Scanners connected to personal computers work great in companies, but progress does not stand still, and mobile devices have taken over the world. The range of tasks for working with text has also changed. Now you need to look for the text not on perfectly straight A4 sheets with black text on a white background, but on various business cards, colorful menus, store signs and much more on what a person can meet in the jungle of a modern city.

A real example of the work of our neural network. The picture is clickable.
Basic requirements and limitations
With such a variety of conditions for presenting text, handwritten algorithms can no longer cope. Here, neural networks with their ability to generalize come to the rescue. In this post, we will talk about our approach to creating a neural network architecture that detects text on complex images with good quality and high speed.
Mobile devices impose additional restrictions on the choice of approach:
- Users do not always have the opportunity to use a mobile network to communicate with the server due to expensive roaming traffic or privacy issues. So solutions like Google Lens won't help here.
- Since we focus on local data processing, it would be nice for our solution:
- It took up little memory;
- It worked quickly using the technical capabilities of the smartphone.
- The text can be rotated and be on a random background.
- Words can be very long. In convolutional neural networks, the scope of the convolution kernel usually does not cover the elongated word as a whole, so it will take some trick to get around this restriction.

- The text sizes in one photo may be different:

Decision
The simplest solution to the text search problem that comes to mind is to take the best network from the ICDAR (International Conference on Document Analysis and Recognition) competitions specializing in this task and business! Unfortunately, such networks achieve quality due to their cumbersomeness and complexity of calculations, and are only suitable as a cloud solution, which does not meet paragraphs 1 and 2 of our requirements. But what if we take a large network that works well in the scenarios that we need to cover and try to reduce it? This approach is already more interesting.
Baoguang Shi et al in their neural network SegLink [1] proposed the following:
- To find not whole words at once (green areas in the image a ), but their parts, called segments, with the prediction of their rotation, tilt and shift. Let's borrow this idea.
- You need to search for word segments on several scales at once to meet requirement 5. The segments are shown by green rectangles in image b .
- In order to save a person from inventing how to combine these segments, we simply make the neural network predict connections (links) between segments related to the same word
but. within the same scale (red lines in image c )
b. and between scales (red lines in image d ), solving the problem of clause 4 of the requirements.
Blue squares in the image below show the visibility areas of the pixels of the output layers of the neural network of different scales, which "see" at least part of the word.

Segment and Link Examples
SegLink uses the well-known VGG-16 architecture as its foundation. Prediction of segments and links in it is carried out on 6 scales. As the first experiment, we started with the implementation of the original architecture. It turned out that the network contains 23 million parameters (weights) that need to be stored in a file of 88 megabytes. If you create an application based on VGG, then it will become one of the first candidates for removal if there is not enough space, and the text search itself will work very slowly, so the network needs to lose weight urgently.

