For questions in the style of "why?" There is an older article - Natural Geektimes - making space cleaner .
There are many articles, for subjective reasons, some do not like, and some, on the contrary, are a pity to miss. I want to optimize this process and save time.
The above article suggested an approach with scripts in the browser, but I didn’t really like it (even though I used it before) for the following reasons:
- For different browsers on your computer / phone, you have to configure it again, if at all possible.
- Hard filtering by authors is not always convenient.
- The problem with authors whose articles do not want to be missed, even if they are published once a year, is not resolved.
Filtering by article rating built into the site is not always convenient, since highly specialized articles, for all their value, can receive a rather modest rating.
Initially, I wanted to generate rss feed (or even some), leaving only the interesting stuff there. But in the end it turned out that reading rss seemed not very convenient: in any case, to comment / vote on an article / add it to favorites, you have to go through the browser. Therefore, I wrote a bot for a telegram that throws interesting articles to me in PM. Telegram itself makes them beautiful previews, which in combination with information about the author / rating / views looks pretty informative.
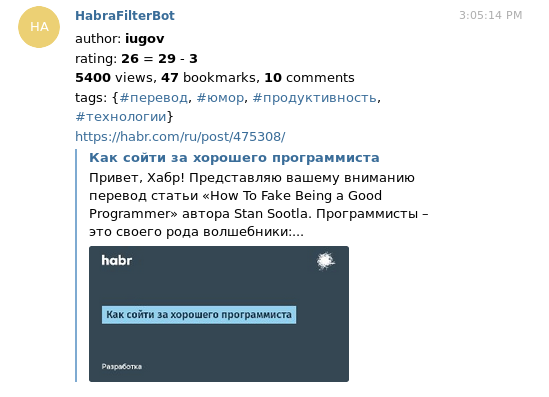
Under the cut, details such as work features, writing process and technical solutions.
Briefly about the bot
Repository: https://github.com/Kright/habrahabr_reader
Telegram bot: https://t.me/HabraFilterBot
The user sets an additional rating for tags and authors. After that, a filter is applied to the articles - the article’s rating on Habré, the author’s user rating and the average for user ratings by tags are added. If the amount is greater than the user-defined threshold value, then the article passes the filter.
A side goal of writing a bot was to get fun and experience. In addition, I regularly reminded myself that I was not Google , and therefore many things were done as simple and even primitive as possible. However, this did not prevent the process of writing a bot from stretching for three months.
Outside the window was summer
July ended, and I decided to write a bot. And not alone, but with a friend who mastered scala and wanted to write something on it. The beginning looked promising - the code will be sawn "team", the task seemed easy and I thought that in a couple of weeks or a month the bot will be ready.
Despite the fact that I myself have been writing code on the rock for the past few years, usually no one sees or looks at this code: pet projects, checking some ideas, preprocessing data, mastering some concepts from the FP. I was really interested in how code writing in a team looks like, because code on a rock can be written in very different ways.
What could have gone so ? However, we will not rush things.
Everything that happens can be tracked by the history of commits.
A friend created the repository on July 27, but did nothing else, so I started writing code.
July 30th
Briefly: I wrote parsing rss feeds of Habr.
-
com.github.pureconfig
for reading typesafe config files directly in case classes (it turned out to be very convenient) -
scala-xml
for reading xml: since I originally wanted to write my implementation for rss tape and rss tape in xml format, I used this library for parsing. Actually, parsing rss also appeared. -
scalatest
for tests. Even for tiny projects, writing tests saves time - for example, when debugging parsing xml it is much easier to download it to a file, write tests and fix errors. When in the future a bug appeared with parsing of some strange html with invalid utf-8 characters, it turned out to be again more convenient to put it in a file and add a test. - actors from Akka. Objectively, they were not needed at all, but the project was written for fun, I wanted to try them. As a result, I’m ready to say what I liked. One can look at the idea of OOP from the other side - there are actors who exchange messages. What is more interesting - it is possible (and necessary) to write code in such a way that the message may not reach or cannot be processed (generally speaking, when an account is running on a single computer, messages should not be lost). At first I was racking my brains and there was a trash in the code with actors subscribing to each other, but in the end I managed to come up with a rather simple and elegant architecture. The code inside each actor can be considered single-threaded, when the actor crashes, the Akka restarts it - a rather fault-tolerant system is obtained.
