 2008年、pgsql-hackersメーリングリストでクエリ統計の拡張に関する議論が始まりました 。 バージョン8.4以降、 pg_stat_statements拡張はpostgresの一部であり、サーバーが処理するリクエストに関するさまざまな統計を取得できます。
2008年、pgsql-hackersメーリングリストでクエリ統計の拡張に関する議論が始まりました 。 バージョン8.4以降、 pg_stat_statements拡張はpostgresの一部であり、サーバーが処理するリクエストに関するさまざまな統計を取得できます。
通常、この拡張機能は、データベース管理者がレポートのデータソースとして使用します(このデータは、実際にはカウンターがリセットされてからのインジケーターの合計です)。 しかし、これらの統計に基づいて、リクエストを監視できます。時間の経過とともに統計を確認してください。 これは、さまざまな問題の原因を見つけたり、一般的にデータベースサーバーで何が起こっているかを理解するのに非常に役立ちます。
エージェントが収集するリクエストのメトリックス、それらをグループ化する方法、それらを視覚化する方法、および私たちが経験したレーキについても説明します。
pg_stat_statements
したがって、pg_stat_statementsビューで何がありますか(9.4の私の例):
postgres=# \d pg_stat_statements; View "public.pg_stat_statements" Column | Type | Modifiers ---------------------+------------------+----------- userid | oid | dbid | oid | queryid | bigint | query | text | calls | bigint | total_time | double precision | rows | bigint | shared_blks_hit | bigint | shared_blks_read | bigint | shared_blks_dirtied | bigint | shared_blks_written | bigint | local_blks_hit | bigint | local_blks_read | bigint | local_blks_dirtied | bigint | local_blks_written | bigint | temp_blks_read | bigint | temp_blks_written | bigint | blk_read_time | double precision | blk_write_time | double precision |
ここでは、すべてのリクエストがグループ化されています。つまり、各リクエストの統計は取得しませんが、pgの点で同一のリクエストのグループについては取得します(これについて詳しく説明します)。 すべてのカウンターは、開始時またはカウンターのリセット時(pg_stat_statements_reset)から増加します。
- query-クエリテキスト
- 呼び出し -要求呼び出しの数
- total_time-ミリ秒単位のクエリ実行時間の合計
- rows-返された(選択)またはリクエスト中に変更された(更新)行の数
- shared_blks_hit-キャッシュから受信した共有メモリブロックの数
shared_blks_read-キャッシュからではなく読み込まれた共有メモリブロックの数
ドキュメントでは明らかではありません。これは、読み取られたブロックの総数、またはキャッシュで見つからなかったもののみです。コードで確認します
/* * lookup the buffer. IO_IN_PROGRESS is set if the requested block is * not currently in memory. */ bufHdr = BufferAlloc(smgr, relpersistence, forkNum, blockNum, strategy, &found); if (found) pgBufferUsage.shared_blks_hit++; else pgBufferUsage.shared_blks_read++;
- shared_blks_dirtied-リクエスト中に「ダーティ」としてマークされた共有メモリブロックの数(リクエストはブロック内の少なくとも1つのタプルを変更し、このブロックはディスクに書き込まれる必要があります。これはチェックポイントまたはbgwriterによって行われます)
- shared_blks_written-要求処理中にディスクに同期的に書き込まれた共有メモリブロックの数。 Postgresは、ブロックがすでに「ダーティ」を返している場合、同期してブロックを書き込もうとします。
- local_blks-一時テーブルに使用されるバックエンドローカルブロックの同様のカウンター
- temp_blks_read-ディスクから読み取られた一時ファイルブロックの数。
work_memの設定によって制限された十分なメモリがない場合、一時ファイルはリクエストを処理するために使用されます - temp_blks_written-ディスクに書き込まれた一時ファイルブロックの数
- blk_read_time-ブロックの読み取りを待機する時間(ミリ秒)
- blk_write_time-ディスクへのブロックの書き込みを待機する時間(ミリ秒単位)(同期記録のみが考慮され、チェックポイント/ bgwriterで費やされる時間はここでは考慮されません)
blk_read_timeおよびblk_write_timeは、 track_io_timingが有効な場合にのみ収集されます。
