Acceleration instagram.com. Part 2
Today we bring to your attention the translation of the second material from the series dedicated to instagram.com optimization. Here we will talk about improving the mechanism for early execution of GraphQL queries and increasing the efficiency of transmitting HTML data to the client.

→ Read with bated breath, the first part
In the first part, we talked about how, using pre-loading mechanisms, to start executing queries in the early stages of page processing. That is - even before the script that initiates such requests is loaded. Given this, it can be noted that the execution of these requests at the preloading stage of the materials still meant that their execution did not start before the rendering of the HTML page on the client. And this, in turn, meant that the request could not be started before the client sent the server a request and the server responded to this request (here you also need to add the time it takes the server to generate an HTML response to the client). In the next figure, you can see that the start of a GraphQL query can be quite delayed. And this is - given that we begin to perform such requests using the code located in the
HTML tag, and that this is one of the first tasks that we solve using data preloading tools.

Request pre-execution begins with a noticeable delay
In theory, the start of the execution of such a GraphQL query would ideally look at the moment when a request to load the corresponding page was sent to the server. But how to make the browser start loading something even before it receives at least some HTML code from the server? The answer is to send the resource to the browser at the initiative of the server. It might seem that to implement such a mechanism, you will need something like HTTP / 2 Server Push. But, in fact, there is a very old technology (which is often forgotten) that allows you to implement a similar scheme of interaction between the client and server. This technology is distinguished by universal browser support, for its implementation you do not need to delve into the infrastructural complexities that are typical for implementing HTTP / 2 Server Push. Facebook has been using this technology since 2010 (read about BigPipe ), and on other sites like Ebay, it also finds application in various forms. But there is a feeling that JavaScript developers of single-page applications basically either ignore this technology or simply do not use it. It's about progressively loading HTML. This technology is known under various names: “early flush”, “head flushing”, “progressive HTML”. It works thanks to a combination of two mechanisms:
The chunked transfer encoding mechanism appeared in HTTP / 1.1. It allows you to split HTTP responses into many small parts that are transmitted to the browser in streaming mode. The browser “fastens” these parts as they arrive, forming the complete response code from them. Although this approach provides for significant changes in the way pages are formed on the server, most languages and frameworks support the delivery of such answers, broken into parts. Instagram web frontends use Django, so we use the StreamingHttpResponse object. The reason why using such a mechanism can be beneficial is that it allows you to send the HTML content of the page to the browser in streaming mode as individual parts of the page are ready, rather than waiting until the full page code is ready. This means that we can flush the browser’s page title almost instantly after receiving the request (hence the term “early flush”). Header preparation does not require particularly large server resources. This allows the browser to start loading scripts and styles even when the server is busy generating dynamic data for the rest of the page. Let’s take a look at what effect this technique has. This is what a normal page load looks like.

Early flush technology is not used: resource loading does not start until the page HTML is fully loaded
But what happens if the server, upon receipt of the request, immediately passes the page title to the browser.

Early flush technology is used: resources start loading immediately after HTML tags are reset to the browser
In addition, we can use the mechanism of sending HTTP messages in parts to send data to the client as they are ready. In the case of applications that are rendered on the server, this data can be presented in the form of HTML code. But if we are talking about single-page applications like instagram.com, the server can also transmit something like JSON data to the client. In order to take a look at how this works, let's take a look at the simplest example of starting a single-page application.
First, the original HTML markup is sent to the browser containing the JavaScript code needed to render the page. After parsing and executing this script, an XHR request will be executed, loading the source data necessary for rendering the page.

