
From backend development to machine learning
What do ML data engineers do? What are the similarities and differences between the tasks of the backend developer and the ML engineer? What path do you need to go to change the first profession to the second? This was told by Alexander Parinov, who went into machine learning after 10 years of backend.

Alexander Parinov
Today, Alexander works as an architect of computer vision systems at the X5 Retail Group and contributes to open source projects related to computer vision and deep learning (github.com/creafz). His skills are confirmed by his participation in the top 100 of the world ranking Kaggle Master (kaggle.com/creafz) - the most popular platform that hosts machine learning competitions.
Why switch to machine learning
A year and a half ago, Jeff Dean, head of Google Brain, Google’s deep learning artificial intelligence research project, told Google how half a million lines of code in Google Translate were replaced by a neural network with Tensor Flow, which consists of just 500 lines. After training the network, data quality has grown and infrastructure has been simplified. It would seem that here is our bright future: no longer have to write code, just make neurons and throw them with data. But in practice, everything is much more complicated.
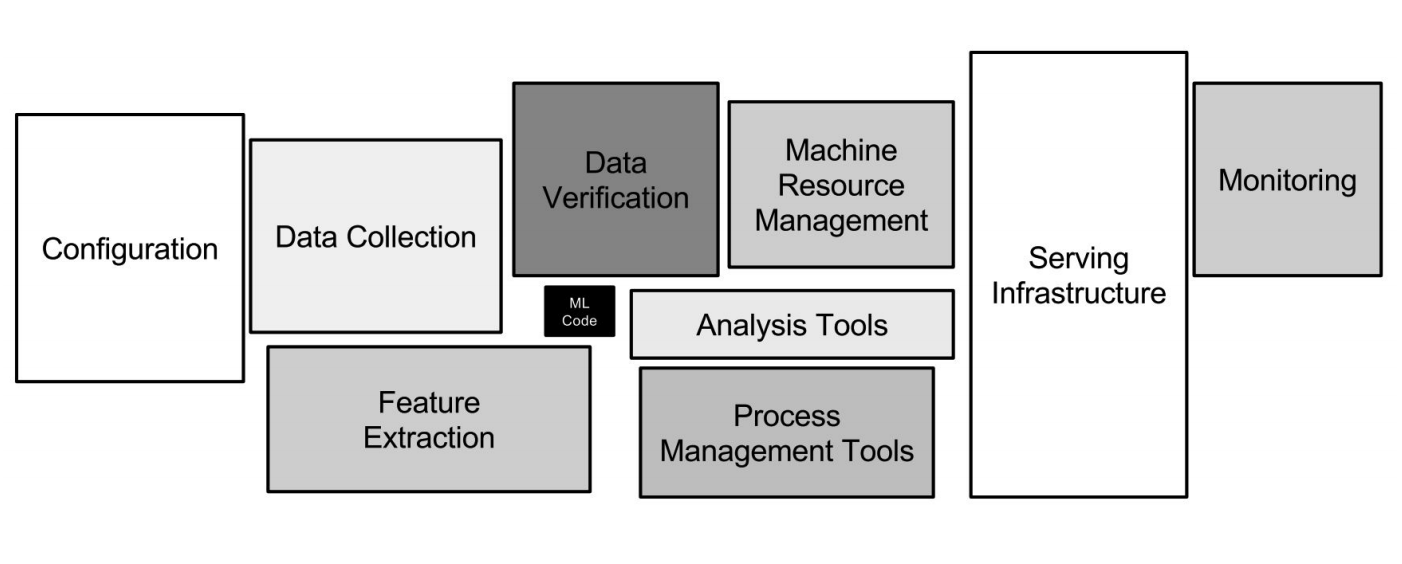 Google ML Infrastructure
Google ML Infrastructure
Neural networks are just a small part of the infrastructure (a small black box in the picture above). It takes many more auxiliary systems to receive data, process it, store it, check quality, etc., you need the infrastructure for training, deploying machine learning code in production, testing this code. All these tasks are just like what the backend developers do.
