
In general, everything in nginx is modules that were once written by someone. Therefore, writing modules under nginx is not only possible, but also necessary. When it is necessary to do it and why, Vasily Soshnikov ( dedokOne ) will tell on the example of several cases.
Let's talk about the reasons that encourage writing modules in C, the architecture and core of nginx, the anatomy of HTTP modules, C modules, NJS, Lua, and nginx.conf. This is important to know not only to those who develop under nginx, but also to those who use nginx-configs, Lua or another language inside nginx.
Note: the article is based on a report by Vasily Soshnikov. The report is constantly being updated and updated. The information in the material is quite technical and in order to get the most out of it, readers need to have experience working with nginx code at an average level and above.
Briefly about nginx
All you use with nginx are modules . Each directive in the nginx configuration is a separate module, which was carefully written by colleagues from the nginx community.
Directives in nginx.conf are also modules that solve a specific problem. Therefore, in nginx modules are everything. add_header, proxy_pass, any directive is modules or combinations of modules that work according to certain rules.
Nginx is a framework that has: Network & File I / O, Shared Memory, Configuration & Scripting. This is a huge layer of low-level libraries, on which you can do anything to work with the network drives.
Nginx is fast and stable, but complex . You should write such code not to lose these qualities of nginx. Unstable nginx on production are dissatisfied clients, and all that follows from this.
Why create your own modules
Convert the HTTP protocol to another protocol. This is the main reason that often motivates the creation of a particular module.
For example, the memcached_pass module converts HTTP to another protocol, and you can work with other external systems. The proxy_pass module also allows you to convert, though from HTTP (s) to HTTP (s). Another good example is fastcgi_pass.
These are all directives of the form: "go to such and such a backend, where not HTTP (but in the case of proxy_pass HTTP)."
Dynamic content insertion: AdBlock bypass, ad insertion. For example, we have a backend and it is necessary to modify the content that comes from it. For example, AdBlock, which analyzes the ad insertion code, and we need to deal with it - to tune it in one way or another.
Another thing you often have to do to embed content is the problem with HLS caching. When parameters are cached inside HLS, then two users can get the same session or the same parameters. From there, you cut or add some parameters when you need to track something.
Clickstream data collection from internet / mobile meters. A popular case in my practice. Most often this is done on nginx, but not on access.log, but a little more intelligent.
Converting all sorts of content. For example, the rtmp module for allows you to work not only with rtmp, but also with HLS. This module can do a lot with video content.
Generic authorization point: SEP or Api Gateway. This is the case when nginx works as part of the infrastructure: authorizes, collects metrics, sends data to monitoring and ClickStream. Nginx works here as an infrastructure hub - a single entry point for backends.
Enrichment of requests for their subsequent tracing. Modern systems are very complex, with several types of backends that make different teams. As a rule, they are difficult to debut, sometimes it is even difficult to understand where the request came from and where it went. To simplify debugging, some large companies use a tricky technique - they add certain data to requests. The user will not see them, but from this data it is easy to trace the request path inside the system. This is called a trace .
S3-proxy. This year, I often see people working with their objects through s3. But it is not necessary to do this on C-modules, the infrastructure is sufficient in nginx as well. To solve some of these problems, you can use Lua, something is being solved on NJS. But sometimes it is necessary to write modules in C.
When is the time to create modules
There are two criteria to understand that the time has come.
Generalization of functionality. When you understand that someone else needs your product, then you should smuggle it into Open Source, create generalized functionality, post it and let it be used.
Solving business problems. When a business sets such requirements that can be satisfied only by writing its own module for nginx. For example, dynamic insertion / change of content, ClickStream collection can be done on Lua, but most likely it will not work normally.
Nginx architecture
I have been writing nginx code for a long time. Nine of my modules are spinning in production, one of them is in Open Source, and in production for many. Therefore, I have experience and understanding.
Nginx is a nesting doll in which everything is built around the kernel.So I understand nginx.
Core are wrappers over epoll.Epoll is a method that allows you to work asynchronously with any descriptor files, not just sockets, because a descriptor is not just a socket.
Upstreams, HTTP, and scripting are built on top of the kernel. By scripting, I mean nginx.conf, not NJS. On top of upstreams, HTTP and scripting, HTTP modules are already built, which we will talk about.
