Let's take a closer look at the topic of protocol-oriented programming. For convenience, the material was divided into three parts.
This material is a commentary translation of the presentation of WWDC 2016 . Contrary to the common belief that things "under the hood" should remain there, sometimes it is extremely useful to figure out what is happening there. This will help to use the item correctly and for its intended purpose.
This part will address key issues in object-oriented programming and how POP solves them. Everything will be considered in the realities of the Swift language, the details will be considered "engine compartment" of the protocols.
OOP problems and why do we need POP
It is known that in OOP there are a number of weaknesses that can “overload” program execution. Consider the most explicit and common:
- Allocation: Stack or Heap?
- Reference counting: more or less?
- Method dispatch: static or dynamic?
1.1 Allocation - Stack
Stack is a fairly simple and primitive data structure. We can put stack (push) on the top, we can take (pop) from the top of stack. Simplicity is that this is all we can do with it.
For simplicity, let us assume that each stack has a variable (stack pointer). It is used to track the top of the stack and stores an integer (Integer). From this it follows that the speed of operations with the stack is equal to the speed of rewriting Integer into this variable.
Push - put on the top of the stack, increase the stack pointer;
pop - reduce stack pointer.
Value types
Let's consider the principles of stack operation in Swift, using structures (struct).
In Swift, value types are structures (struct) and enumerations (enum), and reference types are classes (class) and functions / closures (func). Value types are stored on Stack, reference types are stored on Heap.
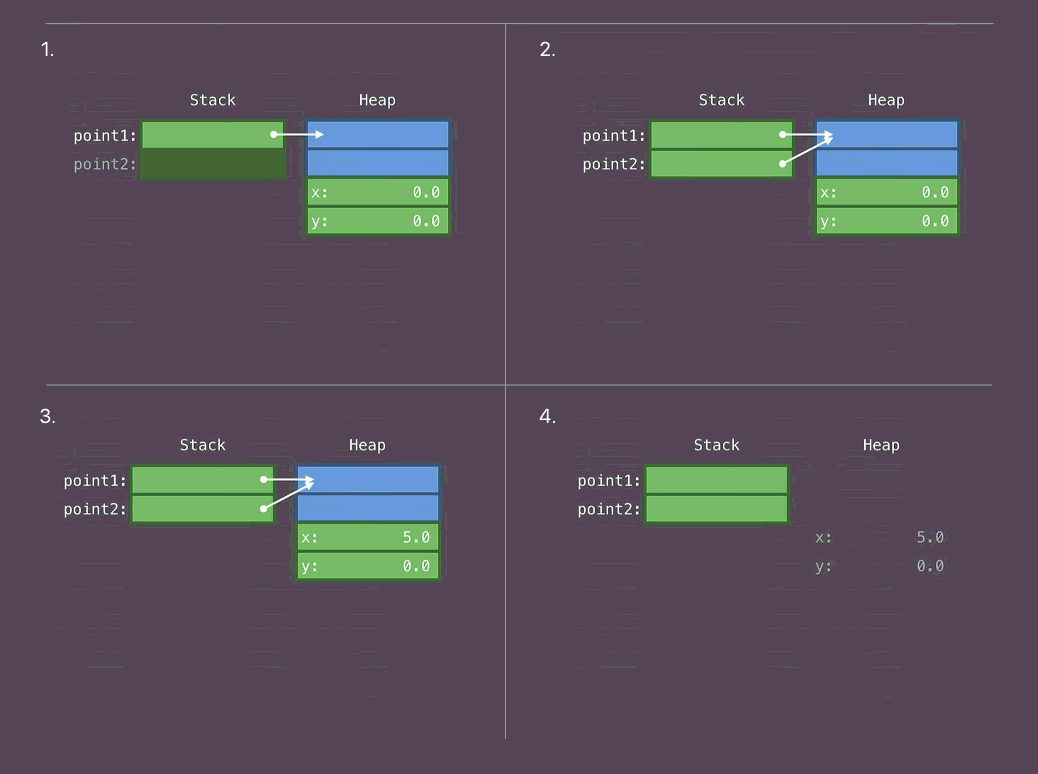
struct Point { var x, y: Double func draw() {...} } let point1 = Point(...) // (1) let point2 = point1 // (2) point2.x = 5 // (3) // point1 // point2 // (4)

- We place the first structure on Stack
- Copy the contents of the first structure
- We change the memory of the second structure (the first remains intact)
- End of use. Free memory
1.2 Allocation - Heap
Heap is a tree-like data structure. The heap implementation topic will not be affected here, but we will try to compare it with the stack.