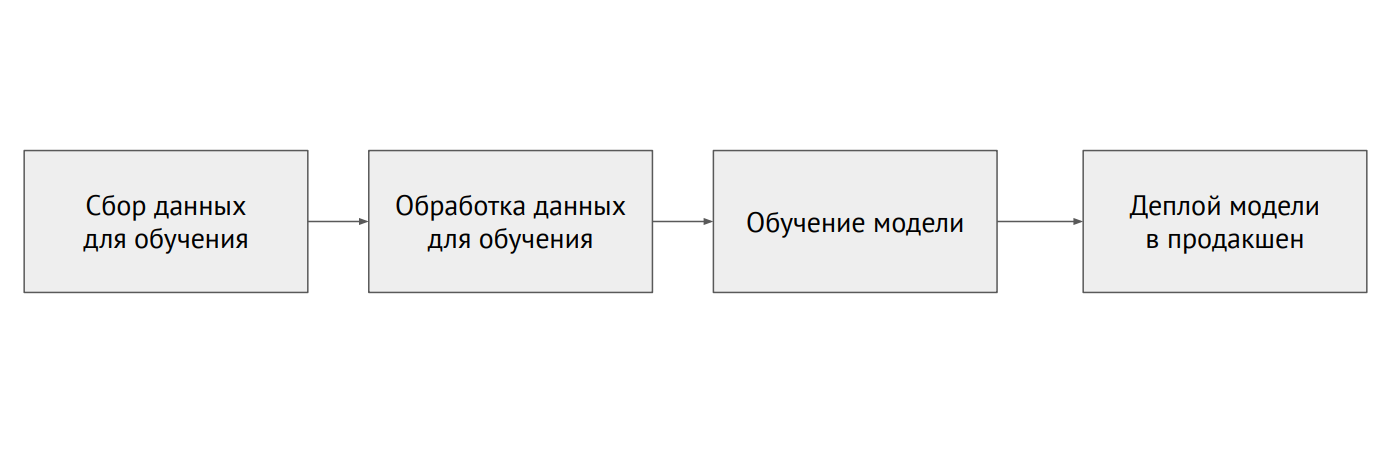 Machine learning process
Machine learning process
What is the difference between ML and backend
In classical programming, we write code, and this dictates the behavior of the program. In ML, we have a small model code and a lot of data with which we drop the model. Data in ML is very important: the same model, trained with different data, can show completely different results. The problem is that almost always the data is fragmented and lies in different systems (relational databases, NoSQL databases, logs, files).
 Data versioning
Data versioning
ML requires versioning not only of the code, as in classical development, but also of data: it is necessary to clearly understand what the model was trained on. You can use the popular Data Science Version Control library (dvc.org) for this.

Data markup
The next task is data markup. For example, mark all the objects in the picture or say which class it belongs to. This is done by special services like Yandex.Tolki, the work with which greatly simplifies the availability of the API. Difficulties arise due to the “human factor”: it is possible to improve data quality and minimize errors by entrusting the same task to several performers.
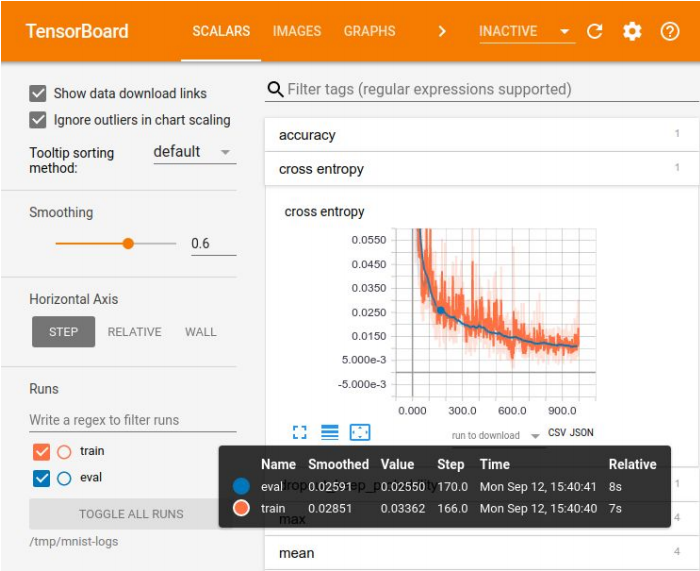 Visualization in the Tensor Board
Visualization in the Tensor Board
Logging of experiments is necessary for comparing results, choosing the best model for some metrics. For visualization there is a large set of tools - for example, Tensor Board. But there are no ideal methods for storing experiments. In small companies, they often get by with an excel-plate, in large companies they use special platforms for storing results in the database.