The process of loading a page in a situation where the browser independently requests from the server everything that it needs
This process involves several situations in which the client sends a request to the server and waits for a response from it. As a result, there are periods when both the server and the client are inactive. Instead of waiting for the server to wait for the API request from the client, it would be more efficient if the server started working on preparing an API response immediately after the HTML code was generated. After the answer was ready, the server could, on its own initiative, poison it to the client. This would mean that by the time the client had prepared everything that was needed to visualize the data that was previously loaded after the API request was completed, this data would most likely have been ready. In this case, the client would not have to fulfill a separate request to the server and wait for a response from it.
The first step in implementing such a client-server interaction scheme is to create a JSON cache designed to store server responses. We developed this part of the system using a small script block embedded in the HTML code of the page. It plays the role of a cache and contains information about requests that will be added to the cache by the server (this, in a simplified form, is shown below).
After resetting the HTML code to the browser, the server can independently execute API requests. After receiving answers to these requests, the server will dump JSON data to the page in the form of a script tag containing this data. When the browser receives and parses a similar fragment of the HTML code of the page, this will lead to the fact that the data will fall into the JSON cache. The most important thing here is that the browser will display the page progressively - as it receives fragments of the response (that is, finished blocks of scripts will be executed as they arrive in the browser). This means that it is quite possible to simultaneously generate large amounts of data on the server and drop script blocks onto the page as soon as the corresponding data is ready. These scripts will be immediately executed on the client. This is the foundation of the BigPipe system used by Facebook. There, many independent pagers are loaded in parallel on the server and transmitted to the client as they become available.
When the client script is ready to request the data it needs, instead of executing the XHR request, it first checks the JSON cache. If the cache already has the query results, the script immediately gets what it needs. If the request is in progress, the script is waiting for the results.
All this leads to the fact that the process of loading the page becomes the same as in the following diagram.
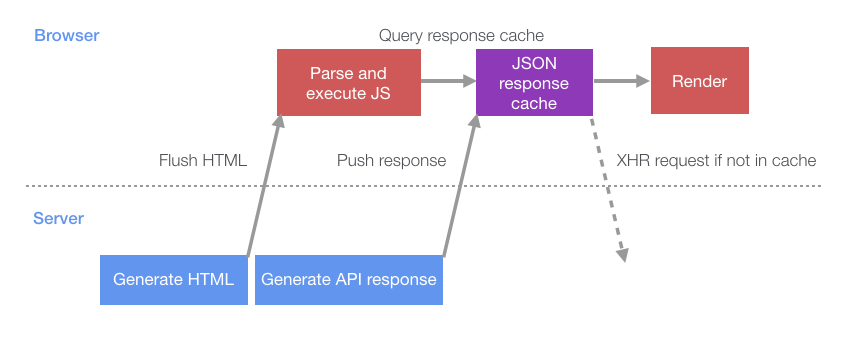
The process of loading a page in a situation where the browser is actively involved in preparing data for the client
If you compare this with the easiest way to load pages, it turns out that the server and client can now perform more tasks in parallel. This reduces downtime during which the server and client wait for each other.
This optimization has had a very positive effect on our system. So, in desktop browsers, page loading began to complete 14% faster than before. And in mobile browsers (due to longer delays in mobile networks) the page began to load 23% faster.
Dear readers! Do you plan to apply the methodology for optimizing the formation of web pages discussed here in your projects?


