「独自の検索があります!」
すべての検索スペシャリストがMail.Ru検索行に設定されたクエリがライセンスされたサードパーティエンジンではなく、会社の内部開発によって処理される可能性が最も高いことを知っていたわけではないため、2年連続で会議ですべてのスピーチをこのフレーズで始めました。
今、状況が変わったことがわかりました。多くの人が検索エンジンを知っており、受け入れています。 しかし、疑問や疑問はまだ残っています。Mail.RuGroupが検索を書き込む方法は? Mail.Ru Groupはメールであり、ソーシャルネットワーク、エンターテイメントです...どのような検索エンジンを作成できますか? したがって、これらの疑問を払拭するために、検索、その方法、使用するテクノロジー、結果として得たいものについてお話したいと思います。 提案された記事が有益で興味深いものになることを願っています。 さらに、私たちの技術についての話をより詳細に続け、次の投稿で機械学習、スパイダー、スパム対策などについて話します。
GoGo.Ru
Mail.Ru検索エンジンは、aport.ru検索エンジンの元ヘッドであるMikhail Kostinによって2004年に開発が開始されました。 2007年、検索エンジンはドメインgogo.ruでGoGoという名前で発表されました。

GoGoには既に非常に興味深いプロパティがありました。検索を商業サイトや情報サイトだけでなく、フォーラムやブログに限定することもできます。 しばらくして、画像検索が登場し、RuNetで最初のビデオ検索が行われました。
検索クエリの実行時間のランキングと最適化に多くの注意が払われました。 たとえば、GoGoテキストランキング式は、ROMIP(情報検索方法の評価に関するロシアのセミナー)コンテストに参加し、すべての参加者の中で最高の結果を示しました( www.romip.ru/romip2005/09_mailru.pdfを参照)。
GoGoからGo.Mail.Ruへ
これまで、Mail.Ruポータルのメインページに入力されたクエリは、ライセンスされた検索エンジンによって実行されていました。 最初はGoogleエンジン、次にYandexでした。 しかし、2009年にYandexとの契約は終了し、2010年1月1日から独自の検索エンジンを試すことが決定されました。
その後、次の条件でGoogle検索エンジンとパートナーシップを結びました:リクエストの一部はGoogleによって処理され、他のリクエストはGoogleによって処理されます。 しかし、これは2010年8月にのみ発生し、8か月間、検索は独自のエンジンで完全に機能しました。
開発者の観点から見ると、これはまったく異なる検索要件を意味します。以前のgogo.ruが1日に数十万件のリクエストを処理した場合、数千万件の処理が必要になりました。 予想される負荷の2桁の増加には、新しいアーキテクチャソリューションが必要でした。 最も重要な変更は、RAMへのリバースインデックスの上昇でした。以前はハードドライブ上に存在していたため、要求ごとに最大300ミリ秒の必要な応答時間を満たすことができませんでした。 そして、すべての変更について、開発チームはわずか数か月しかありませんでした。2010年1月1日、新しい検索エンジンは動作し、Mail.Ruポータルのユーザーのリクエストに応えることになっています。
このタスクは「ミッション不可能」クラスに属しますが、開発者は労力の偉業を完了し、正常に対処しました。新しい検索エンジンへの切り替えは2010年1月1日0:00に発生しました。 検索リポジトリへの最初のコミットは、新たに発見された問題の1つを修正し、大New日の3時から既に発生しています。 そしてその後、国のほとんどがお正月休みでしたが、検索チームは、彼らが言うように、「空を保持」し、常にさまざまなバグを見つけて修正しました。
検索の安定性に関する問題は年間を通じて発生し解決しましたが、最初の3か月が最もストレスが多く、すべての検索エンジン開発者から最大限の利益を必要としました。 同時に、彼らはおそらく2010年8月までにようやく火を消すことができたでしょう。 その後、検索はついに通常の生活を始め、開発者は別の重大な問題を修正するよりも長期のタスクに切り替えることができました。 特に、検索の現在のアーキテクチャが以前のタスクにどの程度対応しているかについて考えることができます。