 There are many platforms for machine learning, but not one of them covers even 70% of the needs
There are many platforms for machine learning, but not one of them covers even 70% of the needs
The first problem that you have to deal with when you bring a trained model to production is related to your favorite data scientist tool - Jupyter Notebook. There is no modularity in it, that is, the output is such a "footbait" of code that is not broken into logical pieces - modules. Everything is mixed up: classes, functions, configurations, etc. This code is difficult to version and test.
How to deal with this? You can put up with Netflix and create your own platform that allows you to run these laptops directly in production, transfer data to them and get the result. You can force developers who roll the model into production to rewrite the code normally, break it into modules. But with this approach, it is easy to make a mistake, and the model will not work as intended. Therefore, the ideal option is to prohibit the use of Jupyter Notebook for model code. If, of course, Data Scientists agree to this.
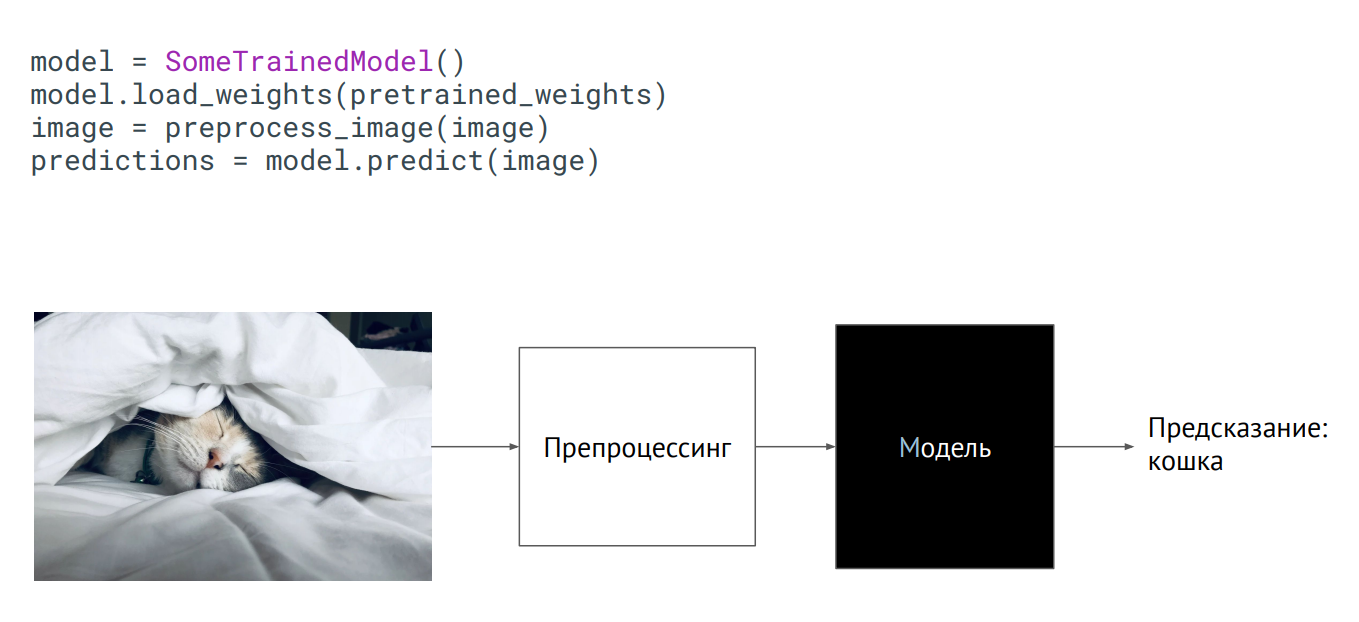 Model as a black box
Model as a black box
The easiest way to bring a model to production is to use it as a black box. You have some class of the model, the weights of the model (parameters of the neurons of the trained network) were passed to you, and if you initialize this class (call the predict method, put a picture on it), then the output will get some kind of prediction. What happens inside does not matter.