August 9th
I added the scala-scrapper
project for parsing html pages from the Habr (to pull out information such as article rating, number of bookmarks, etc.).
And Cats. The ones that are in the rock.
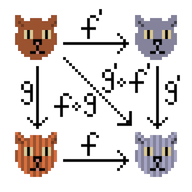
I then read one book about distributed databases, I liked the idea of CRDT (Conflict-free replicated data type, https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type , habr ), so I filmed the type class of the commutative semigroup for information about the article on Habr.
In fact, the idea is very simple - we have counters that change monotonously. The number of promoters is growing smoothly, the number of pluses too (however, as well as the number of minuses). If I have two versions of information about an article, then you can "merge them into one" - consider the state of the counter, which is greater, to be more urgent.
A semigroup means that two objects with information about an article can be merged into one. Commutative means that you can merge both A + B and B + A, the result does not depend on the order, as a result, the newest version remains. By the way, associativity is also here.
For example, by design, rss after parsing gave slightly dampened information about the article - without metrics such as the number of views. A special actor then took information about the articles and ran to the html pages in order to update it and merge it with the old version.
Generally speaking, like akka, there was no need for this, it was possible just to store updateDate for the article and take a newer one without any mergers, but the road of adventure led me.
12th of August
I began to feel freer and, for the sake of interest, made each chat a separate actor. Theoretically, an actor by itself weighs about 300 bytes and can be created at least by millions, so this is a completely normal approach. It turned out, it seems to me, a rather interesting solution:
One actor was the bridge between the telegram server and the message system in Akka. He simply received messages and sent them to the desired chat actor. The actor-chat in response could send something back - and it was sent back to telegrams. What was very convenient - this actor turned out to be as simple as possible and contained only the logic of the response to messages. By the way, information about new articles came to every chat, but again, I do not see any problems in this.
In general, the bot already worked, responded to messages, stored a list of articles sent to the user, and I already thought that the bot was almost ready. I slowly finished up small chips like normalizing the names of authors and tags (replacing "sd f" with "s_d_f").
There was only one small but - the state did not persist anywhere.
Everything went wrong
You may have noticed that I wrote the bot mostly alone. So, the second participant joined in the development, and the following changes appeared in the code:
- To store the state appeared mongoDB. At the same time, the logs broke in the project, because for some reason the monga began to spam in them and some simply turned them off globally.
- The actor-bridge in telegram was transformed beyond recognition and began to parse messages itself.
- Actors for chats were mercilessly drunk, instead of them appeared an actor who hid in himself all the information about all chats at once. For every sneeze this actor climbed into mongu. Well, yes, it’s hard to send it to all chat actors when updating information about an article (as Google, millions of users are waiting for a million articles in a chat for everyone), but it’s normal to go into monga every time you update a chat. As I understood it very much later, the working logic of the chats was also completely cut out and inoperative something appeared.
- There is no trace left of the classes.
- An unhealthy logic appeared in the actors with their subscriptions to each other, leading to a race condition.
- Data structures with fields of type
Option[Int]
turned into Int with magic default values of type -1. Later I realized that mongoDB stores json and there is nothing wrong with storingOption
there, or at least parse -1 like None, but at that moment I did not know this and believed the word that "it is necessary." That code was not written by me, and I did not bother to change it for the time being. - I found out that my public IP address has the property of changing, and every time I had to add it to the whitelist mongue. I started the bot locally, the monga was somewhere on the monga servers as a company.
- Suddenly, the normalization of tags and the formatting of messages for a telegram disappeared. (Hmm, why would it?)
- I liked that the state of the bot is stored in an external database, and when it restarts, it continues to work as if nothing had happened. However, this was the only plus.
The second person was not in a hurry, and all these changes appeared in one big heap already in early September. I did not immediately appreciate the scale of the damage and began to understand the work of the database, because had never dealt with them before. Only then I realized how much working code was cut and how many bugs were added in return.
