
The upcoming release of Red Hat Ansible Engine 2.9 is waiting for you with impressive improvements, some of which are described in this article. As usual, we developed Ansible Network improvements openly, with community support. Join - Take a look at the GitHub task board and explore the development plan for the release of Red Hat Ansible Engine 2.9 on the wiki page for Ansible Network .
As we recently announced, Red Hat Ansible Automation Platform now includes Ansible Tower, Ansible Engine, and all Ansible Network content. Now, most popular network platforms are implemented through Ansible modules. For example:
- Arista eos
- Cisco IOS
- Cisco IOS XR
- Cisco NX-OS
- Juniper Junos
- Vyos
A complete list of platforms that are fully supported by Red Hat through Ansible Automation is available here .
What have we learned
Over the past four years, we have learned a lot about developing a platform for network automation. We also learned about how end-user platform artifacts are used in Ansible playbooks and roles. And here is what we found out:
- Organizations automate devices not just one, but many vendors.
- Automation is not only a technical phenomenon, but also a cultural one.
- Large-scale automation of networks is more complicated than it seems, due to the fundamental architectural principles of automation design.
When we discussed our long-term development plans over a year ago, our corporate clients requested the following:
- Fact collection needs to be better standardized and aligned with the automation workflow for any device.
- Updating configurations on the device also needs to be standardized and harmonized so that Ansible modules process the second half of the cycle after collecting the facts.
- We need rigorous and supported methods for converting device configuration into structured data. On this basis, the source of truth can be moved from a network device.
Fact enhancements
Gathering facts from network devices using Ansible is often at random. Network platforms are equipped to varying degrees with the ability to collect facts, but they have almost no — or even none at all — functions for parsing and standardizing the presentation of data in key-value pairs. Read Ken Celenza's post on how difficult and painful it is to analyze and standardize factual data.
You may have noticed how we worked on the Ansible Network Engine role. Naturally, 24,000 downloads later, the Network Engine role quickly became one of Ansible's most popular roles in Ansible Galaxy for network automation scenarios. Before we moved much of this to Ansible 2.8, in order to prepare for what Ansible 2.9 needed, this Ansible role provided the first set of tools to help command parsing, command management, and data collection for network devices.
If you are good at using Network Engine, this is a very efficient way to collect, parse, and standardize fact data for use with Ansible. The disadvantage of this role is that you need to create a whole bunch of parsers for each platform and for all network activity. To see how difficult it is to create, ship, and maintain parsers, look at the 1200+ parsers from the guys at Cisco.
In a nutshell, for large-scale automation it is very important to receive facts from devices and normalize them into key-value pairs, but this is difficult to achieve when you have many vendors and network platforms.
Each network fact module in Ansible 2.9 can now analyze the configuration of a network device and return structured data - without additional libraries, Ansible roles or custom parsers.
Starting with Ansible 2.9, with each release of the updated network module, the fact module is improved to provide information about this configuration section. That is, the development of facts and modules is now happening at the same pace, and they will always have a common data structure.
The resource configuration on a network device can be extracted and converted to structured data in two ways. In both ways, you can collect and convert a specific list of resources using the new gather_network_resources
. Resource names correspond to module names, and this is very convenient.
At the time of collecting the facts:
Using the gather_facts
you can extract the current device configuration at the beginning of the playbook, and then use it throughout the playbook. Specify the individual resources to extract from the device.
- hosts: arista module_defaults: eos_facts: gather_subset: min gather_network_resources: - interfaces gather_facts: True
You might notice something new in these examples, namely, gather_facts: true
now available for native fact-gathering for network devices.
Using the network facts module directly:
- name: collect interface configuration facts eos_facts: gather_subset: min gather_network_resources: - interfaces
The playbook returns the following facts about the interface:
ansible_facts: ansible_network_resources: interfaces: - enabled: true name: Ethernet1 mtu: '1476' - enabled: true name: Loopback0 - enabled: true name: Loopback1 - enabled: true mtu: '1476' name: Tunnel0 - enabled: true name: Ethernet1 - enabled: true name: Tunnel1 - enabled: true name: Ethernet1
Notice how Ansible retrieves the native configuration from the Arista device and converts it into structured data to use as standard key-value pairs for subsequent tasks and operations.
Interface facts can be added to Ansible stored variables and used immediately or later as input to the eos_interfaces
resource eos_interfaces
without additional processing or conversion.