それとは別に、完了したリクエストのみがpg_stat_statementsに入ることに注意する価値があります。 つまり、何か重いことをしているのに1時間要求があり、それでもまだ終了していない場合、それはpg_stat_activityでのみ表示されます。
クエリのグループ化方法
長い間、私はリクエストが実際の実行計画に従ってグループ化されていると考えていました。 唯一の恥ずかしさは、INの引数の数が異なるリクエストが個別に表示されることであり、それらのプランは同じでなければなりません。
このコードは、実際には解析後にリクエストの「重要な」部分からハッシュが取得されることを示しています。 9.4以降、 queryid列に表示されます。
実際には、すでにエージェントにあるリクエストをさらに正規化し、グループ化する必要があります。 たとえば、INの異なる数の引数は、1つのプレースホルダー「(?)」にまとめられます。 または、pgをインラインでリクエストに追加した引数は、プレースホルダーに置き換えられます。 タスクは、要求テキストが完全でない可能性があるという事実により複雑になります。
9.4まで、クエリテキストはtrack_activity_query_sizeにトリミングされます.9.4からクエリテキストは共有メモリの外部に格納され、制限が削除されたため、いずれにしても、クエリに非常に重い行が含まれている場合、エージェントからのリクエストが著しくpostgresをロードするため、リクエストを8Kbにトリミングします
このため、追加の正規化のためにSQLパーサーでクエリを解析することはできません;その代わりに、クエリをさらにきれいにするために正規表現のセットを記述する必要がありました。 新しいシナリオを絶えず追加する必要があるため、これはあまり良い解決策ではありませんが、これまでより良いものは発明されていません。
もう1つの問題は、 クエリフィールドでpostgresが元のフォーマットを維持しながら正規化の前にグループ内の最初の着信要求を記録し、カウンターがリセットされると、同じグループの要求が異なる場合があることです。 まだ非常に多くの場合、開発者はクエリでコメントを使用します。たとえば、このクエリを取得する関数の名前やユーザークエリIDを示すために、コメントもqueryに保存されます 。