September
At first, I thought it would be useful to master Mongu and do everything well. Then I slowly began to understand that organizing communication with the database is also an art in which you can make races and just mistakes. For example, if two messages of the type /subscribe
arrive from the user, and in response to each, we will create an entry in the label, because at the time of processing those messages, the user is not signed. I had a suspicion that communication with the monga in its present form was not written in the best way. For example, user settings were created at the moment when he signed up. If he tried to change them before the fact of subscription ... the bot did not answer, because the code in the actor climbed into the database for the settings, could not find and crashed. To the question - why not create settings as needed, I found out that there is nothing to change them if the user has not subscribed ... The message filtering system was somehow not obvious, and even after a close look into the code I couldn’t understand if it was originally conceived or there is a mistake.
There was no list of articles sent to chat; instead, it was suggested that I write them myself. This surprised me - in general, I was not opposed to dragging all sorts of pieces into the project, but it would be logical to pull these pieces in and screw them on. But no, the second participant seems to have forgotten everything, but said that the list inside the chat is supposedly a bad decision, and you need to make a plate with events like "article x was sent to user x". Then, if the user requested to send new articles, it was necessary to send a request to the database, which of the events would select events related to the user, still get a list of new articles, filter them, send to the user and throw events about it back to the database.
The second participant somewhere suffered in the direction of abstractions, when the bot will not only receive articles from Habr and send not only to telegrams.
I somehow implemented the events in the form of a separate tablet by the second half of September. Not optimal, but the bot at least worked and started sending me articles again, and I slowly figured out what was happening in the code.
Now you can go back first and remember that the repository was not originally created by me. What could have gone so? My pool request was rejected. It turned out that I had a shortcode, that I did not know how to work in a team and I had to edit bugs in the current implementation curve, and not modify it to a usable state.
I was upset, looked at the history of commits, the amount of code written. I looked at the moments that were originally written well, and then broken back ...
F * rk it
I remembered the article You Are Not Google .
I thought that nobody really needs an idea without implementation. I thought that I want to have a working bot that will work in a single copy on a single computer as a simple java program. I know that my bot will work for months without restarts, since in the past I wrote such bots. If he suddenly falls and does not send the user another article, the sky will not fall on the earth and nothing catastrophic will happen.
Why do I need a docker, mongoDB and other cargo-cult of "serious" software, if the code does not work stupidly or works crookedly?
I forked the project and did everything as I wanted.
Around the same time, I changed my job and free time was sorely lacking. In the morning I woke up exactly on the train, returned late in the evening and did not want to do anything anymore. I didn’t do anything for a while, then I overwhelmed the desire to finish the bot, and I began to slowly rewrite the code while driving to work in the morning. I will not say that it was productive: sitting in a shaking train with a laptop on your lap and peeking at stack overflow from the phone is not very convenient. However, the time behind writing the code flew completely unnoticed, and the project began to slowly move to a working state.
Somewhere deep down there was a worm of doubt that mongoDB wanted to use, but I thought that, in addition to the pluses with "reliable" state storage, there are noticeable disadvantages:
- The database becomes another point of failure.
- The code is getting harder, and I will write it longer.
- The code becomes slow and inefficient, instead of changing the object in memory, the changes are sent to the database and, if necessary, pulled back.
- There are restrictions on the type of storage of events in a separate plate, which are associated with the features of the database.
- There are some restrictions in the trial version of monga, and if you run into them, you will have to start and configure the monga for something.
I drank Mongu, now the state of the bot is simply stored in the program memory and from time to time it is saved in a file in the form of json. Perhaps in the comments they’ll write that I’m wrong, because this is where you should use it, etc. But this is my project, the approach with the file is as simple as possible and it works in a transparent way.
I threw out magic values like -1 and returned normal Option
, added storage of a hash-plate with the sent articles back to the object with chat information. Added deletion of information about articles older than five days, so as not to store everything in a row. He brought logging to working state - logs in reasonable quantities are written both to the file and to the console. Added several admin commands such as saving state or receiving statistics such as the number of users and articles.