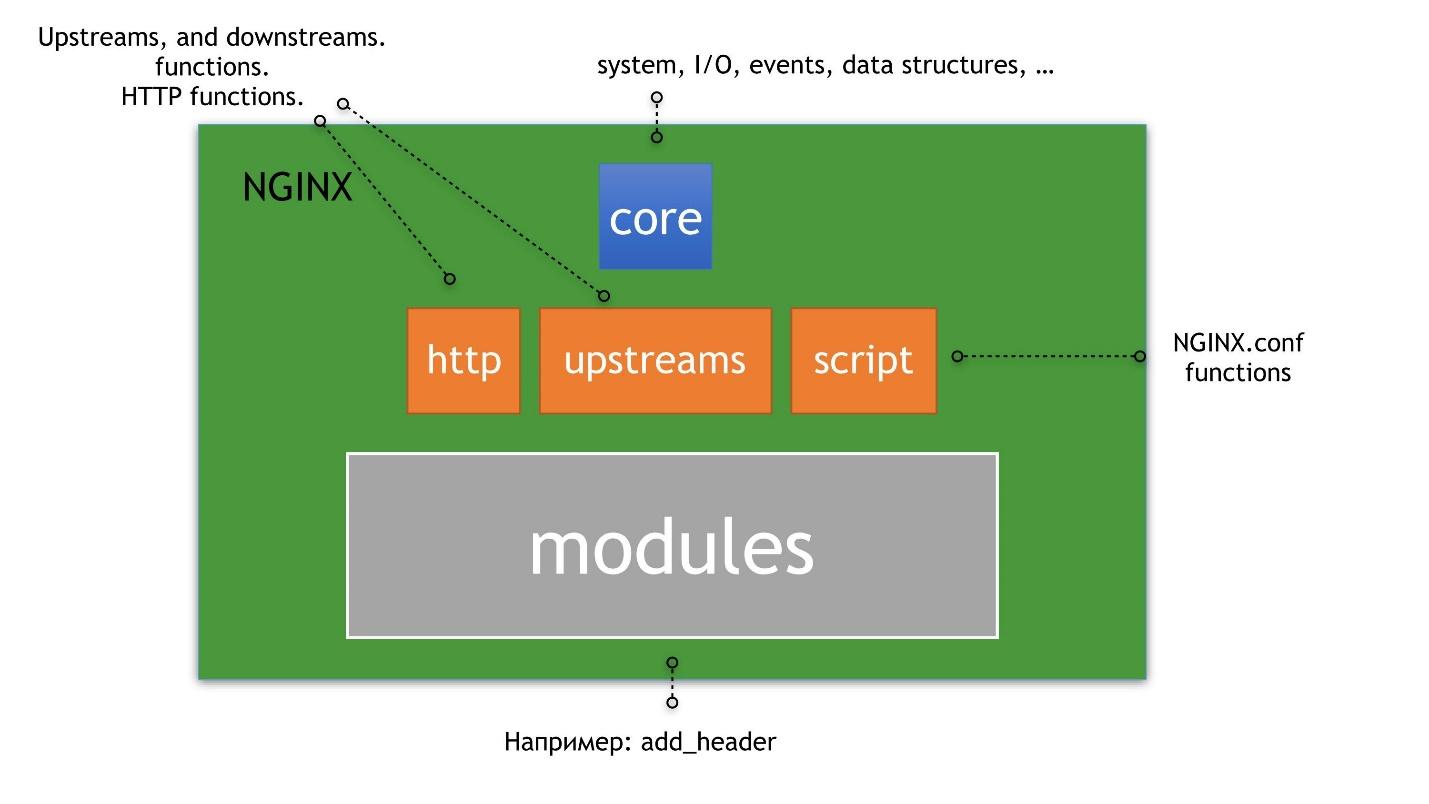
A classic example of upstreams and HTTP are upstream servers - directives inside the config. An example of modules for HTTP is add_header. An example of scripting is the config file itself. The file contains the modules that nginx consists of; it is interpreted somehow and allows you to do something as an administrator or as your user.
We will not consider core and dwell very briefly on upstreams, because it is a separate universe inside nginx. The story about them is worthy of several articles.
Anatomy of HTTP Modules
Even if you do not write C code inside nginx, but use it, remember the main rule.
In nginx, everything obeys the Chain of Responsibility - COR pattern.I don’t know how to translate this into Russian, but I will describe the logic. Your request goes through a galaxy of configured chain modules, starting from location. Each of these modules returns a result. If the result is bad, the chain is interrupted.

