Intel Core i7 6700Kプロセッサに統合された第9世代HDグラフィックス530、8ブロックの3つのフラグメントで構成される24の命令実行ユニット(EU)。
驚いたことに、Intelはハードウェアアクセラレーションビデオコーディングの実装でAMDとNvidiaの両方を回避することができました: AMDとNvidia NVENCテクノロジーは 、AMDとNvidiaビデオカードにかなりの遅延を伴って登場しました(圧縮アルゴリズムにはビデオプロセッサへの深刻な適応が必要です)。 それが、QSVのアイデアと開発が5年間秘密にされてきた理由です。
QSVが需要があったと言うことは言うまでもありません。 ハードウェアサポートを使用したビデオの再生(デコード)は、OSの他のタスクからのリソース消費を大幅に削減し、CPUの過熱を抑え、消費電力を削減しました。
さらに、近年、ビデオエンコーディングはPCで最も要求の厳しいタスクの1つになりました。 YouTubeの人気により、何百万人もの人々がカメラマンや監督になりました。 そして、圧縮されたAVC MP4 / H.264へのDVDトランスコーディングを必要とするスマートフォンの至る所にあります。 その結果、ほぼすべてのPCがビデオスタジオになりました。 インターネット上のIPTVおよびビデオストリーミングは広く普及しています。 コンピューターはテレビの役割を果たし始めました。 ビデオはユビキタスになり、PCで最も人気のあるタイプのコンテンツの1つになりました。 デバイスの種類、画面サイズ、インターネット速度に応じて、さまざまなビットレートで、常にどこでもエンコードおよびトランスコードされます。 このような状況では、プロセッサでビデオをすばやくエンコードおよびデコードする能力は自明でした。 そのため、Intel GPU統合ハードウェアエンコーダー/デコーダー。
最新のコーデックは、各フレームを個別に処理しますが、時間の繰り返し(フレーム間)と空間(1フレーム内)のフレームシーケンスを分析します。 これは難しい計算タスクです。 以下は、最新のHEVCコーデックでエンコードされたビデオのフレームの例です。 ウサギの耳の近くの特定の領域について、フレームの異なる部分がどのようにエンコードされたかが示されます。 また、ビデオストリームの全体的な構造におけるフレームの位置とタイプを示します。 ビデオ圧縮アルゴリズムの詳細に入ることなく、これはビデオを効果的にエンコードおよびデコードするためにどれだけの情報を分析する必要があるかの一般的なアイデアを与えます。
Elecard StreamEyeプログラムで開いているビデオのスクリーンショット、 1920×1040
コーディングおよびデコーディングのハードウェアサポートは、コーディングおよびデコーディングの特定のタスクに特化した集積回路がプロセッサに直接実装されることを意味します。 たとえば、エンコード中に離散コサイン変換(DCT)が実行され、デコード中に逆離散コサイン変換が実行されます。
過去5年間で、Intel QSVテクノロジーは大幅に進歩しました。 無料のVP8およびVP9ビデオコーデックのサポート、Linux用の更新されたドライバーなどが追加されました。
現在の第6世代のSkylakeまで、Intel Coreのすべての新世代でテクノロジーが改善されました。
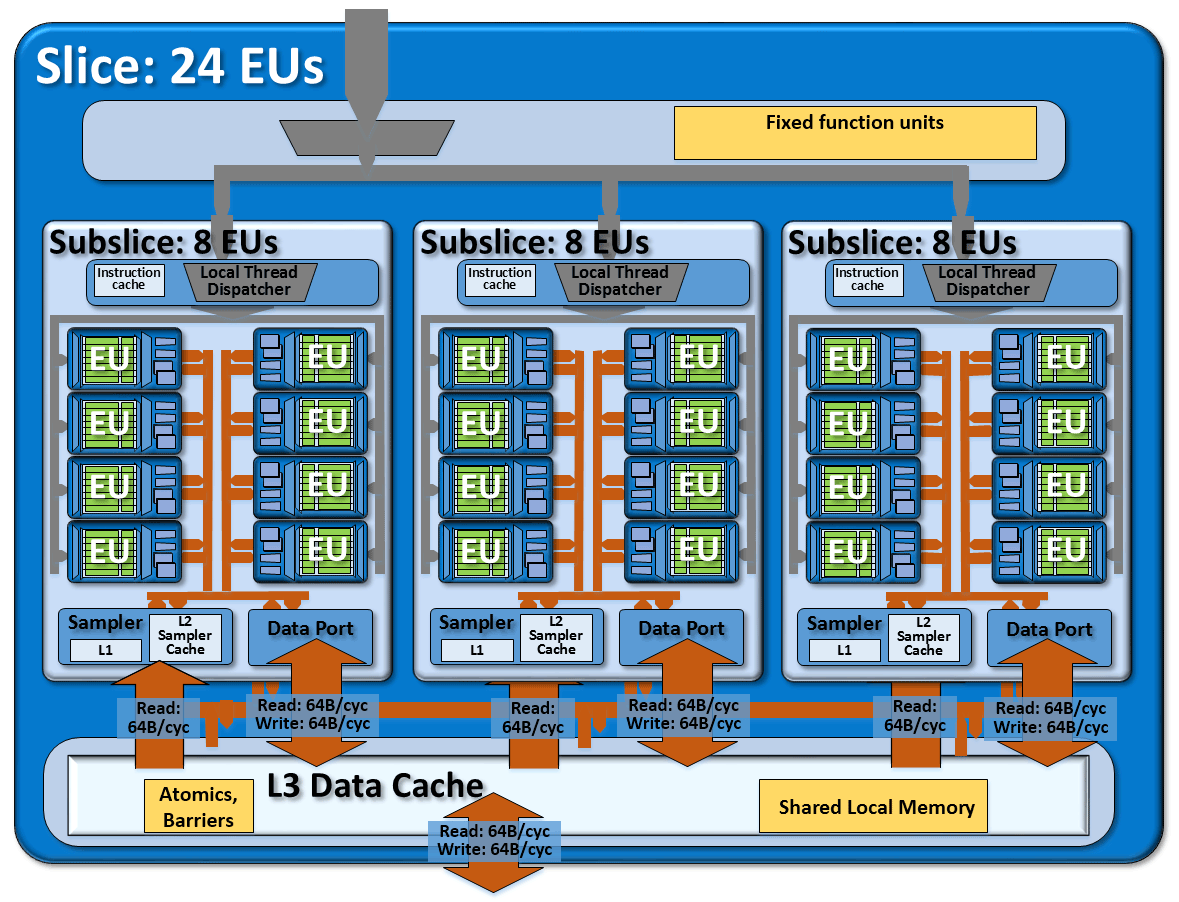
第9世代GPUマイクロアーキテクチャ