Resource modules
So, we extracted the facts, normalized the data, entered them into the standardized internal schema of the data structure and got a ready source of truth. Hurrah! This, of course, is great, but we still need to somehow convert the key-value pairs back to the specific configuration that a specific device platform expects. Now we need modules for specific platforms to satisfy these new facts-gathering and normalization requirements.
What is a resource module? The device configuration sections can be thought of as the resources provided by this device. Network resource modules are intentionally limited to one resource, and they can be stacked like bricks to configure complex network services. As a result, the requirements and specifications for the resource module are naturally simplified, because the resource module can read and configure a specific network service on a network device.
To explain what the resource module does, let's look at an example of a playbook that shows an idempoent operation using new facts from a network resource and the eos_l3_interface
module.
- name: example of facts being pushed right back to device. hosts: arista gather_facts: false tasks: - name: grab arista eos facts eos_facts: gather_subset: min gather_network_resources: l3_interfaces - name: ensure that the IP address information is accurate eos_l3_interfaces: config: "{{ ansible_network_resources['l3_interfaces'] }}" register: result - name: ensure config did not change assert: that: not result.changed
As you can see, the data collected from the device is transferred directly to the corresponding resource module without conversion. At startup, the playbook retrieves the values from the device and compares them with the expected values. In this example, the received values correspond to the expected ones (that is, the configuration deviations are checked) and a message is displayed if the configuration has changed.
An ideal way to detect configuration deviations is to store the facts in Ansible stored variables and periodically use them with the resource module in check mode. This is a simple method to see if someone changed the values manually. In most cases, organizations allow manual changes and configuration, although many operations are performed through Ansible Automation.
How are new resource modules different from previous ones?
For a network automation engineer, there are 3 main differences between resource modules in Ansible 2.9 from previous versions.
1) For a specific network resource (which can also be thought of as a configuration section), the modules and facts will develop in all supported network operating systems at the same time. We think that if Ansible supports resource configuration on a single network platform, we should support it everywhere. This simplifies the use of resource modules because the network automation engineer can now configure the resource (for example, LLDP) in all network operating systems with native and supported modules.
2) Resource modules now include a state value.
-
merged
: configuration is merged with the provided configuration (default); -