I fixed a bunch of little things: for example, articles now show the number of views, likes, dislikes and comments at the time the user filter was passed. In general, it is amazing how many little things had to be fixed. I kept a list, noted all the “roughnesses” there and corrected them as far as possible.
For example, I added the ability to set all the settings directly in one message:
/subscribe /rating +20 /author a -30 /author s -20 /author p +9000 /tag scala 20 /tag akka 50
And the /settings
command displays them in this form, you can take text from it and send all the settings to a friend.
It seems to be a trifle, but there are dozens of similar nuances.
Implemented filtering of articles in the form of a simple linear model - the user can specify an additional rating for authors and tags, as well as a threshold value. If the sum of the author’s rating, the average rating for tags and the actual rating of the article is greater than the threshold value, then the article is shown to the user. You can either ask the bot for articles with the / new command, or subscribe to the bot and it will throw articles in PM at any time of the day.
Generally speaking, I had an idea for each article to draw out more signs (hubs, number of comments, bookmarks, dynamics of rating changes, the number of text, pictures and code in the article, keywords), and the user to show the vote ok / not ok under each article and for each user to train the model, but I became too lazy.
In addition, the logic of work will not be so obvious. Now I can manually put a rating of +9000 for patientZero and with a threshold rating of +20 I will be guaranteed to receive all his articles (unless, of course, I put -100500 for any tags).
The resulting architecture was quite simple:
- An actor who stores the state of all chats and articles. It loads its state from a file on disk and from time to time saves it back, each time to a new file.
- An actor who occasionally runs into the rss feed learns about new articles, looks at the links, parses, and sends these articles to the first actor. In addition, he sometimes asks the first actor for a list of articles, selects those of them that are not older than three days, but have not been updated for a long time, and updates them.
- An actor who communicates with a telegram. I still took the parsing of messages completely here. In a good way, I want to divide it into two - so that one parses incoming messages, and the second deals with transport problems such as forwarding unsent messages. Now there is no re-sending, and the message that did not reach due to an error will simply be lost (except that it will be marked in the logs), but so far this does not cause problems. Perhaps problems will arise if a bunch of people subscribe to the bot and I reach the limit for sending messages).
What I liked - thanks to akka, the fall of actors 2 and 3 in general does not affect the bot's performance. Perhaps some articles do not update on time or some messages do not reach the telegram, but Akka restarts the actor and everything continues to work further. I store information that the article is shown to the user only when the telegram actor replies that he successfully delivered the message. The worst thing that threatens me is to send a message several times (if it is delivered, but the confirmation is lost in some unknown way). In principle, if the first actor did not keep the state in himself, but communicated with some kind of database, then he could also quietly fall and return to life. I could also try akka persistance to restore the state of actors, but the current implementation suits me with its simplicity. Not that my code crashes often - on the contrary, I put a lot of effort into making it impossible. But shit happens, and the ability to split the program into isolated pieces-actors seemed really convenient and practical to me.
Added circle-ci in order to immediately know about it when the code breaks. At least that the code has ceased to compile. Initially, I wanted to add travis, but it showed only my projects without forked ones. In general, both of these things can be freely used on open repositories.
Summary
It's November already. The bot is written, I used it for the last two weeks and I liked it. If you have ideas for improvement - write. I don’t see the point of monetizing it - let it just work and send interesting articles.
Link to the bot: https://t.me/HabraFilterBot
Github: https://github.com/Kright/habrahabr_reader
Small conclusions:
- Even a small project can take a long time.
- You are not Google. It makes no sense to shoot a sparrow from a cannon. A simple solution can work just as well.
- Pet projects are very well suited for experimenting with new technologies.
- Telegram bots are written quite simply. If not for “teamwork” and experiments with technologies, the bot would have been written in a week or two.
- The actor model is an interesting thing that goes well with multi-threading and code resiliency.
- I seem to feel for myself why the open source community loves forks.
- Databases are good in that the state of the application no longer depends on the crashes / restarts of the application, but working with the database complicates the code and imposes restrictions on the data structure.