Why, if possible, is it worth using Stack instead of Heap? That's why:
- reference counting
- free memory administration and its search for allocation
- rewriting memory for deallocation
All of this is just a small part of what makes Heap work and clearly weighs it down compared to Stack.
For example, when we need free memory on Stack, we just take the value of stack-pointer and increase it (because everything above the stack-pointer in Stack is free memory) - O (1) is an operation that is constant over time.
When we need free memory on Heap, we begin to search for it using the appropriate search algorithm in the data tree structure - in the best case, we have an O (logn) operation, which is not constant in time and depends on specific implementations.
In fact, Heap is much more complicated: its work is provided by a host of other mechanisms that live in the bowels of operating systems.
It is also worth noting that the use of Heap in multi-threading mode worsens the situation at times, since it is necessary to ensure the synchronization of the shared resource (memory) for different threads. This is achieved by using locks (semaphores, spinlocks, etc.).
Reference types
Let's look at how Heap works in Swift using classes.
class Point { var x, y: Double func draw() {...} } let point1 = Point(...) // (1) let point2 = point1 // (2) point2.x = 5 // (3) // point1 // point2 // (4)
1. Place the class body on Heap. Place the pointer to this body on the stack.
- Copy the pointer that refers to the body of the class
- We change a body of a class
- End of use. Free memory
1.3 Allocation - A Small and "Real" Example
In some situations, choosing Stack not only simplifies memory handling, but also improves the quality of the code. Consider an example:
enum Color { case red, green, blue } enum Orientation { case left, right } enum Tail { case none, tail, bubble } var cache: [String: UIImage] = [] func makeBalloon(_ color: Color, _ orientation: Orientation, _ tail: Tail) -> UIImage { let key = "\(color):\(orientation):\(tail)" if let image = cache[key] { return image } ... }
If the cache dictionary has a value with the key key, then the function will simply return the cached UIImage.
The problems of this code are:
Not a good practice is to use String as a key in cached, because String in the end "can turn out to be anything."
String is a copy-on-write structure; to implement its dynamism, it stores all its Character-s on Heap. Thus, String is a structure, and is stored in Stack, but it stores all its contents on Heap.
This is necessary in order to provide the ability to change the line (remove part of the line, add a new line to this line). If all characters of the string were stored on Stack, then such manipulations would be impossible. For example, in C, strings are static, which means that the size of the string cannot be increased in runtime since all content is stored on Stack. For copy-on-write and more detailed parsing of lines in Swift, please click here .
Decision:
Use the structure quite obvious here instead of the string:
struct Attributes: Hashable { var color: Color var orientation: Orientation var tail: Tail }
Change dictionary to:
var cache: [Attributes: UIImage] = []
Get rid of String
let key = Attributes(color: color, orientation: orientation, tail: tail)
In the Attributes structure, all properties are stored on Stack, since the enum is stored on Stack. This means that there is no implicit use of Heap here, and now the keys for the cache dictionary are very precisely defined, which increased the security and clarity of this code. We also got rid of the implicit use of Heap.
Verdict: Stack is much easier and faster than Heap - the choice for most situations is obvious.
2. Reference Counting
For what?
Swift should know when it is possible to free a piece of memory on Heap, occupied, for example, by an instance of a class or function. This is implemented through a link counting mechanism - each instance (class or function) hosted on Heap has a variable that stores the number of links to it. When there are no links to an instance, Swift decides to free a piece of memory allocated for it.
It should be noted that for a “quality” implementation of this mechanism much more resources are needed than for increasing and decreasing the Stack-pointer. This is due to the fact that the number of links can increase from different threads (since you can refer to a class or function from different threads). Also, do not forget about the need to ensure the synchronization of the shared resource (variable number of links) for different threads (spinlocks, semaphores, etc.).