replaced
: the resource configuration will be replaced with the provided configuration; -
overridden
: the resource configuration will be replaced with the provided configuration; excess resource instances will be deleted; -
deleted
: the resource configuration will be deleted / restored by default.

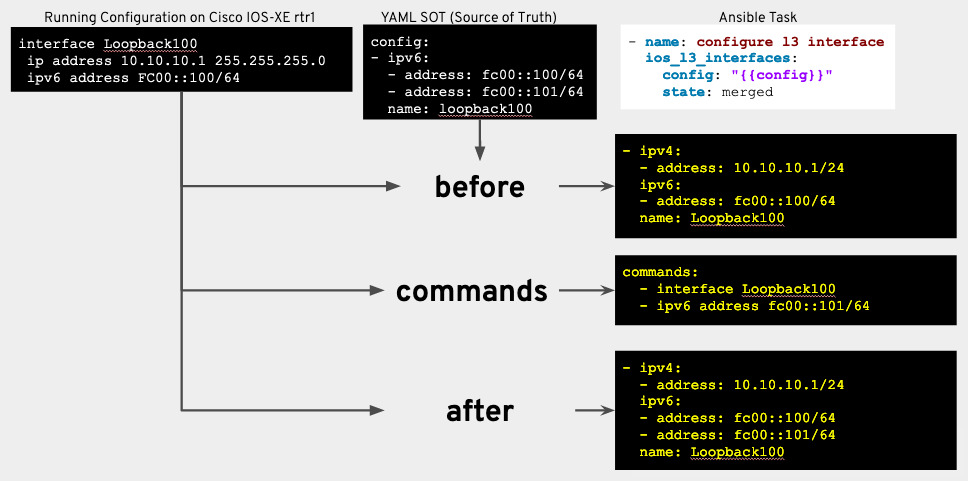
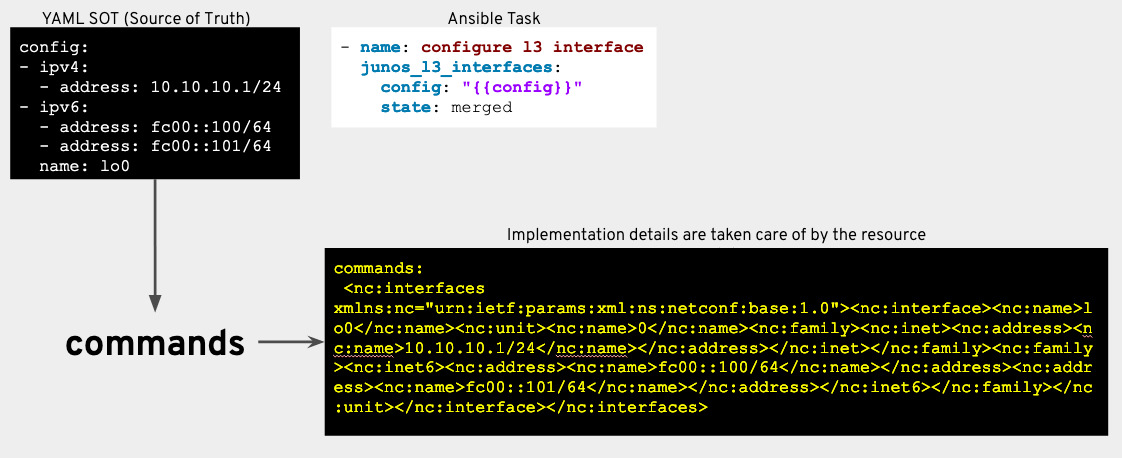
3) Resource modules now include stable return values. When the network resource module has made (or suggested) the necessary changes to the network device, it returns the same key-value pairs to the playbook.
-
before
: configuration on the device in the form of structured data before the task; -
after
: if the device has changed (or may change if the verification mode is used), the resulting configuration will be returned in the form of structured data; -
commands
: any configuration commands running on the device to bring it to the desired state.
What does all this mean? Why is it important?
This post describes a lot of complex concepts, but we hope that in the end you will better understand that corporate customers are asking for facts, data normalization and loop configuration for the automation platform. But why do they need these improvements? Many organizations are now engaged in digital transformation to make their IT environments more flexible and competitive. For better or worse, many network engineers become network developers, either out of their own interest or at the behest of managers.
Organizations understand that automating individual network templates does not solve the problem of fragmentation and increases efficiency only to a certain point. The Red Hat Ansible Automation Platform provides rigorous and normative resource data models to programmatically manage the underlying data on a network device. That is, users are gradually abandoning individual configuration methods in favor of more modern methods with a focus on technologies (for example, IP addresses, VLAN, LLDP, etc.), and not on a specific vendor implementation.
Does this mean that the days of reliable and proven command modules and configurations are numbered? In no case. The expected network resource modules will not be applicable in all cases and not for each vendor, so the network engineers will still need the command and configuration modules for certain implementations. The purpose of resource modules is to simplify large Jinja templates and normalize unstructured device configurations into a structured JSON format. With resource modules, it will be easier for existing networks to transform their configuration into structured key-value pairs that will be an easy-to-read source of truth. If you use structured key-value pairs, you can switch from running configurations on each device to working with independent structured data and bring networks to the forefront with the “infrastructure as code” approach.
What resource modules will appear in Ansible Engine 2.9?
Before telling in detail what will happen in Ansible 2.9, let's recall how we divided the entire amount of work.