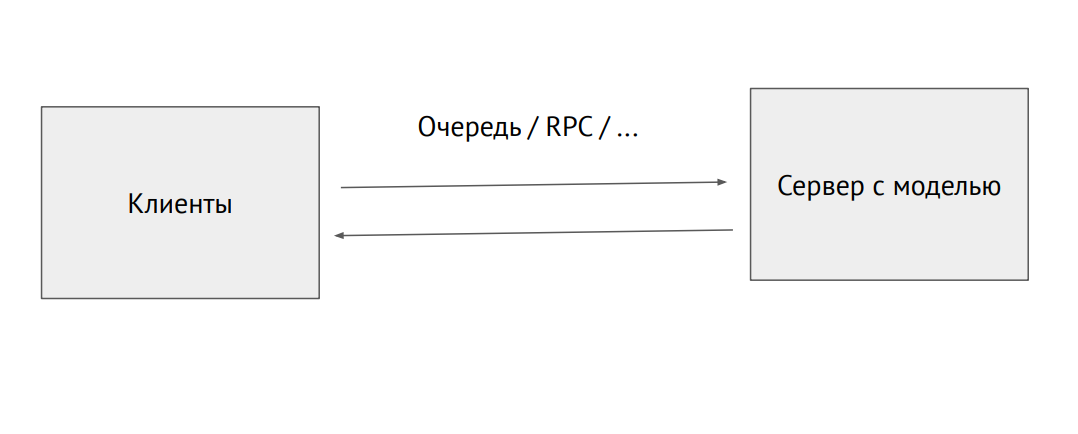
Separate server process with a model
You can also pick up a separate process and send it through the RPC queue (with pictures or other source data. At the output, we will receive predictions.
An example of using the model in Flask:
@app.route("/predict", methods=["POST"]) def predict(): image = flask.request.files["image"].read() image = preprocess_image(image) predictions = model.predict(image) return jsonify_prediction(predictions)
The problem with this approach is performance limitation. Suppose we have a Phyton code written by data scientists that slows down, and we want to squeeze the maximum performance. To do this, you can use tools that convert the code to native or convert it to another framework sharpened for production. There are such tools for each framework, but there are no ideal tools, you will have to finish it yourself.
The infrastructure in ML is the same as in a regular backend. There are Docker and Kubernetes, only for Docker you need to set the NVIDIA runtime, which allows the processes inside the container to access the video cards in the host. Kubernetes needs a plugin so that it can manage servers with video cards.