同じクエリに対して新しいメトリックを毎回生成しないように、コメントと余分な空白文字を切り取ります。
問題の声明
postgresqlコンサルティングの友人の助けを借りてpostgresの監視を行いました 。 彼らは、データベースの問題を見つけるのに最も有用なことを示唆しました。どのメトリックスは特に有用ではなく、postgresqlの内部でアドバイスされました。
その結果、次の質問に対する監視からの回答を受け取りたいと思います。
- 別の期間と比較してデータベースが全体としてどのように機能するか
- どの要求がサーバー(CPU、ディスク)をロードするか
- どんなリクエスト
- 異なるリクエストの実行時間は何ですか
メトリックの収集
実際、すべての監視要求にカウンターを注ぐことは非常に高価です。 TOP-50クエリのみに関心があると判断しましたが、total_timeだけを取得することはできません。新しいクエリがある場合、total_timeは長い間古いクエリに追いつくからです。
1分あたりの派生物(レート)total_timeを優先することにしました。 これを行うために、エージェントは1分間に1回、pg_stat_statements全体を読み取り、以前のカウンター値を保存します。 レートは各リクエストの各カウンタに対して計算され、その後、同じリクエストをさらに組み合わせようとします。これは異なるとみなされ、統計が要約されます。 次に、それらから個別のメトリックを作成し、残りのクエリを特定のクエリ= "〜other"にまとめます。
その結果、各リクエストの上部から11のメトリックを取得します。 各メトリックには、一連の改良パラメーター(ラベル)があります。
{"database": "<db>", "user": "<user>", "query": "<query>"}