When developing modules or using some kind of directive in NJS and Lua, do not forget that your code may crash the execution of this chain.
The closest analogy to Chain of Responsibility is a line of Bash code:
grep -RI pool nginx | awk -F":" '{print $1}' | sort -u | wc -l
Everything is quite simple in the code: if AWK fell in the middle of the line, then
sort
and the following commands will fail. The nginx module works similarly, but the truth is in nginx and you can get around this - restart the code. But you should be prepared to crash and run, just like your modules that you use in the config, but not the fact that this is so.
Types of HTTP Modules
HTTP and nginx are a bunch of different PHASEs.
- Phase Handling - PHASE handlers .
- Filters - Body / Headers filters . This filtering is either Headers or request bodies.
- Proxies . Typical proxy modules are proxy_pass, fastcgi_pass, memcached_pass.
- Modules for specific load balancing - Load balancers . This is the most untwisted type of modules, they are few developed. An example is the Ketama CHash module, which allows you to do consistent hashing inside nginx to distribute requests to backends.
I will tell you about each of these types and their purpose.
Phase handlers
Imagine that we have several phases, starting from the access phase. There are several modules in each phase. For example, the ACCESS phase is divided into a connection, a request to nginx, verification of user authorization. Each module is a cell in the chain. There can be an infinite number of such modules in phase.
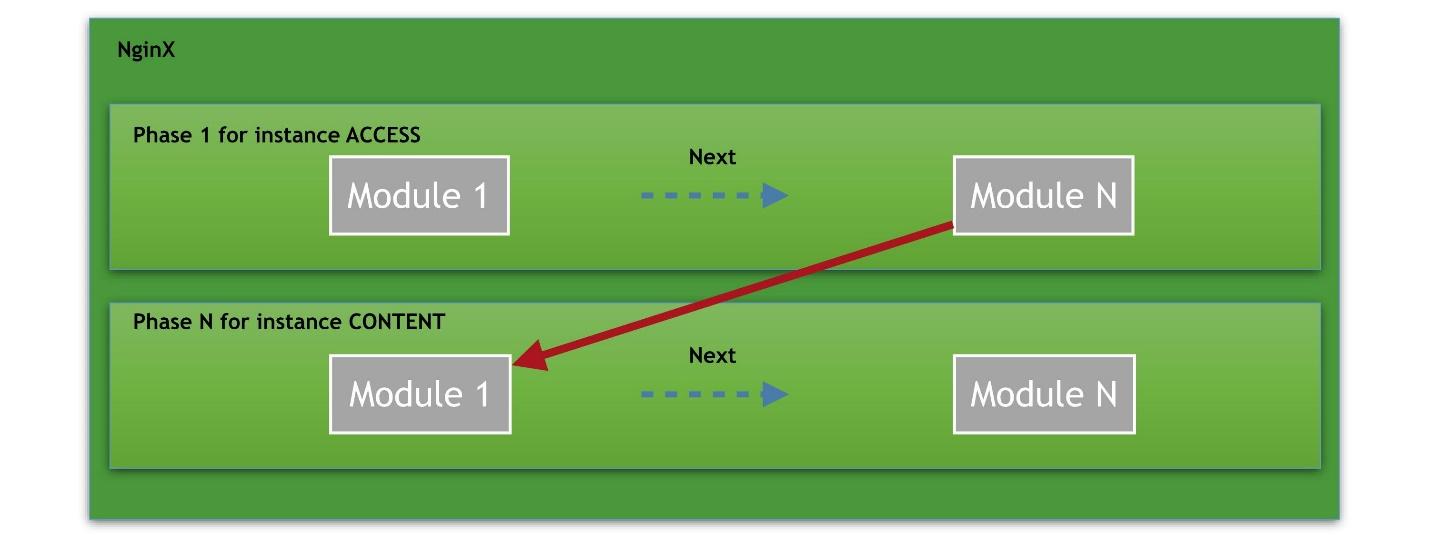
The last, final handler is the CONTENT phase in which content is delivered on demand.