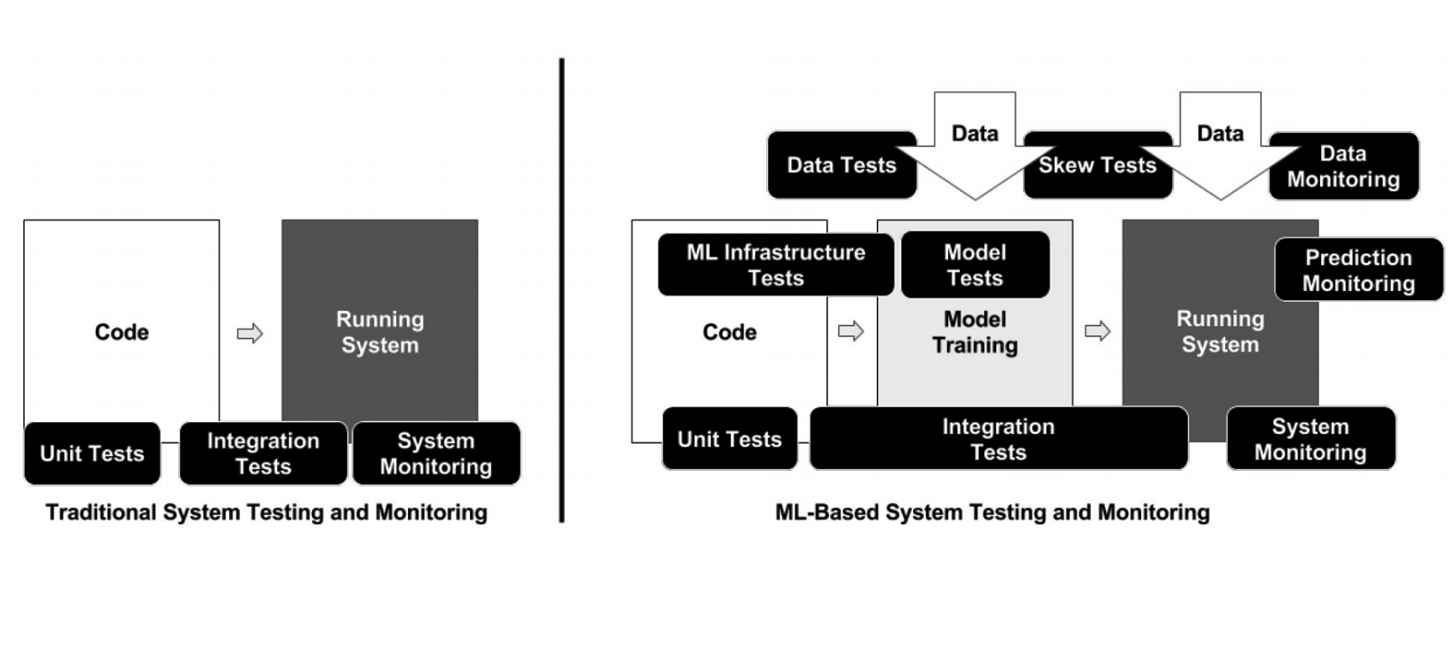
Unlike classical programming, in the case of ML, the infrastructure has many different moving elements that need to be checked and tested - for example, data processing code, model training pipeline and production (see diagram above). It is important to test the code linking different pieces of pipelines: there are a lot of pieces, and problems very often arise at the borders of modules.
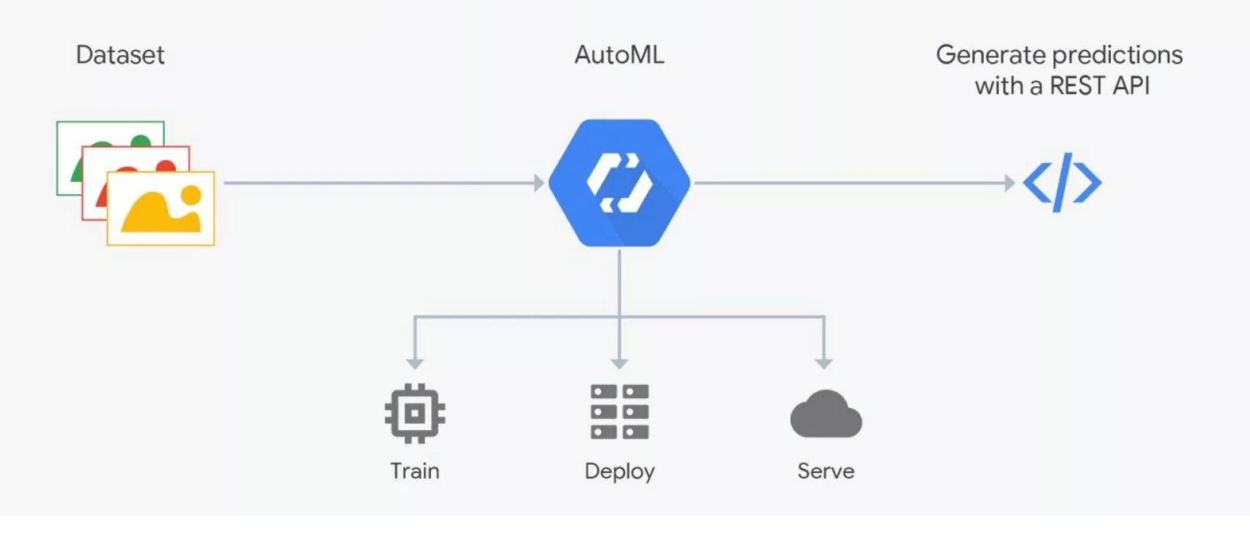
How AutoML Works
AutoML services promise to select the best model for your goals and train it. But you need to understand: in ML, data is very important, the result depends on their preparation. People are marking up, which is fraught with errors. Without tough control, garbage can turn out, but automation does not work out yet; verification by experts - data scientists is needed. This is where AutoML “breaks”. But it can be useful for the selection of architecture - when you have already prepared the data and want to conduct a series of experiments to find the best model.