SegLink Network Architecture
The secret of our diet
You can reduce the size of the network simply by changing the number of layers and channels in it, or by changing the convolution itself and the connections between them. Mark Sandler and associates just in time picked up the architecture in their MobileNetV2 network [2] so that it works quickly on mobile devices, takes up little space, and still does not lag behind the same VGG in quality of work. The secret to working speed and reducing memory consumption is in three main steps:
- The number of channels with feature maps at the entrance to the block is reduced by point convolution to the entire depth (the so-called bottleneck) without an activation function.
- The classic convolution is replaced by a per-channel separable convolution. Such a convolution requires less weight and less computation.
- Character cards after the bottleneck are forwarded to the input of the next block for summing without additional convolutions.
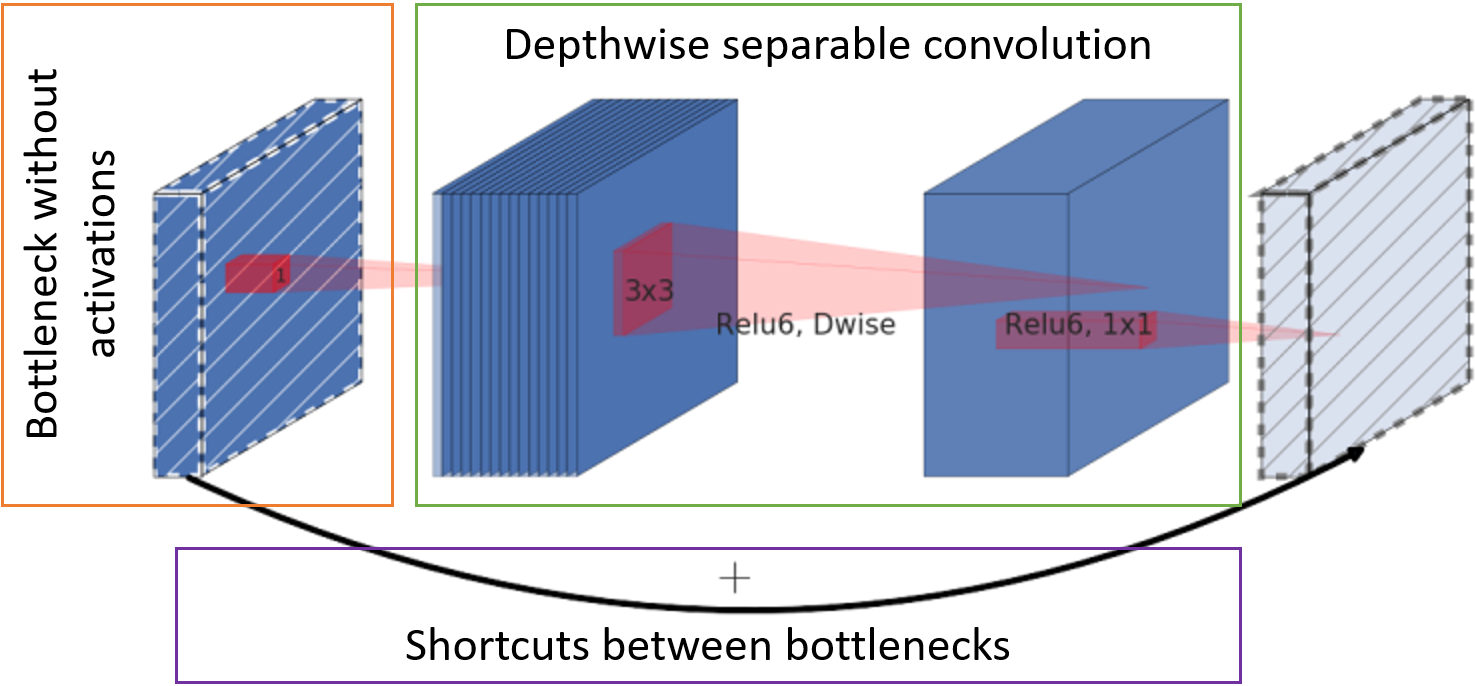
MobileNetV2 Base Unit
Resulting neural network
Using the above approaches, we came to the following network structure:
- We use segments and links from SegLink
- Replace VGG with a less gluttonous MobileNetV2
- Reduce the number of text search scales from 6 to 5 for speed

Text Search Summary Network
Decryption of values in network architecture blocks
The stride step and the base number of channels in the channels are indicated as s <stride> c <channels>, respectively. For example, s2c32 means 32 channels with a shift of 2. The actual number of channels in the convolution layers is obtained by multiplying their base number by a scaling factor α, which allows you to quickly simulate different “thickness” of the network. Below is a table with the number of parameters in the network depending on α.

Block type:
- Conv2D - a full-fledged convolution operation;
- D-wise Conv - per-channel separable convolution;
- Blocks - a group of MobileNetV2 blocks;
- Output - convolution to get the output layer. NxN values indicate the size of the receptive pixel field.
As an activation function, the blocks use ReLU6.