- postgresql.query.time.cpu(便宜上、total_timeからディスクレイテンシーを差し引いただけです)
- postgresql.query.time.disk_read
- postgresql.query.time.disk_write
- postgresql.query.calls
- postgresql.query.rows
- postgresql.query.blocks.hit
- postgresql.query.blocks.read
- postgresql.query.blocks.written
- postgresql.query.blocks.dirtied
- postgresql.query.temp_blocks.read
- postgresql.query.temp_blocks.written
指標の解釈
非常に多くの場合、ユーザーはメトリック「postgresql.query.time。*」の物理的な意味について質問します。 実際、応答時間の合計が何を示しているかはあまり明確ではありませんが、このようなメトリックは通常、いくつかのプロセスの相互の比率をよく示しています。
しかし、ロックを考慮しないことに同意する場合、リクエストが処理されている間、postgresは何らかの種類のリソース(プロセッサまたはディスク)を使用すると非常に大雑把に想定できます。 このようなメトリックには、1秒あたりの消費リソース秒数というディメンションがあります。 また、プロセッサコアにクエリを実行することで、100%を掛けると、これをパーセント使用率にすることができます。
何が起こったのか見て
メトリックに依存する前に、それらが真実を示すかどうかを確認する必要があります。 たとえば、データベースサーバーでの書き込み操作の数が増加する原因を把握してみましょう。
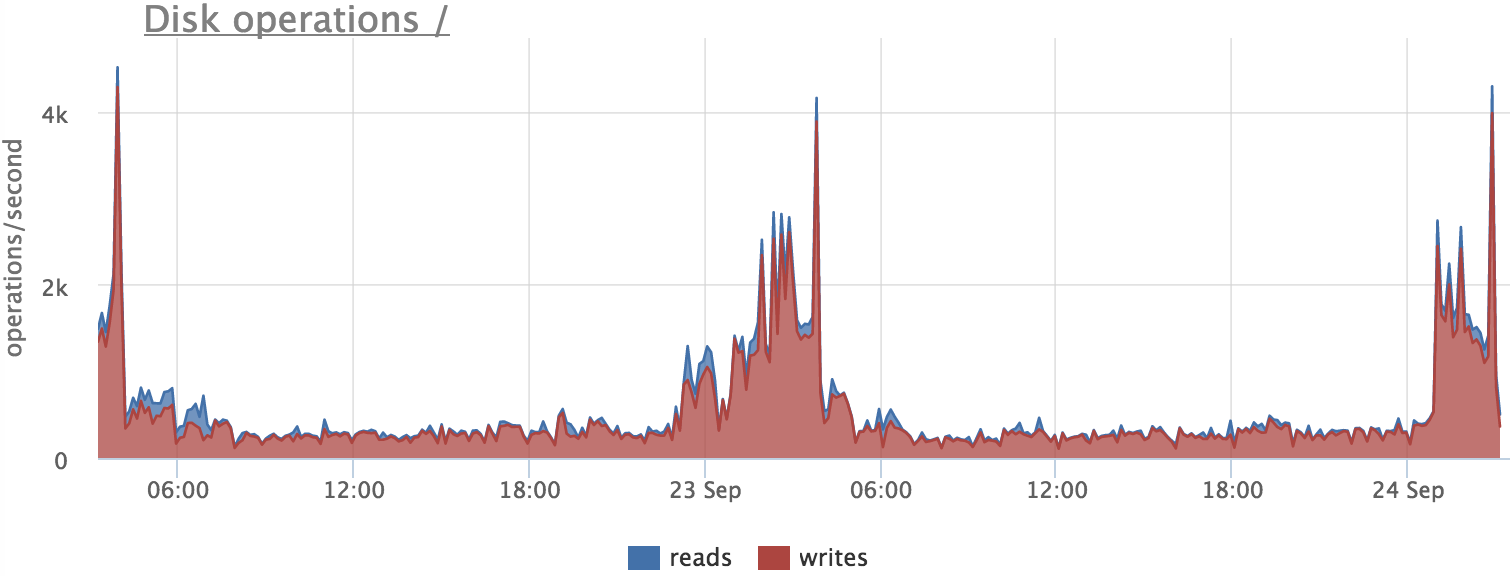
