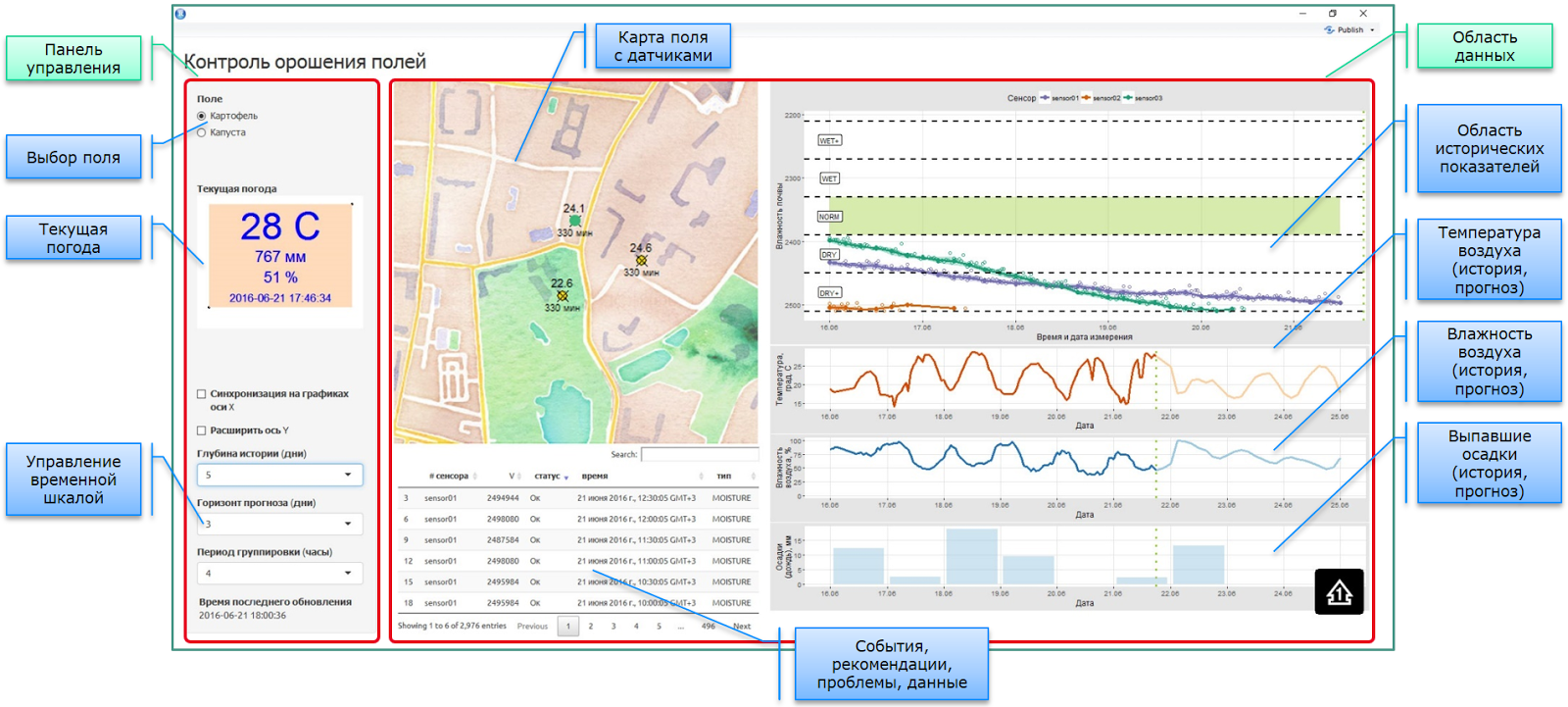
詳細に飛び込むまで、すべてがシンプルで些細なように見えます。 すなわち、 ローカルデータスティッチングに対する提案されたアプローチが詳細に明示されています。
1.すべてすべての情報を含む厳格なデータモデルを持つグローバルリポジトリはありません。 それどころか、情報のサブセットを独自の形式で含む自律的または半自律的なサブシステムのセットがあります。
2.視聴者がいる場合、農学者のコンソールとそこに表示される情報が必要なので、アプリケーション自体がメッセージマネージャーの無限ループとして機能します。 コンソールは動的で、再カウントの必要性はタイマーベースでチェックされ、Shinyプラットフォームのリアクティブエレメントを使用してエレメントが自動的に更新されます。 同時に、自律運用分析は、コンソールに依存しないモードでRサーバー上に存在します。
3.現在の天気。 データは、Webソース(REST API)およびフィールド内の実際のセンサーデータ(log \ csv + git)を含むいくつかのソースから取得されます。 フィールド上のすべてのセンサーはバッテリーを節約し、独自のモードで通信するため、データは非同期モードでコンソールに送信されます。 gitリポジトリは、フィールドデータウェアハウスとして使用されました。
4.運用分析のために、インターフェイスには、表示されるスライスを制御する要素などが含まれます。 再カウントはすべて、設定の変更時に発生します。
5.現場にセンサーを設置したGISカード。 フィールドセンサーのインフラストラクチャがオーバーレイされた多層マップ(ここでは、OpenStreet基板として)、およびこれらのセンサーの動的に再計算されたインジケーター(現在のステータス、現在の読み取り値、最後の読み取り時間など)。 センサーに関するメタ情報は、IoT機器用のクラウドベースの会計システムから取得されます。 IoTプラットフォームオブジェクトのやや複雑な内部論理構造により、センサーデータを取得するには、3〜4個のREST APIリクエストのチェーンを中間処理で実行する必要があります。
6.イベント情報の出力の表形式表示:指示、ログ、推奨事項、問題、予測。 表示される各タイプの情報は、個別のソース(接続、収集、解析、前処理)から取得されるか、マットの作業の結果です。 アルゴリズム(予測や推奨など)。
7.データ領域(右側)は、さまざまなソースから受信および処理される単一のコンソール情報に結合されます。
過去の気象指標に関するデータ。 フィールドセンサーデータ(txt + git)とオープンWebソースからの気象データを使用します。 無料のアカウント(いくつかのWebソースの予備分析後)にはどこにも深い歴史がないため、農業生産者の気象データにアクセスするために月額100-150ドルを支払うという考えはまったく満足していません。現在の監視に基づくデータ(REST API-> txt + git)。 そして、もちろん、異なるソースからのデータが競合する場合、それを解決する必要があります。 主な情報源の1つとして、 Open Weather Map-OWMに決めました
