
Hello, Habr! I lead the development of the Vision platform - this is our public platform that provides access to computer vision models and allows you to solve tasks such as recognizing faces, numbers, objects and entire scenes. And today I want to tell by the example of Vision how to implement a fast, highly loaded service using video cards, how to deploy and operate it.
What is Vision?
This is essentially a REST API. The user generates an HTTP request with a photo and sends it to the server.
Suppose you need to recognize a face in a picture. The system finds it, cuts it, extracts some properties from the face, saves it in the database and assigns a conditional number. For example, person42. The user then uploads the next photo, which has the same person. The system extracts properties from its face, searches the database and returns the conditional number that was assigned to the person initially, i.e. person42.
Today, the main users of Vision are various projects of Mail.ru Group. Most requests come from Mail and Cloud.
In the Cloud, users have folders in which photos are uploaded. The cloud runs files through Vision and groups them into categories. After that, the user can conveniently flip through his photos. For example, when you want to show photos to friends or family, you can quickly find the ones you need.
Both Mail and Cloud are very large services with millions of people, so Vision processes hundreds of thousands of requests per minute. That is, it is a classic high-loaded service, but with a twist: it has nginx, a web server, a database, and queues, but at the lowest level of this service is inference - running images through neural networks. It is the run of neural networks that takes up most of the time and requires resources. Computing networks consists of a sequence of matrix operations that usually take a long time on the CPU, but they are perfectly parallelized on the GPU. To efficiently run networks, we use a cluster of servers with video cards.
In this article I want to share a set of tips that can be useful when creating such a service.
Service Development
Processing time for one request
For a system with a heavy load, the processing time of one request and the throughput of the system are important. High speed of query processing is provided, first of all, by the correct selection of neural network architecture. In ML, as in any other programming task, the same tasks can be solved in different ways. Take face detection: to solve this problem, we first took neural networks with R-FCN architecture. They show a rather high quality, but took about 40 ms on one image, which did not suit us. Then we turned to the MTCNN architecture and got a twofold increase in speed with a slight loss in quality.
Sometimes, in order to optimize the computation time of neural networks, it can be advantageous in the production to implement inference in another framework, not in the one that was taught. For example, sometimes it makes sense to convert your model to NVIDIA TensorRT. He applies a number of optimizations and is especially good on rather complex models. For example, it can somehow rearrange some layers, merge and even throw it away; the result will not change, and the inference calculation speed will increase. TensorRT also allows you to better manage memory and, after some tricks, can reduce it to calculating numbers with less accuracy, which also increases the speed of calculating inference.
Download video card
The network inference is carried out on the GPU, the video card is the most expensive part of the server, so it is important to use it as efficiently as possible. How to understand, have we fully loaded the GPU or can we increase the load? This question can be answered, for example, using the GPU Utilization parameter in the nvidia-smi utility from the standard video driver package. This figure, of course, does not show how many CUDA cores are directly loaded on the video card, but how many are idle, but it allows you to somehow evaluate the loading of the GPU. From experience, we can say that 80-90% loading is good. If it is 10-20% loaded, then this is bad, and there is still potential.
An important consequence of this observation: you need to try to organize the system so as to maximize the loading of video cards. In addition, if you have 10 video cards, each of which is loaded at 10-20%, then, most likely, two high-load video cards can solve the same problem.
System throughput
When you submit a picture to the input of a neural network, the picture processing is reduced to a variety of matrix operations. The video card is a multi-core system, and the input pictures we usually submit are small. Let's say there are 1,000 cores on our video card, and we have 250 x 250 pixels in the picture. Alone, they will not be able to load all the cores because of their modest size. And if we submit such pictures to the model one at a time, then loading the video card will not exceed 25%.

Therefore, you need to upload several images to inference at once and form a batch from them.

In this case, the video card load rises to 95%, and the calculation of inference will take time as for a single picture.
But what if there are no 10 pictures in the queue so that we can combine them into a batch? You can wait a bit, for example, 50-100 ms in the hope that requests will come. This strategy is called fix latency strategy. It allows you to combine requests from clients in an internal buffer. As a result, we increase our delay by some fixed amount, but significantly increase the system throughput.