QSV 5.0の最新バージョンは、第6世代のSkylakeコアマイクロアーキテクチャとともにリリースされました。 Intelの公式ドキュメントにあるこのバージョンのGPUは、Gen9、つまり第9世代のグラフィックとして分類されています。

Intel Core i7 6700Kデスクトッププロセッサには、4つのCPUコアと第9世代統合グラフィックスHDグラフィックス530が含まれています
GPUの新しいマイクロアーキテクチャごとに、コマンド実行ユニット(EU)の数が増加しました。 Sandy Bridgeの6からSkylakeクリスタルのIris Pro Graphics 580のトップエンドで72に成長しました。 これを含め、GPUのパフォーマンスはクロック周波数を上げることなく10倍に向上しました。 IrisおよびIris Proグラフィックスの最新世代を通して、64または128 MBの組み込みのレベル4キャッシュがあります。
commandコマンド実行ユニットのマイクロアーキテクチャ(EU)
Gen9マイクロアーキテクチャの基本的な構成要素は、コマンド実行ユニット(EU)です。 各EUは、同時マルチスレッド(SMT)と慎重に調整された交互マルチスレッド(IMT)を組み合わせています。 ここでは、単一のコマンドストリーム、複数のデータストリーム(SIMD ALU)を使用する算術論理デバイスが機能します。 高速浮動小数点計算および整数演算のために、多数のスレッドのコンベヤー上に構築されています。
EUでマルチスレッドを交互に行うことの本質は、すぐに実行可能な命令の連続フローを保証することですが、同時に、メモリ、サンプラーリクエスト、または他のシステム通信にベクトルを配置するなど、より複雑な操作を最小限の遅延でキューに入れることです。

コマンド実行ユニット(EU)
Gen9命令ブロックの各スレッドには、128個の汎用レジスタが含まれています。 各レジスタには、8要素のSIMDベクトルまたは32ビットのデータ要素として使用可能な32バイトのメモリがあります。 したがって、すべてのスレッドには、4 KBの汎用レジストリファイル(GRF)があります。 合計で、EUごとに7つのスレッドがあり、EUごとに合計28 KBのGRFがあります。 柔軟なアドレス指定システムにより、複数のレジスタを同時にアドレス指定できます。 スレッドのステータスは現在、個別のレジストリアーキテクチャファイル(ARF)に保存されています。
負荷に応じて、EUのハードウェアスレッドは1つのコンピューティングコアから1つのコードを並列に実行するか、まったく異なるコンピューティングコアからコードを実行できます。 独自の命令ポインタを含む各スレッドの実行ステータスは、独立したARFに保存されます。 各サイクルで、EUは最大4つの異なる命令を発行できます。これらの命令は4つの異なるスレッドから発行する必要があります。 特別なスレッドアービター(スレッドアービター)は、これらの命令を4つの機能ブロックの1つに送信して実行します。 通常、アービターは、異なる命令から選択してすべての機能ブロックを同時にロードし、命令レベルで並列処理を提供できます。
回路内のFPUのペアは、実際には浮動小数点と整数の両方の計算を実行します。 Gen9では、これらのモジュールは、サイクルあたり32ビット数の最大4つの操作だけでなく、16ビットの操作で最大8つの操作を処理できます。 加算と乗算の演算は同時に実行されます。つまり、EUユニットは、1サイクルで32ビット数で最大16演算を実行できます。4演算×2の2 FPU(加算+乗算)。