The way is always this: request - a chain of handlers - output content.Phases that are available to developers of modules from the NGINX sources :
typedef enum { NGX_HTTP_POST_READ_PHASE = 0, NGX_HTTP_SERVER_REWRITE_PHASE, NGX_HTTP_FIND_CONFIG_PHASE, NGX_HTTP_REWRITE_PHASE, NGX_HTTP_POST_REWRITE_PHASE, NGX_HTTP_PREACCESS_PHASE, NGX_HTTP_ACESS_PHASE, NGX_HTTP_POST_ACESS_PHASE, NGX_HTTP_PRECONTENT_PHASE, NGX_HTTP_CONTENT_PHASE, NGX_HTTP_LOG_PHASE, } ngx_http_phases;
Phases can be overwritten, add your own handler. Not all of them are needed in real life, if you are not a nginx core developer. Therefore, I will not talk about each phase, but only about the main ones that I used.
The main one is ACCESS_PHASE. It is especially useful to add your authorization to nginx - to check the execution of the request in terms of access.
The next important phases that I often exploit are the phases of precontent and content. PRECONTENT_PHASE allows you to collect metrics about content that is about to be sent as a response to the client. CONTENT_PHASE allows you to generate your own unique content based on something.
The last phase that I often use is the logging phase LOG_PHASE. Incidentally, the ACCESS_LOG directive works in it. The logging phase has the wildest restrictions that drive me crazy: you cannot use subrequest and generally you cannot use any request. You have already left the content to the user, and handlers, posthandlers, and any subrequest will not be executed.
I will explain why it is annoying. Let's say when you want to cross nginx and Kafka in the logging phase. In this phase, everything has already been completed: there is a calculated content size, status, all data, but you can not do it subrequest. They do not work there. You have to write on bare sockets in the logging phase to send data to Kafka.
Body / Headers filters
There are two types of filters: Body filters and Headers filters.
An example of a Body filter is the gzip filter module. Why do you need Body filters? Imagine that you have a certain proxy_pass, and you want to somehow transform the content or analyze it. In this case, you should use the Body filter.
It works like this: many chunks come to you, you do something with them, look at the contents, aggregate, etc. But the filter also has significant limitations. For example, if you decide to change the body - to insert or cut out the response body, remember that HTTP attributes, for example, content tape, will be replaced. This can lead to strange effects if you do not provide for restrictions and correctly reflect in your code.
An example of a Header filter is the add_header that everyone has used. The algorithm works as in the Body filter. A response is prepared for the client, and the add_header filter allows you to do something there: add header, delete header, replace header, send subrequest.
By the way, in the Body filter and in the Header filter subrequests are available, you can even send internal identifications to an additional location.
Proxy
This is the most complex and controversial type of modules that allow you to proxy requests to external systems, for example, convert HTTP to another protocol . Examples: proxy_pass, redis_pass, tnt_pass.
Proxy is the interface that nginx core developers proposed to make writing proxy modules easier. If this is done in the classical way, then for such a proxy PHASES handlers, filters, Balancers will be executed. However, if the protocol you want to convert HTTP to is somehow different from the classics, then big problems begin. The proxy API that nginx gives is simply not suitable - you have to invent this proxy module from scratch.
A good example of such a module is postgres_pass. It allows nginx to communicate with PostgreSQL. The module does not use the interface that was developed in nginx at all - it has its own path.
Remember proxy, but preferably do not write. To write proxy, you have to learn all nginx by heart - it is very long and difficult.
Load balancers
The task of Load balancers is very simple - to work in round-robin mode. Imagine that you have an upstream section, some servers in it, you specify weights and balancing methods. This is a typical load balancer.
This mode is not always suitable. Therefore, the Ketama CHash module was developed, where it is conditionally possible to arrive at a consistent hash request to some server. Sometimes it’s convenient. Nginx Lua offers balancer_by_lua. You can write any balancer on Lua.
C modules
Next will be my absolutely subjective opinion on the development of C-modules. To begin with - my subjective rules.
The module starts with nginx.conf directives. Even if you are making a C-module that will only be operated in your company, always think about directives. Start designing the module with them, because this is what the system administrator will communicate with. This is important - coordinate all the nuances with him or with the person who will operate your C-module. NGINX is a well-known product, its directives obey certain laws that system administrators know. Therefore, always think about it.
Use nginx code style. Imagine that your module will be supported by another person. If he is already familiar with nginx and its code style, it will be much easier for him to read and understand your code.
Recently, a good friend from Germany asked me to help him deal with a bug inside his nginx code. I don’t know what code style he wrote it for, but I couldn’t even read the code normally.
