This short story will be devoted to how not to fall into the trap of imaginary control over the process of estimating tasks for the upcoming sprint. I must say right away that the data presented below are only indicative and comments on the non-use of Fibonacci numbers for the purpose of estimating here will be superfluous.
Our team consisted of an analyst, tester, designer and 2 developers, however, for greater clarity, we leave only the developers.
We start a new sprint and gradually proceed to the assessment of User stories. Nothing new. Move on...

Planning is completed and the results can be seen above. They took 3 User stories valued at 16, 20 and 37 story points, respectively. Total - 73.
Further, like any self-respecting development team that adores all the delights of working on Scrum, we add these ratings to Jira. At the same time, we introduce only general (or average - even worse!) Estimates for each story.
Two weeks of work without removing your hands from the keyboard and without getting up from the office chair that has been so beloved for years, you can contemplate the newly made functionality.
But what is the matter? The sprint is over and we see that the front did everything as planned and wouldn’t have time to do any more keystrokes, and the back went beyond the sprint and did more tasks than planned.
And here appears just finished reading Scrum and XP from the Trenches PM and says: “Everything is clear !!! We’ll have to take more building points to the next sprint and then everything will be fine and no backing will run away from me anymore, taking with them scooping !! ”
We are planning a new sprint ....
Fine! Took 10 story points more !!! Now we have calculated everything for sure !!
Another 2 weeks fly by quickly and it's time to take stock.
But to everyone’s regret, the sprint ended in a completely different way than we would like.
For some reason, the back again pulled ahead, and the front did not have time to do what they planned (the possibility that the front is just an inexperienced June, and we will lower the back untouchable senior and imagine that the whole thing is only about the wrong planning).
Another sprint was a failure !!! But why, we took quite a bit more storypots and that, only for good purposes - to give the necessary amount of work for the server side ??!?
How can this be ?? The answer is all about the evaluation system itself. Back to our sprints.

What do we see? It turns out that taking more storpoints on the new sprint to load the back, we just loaded the front.
Having understood this, the first thought in PM’s crazy head is to find out how many story points the front took upon itself and how much backing. But looking at the overall rating in Jira is simply not possible, because all that can be found there is a general (well or average) rating for each story, and remember who give what kind of rating is no longer possible.

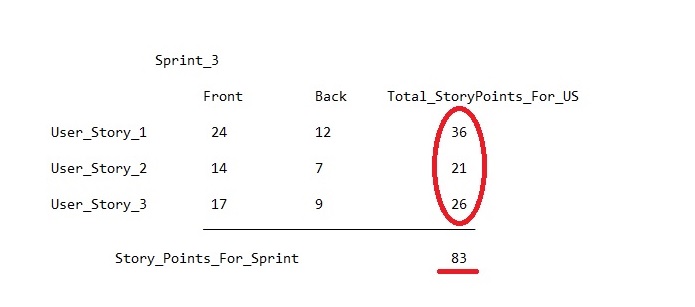
And then the solution comes by itself. In order to successfully regulate the load of a team, it is necessary to keep not only a general record in the history points, but also a separate record in the context of the load on the front and back. This will allow you to find out the optimal amount of work for each area and rely on it to fill the sprint backlog. So far, this approach cannot be implemented in Jira without separate notes in MS Excel, but this does not mean that it should not be used.
I am sure that Atlassian developers will come to a solution to this problem, but for now, just do not repeat our mistakes!
PS These conclusions are applicable only for the development of client-server applications, where there is a clear separation of work on the front and backend. Such a problem should not arise in the team of Full-Stack developers, who immediately evaluate the work in two directions.