How to get into machine learning
Getting into ML is easiest if you are developing in Python, which is used in all deep learning frameworks (and regular frameworks). This language is practically required for this field of activity. C ++ is used for some tasks with computer vision - for example, in control systems of unmanned vehicles. JavaScript and Shell - for visualization and such strange things as launching a neuron in a browser. Java and Scala are used when working with Big Data and for machine learning. R and Julia are loved by people who do statistics.
Getting practical experience to begin with is most convenient at Kaggle, participation in one of the platform’s contests gives more than a year of studying the theory. On this platform, you can take someone’s laid out and commented code and try to improve it, optimize for your goals. Bonus rank on Kaggle affects your salary.
Another option is to go as a backend developer to the ML team. Now there are a lot of startups involved in machine learning, in which you gain experience by helping colleagues in solving their problems. Finally, you can join one of the data scientist communities - Open Data Science (ods.ai) and others.
The speaker placed additional information on the topic at https://bit.ly/backend-to-ml
“Quadrupel” - the service of targeted notifications of the portal “State Services”
 Evgeny Smirnov
Evgeny Smirnov
The next speaker was Yevgeny Smirnov, head of the e-government infrastructure development department, who spoke about the Quadrupel. This is a service of targeted notifications of the Gosuslugi portal (gosuslugi.ru) - the most visited state resource of the Runet. The daily audience is 2.6 million, all in all, 90 million users are registered on the site, of which 60 million are confirmed. The load on the portal API is 30 thousand RPS.
 Technologies used in the Gosuslug backend
Technologies used in the Gosuslug backend
“Quadruple” is an address notification service, with the help of which the user receives a service offer at the most suitable moment for him by setting up special information rules. The main requirements in the development of the service were flexible settings and adequate time for mailing.
How does the Quadruple work?

The diagram above shows one of the rules of the “Quadruple” on the example of a situation with the need to replace a driver’s license. First, the service searches for users whose expiration date expires in a month. They put up a banner with an offer to receive the corresponding service and send an e-mail message. For those users who have already expired, the banner and email are changing. After a successful exchange of rights, the user receives other notifications - with a proposal to update the data in the certificate.
From a technical point of view, these are groovy scripts in which code is written. At the input - data, at the output - true / false, matched / not matched. In total, more than 50 rules - from determining the user's birthday (the current date is equal to the user's birthday) to difficult situations. Every day, according to these rules, about a million matches are determined - people who need to be notified.
 Quadruple Notification Channels
Quadruple Notification Channels
Under the hood of the Quadrupel there is a database in which user data is stored, and three applications:
- Worker is designed to update data.
- The Rest API picks up and gives the banners themselves to the portal and to the mobile application.
- Scheduler launches banner recounts or bulk mailing.