RenderScript、OpenCL、Microsoft DirectX Compute Shader、OpenGL Compute、C ++ AMPなどのコンパイラーは、EUマルチスレッドダウンロード用のSPMDコードを生成します。 コンパイラ自体は、スレッド読み込みモード(SIMD-width)をヒューリスティックに選択します:SIMD-8、SIMD-16またはSIMD-32。 そのため、SIMD-16の場合、112(16×7)スレッドを1つのEUで同時に実行できます。
EUブロック内の1つの命令内でのデータ交換は、たとえば、96バイトの読み取りと32バイトの書き込みが可能です。 メモリ階層のいくつかのレベルを考慮して、GPU全体にスケーリングする場合、FPUとGRF間の理論上の最大データ交換制限は1秒あたり数テラバイトに達することがわかります。
▍スケーラビリティ
GPUマイクロアーキテクチャは、すべてのレベルでスケーラブルです。 スレッドレベルのスケーラビリティは、コマンド実行ブロックのレベルのスケーラビリティになります。 次に、コマンド実行のこれらのブロックは、8個のグループ(8 EU = 1サブスライス)に結合されます。
各ズームレベルで、ここでのみ機能するローカルモジュールがあります。 たとえば、8つのEUブロックの各グループには、独自のローカルスレッドマネージャー、データポート、およびテクスチャサンプラーがあります。

8 EUブロックのブロック(サブスライス)
同様に、8 EUのグループは、24 EUのグループに統合されます(3サブスライス= 1スライス)。 これら24のブロックスライスは、スケーラブルです。既存のGen9グラフィックには、24、48、または72 EUが含まれています。
Gen9グラフィックスにより、24 EUの各グループでL3 L3キャッシュが768 KBに増加しました。 すべてのサンプラーとデータポートには独自のL3アクセスインターフェイスがあり、サイクルごとに64バイトを読み書きできます。 したがって、24 EUのグループには3つのデータポートがあり、L3キャッシュへのデータ転送帯域はサイクルあたり192バイトです。 キャッシュにオンデマンドのデータがない場合、システムメモリへの書き込みのためにデータが要求または送信されます。これもサイクルごとに64バイトです。

24(3×8)EUの2つのグループからのGen9マイクロアーキテクチャー
このスケーラビリティにより、現在関与していないモジュールを無効にすることで、消費電力を効果的に削減できます。
SkylakeでQSVにできること
Gen9は、H.265 / HEVCエンコードおよびデコードのハードウェアアクセラレーションを完全にサポートし、無料のVP9コーデックでハードウェアエンコードおよびデコードを部分的にサポートします。 QSVテクノロジーの大幅な改善が行われました。 エンコードとデコードの品質と効率、およびハードウェアアクセラレーションを使用するトランスコーディングおよびビデオ編集プログラムのフィルターのパフォーマンスが向上しました。
Skylakeの統合グラフィックスは、DirectX 12機能レベル12_1、OpenGL 4.4、およびOpenCL 2.0標準をサポートしています。 VGAモニターを完全に放棄することが決定されましたが、Skylake GPUは、HDMI 1.4、DisplayPort 1.2またはEmbedded DisplayPort(eDP)1.3インターフェイスを備えた最大3台のモニターをサポートします。