Launch inference
We train models on images of a fixed format and size (for example, 200 x 200 pixels), but the service must support the ability to upload various images. Therefore, all images before submitting to inference, you need to properly prepare (resize, center, normalize, translate to float, etc.). If all these operations are performed in a process that launches inference, then its work cycle will look something like this:
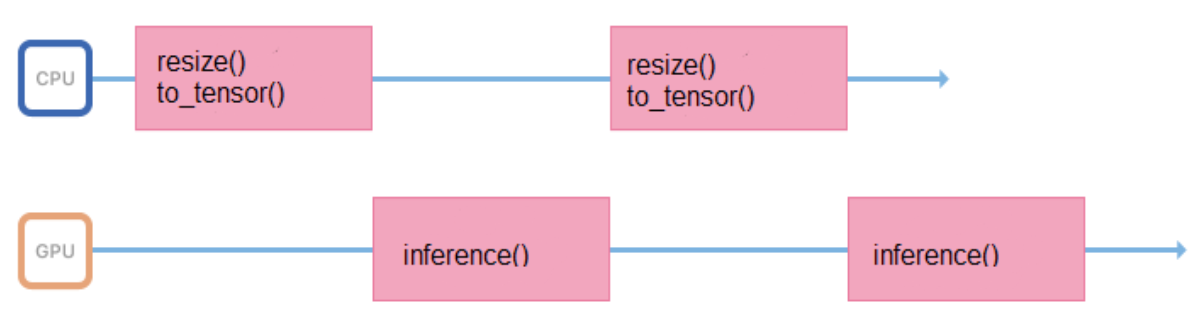
He spends some time in the processor, preparing the input data, for some time waiting for a response from the GPU. It is better to minimize the intervals between inferences so that the GPU is less idle.
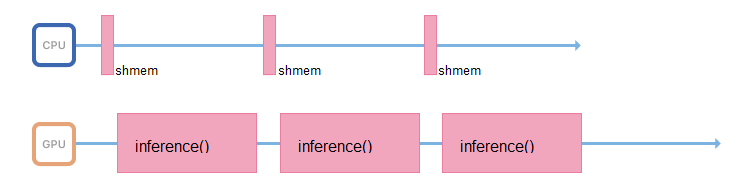
To do this, you can start another stream, or transfer image preparation to other servers, without video cards, but with powerful processors.
If possible, the process responsible for inference should deal only with it: access the shared memory, collect input data, immediately copy them to the video card's memory and run inference.
Turbo boost
Launching neural networks is an operation that consumes resources not only of the GPU, but also of the processor. Even if everything is organized correctly in terms of bandwidth, and the thread that performs the inference is already waiting for new data, on a weak processor you simply will not have time to saturate this stream with new data.
Many processors support Turbo Boost technology. It allows you to increase the frequency of the processor, but it is not always enabled by default. It’s worth checking it out. For this, Linux has the CPU Power utility:
$ cpupower frequency-info -m
.
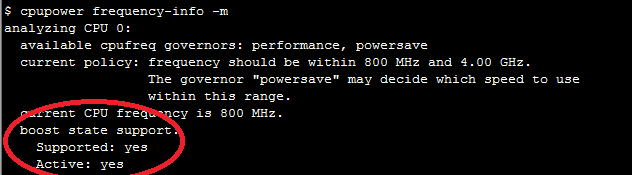
The processors also have a power consumption mode that can be recognized by such a CPU Power:
performance
command.
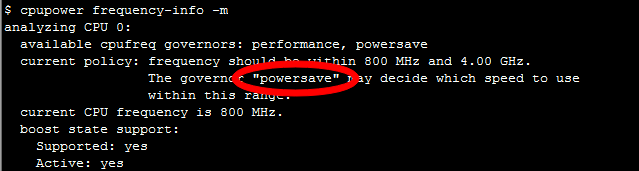
In powersave mode, the processor can throttle its frequency and run slower. It is worth going into the BIOS and choosing performance mode. Then the processor will always work at maximum frequency.