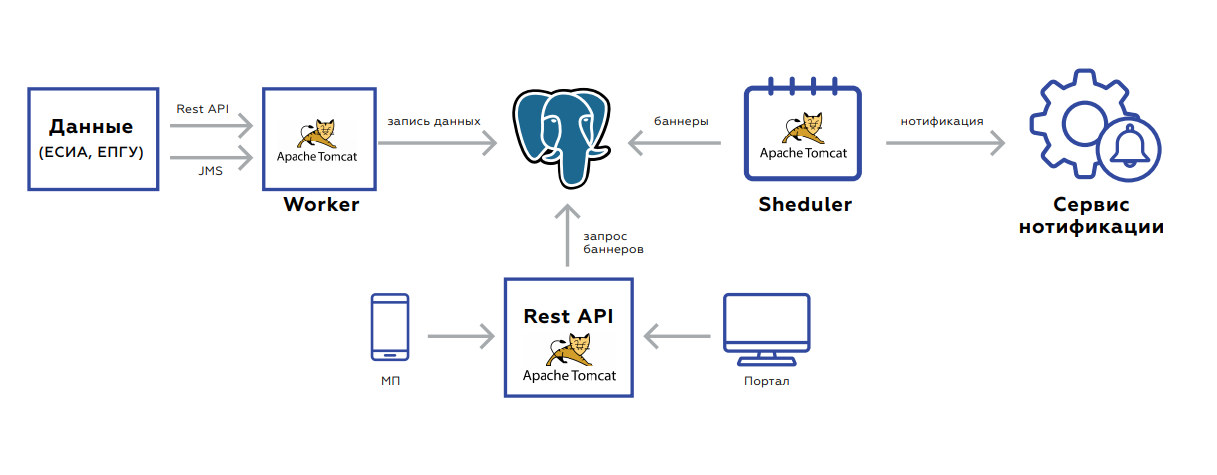
The backend is event-oriented for updating data. Two interfaces - rest or JMS. There are many events, before they are saved and processed, they are aggregated so as not to make unnecessary requests. The database itself, the plate in which the data is stored, looks like key value storage - the user's key and the value itself: flags indicating the presence or absence of relevant documents, their validity period, aggregated statistics on the order of services by this user, and so on.

After saving the data, the task is set in JMS so that the banners are immediately recounted - this must be immediately displayed on the web. The system starts at night: in JMS tasks are thrown at user intervals, for which you need to recount the rules. This is picked up by recounters. Further, the processing results fall into the next turn, which either saves the banners in the database, or sends tasks to the user to notify the user. The process takes 5-7 hours, it is easily scalable due to the fact that you can always either drop processors or raise instances with new processors.

The service works quite well. But the amount of data is growing as more users. This leads to an increase in the load on the database - even taking into account the fact that the Rest API looks into the replica. The second point is JMS, which, as it turned out, is not very suitable because of the large memory consumption. There is a high risk of queue overflow with JMS crash and processing stop. It is impossible to raise the JMS after this without cleaning the logs.
It is planned to solve problems using sharding, which will allow balancing the load on the base. There are also plans to change the data storage scheme, and change the JMS to Kafka - a more fault-tolerant solution that will solve memory problems.
Backend-as-a-Service Vs. Serverless

From left to right: Alexander Borgart, Andrey Tomilenko, Nikolai Markov, Ara Israelyan
Backend as a service or serverless solution? The following people participated in the discussion of this pressing issue at the round table:
- Ara Israelyan, CTO CTO and founder of Scorocode.
- Nikolay Markov, Senior Data Engineer at Aligned Research Group.
- Andrey Tomilenko, Head of RUVDS Development Department.
The conversation was moderated by senior developer Alexander Borgart. We present the debate, in which the audience participated, in an abridged version.
- What is Serverless in your understanding?
Andrei : This is a computational model - a Lambda function that should process data so that the result depends only on the data. The term came from Google, or from Amazon and its AWS Lambda service. It is easier for the provider to process such a function by allocating a capacity pool for this. Different users can independently be considered on the same servers.
Nikolay : If it’s simple, we transfer some part of our IT infrastructure, business logic to the cloud, to outsource.
Ara : On the part of the developers - a good attempt to save resources, on the part of marketers - to earn more money.
- Serverless - the same as microservices?
Nikolai : No, Serverless is more an organization of architecture. Microservice is an atomic unit of a certain logic. Serverless is an approach, not a “separate entity.”
Ara : The Serverless function can be packaged in a microservice, but from this it will cease to be Serverless, cease to be a Lambda function. In Serverless, a function starts only when it is requested.
Andrew : They differ in life time. We launched and forgot the Lambda function. It worked for a couple of seconds, and the next client can process its request on another physical machine.
- Which scales better?
Ara : With horizontal scaling, Lambda functions behave in exactly the same way as microservices.
Nikolai : How many replicas you ask - there will be so many of them, there are no problems with Serverless scaling. In Kubernetes, I made a replica set, launched 20 instances “somewhere”, and you returned 20 anonymized links. Forward!
- Is it possible to write a backend on Serverless?