ハードウェアビデオデコードアクセラレーションは、Direct3D Video API(DXVA2)、Direct3d11 Video API、Intel Media SDK、およびMFT(Media Foundation Transform)フィルターを介してグラフィックドライバーで利用できます。
Gen9グラフィックスは、AVC、VC1、MPEG2、HEVC(8ビット)、VP8、VP9、およびJPEGをデコードするためのハードウェアアクセラレーションをサポートしています。
ardハードウェアビデオデコードアクセラレーション
| コーデック
| プロフィール
| レベル
| 最大解像度
|
| MPEG2
| メイン
| メイン
高い | 1080p
|
| VC1 / WMV9
| 高度な
メイン シンプル | L3
高い シンプル | 3840×3840
|
| AVC / H264
| 高い
メイン MVCおよびステレオ | L5.1
| 2160p(4K)
|
| VP8
| 0
| 統一レベル
| 1080p
|
| JPEG / MJPEG
| ベースライン
| 統一レベル
| 16k×16k
|
| HEVC / H265
| メイン
| L5.1
| 2160(4K)
|
| VP9
| 0(4:2:0クロマ8ビット)
| 統一レベル
| ULT、4k 24fps @ 15Mbps
ULX、1080p 30fps @ 10Mbps |
ハードウェアアクセラレーションを使用した推定ビデオデコードパフォーマンスは、16以上の同時1080pビデオストリームです。 実際のパフォーマンスは、GPUモデル、ビットレート、クロック速度によって異なります。 H264 SVCハードウェアデコードは、Skylakeではサポートされていません。
ハードウェアエンコーディングアクセラレーションは、Intel Media SDKインターフェイスおよびMFT(Media Foundation Transform)フィルターを介してのみ使用できます。
ardハードウェアビデオエンコーディングアクセラレーション
| コーデック
| プロフィール
| レベル
| 最大解像度
|
| MPEG2
| メイン
| 高い
| 1080p
|
| AVC / H264
| メイン
高い | L5.1
| 2160p(4K)
|
| VP8
| 統一されたプロファイル
| 統一レベル
| -
|
| Jpeg
| ベースライン
| -
| 16K×16K
|
| HEVC / H265
| メイン
| L5.1
| 2160p(4K)
|
| VP9
| 8ビット4:2:0 BT2020
| -
| -
|
エンコードおよびデコードのハードウェアアクセラレーションに加えて、Gen9グラフィックスは次の機能を含むビデオ処理のハードウェアアクセラレーションも実装します。インターレース解除、ケイデンス検出、ビデオスケーリング(Advanced Video Scaler)、ディテールエンハンスメント、画像安定化、色域圧縮(色域圧縮)、 HDコントラストの適応改善、肌の色調の改善、演色制御、チャネルの色成分のノイズ低減(クロマノイズ除去)、SFC変換(スカラーおよびフォーマット変換)、メモリ圧縮、LACE(ローカライズされた適応コントラスト強調)、スペース 政府のノイズ低減、(AVCデコーダ用の)アウト・オブ・ループデブロッキング、およびその他。
Gen9ハードウェアトランスコーダーは、次の特定のトランスコーディング機能をサポートしています。
- ビデオ会議用のリアルタイム、高速、エネルギー効率の高いAVCエンコーダー