Stack: finding free memory and freeing used memory - stack-pointer operation
Heap: search for free memory and free used memory - tree search algorithm and reference counting.
In the Attributes structure, all properties are stored on Stack, since the enum is stored on Stack. This means that there is no implicit use of Heap here, and now the keys for the cache dictionary are very precisely defined, which increased the security and clarity of this code. We also got rid of the implicit use of Heap.
Pseudo code
Consider a small piece of pseudocode to demonstrate how link counting works:
class Point { var refCount: Int var x, y: Double func draw() {...} init(...) { ... self.refCount = 1 } } let point1 = Point(x: 0, y: 0) let point2 = point1 retain(point2) // retain() - refCount 1 point2.x = 5 // `point1` release(point1) // release() - refCount 1 // `point2` release(point2)
Struct
When working with structures, a mechanism such as reference counting is simply not needed:
- struct not stored on Heap
- struct - copied upon assignment, therefore, no links
Copy links
Again, struct and any other value types in Swift are copied upon assignment. If the structure stores links in itself, they will also be copied:
struct Label { let text: String let font: UIFont ... init() { ... text.refCount = 1 font.refCount = 1 } } let label = Label(text: "Hi", font: font) let label2 = label retain(label2.text._storage) // `String` Heap retain(label2.font) // label release(label.text._storage) release(label.font) // label2 release(label2.text._storage) release(label2.font)
label and label2 share common instances hosted on Heap:
- text content
- and font
Thus, if the struct stores links in itself, then when copying this structure, the number of links doubles, which, if not necessary, negatively affects the "ease" of the program.
And again the “real” example:
struct Attachment { let fileUrl: URL // HEAP let uuid: String // HEAP let mimeType: String // HEAP init?(fileUrl: URL, uuid: String, mimeType: String) { guard mimeType.isMimeType else { return nil } self.fileUrl = fileUrl self.uuid = uuid self.mimeType = mimeType } }
The problems with this structure are that it has:
- 3 Heap allocation
- Because String can be any string, security and code clarity are affected.
At the same time, uuid and mimeType are strictly defined things:
uuid is a format string xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
mimeType is a type / extension format string.
Decision
let uuid: UUID // UUID , Foundation
In the case of mimeType, enum works fine:
enum MimeType { init?(rawValue: String) { switch rawValue { case "image/jpeg": self = .jpeg case "image/png": self = .png case "image/gif": self = .gif default: return nil } } case jpeg, png, gif }
Or better and easier:
enum MimeType: String { case jpeg = "image/jpeg" case png = "image/png" case gif = "image/gif" }
And do not forget to change:
let mimeType: MimeType
3.1 Method Dispatch
- this is an algorithm that looks for the method code that was called
Before talking about the implementation of this mechanism, it is worth determining what a “message” and “method” are in this context:
- a message is the name we send to the object. Arguments can still be sent along with the name.
circle.draw(in: origin)
The message is draw - the name of the method. The receiver object is a circle. Origin is also an argument passed.
- method is the code that will be returned in response to the message.
Then Method Dispatch is an algorithm that decides which method should be given to a particular message.
More specifically about Method Dispatch in Swift
Since we can inherit from the parent class and override its methods, Swift must know exactly which implementation of this method needs to be called in a specific situation.
class Parent { func me() { print("parent") } } class Child: Parent { override func me() { print("child") } }
Create a couple of instances and call the me method:
let parent = Parent() let child = Child() parent.me() // "parent" child.me() // "child"
A fairly obvious and simple example. What if:
let array: [Parent] = [Child(), Child(), Parent(), Child()] array.forEach { $0.me() // "child" "child" "parent" "child" }
This is not so obvious and requires resources and a certain mechanism to determine the correct implementation of the me method. Resources are the processor and RAM. A mechanism is a Method Dispatch.
In other words, Method Dispatch is how the program determines which method implementation to call.
When a method is called in the code, its implementation must be known. If she is known to
At the time of compilation, then this is Static Dispatch. If the implementation is determined immediately before the call (in runtime, at the time of code execution), then this is Dynamic Dispatch.