Application Deployment
Docker is great for deploying an application; it allows you to run applications on the GPU inside the container. To access the video cards, first you need to install the drivers for the video card on the host system - a physical server. Then, to start the container, you need to do a lot of manual work: correctly throw the video cards inside the container with the right parameters. After starting the container, it will still be necessary to install video drivers inside it. And only after that you can use your application.

This approach has one caveat. Servers can disappear from the cluster and be added. It is possible that different servers will have different versions of drivers, and they will differ from the version that is installed inside the container. In this case, a simple Docker will break: the application will receive a driver version mismatch error when trying to access the video card.

How to deal with this? There is a version of Docker from NVIDIA that makes using a container easier and more enjoyable. According to NVIDIA itself and according to practical observations, the overhead cost of using nvidia-docker is about 1%.
In this case, drivers need to be installed only on the host machine. When you start the container, you don’t need to throw anything inside, and the application will immediately have access to the video cards.

The "independence" of nvidia-docker from drivers allows you to run a container from the same image on different machines that have different versions of drivers installed. How is this implemented? Docker has such a concept as docker-runtime: it is a set of standards that describes how a container should communicate with the host kernel, how it should start and stop, how to interact with the kernel and driver. Starting with a specific version of Docker, it is possible to replace this runtime. This is what NVIDIA did: they replace the runtime, catch the calls to the video driver inside and convert the correct version to the calls to the video driver.
Orchestration
We chose Kubernetes as the orchestra. It supports many very nice features that are useful for any heavily loaded system. For example, autodiscovering allows services to access each other within a cluster without complex routing rules. Or fault tolerance - when Kubernetes always keeps several containers ready, and if something happened to yours, Kubernetes will immediately launch a new container.
If you already have a Kubernetes cluster configured, then you don’t need so much to start using video cards inside the cluster:
- relatively fresh drivers
- installed nvidia-docker version 2
- docker runtime set by default to `nvidia` in /etc/docker/daemon.json:
"default-runtime": "nvidia"
- Installed plugin
kubectl create -f https://githubusercontent.com/k8s-device-plugin/v1.12/plugin.yml
After you have configured your cluster and installed the device plugin, you can specify a video card as a resource.
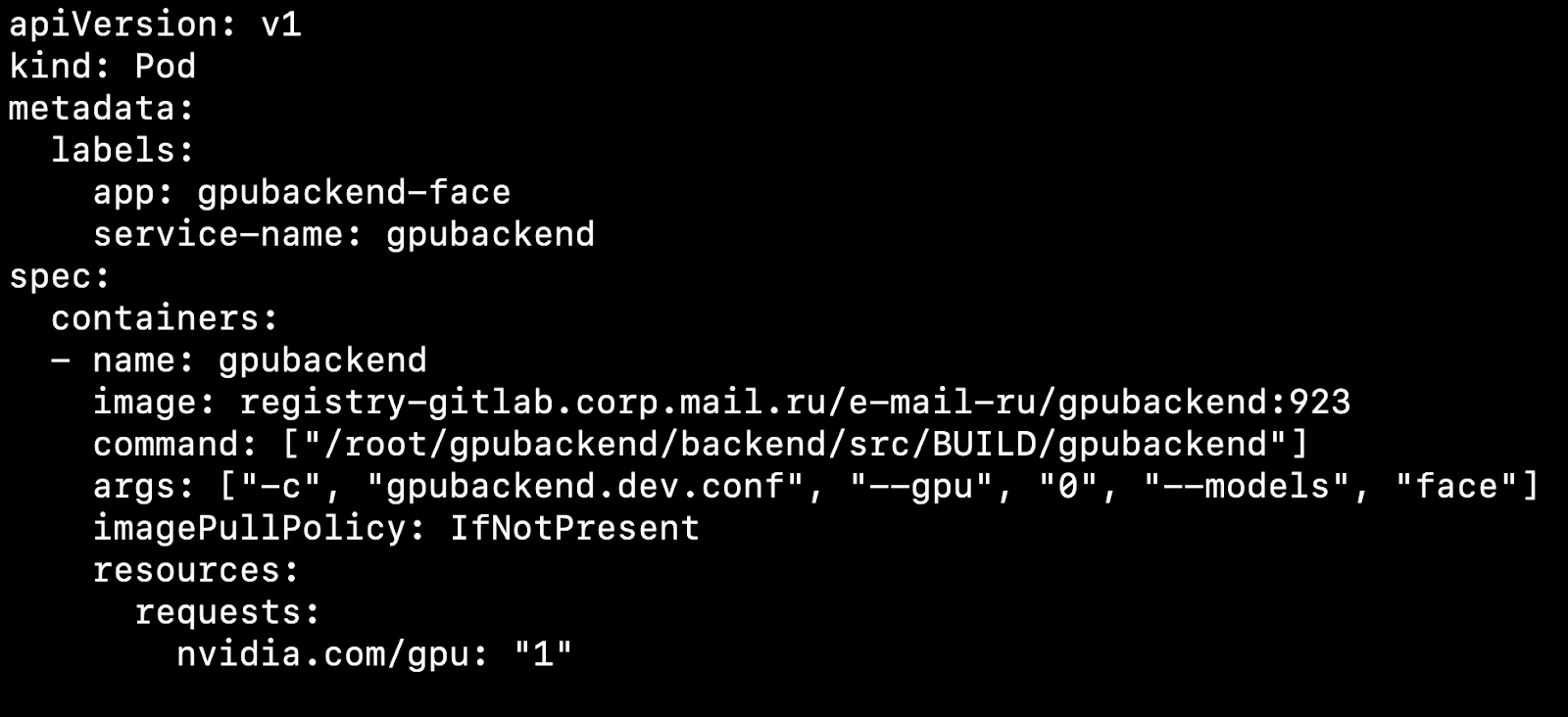
What does this affect? Let's say we have two nodes, physical machines. On one there is a video card, on the other not. Kubernetes will detect a machine with a video card and pick up our pod on it.
It is important to note that Kubernetes does not know how to competently fumble a video card between pods. If you have 4 video cards and you need 1 GPU to start the container, then you can raise no more than 4 pods on your cluster.
We take as a rule 1 Pod = 1 Model = 1 GPU.
There is an option to run more instances on 4 video cards, but we will not consider it in this article, since this option does not go out of the box.
If several models should be spinning at once, it’s convenient to create Deployment in Kubernetes for each model. In its configuration file, you can specify the number of hearths for each model, taking into account the popularity of the model. If a lot of requests come to the model, then for it, accordingly, you need to specify a lot of pods, if there are few requests, there are few pods. In total, the number of hearths should be equal to the number of video cards in the cluster.
Consider an interesting point. Let's say we have 4 video cards and 3 models.

On the first two video cards, let the inference of the face recognition model rise, on another recognition of objects and on another recognition of car numbers.
You work, clients come and go, and once, for example at night, a situation arises when a video card with inference objects is simply not loaded, a tiny amount of requests come to it, and video cards with face recognition are overloaded. I would like to put out a model with objects at this moment and launch faces in its place to unload the lines.
For automatic scaling of models on video cards, there are tools inside Kubernetes - horizontal hearth auto-scaling (HPA, horizontal pod autoscaler).
Out of the box, Kubernetes supports auto-scaling on CPU utilization. But in a task with video cards it will be much more reasonable to use information on the number of tasks for each model for scaling.
We do this: put requests for each model in a queue. When the requests are completed, we remove them from this queue. If we manage to quickly process requests for popular models, then the queue does not grow. If the number of requests for a particular model suddenly increases, then the queue begins to grow. It becomes clear that you need to add video cards that will help rake the line.