この時点でpostgresがディスクに書き込んだかどうかを確認します。
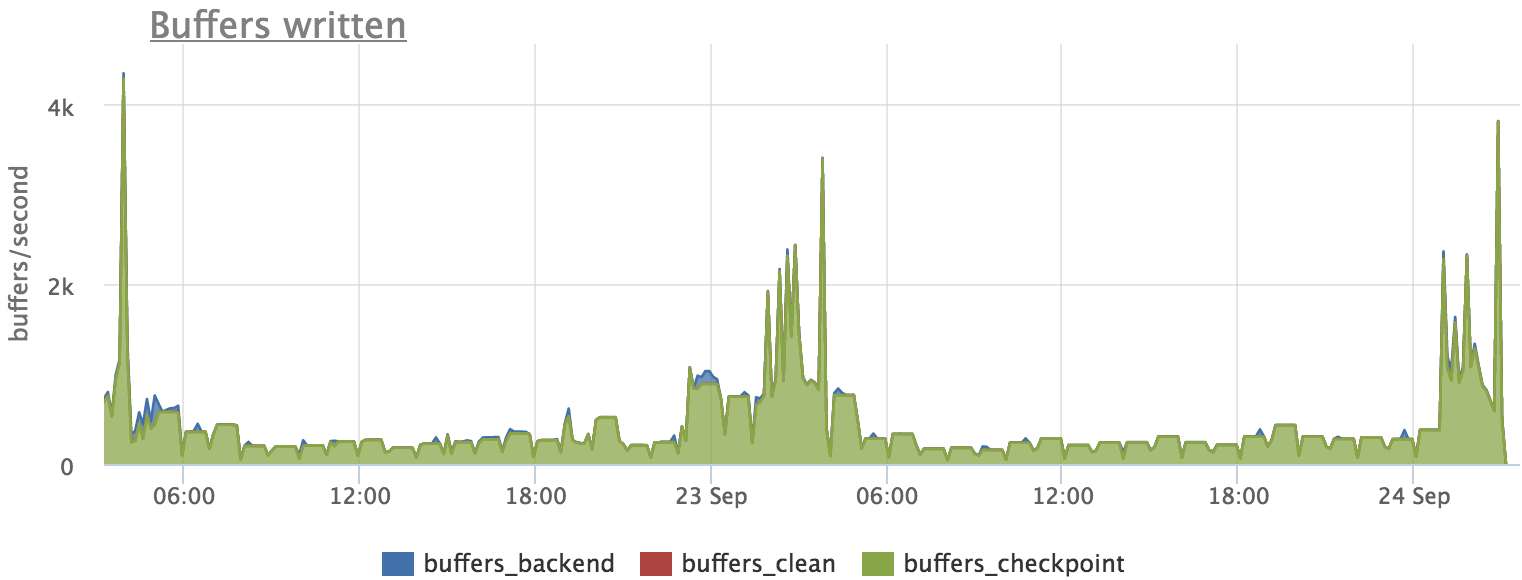
次に、どのクエリがページを「ダーティ」にするかを調べます。
ほぼ一致していることがわかりますが、リクエストのスケジュールは、バッファのフラッシュのスケジュールを正確に繰り返していません。 これは、ブロックの書き込みプロセスがバックグラウンドで発生し、ディスクの負荷のプロファイルがわずかに変化するためです。
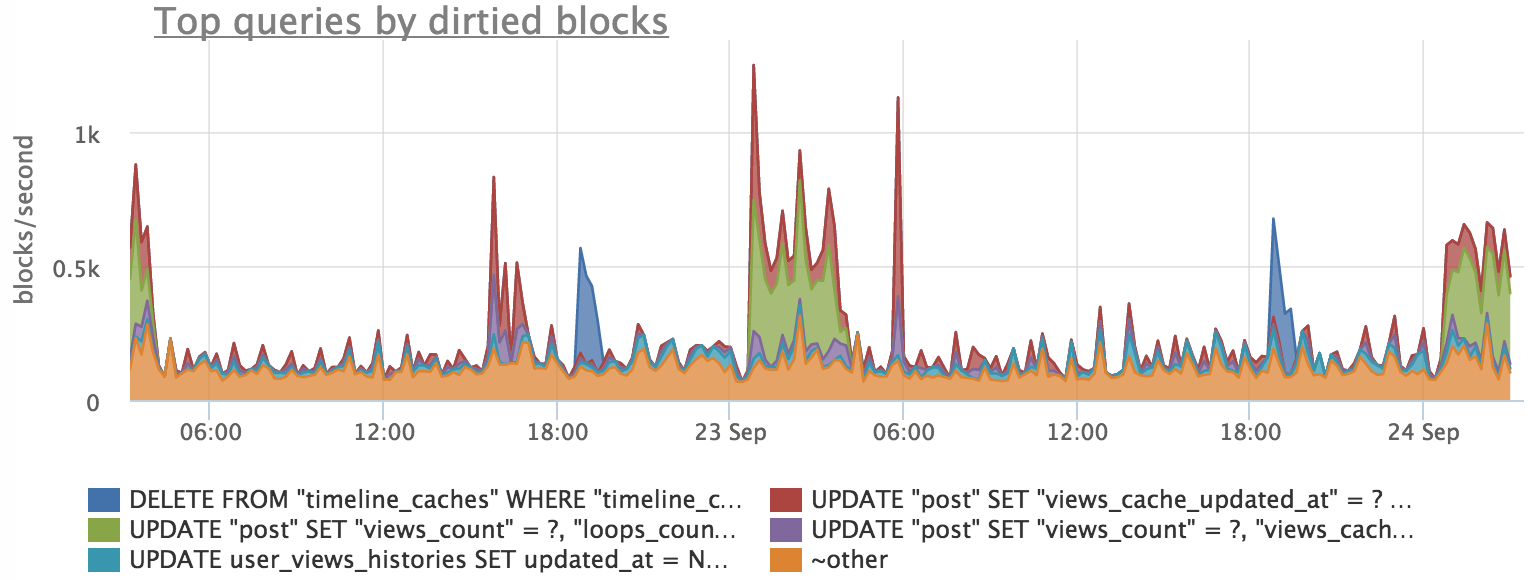
では、読書でどのような写真が得られたかを見てみましょう。
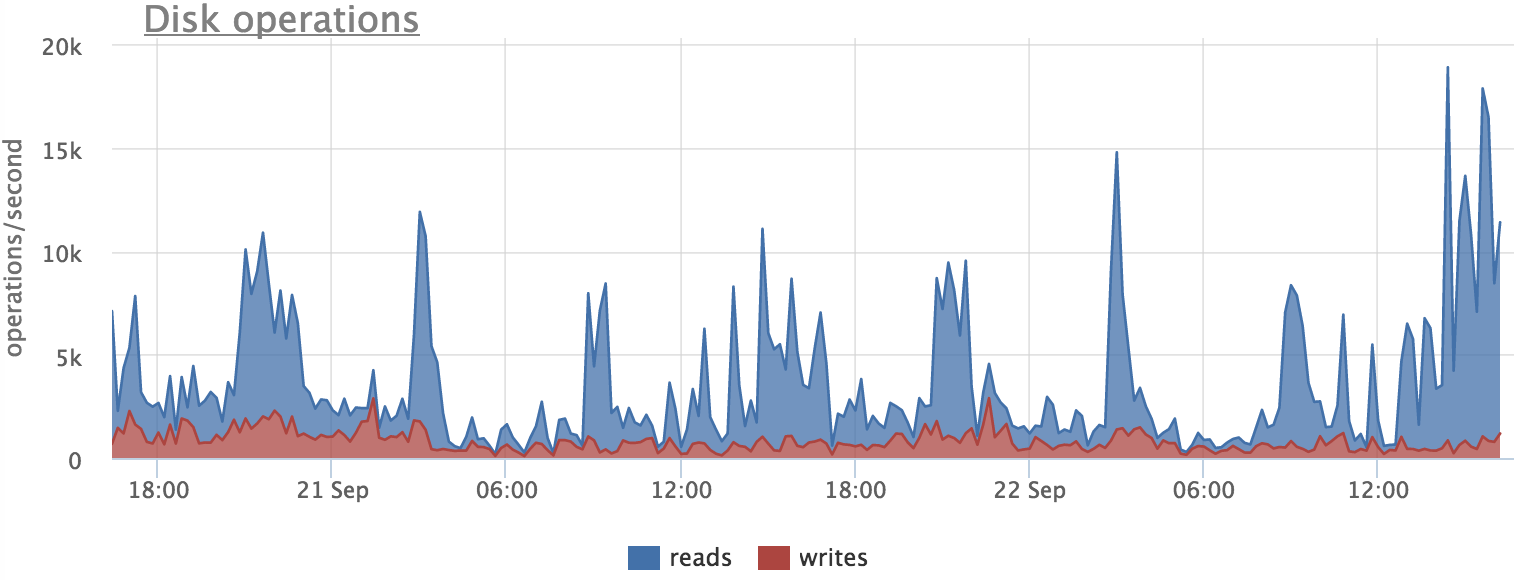
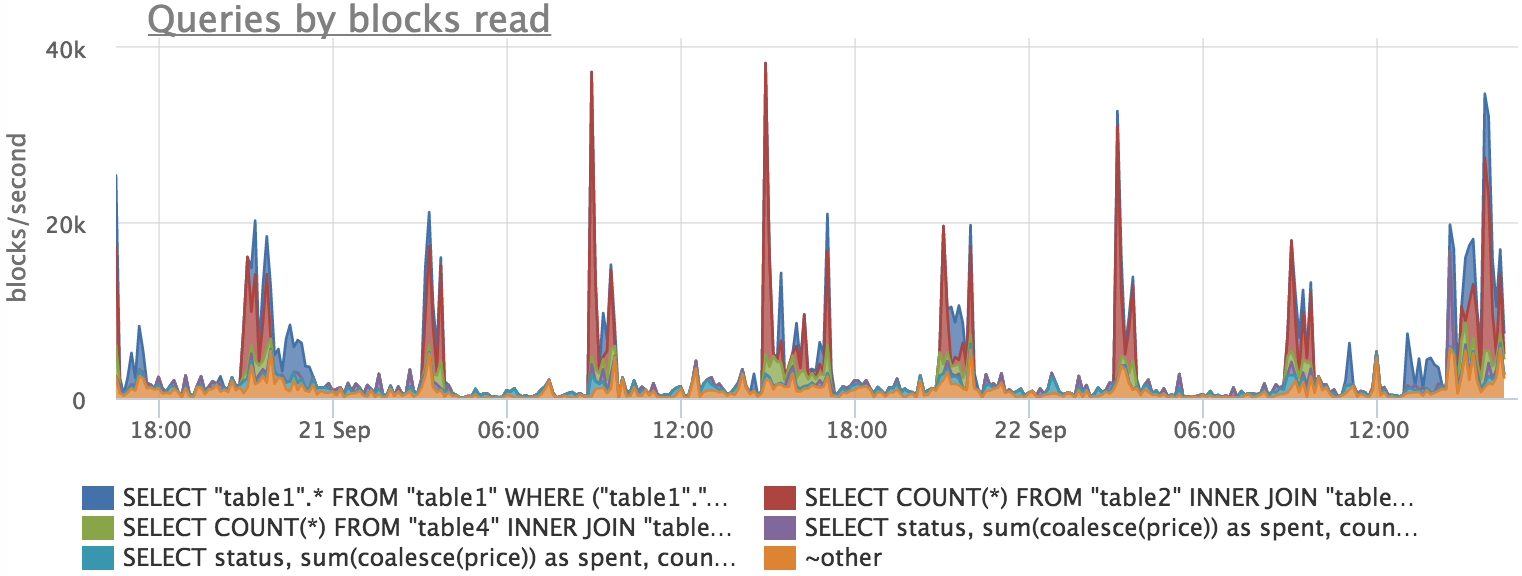
ここでも相関関係があることがわかりますが、完全に一致するものはありません。 これは、postgresがディスクからブロックを直接読み取るのではなく、ファイルシステムキャッシュを介して読み取るという事実によって説明できます。 したがって、ブロックの一部がキャッシュから読み取られるため、ディスクの負荷の一部は表示されません。
CPU使用率は特定の要求によっても説明できますが、さまざまなロックなどが予想されるため、絶対的な精度は期待できません。
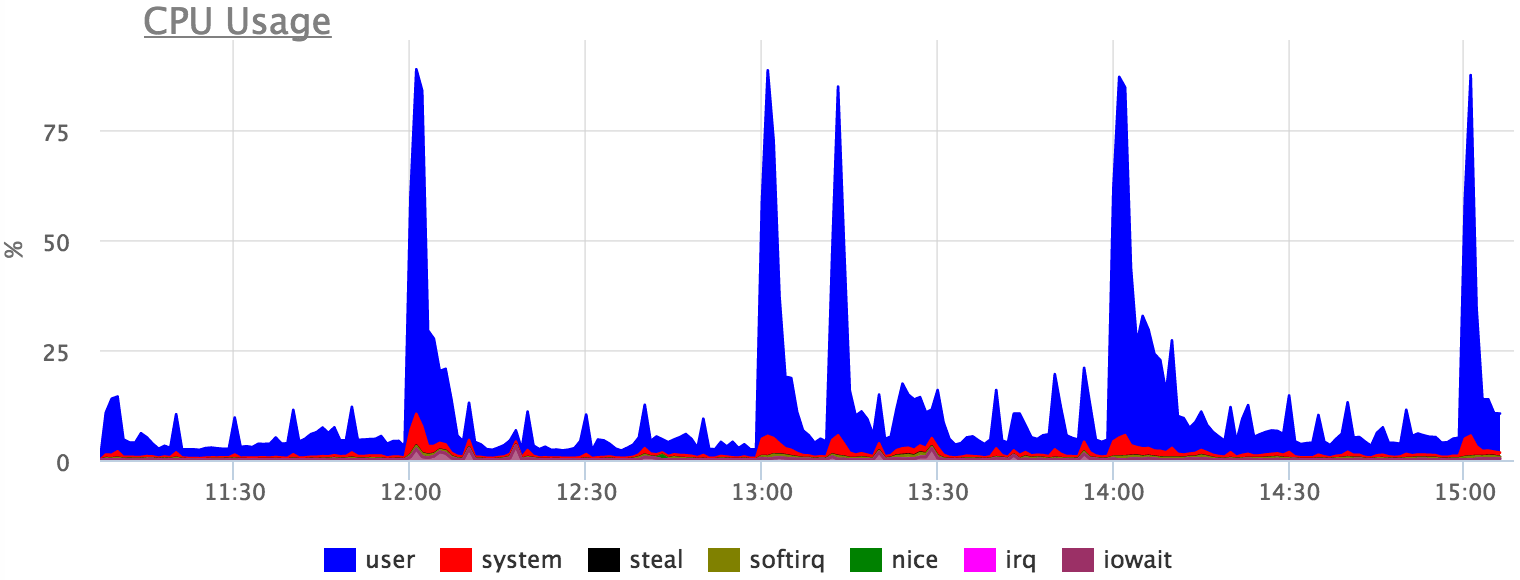
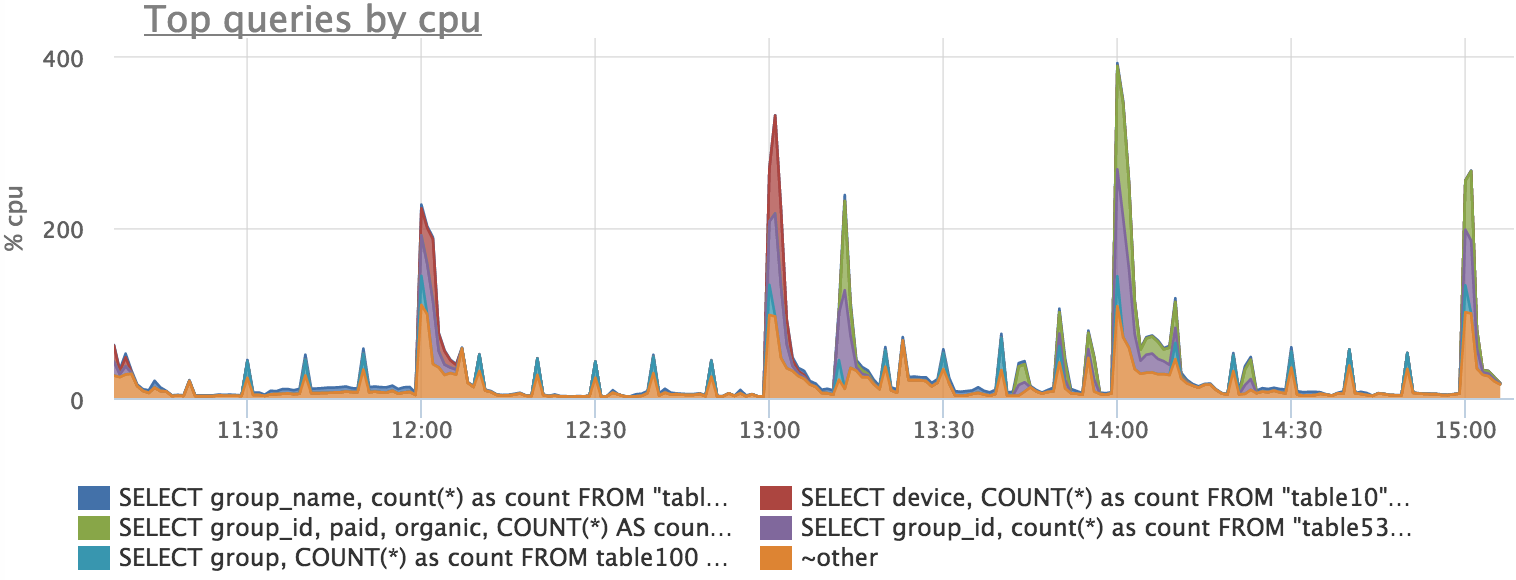
合計
- pg_stat_statementsは、詳細な統計情報を提供する非常にクールなものですが、サーバーを強制終了しません。
- 多数の仮定と不正確さがありますが、それらはメトリックの正しい解釈のために理解される必要があります
デモブースには、オンデマンドのメトリックの例がありますが、負荷はあまり面白くなく、メトリックで確認する方が良いです(無料の、拘束力のない2週間の試用版があります)