
The image of the user's face is captured using an infrared camera, which is more resistant to changes in light and color of the environment. Using in-depth training, a smartphone is able to recognize the user's face in the smallest details, thereby “recognizing” the owner every time he picks up his phone. Surprisingly, Apple said that this method is even safer than TouchID: the error rate is 1: 1 000 000.
This article explores the principle of an algorithm similar to FaceID using Keras. Also presented are some of the final developments created using Kinect.
Understanding FaceID
“... the neural networks on which FaceID technology is based do not just perform the classification.”
The first step is to analyze how FaceID works on the iPhone X. Technical documentation can help us with this. With TouchID, the user had to first register their fingerprints by tapping the sensor several times. After 10-15 different touches, the smartphone completes the registration.
Similarly with FaceID: the user must register his face. The process is quite simple: the user simply looks at the phone as he does it daily, and then slowly turns his head in a circle, thereby registering his face in different poses. This ends the registration, and the phone is ready to unlock. This incredibly fast registration procedure can tell a lot about the basic learning algorithms. For example, the neural networks on which FaceID technology is based do not just perform classification.
Performing a classification for a neural network means the ability to predict whether the person that she “sees” at the moment is the face of the user. Therefore, she should use some training data to predict “true” or “false,” but unlike many other deep learning applications, this approach will not work here.
First, the network must train from scratch, using new data received from the user's face. This would require a lot of time, energy and a lot of data from different persons (not being the user's face) in order to have negative examples. In addition, this method will not allow Apple to train a more complex network “offline”, that is, in its laboratories, and then send it already trained and ready to use on their phones. It is believed that FaceID is based on the Siamese convolutional neural network, which is trained “offline” to display faces in a low-dimensional hidden space, formed to maximize the difference between faces of different people, using contrast loss. You get an architecture that can do one-time training, as mentioned in Keynote.

From face to numbers
The Siamese neural network basically consists of two identical neural networks, which also share all the weights. This architecture can learn to distinguish distances between specific data, such as images. The idea is that you transmit data pairs through Siamese networks (or just transfer data in two different steps through the same network), the network displays them in the low-dimensional characteristics of space, like an n-dimensional array, and then you train the network, to make such a comparison that the data of points from different classes were as far as possible, while the data of points from the same class were as close as possible.
Ultimately, the network will learn to extract the most significant functions from the data and compress them into an array, creating an image. To understand this, imagine how you would describe dog breeds using a small vector so that similar dogs would have almost similar vectors. You would probably use one number to encode the color of the dog, the other to indicate the size of the dog, the third for the length of the coat, etc. Thus, dogs that are alike will have similar vectors. A Siamese neural network can do this for you, just like an auto-encoder does.
Using this technology, a large number of individuals are needed to train such an architecture to recognize the most similar ones. With the right budget and computing power (as Apple does), you can also use more complex examples to make the network resistant to situations like twins, masks, etc.
What is the final advantage of this approach? In that, finally, you have a plug and play model that can recognize various users without any additional preparation, but simply calculate the location of a user's face on a hidden face map formed after setting FaceID. In addition, FaceID is able to adapt to changes in your appearance: both sudden (for example, glasses, hat, makeup), and “gradual” (growing hair). This is done by adding face support vectors calculated based on your new look to the map.

Implementing FaceID with Keras
For all machine learning projects, the first thing we need is data. Creating your own data set will require time and cooperation of many people, so this can be difficult. There is a website with an RGB-D faces dataset . It consists of a series of RGB-D photos of people standing in different poses and making different facial expressions, as would be the case with iPhone X. To see the final implementation, here is a link to GitHub.
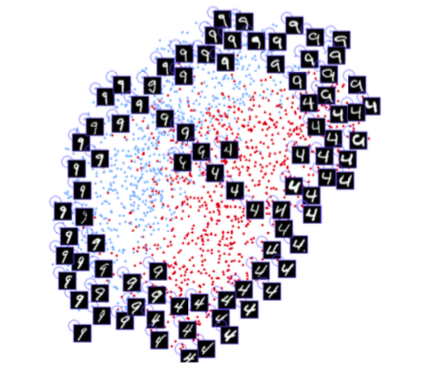
A convolution network is created based on the SqueezeNet architecture. As input, the network accepts both RGBD images of pairs of faces and 4-channel images, and displays the differences between the two attachments. The network learns with significant loss, which minimizes the difference between images of the same person and maximizes the difference between images of different faces.
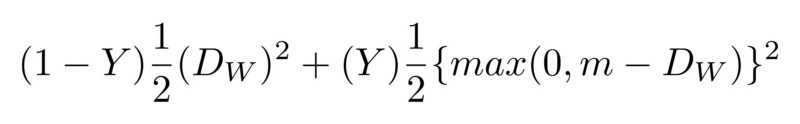
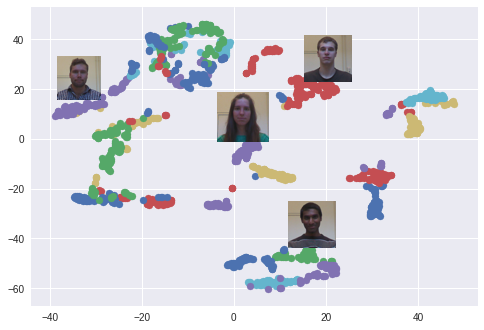
After training, the network is able to convert faces into 128-dimensional arrays, so that photos of the same person are grouped together. This means that to unlock the device, the neural network simply calculates the difference between the image that is required during unlocking with the images stored during the registration phase. If the difference matches a specific value, the device is unlocked.
The t-SNE algorithm is used. Each color corresponds to a person: as you can see, the network has learned to group these photos quite tightly. An interesting graph also arises when using the PCA algorithm to reduce data dimension.

Experiment
Now let's try to see how this model works, simulating a normal FaceID loop. First of all, register the person. Then we will unlock it both on behalf of the user and from other people who should not unlock the device. As mentioned earlier, the difference between the person who “sees” the phone and the registered person has a certain threshold.
Let's start with registration. Take a series of photographs of the same person from the data set and simulate the registration phase. Now the device calculates the attachments for each of these poses and saves them locally.


Let's see what happens if the same user tries to unlock the device. Different poses and facial expressions of the same user achieve a low difference, an average of about 0.30.

On the other hand, images from different people get an average difference of about 1.1.

Thus, a threshold value of approximately 0.4 should be sufficient to prevent strangers from unlocking the phone.
In this post, I showed how to implement the FaceID unlocking mechanics test concept based on embedding faces and Siamese convolution networks. I hope the information was useful to you. You can find all the relative Python code here.
More analysis of new technologies - in the Telegram channel .
All knowledge!