3.2 Method Dispatch - Static Dispatch
The most optimal, since:
- The compiler knows which block of code (method implementation) will be called. Thanks to this, he can optimize this code as much as possible and resort to such a mechanism as inlining.
- Also, at the time of code execution, the program will simply execute this block of code known to the compiler. No resources and time will be spent on determining the correct implementation of the method, which will accelerate the execution of the program.
3.3 Method Dispatch - Dynamic Dispatch
Not the most optimal, since:
- The correct implementation of the method will be determined at the time of program execution, which requires resources and time
- No compiler optimizations are out of the question
3.4 Method Dispatch - Inlining
A mechanism such as inlining was mentioned, but what is it? Consider an example:
struct Point { var x, y: Double func draw() { // Point.draw implementation } } func drawAPoint(_ param: Point) { param.draw() } let point = Point(x: 0, y: 0) drawAPoint(point)
- The point.draw () method and drawAPoint function will be processed through Static Dispatch, since there is no difficulty in determining the correct implementation for the compiler (since there is no inheritance and redefinition is impossible)
- since the compiler knows what will be executed, it can optimize this. First optimizes drawAPoint, simply replacing the function call with its code:
let point = Point(x: 0, y: 0) point.draw()
- then optimizes point.draw, since the implementation of this method is also known:
let point = Point(x: 0, y: 0) // Point.draw implementation
We created a point, executed the code of the draw method - the compiler simply substituted the necessary code for these functions instead of calling them. In Dynamic Dispatch, this will be a bit more complicated.
3.5 Method Dispatch - Inheritance-Based Polymorphism
Why do I need Dynamic Dispatch? Without it, it is not possible to define methods overridden by child classes. Polymorphism would not be possible. Consider an example:
class Drawable { func draw() {} } class Point: Drawable { var x, y: Double override func draw() { ... } } class Line: Drawable { var x1, y1, x2, y2: Double override func draw() { ... } } var drawables: [Drawable] for d in drawables { d.draw() }
- drawables array can contain Point and Line
- intuitively, Static Dispatch is not possible here. d in the for loop can be Line, or maybe Point. The compiler cannot determine this, and each type has its own implementation of draw
Then how does Dynamic Dispatch work? Each object has a type field. So Point (...). Type will be equal to Point, and Line (...). Type will be equal to Line. Also somewhere in the (static) memory of the program is a table (virtual-table), where for each type there is a list with its method implementations.
In Objective-C, the type field is known as the isa field. It is present on every Objective-C object (NSObject).
The class method is stored in virtual-table and has no idea about self. In order to use self inside this method, it needs to be passed there (self).
Thus, the compiler will change this code to:
class Point: Drawable { ... override func draw(_ self: Point) { ... } } class Line: Drawable { ... override func draw(_ self: Line) { ... } } var drawables: [Drawable] for d in drawables { vtable[d.type].draw(d) }
At the time of code execution, you need to look into the virtual-table, find the class d there, take the draw method from the resulting list and pass it an object of type d as self. This is a decent job for a simple method invocation, but it is necessary for the polymorphism to work. Similar mechanisms are used in any OOP language.
Method Dispatch - Summary
- class methods are processed by default through Dynamic Dispatch. But not all class methods need to be handled through Dynamic Dispatch. If the method is not overridden, then you can head it with the final keyword, and then the compiler will know that this method cannot be overridden and it will process it through Static Dispatch
- non-class methods cannot be overridden (since struct and enum do not support inheritance) and are processed through Static Dispatch
OOP Problems - Summary
It is necessary to pay attention to such trifles as:
- When creating an instance: where will it be located?
- When working with this instance: how will link counting work?
- When calling a method: how will it be processed?
If we pay for dynamism without realizing it and without need for it, then this will negatively affect the program being implemented.
Polymorphism is a very important and useful thing. At the moment, all that is known is that polymorphism in Swift is directly related to classes and reference types. We, in turn, say that classes are slow and heavy, and structure is simple and easy. Is polymorphism realized through structures possible? Protocol-oriented programming can provide an answer to this question.