We identified 7 categories and each assigned specific network resources:
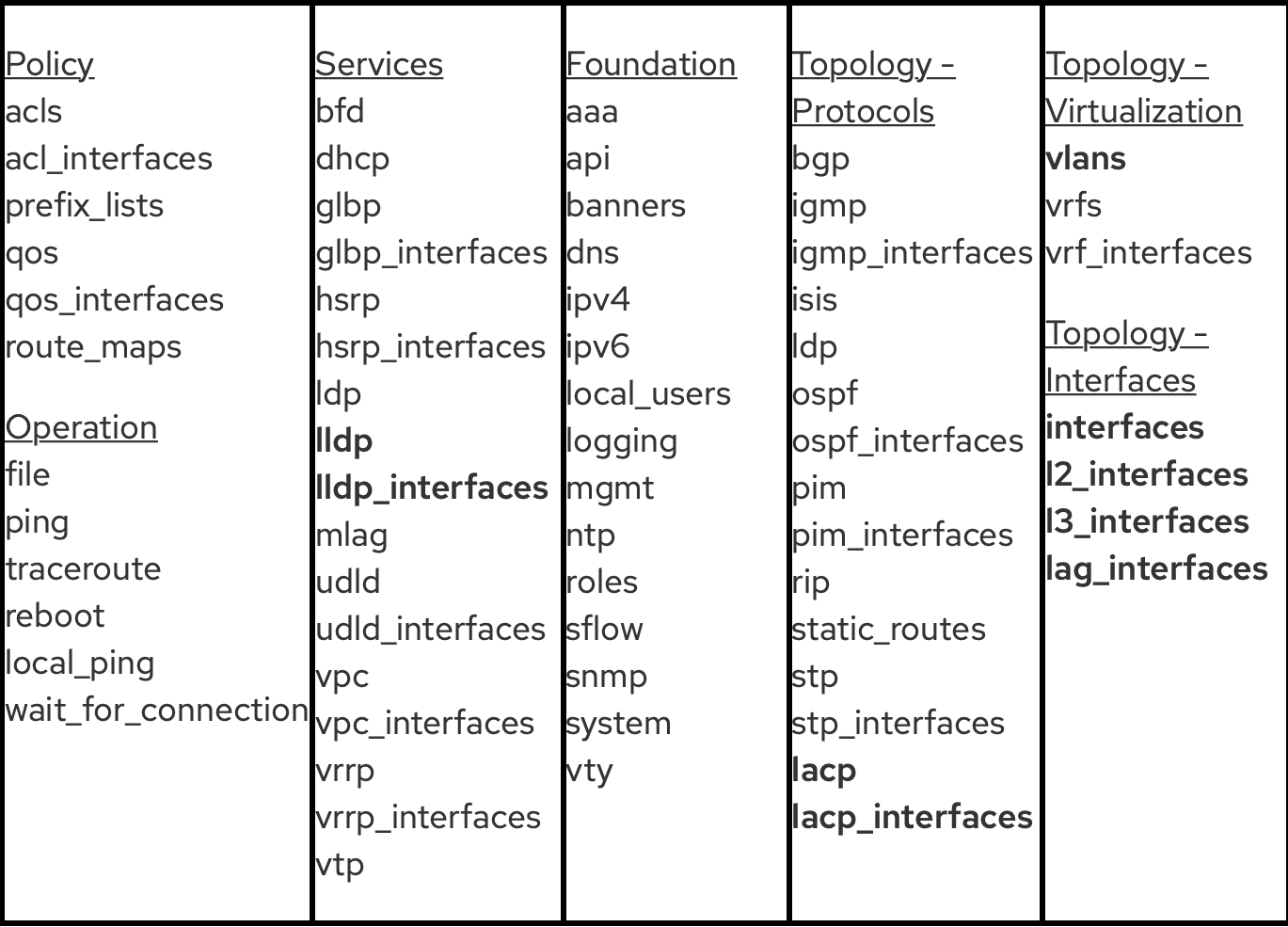
Note: bold resources were planned and implemented in Ansible 2.9.
Based on feedback from corporate clients and the community, it was logical to first deal with those modules that are related to network topology protocols, virtualization, and interfaces.
The following resource modules are developed by the Ansible Network team and correspond to the platforms that Red Hat supports:

The following modules are developed by the Ansible community:
-
exos_lldp_global
- from Extreme Networks. -
nxos_bfd_interfaces
- from Cisco -
nxos_telemetry
- from Cisco
As you can see, the concept of resource modules fits into our platform orientation strategy. That is, we include the necessary capabilities and functions in Ansible itself, in order to support standardization in the development of network modules, as well as to simplify the work of users at the level of Ansible roles and playbooks. To expand the development of resource modules, the Ansible team released the Module Builder tool.
Plans for Ansible 2.10 onwards
After the release of Ansible 2.9, we will deal with the following set of resource modules for Ansible 2.10, which can be used to further configure the topology and network policy, for example, ACL, OSPF, and BGP . The development plan can still be adjusted, so if you have comments, report it to the Ansible Network community .
Resources and getting started
Ansible Automation Platform Press Release
Ansible Automation Platform Blog
The future of content delivery at Ansible
Reflections on Changing the Ansible Project Structure