The output layer has 31 channels:
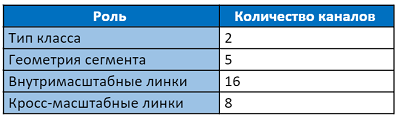
The first two channels of the output layer vote for the pixel to belong to the text and not the text. The following five channels contain information for accurately reconstructing segment geometry: vertical and horizontal shifts relative to the position of the pixel, factors for width and height (since the segment is usually not square), and the rotation angle. 16 values of intra-channel links indicate whether there is a connection between eight neighboring pixels on the same scale. The last 8 channels tell us about the presence of links to four pixels of the previous scale (the previous scale is always 2 times larger). Every 2 values of segments, intra- and cross-scale links are normalized by softmax function. Access to the very first scale does not have cross-scale links.
Word assembly
The network predicts whether a particular segment and its neighbors belong to the text. It remains to collect them into words.
To begin, combine all the segments that are linked by links. To do this, we compose a graph where the vertices are all segments at all scales, and the edges are links. Then we find the connected components of the graph. For each component, it is now possible to calculate the word's enclosing rectangle as follows:
- We calculate the angle of rotation of the word θ
- Or as the average value of the predictions of the angle of rotation of the segments, if there are a lot of them,
- Or as the angle of rotation of the line obtained by regression on the points of the centers of the segments, if there are few segments.
- The center of the word is selected as the center of mass of the center points of the segments.
- Expand all segments by -θ to arrange them horizontally. Find the boundaries of the word.
- The left and right borders of the word are selected as the boundaries of the left and right segments, respectively.
- To get the upper word boundary, the segments are sorted by the height of the upper edge, 20% of the highest ones are cut off, and the value of the first segment is selected from the list remaining after filtering.
- The lower boundary is obtained from the lowest segments with a cutoff of 20% of the lowest, by analogy with the upper boundary.
- Turn the resulting rectangle back to θ.
The final solution is called FaSTExt : Fast and Small Text Extractor [3]
Experiment time!
Training Details
The network itself and its parameters were chosen for good work on a large internal sample, which reflects the main scenario of using the application on the phone - he directed the camera at the object with text and took a photo. It turned out that a large network with α = 1 bypasses in quality the version with α = 0.5 by only 2%. This sample is not publicly available, so for clarity, I had to train the network on the public sample ICDAR2013 , in which the shooting conditions are similar to ours. The sample is very small, so the network was previously trained on a huge amount of synthetic data from SynthText in the Wild Dataset . The pre-training process took about 20 days of calculations for each experiment on the GTX 1080 Ti, so the network operation on public data was checked only for options α = 0.75, 1 and 2.
As an optimizer, the AMSGrad version of Adam was used.
Error Functions:
- Cross entropy for the classification of segments and links;
- Huber loss function for segment geometry.
results
In terms of the quality of the network’s performance in the target scenario, we can say that it does not lag far behind competitors in quality, and even overtakes some. MS is a heavy multiscale network of competitors.

* In the article on EAST there were no results on the sample we needed, so we conducted the experiment ourselves.
The image below shows an example of how FaSTExt works on images from ICDAR2013. The first line shows that the illuminated letters of the word ESPMOTO were not marked, but the network was able to find them. The less capacious version with α = 0.75 coped with small text worse than the more “thick” versions. On the bottom line, markup flaws are again visible in the selection with lost text in the reflection. FaSTExt at the same time sees such text.