予測部分では、いくつかの質問も提起されました。 異なるソースは、異なる粒度で異なる情報を提供します。 すべてのソースが降水量をmmで予測するわけではありません。 彼らが与えるなら、誰もが毎時与えるわけではありません。 ユニットを発行できます。 彼らは何らかの形で削減する必要があります。
特に、降水量を要求する場合、OWMは固定の瞬間から開始して、mm単位で3時間の集計を発行します。 過去について話すと、凝視の瞬間もランダムに発行されます。 したがって、3時間単位と多数の繰り返しを含む任意の時系列を取得し、それに応じて1時間ごとの画像を復元する必要があります。
センサーからのデータは、さまざまなチャネルを介して入力されます。 センサー自体は非同期モード(バッテリー節約)で「ライブ」であるため、センサーからのデータは強制ポーリングの可能性なしにストリームモードで送信されます。 保証されていない通信チャネル(すべてがフィールドにあり、カバレッジエリアが悪い場合もあります)およびセンサーハードウェアプラットフォームのさまざまなバージョンは、分析のためにすべての潜在的なストレージからデータを収集する必要があるという事実につながります。 現在、センサーデータはgit(構造化されたビューとログ)およびIoTデバイスを管理するためのクラウドプラットフォームに送信されています。
- センサーからのデータ(フィールド上の2または5ではありません)は、予備的な数学的処理を受けます。 土壌水分の測定の詳細と直接測定は不可能であるため(NMRまたは放射分析法に関する特定の注意事項を伴う)、間接測定の結果は土壌の構造特性に大きく依存します。 各センサーの読み取り値の信頼性を判断するために、専用の検量線と、履歴データ、予想される指標、実施された灌漑に関するデータ、および現場の他のセンサーからの情報の両方に依存する必要があります。
おわりに
欧米では、Rコミュニティと解決すべき課題の範囲が指数関数的に発展しています。 オープンソースが積極的に登場しています。 R-bloggersアグリゲーターを起動パッドとして使用して、Rパートの最新の開発に慣れることができます。 たとえば、非常に興味深い最新のビジネスポストは次のとおりです。 「Rを使用して1秒あたり100万トランザクションで不正を検出する」
ロシアでは、ビジネスタスクでRを使用するためのすべての前提条件がありますが、これまでのところ、コミュニティは比較的脆弱です。 一方、Habrの積極的で興味をそそる聴衆は、我が国における最新のITテクノロジーの最高の指揮者です。
あなたの会社に存在する問題を新しい方法で解決し、新しいツールを使用して、得られた経験を共有し始めましょう。 公開討論での問題と理解できない点の議論は、これにのみ貢献します。
PSところで、 dplyr
パッケージのセマンティクスは、Apach Sparkで使用することdplyr
できます。 この透明性を提供するために、 sparkly
パッケージがリリースされました。
前の投稿: 「Rスピードを見逃していますか?隠れた埋蔵量を探しています」
次の投稿: 「Rを使用したライブ分析の準備と他のビジネスユニットへの転送」