Andrew : Theoretically, but there is no point in this. Lambda functions will rest against a single repository - we also need to provide a guarantee. For example, if the user conducted a certain transaction, then the next time he should see: the transaction has been completed, the funds have been credited. All Lambda functions will be blocked on this call. In fact, a bunch of Serverless-functions will turn into a single service with one narrow point of access to the database.
- In what situations does it make sense to use serverless architecture?
Andrey : Tasks in which a common storage is not required - the same mining, blockchain. Where you need to count a lot. If you have a lot of computing power, then you can define a function such as “calculate the hash of something there ...” But you can solve the problem of data storage by taking, for example, Amazon and Lambda-functions, and their distributed storage. And it turns out that you are writing a regular service. Lambda functions will access the repository and give some kind of response to the user.
Nikolai : Containers that run in Serverless are extremely resource-limited. There is little memory and everything else. But if you have all the infrastructure deployed completely on some cloud - Google, Amazon - and you have a permanent contract with them, there is a budget for all this, then for some tasks you can use Serverless containers. It is necessary to be located exactly inside this infrastructure, because everything is tailored for use in a specific environment. That is, if you are ready to tie everything to the cloud infrastructure, you can experiment. The plus is that you do not have to manage this infrastructure.
Ara : That Serverless does not require you to manage Kubernetes, Docker, install Kafka, and so on, is self-deception. The same Amazon and Google are the manager and they put it. Another thing is that you have an SLA. With the same success, you can outsource everything, and not program it yourself.
Andrew : Serverless itself is inexpensive, but you have to pay a lot for the rest of the Amazon services - for example, a database. People were already suing them, for tearing crazy money for an API gate.
Ara : If we talk about money, then you need to consider this point: you will have to deploy 180 degrees the entire development methodology in the company in order to transfer all the code to Serverless. It will take a lot of time and money.
- Are there any decent alternatives to paid Serverless Amazon and Google?
Nikolay : In Kubernetes, you start some kind of job, it fulfills and dies - this is quite Serverless from the point of view of architecture. If you want to create a really interesting business logic with queues, with bases, then you need to think a little more about it. This is all solved without leaving Kubernetes. I would not begin to drag additional implementation.
- How important is it to monitor what is happening in Serverless?
Ara : Depends on the system architecture and business requirements. In fact, the provider should provide reports that will help the devo figure out possible problems.
Nikolai : In Amazon there is CloudWatch, where all the logs are streamed, including with Lambda. Integrate log forwarding and use some separate tool for viewing, alerting and so on. In the containers that you start, you can cram agents.

- Let's summarize.
Andrew : Thinking about Lambda functions is useful. If you create a service on your knee - not a microservice, but one that writes a request, accesses the database and sends an answer - the Lambda function solves a number of problems: multithreading, scalability, and more. If your logic is built in this way, then in the future you will be able to transfer these Lambda to microservices or use third-party services like Amazon. The technology is useful, an interesting idea. How much it is justified for business is still an open question.
Nikolai: Serverless is better to use for operation-tasks than to calculate some kind of business logic. I always take this as event processing. If you have it in Amazon, if you are in Kubernetes - yes. Otherwise, you will have to make a lot of efforts to raise Serverless yourself. You need to look at a specific business case. For example, I have one of the tasks now: when files appear on a disk in a certain format, you need to upload them to Kafka. I can use this WatchDog or Lambda. Logically, both are suitable, but Serverless is harder to implement, and I prefer a simpler path without Lambda.
Ara : Serverless - an interesting, applicable, very technically beautiful idea. Sooner or later, technology will come to the point that any function will rise in less than 100 milliseconds. Then, in principle, there will be no question of whether the waiting time is critical for the user. At the same time, the applicability of Serverless, as colleagues have already said, is completely dependent on the business task.
We thank our sponsors who helped us a lot:
- The space of IT conferences " Spring " for the site for the conference.
- Calendar of IT events Runet-ID and the publication " Internet in numbers " for information support and news.
- Akronis for gifts.
- Avito for co-creation.
- Association of Electronic Communications RAEC for involvement and experience.
- The main sponsor of RUVDS - for everything!