- 消費電力を削減するメディアエンジンのロスレスメモリ圧縮
- ビデオスケーリング(Advanced Video Scaler)
- エネルギー効率の高いSFCコンバーター(スカラーおよびフォーマット変換)
ビデオ分析アプリケーションの観点から、Gen9は多くのフィルターのハードウェアアクセラレーションをサポートしています。これは、顔認識、顔認識、ジェスチャー認識、オブジェクト追跡などのアプリケーションで役立ちます。 (表を参照)。

出典: S-Platformの第6世代Intelプロセッサデータシート
Gen9は、この処理の一部の機能を含む、デジタルカメラ(カメラ処理パイプライン)からのビデオ処理のハードウェアサポートを実装します:ホワイトバランス、カメラセンサーのカラーフィルターの配列からのフルカラー画像の復元(デモザイク)、欠陥ピクセルの補正、黒レベルの補正、ガンマ補正、ケラレの除去、カラースペースコンバーター(フロントエンドカラースペースコンバーター、CSC)、カラーエンハンスメント(イメージエンハンスメントカラープロセッシング、IECP)。
Skylake GPU
- HDグラフィックス510(GT1、12 EU、950 MHz、182.4 GFlops)
- HDグラフィックス515(GT2、24 EU、1000 MHz、384 GFlops)
- HD Graphics 520(GT2、24 EU、1050 MHz、403.2 GFlops)
- HDグラフィックス530(GT2、24 EU、1150 MHz、441.6 GFlops)
- Iris Graphics 540(GT3e、48 EU、64 MB eDRAM、1050 MHz、806.4 GFlops)
- Iris Graphics 550(GT3e、48 EU、64 MB eDRAM、1100 MHz、844.8 GFlops)
- Iris Pro Graphics 580(GT4e、72 EU、128 MB eDRAM、1000 MHz、1152 GFlops)
- HD Graphics P530、サーバー(GT2、24 EU、1150 MHz、441.6 Gflops)
- Iris Pro Graphics P555、サーバー(GT3e、48 EU、128 MB eDRAM、1000 MHz、768 Gflops)
- Iris Pro Graphics P580、サーバー(GT4e、72 EU、128 MB eDRAM、1000 MHz、1152 Gflops)
プログラムがハードウェアアクセラレーションを使用する方法
ハードウェアアクセラレーションを使用するには、各プログラムが特定のGen9機能を明示的にサポートする必要があります。 多くの人がやっています。 IntelはオープンアクセスMedia SDK 2.0を公開しているため、エンコードおよびデコードのハードウェアアクセラレーションのサポートはどのプログラムでも実装できます。 さらに、 Elecard CodecWorks 990など、Intelコーデックでライブビデオをトランスコードするための既製のアプリケーションがあります。 SDKとは異なり、CodecWorks 990は実際のタスクで使用するためにプログラマーの参加を必要としません。既に最も一般的なトランスコーディングプロファイルが含まれているため、プログラマ以外のエンジニアがSDKを使用するよりもはるかに簡単に作業できます。 ハードウェアアクセラレーションを使用したソフトウェアトランスコーダーの仕組みについては、次のパートで説明します。
( 続きます...)