Use the correct memory pool. Always keep this in mind, even if you have a lot of experience with nginx. A typical mistake of a novice C module developer for nginx is to get the wrong pool.
A little background: nginx generally uses the ideology of weak allocators. You can use malloc there, but not recommended. It has its own slabs, its own memory allocator, you need to use it. Accordingly, each object has a link to its pool, and this pool needs to be used. A typical novice mistake is to use a pool connection in the header filter, not a pool request. This means that if we have a keep-alive connection, the pool will swell until out of memory or other side effects occur. Therefore, it is important.
Moreover, such errors are extremely difficult to debug. Valgrind ("syshniks" will understand) does not work with slab allocation - it will show a strange picture.
Do not use blocking I / O. A typical mistake of those who want to apply something external faster is to use blocking I / O and blocking sockets. You can never do this in nginx - there are many processes in it, but each process uses one thread.
You can do multi-threading, but, as a rule, this only makes it worse. If you use blocking I / O in such an architecture, then everyone will be waiting for this blocking piece.
I will decrypt what I said above.
The module starts with nginx.conf directives
Decide in which osprey your directive should live: Main, Server, HTTP, location, location if.Try to avoid location if - as a rule, this leads to a very strange use of the nginx configuration.
All directives in nginx live in different contexts and in different scopes. The add_header directive can work on HTTP-level, on location-level, on location-if-level. This is usually described in the documentation.
Understand at what levels your directive can work, where the directive is executed: PHASE Handler, Body / Header filter.This is important because in nginx the config is frozen. By convention, when you write add_header somewhere above, this value is smoothed in the bottom add_header, which you already have in location. Accordingly, you will add two headers. This applies to any directive.
If you indicate something to the host port, then vice versa, the socket pool rises. This should be indicated once.
In general, I would forbid any merging - you just do not need it. Therefore, you should always clearly determine in which nginx arrays from the config your directive or set of directives lives.
Good example:
location /my_location/ { add_header “My-Header” “my value”; }
Here add_header is simply added to location. The same add_header could be somewhere above, and everything would simply be contorted. This is a documented and understandable behavior.
Think about what might hinder the implementation of the directive.Imagine you are developing a Body filter. As I said above, nginx just puts your module in a common chain, and you have no guarantee that the gzip module did not get into the chain in front of your Body filter at compile time. In this case, if someone turns on the gzip module, the data will come to your module for the gzip. This threatens that you simply cannot do anything with the content. You can re-gzip it, for example, but this is a mockery from the point of view of the CPU.
The same rules apply to all phase handlers - there is no guarantee who will be called before and who is after. Therefore, respect the one who will be called after, and remember that some gzip or something else may unexpectedly fly to you.
Nginx code style
When you created the product, remember that someone will support it. Do not forget about code style nginx.Before writing your nginx module, familiarize yourself with the source: one and the second .
If in the future you will be engaged in the development of nginx modules, then you will well know the sources of nginx. You will love them because there is no documentation . You will learn the nginx directory structure well, learn to use Grep, possibly Sed, when you need to transfer some pieces from nginx to your modules.
Memory pool
Pools must be used correctly. For example, "r-> connection-> pool! = R-> pool". In no case can you use the memory pool configuration when processing requests, it will swell until nginx restarts.
Understand the lifetime of the object. Suppose request replay has a lifetime of exactly this pipeline. In this pool you can place a lot of things and make room. Connection can live theoretically indefinitely - it is better to place something really important in it.
Try not to use external allocators, for example, malloc / free . This has a bad effect on memory fragmentation. If you operate with large amounts of data and use a lot of malloc, this nginx slows down pretty well.
For fans of Valgrind there is a hack that allows you to debug nginx-pools using Valgrind. This is important if you have a lot of nginx C code, because even an experienced memory developer may make a mistake.
Blocking I / O
Everything is simple here - do not use blocking I / O.Otherwise, at least there will be problems with keep-alive connections, but as a maximum, everything will work for a very long time.
I know the case when a person used Quora inside nginx in blocking mode (do not ask why). This led to the fact that keep-alive connections abandoned their activity and timed out all the time. It’s better not to do this - everything will work for a long time, inefficiently and you will immediately have to twist a million timeouts, because nginx will start timeout on many things.
But there is an alternative to C-modules - NJS and Lua.