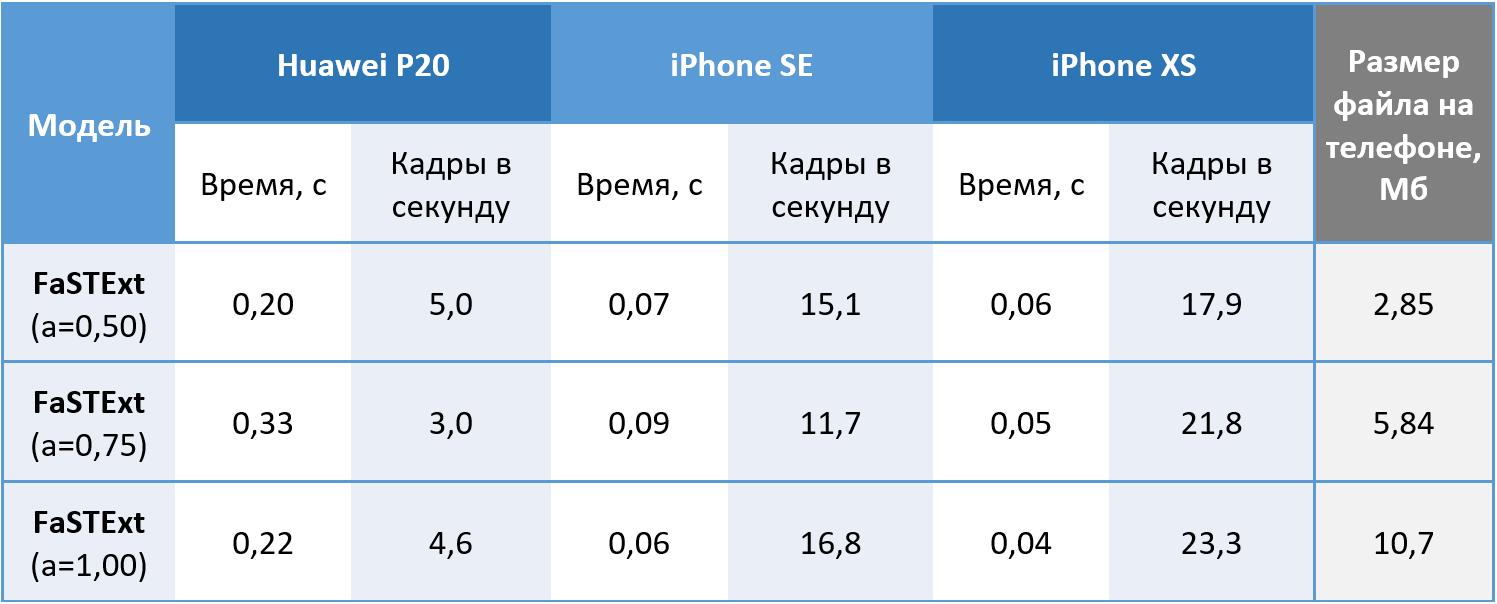
So, the network performs its tasks. It remains to check whether it can actually be used on phones? Models were launched on 512x512 color images on the Huawei P20 using the CPU, and on the iPhone SE and iPhone XS using the GPU, because our machine learning system so far allows using the GPU only on iOS. Values obtained by averaging 100 starts. On Android, we managed to achieve a speed of 5 frames per second acceptable for our task. An interesting effect has appeared on the iPhone XS with a decrease in the average time required for calculations while complicating the network. A modern iPhone detects text with minimal delay, which can be called a victory.
List of references
[1] B. Shi, X. Bai and S. Belongie, “Detecting Oriented Text in Natural Images by Linking Segments,” Hawaii, 2017. link
[2] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov and L.-C. Chen, “MobileNetV2: Inverted Residuals and Linear Bottlenecks,” Salt Lake City, 2018. link
[3] A. Filonenko, K. Gudkov, A. Lebedev, N. Orlov and I. Zagaynov, “FaSTExt: Fast and Small Text Extractor,” in 8th International Workshop on Camera-Based Document Analysis & Recognition, Sydney, 2019 link
[4] Z. Zhang, C. Zhang, W. Shen, C. Yao, W. Liu and X. Bai, “Multi-oriented text detection with fully convolutional networks,” Las Vegas, 2016. link
[5] X. Zhou, C. Yao, H. Wen, Y. Wang, S. Zhou, W. He and J. Liang, “EAST: An Efficient and Accurate Scene Text Detector,” at the 2017 IEEE Conference on Computer Vision and Pattern, Honolulu, 2017. link
[6] M. Liao, Z. Zhu, B. Shi, G.-s. Xia and X. Bai, “Rotation-Sensitive Regression for Oriented Scene Text Detection,” at the 2018 IEEE / CVF Conference on Computer Vision and Pattern, Salt Lake City, 2018. link
[7] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao and J. Yan, “Fots: Fast oriented text spotting with a unified network,” at the 2018 IEEE / CVF Conference on Computer Vision and Pattern, Salt Lake City, 2018. link
Computer vision group