For information about the queues, we proxy through the HPA through Prometheus:
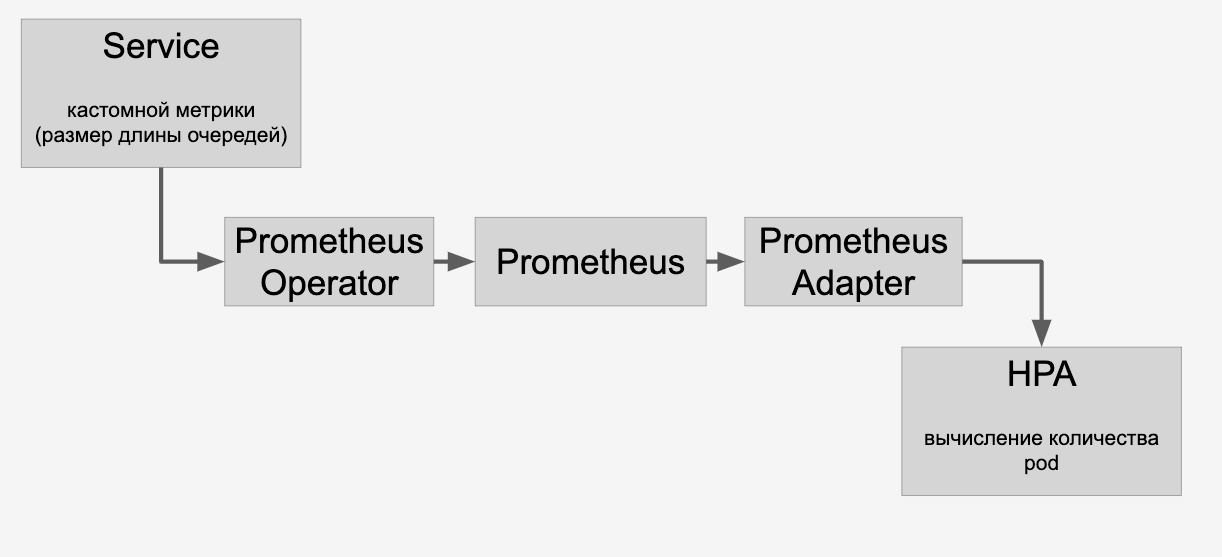
And then we do auto-scaling of models on video cards in the cluster depending on the number of requests to them.
CI / CD
After you have enclosed the application and wrapped it in Kubernetes, you have just one step left to the top of the project. You can add CI / CD, here is an example from our pipeline:
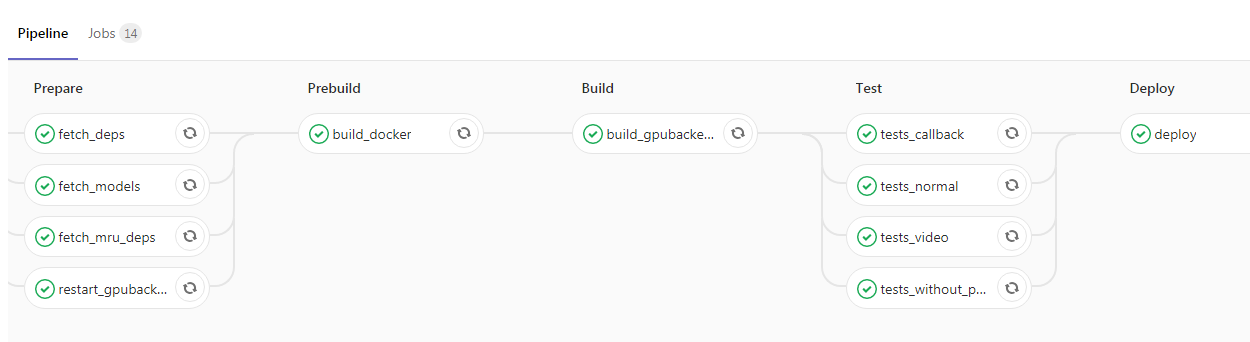
Here, the programmer launched the new code into the master branch, after which the Docker image with our backend daemons is automatically collected and the tests are run. If all the checkmarks are green, then the application is poured into the test environment. If there are no problems in it, then further it is possible to send the image into operation without difficulty.
Conclusion
In my article, I touched on some aspects of the work of a highly loaded service using a GPU. We talked about ways to reduce the response time of a service, such as:
- selection of the optimal neural network architecture to reduce latency;
- Applications of optimizing frameworks like TensorRT.
Raised the issues of increasing throughput:
- the use of image batching;
- applying fix latency strategy so that the number of inference runs is reduced, but each inference would process a larger number of pictures;
- optimization of data input pipeline to minimize GPU downtime;
- "Fight" with processor trotting, removal of cpu-bound operations to other servers.
We looked at the process of deploying an application with a GPU:
- Using nvidia-docker inside Kubernetes
- scaling based on the number of requests and HPA (horizontal pod autoscaler).