持っていたもの:2010年の歴史的背景
2010年、検索アーキテクチャに関する内部プレゼンテーションは、ほぼこの方法でそれを概略的に示しました。
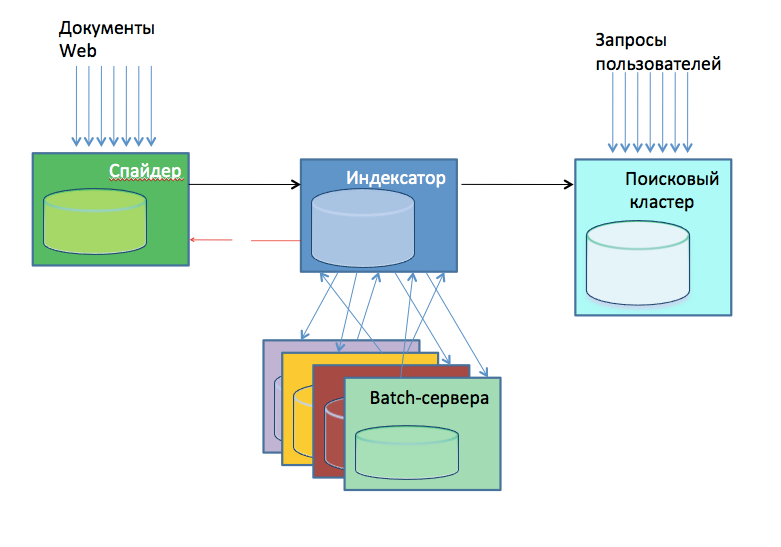
- スパイダー、ウェブをダウンロードします。 これらは、Webの各部分をポンプする24台のサーバーです。 ポンプアウトする部分は、ドメインに代わってハッシュによって決定されました。 クモは自分自身の中にダウンロードしたページのデータベースを含んでおり、彼ら自身がダウンロードするものとしないものを決定しました。
- インデクサー、既製のデータベースインデックスを作成します。 2010年末には約30人もいました。 インデックス自体に加えて、彼らはスパム、ポルノなどの受信ページの分析を実行し、計算のための関心のあるデータ、例えば、引用インデックスのその後の構築のためのリンクを強調しました。
- 同じICの外部データの計算を実行するバッチサーバー(約20個)。 計算は非常に多様で、一部は高速で、一部は低速でした。
- 検索クラスター、150台のサーバー。 インデクサーからデータベースを取得し、ユーザー検索を直接実行しました。
2010年に、データストレージと処理の組織にかなりの数のアーキテクチャ上の欠陥があることが明らかになりました。検索は「数ダースのサーバー」から「数百サーバー」の状態に急速に発展し、処理されたデータの数と処理速度の要件が増加し始め、古いものが増加し始め、これらのメソッドは、品質の高い作業の当面の要件を満たしていません。 たとえば、引用インデックスは1つのサーバーで計算され、1か月間機能しました。 この間にサーバーが再起動した場合、またはプロセスでメモリが不足した場合は、最初からやり直す必要がありました。 したがって、ある時点での引用インデックスは更新を停止しました。
インデックスに配置される初期データの多くは、異なるサーバーで、異なるユーザーの下で計算され、このタイプのデータに対していくつかのユニークな方法を使用してインデックスに配信されました。 その結果、開発者はそれがどこから来たのかについて混乱していました。数ヶ月前に、何らかの理由で特定の要因が1か月前にインデックスを「落とす」ことがわかりました。
多くの場合、開発者は同じタスクを解決しました。複数のディスク、さらに複数のサーバーにまたがって計算を並列化できるように入力データを「ソースルー」する方法です。 すべてのソリューションは多少似ていましたが、互いに多少異なり、さらに開発者はしばしば分散コンピューティングシステムをゼロから構築するために同じ厄介な方法を繰り返しましたが、これは明らかに効果的な開発に貢献しませんでした。
大きな問題は、2つのドキュメントベースの存在でした。1つはスパイダー用、もう1つはインデクサー用です。 これにより、同じドキュメントの運命に関する決定があいまいになりました。たとえば、インデクサーでのスパムの分析により、ドキュメントをインデックスから除外し、スパイダーがそれをダウンロードし続けることができます。 または、逆に、スパイダーは何らかの理由でドキュメントをデータベースから破棄することもできますが、技術的な誤動作のため、インデックスからドキュメントを削除するコマンドがインデクサーに到達できなかったため、ドキュメントは次のガベージクリーニングまで長時間インデックスに残りました。
検索の開発を続けるためには、別の新しいアプローチが必要であることが明らかになりました。分散タスクを実行するための単一のプラットフォーム、つまり高性能データベースが不足していました。 独立した開発と既製のソリューションのどちらかを選択する必要があり、2番目のケースでは、安定性の点で私たちに合ったオプションを見つけ、負荷を迅速に処理する必要がありました。
次の投稿では、このアプローチをどのように開発して実装したか、および他の検索エンジンがどのように機能するかについて説明します。
アンドレイ・カリーニン、
検索Mail.ruのヘッド