When you do not need to develop C-modules
This year I had my first experience with NJS, I got a subjective impression on it, and I even realized what was missing there, so that everything was fine. I would also like to talk about my experience with Lua under nginx, and, moreover, share the problems that are present in Lua.
Lua / LuaJit Essentials
Nginx uses not Lua, but LuaJit. But this is not Lua, because Lua has already advanced two versions, and LuaJit is stuck somewhere in the past. The author practically does not develop LuaJit - he often lives in forks. The most current fork is LuaJit2 . This adds strange situations in the same OpenResty.
Garbage Collector needs attention . LuaJit can’t overcome this problem - just come up with some workarounds. With a huge load, when a lot of keep-alive Garbage Collector will be visible on the client with failures on the chart and 500 errors. There are many ways to deal with the Garbage Collector in Lua, I will not focus on them here. There is a lot of information about this on the Internet.
String implementation leads to performance issues . This is just the evil of LuaJit, and in Lua they fixed it. The implementation of strings in LuaJit simply defies any logic. Lines slow down in the wildest way, which is associated with internal implementation.
Inability to use many ready-made libraries . Lua is initially blocking, so most libraries on Lua and LuaJit use blocking I / O. Due to the fact that nginx is not blocking, it is impossible to use ready-made libraries inside nginx that use any blocking I / O. This will slow down nginx.
The reasons for using LuaJit are identical to the reasons for using modules:
- prototyping of complex modules;
- HMAC, SHA calculations for authorizations;
- balancers ;
- small applications: header processors, rules for redirects;
- computing variables for nginx.conf.
Where is it better not to use LuaJit?
The main rule: do not process a huge body on Lua - this does not work.Handlers for content on Lua do not work either . Try to minimize logic to a few
if
. A simple balancer will work, but a sidebar on Lua will work very poorly.
Shared memory or Garbage Collector will come. Do not use Shared memory with Lua - Garbage Collector will quickly and with guarantee take out the whole brain to production.
Do not use coroutines with lots of keep-alive compounds. Coroutines generate even more trash inside the LuaJit Garbage Collector, which is bad.
If you are already using LuaJit, then remember:
- about memory monitoring;
- on monitoring and optimizing the work of Garbage Collector;
- about how Garbage Collector works, if you did write a complicated application for LuaJit, because you have to add something new.
Njs
When I was at NGINX Conf, they convinced me that it would be cool not to write code in C. I thought I had to try, and that's what I got.
Authorization It works, the code is simple, it does not affect speed - everything is great. My little prototype I started with is 10 lines of code. But these 10 lines do authorization with s3.
Computing variables for nginx.conf. Many variables can be calculated using NJS. Inside nginx, this is cool. There is such a feature in Lua, but there is a Garbage Collector, so it’s not so cool.
However, not everything is so good. To do really cool things on NJS, he misses a few things.
Shared Memory . I patched Shared Memory, this is my own fork, so now it’s enough.
Filters supporting more phases . In NJS there is only a content phase and variables, and the header filter is very lacking. You have to write crutches to add a lot of headers. There is not enough body filter for complex logic or work with content.
Information on how to monitor and profile it . I now know how, but I had to study the source. There is not enough information or tools about the proper profiling. If it is, it is hidden where not to be found. At the same point, there is not enough information about where I can use NJS and where I can not?
C-modules . I had a desire to expand NJS.
Afterword
Why create your own modules? To solve general and business problems.
When do I need to implement modules in C? If there are no other options. For example, a heavy load, insertion of content or basic savings on hardware. Then this must be done guaranteed in C. In most cases, Lua or NJS is suitable. But we must always think ahead.
And on Lua? When you can not write in C. For example, you do not need to convert the request body with huge RPS. Your number of customers is growing, at some point you will cease to cope - think about it.
NJS? When LuaJit is completely fed up with its Garbage Collector and strings. For example, authorization generated many Garbage objects on Lua, but this was not critical. However, this was reflected in the monitoring and annoying. Now it has ceased to appear in my monitoring, and everything has become good.
At HighLoad ++ 2019, Vasily Soshnikov will continue the topic of nginx modules and talk more about NJS, not forgetting the comparison with LuaJit and C.
See the full list of reports on the website, and see you on November 7 and 8 at the largest conference for developers of highly loaded systems. Follow our new ideas in the newsletter and telegram channel .