→ Read with bated breath, the first part
Server-initiated data submission to the client using progressive HTML download technology
In the first part, we talked about how, using pre-loading mechanisms, to start executing queries in the early stages of page processing. That is - even before the script that initiates such requests is loaded. Given this, it can be noted that the execution of these requests at the preloading stage of the materials still meant that their execution did not start before the rendering of the HTML page on the client. And this, in turn, meant that the request could not be started before the client sent the server a request and the server responded to this request (here you also need to add the time it takes the server to generate an HTML response to the client). In the next figure, you can see that the start of a GraphQL query can be quite delayed. And this is - given that we begin to perform such requests using the code located in the
<head>
HTML tag, and that this is one of the first tasks that we solve using data preloading tools.
Request pre-execution begins with a noticeable delay
In theory, the start of the execution of such a GraphQL query would ideally look at the moment when a request to load the corresponding page was sent to the server. But how to make the browser start loading something even before it receives at least some HTML code from the server? The answer is to send the resource to the browser at the initiative of the server. It might seem that to implement such a mechanism, you will need something like HTTP / 2 Server Push. But, in fact, there is a very old technology (which is often forgotten) that allows you to implement a similar scheme of interaction between the client and server. This technology is distinguished by universal browser support, for its implementation you do not need to delve into the infrastructural complexities that are typical for implementing HTTP / 2 Server Push. Facebook has been using this technology since 2010 (read about BigPipe ), and on other sites like Ebay, it also finds application in various forms. But there is a feeling that JavaScript developers of single-page applications basically either ignore this technology or simply do not use it. It's about progressively loading HTML. This technology is known under various names: “early flush”, “head flushing”, “progressive HTML”. It works thanks to a combination of two mechanisms:
- The first is HTTP chunked transfer encoding.
- The second is the progressive rendering of HTML in the browser.
The chunked transfer encoding mechanism appeared in HTTP / 1.1. It allows you to split HTTP responses into many small parts that are transmitted to the browser in streaming mode. The browser “fastens” these parts as they arrive, forming the complete response code from them. Although this approach provides for significant changes in the way pages are formed on the server, most languages and frameworks support the delivery of such answers, broken into parts. Instagram web frontends use Django, so we use the StreamingHttpResponse object. The reason why using such a mechanism can be beneficial is that it allows you to send the HTML content of the page to the browser in streaming mode as individual parts of the page are ready, rather than waiting until the full page code is ready. This means that we can flush the browser’s page title almost instantly after receiving the request (hence the term “early flush”). Header preparation does not require particularly large server resources. This allows the browser to start loading scripts and styles even when the server is busy generating dynamic data for the rest of the page. Let’s take a look at what effect this technique has. This is what a normal page load looks like.
Early flush technology is not used: resource loading does not start until the page HTML is fully loaded
But what happens if the server, upon receipt of the request, immediately passes the page title to the browser.
Early flush technology is used: resources start loading immediately after HTML tags are reset to the browser
In addition, we can use the mechanism of sending HTTP messages in parts to send data to the client as they are ready. In the case of applications that are rendered on the server, this data can be presented in the form of HTML code. But if we are talking about single-page applications like instagram.com, the server can also transmit something like JSON data to the client. In order to take a look at how this works, let's take a look at the simplest example of starting a single-page application.
First, the original HTML markup is sent to the browser containing the JavaScript code needed to render the page. After parsing and executing this script, an XHR request will be executed, loading the source data necessary for rendering the page.
The process of loading a page in a situation where the browser independently requests from the server everything that it needs
This process involves several situations in which the client sends a request to the server and waits for a response from it. As a result, there are periods when both the server and the client are inactive. Instead of waiting for the server to wait for the API request from the client, it would be more efficient if the server started working on preparing an API response immediately after the HTML code was generated. After the answer was ready, the server could, on its own initiative, poison it to the client. This would mean that by the time the client had prepared everything that was needed to visualize the data that was previously loaded after the API request was completed, this data would most likely have been ready. In this case, the client would not have to fulfill a separate request to the server and wait for a response from it.
The first step in implementing such a client-server interaction scheme is to create a JSON cache designed to store server responses. We developed this part of the system using a small script block embedded in the HTML code of the page. It plays the role of a cache and contains information about requests that will be added to the cache by the server (this, in a simplified form, is shown below).
<script type="text/javascript"> // API, , // , , // window.__data = { '/my/api/path': { waiting: [], } }; window.__dataLoaded = function(path, data) { const cacheEntry = window.__data[path]; if (cacheEntry) { cacheEntry.data = data; for (var i = 0;i < cacheEntry.waiting.length; ++i) { cacheEntry.waiting[i].resolve(cacheEntry.data); } cacheEntry.waiting = []; } }; </script>
After resetting the HTML code to the browser, the server can independently execute API requests. After receiving answers to these requests, the server will dump JSON data to the page in the form of a script tag containing this data. When the browser receives and parses a similar fragment of the HTML code of the page, this will lead to the fact that the data will fall into the JSON cache. The most important thing here is that the browser will display the page progressively - as it receives fragments of the response (that is, finished blocks of scripts will be executed as they arrive in the browser). This means that it is quite possible to simultaneously generate large amounts of data on the server and drop script blocks onto the page as soon as the corresponding data is ready. These scripts will be immediately executed on the client. This is the foundation of the BigPipe system used by Facebook. There, many independent pagers are loaded in parallel on the server and transmitted to the client as they become available.
<script type="text/javascript"> window.__dataLoaded('/my/api/path', { // JSON- API, , // JSON-... }); </script>
When the client script is ready to request the data it needs, instead of executing the XHR request, it first checks the JSON cache. If the cache already has the query results, the script immediately gets what it needs. If the request is in progress, the script is waiting for the results.
function queryAPI(path) { const cacheEntry = window.__data[path]; if (!cacheEntry) { // XHR- API return fetch(path); } else if (cacheEntry.data) { // return Promise.resolve(cacheEntry.data); } else { // , // // const waiting = {}; cacheEntry.waiting.push(waiting); return new Promise((resolve) => { waiting.resolve = resolve; }); } }
All this leads to the fact that the process of loading the page becomes the same as in the following diagram.
The process of loading a page in a situation where the browser is actively involved in preparing data for the client
If you compare this with the easiest way to load pages, it turns out that the server and client can now perform more tasks in parallel. This reduces downtime during which the server and client wait for each other.
This optimization has had a very positive effect on our system. So, in desktop browsers, page loading began to complete 14% faster than before. And in mobile browsers (due to longer delays in mobile networks) the page began to load 23% faster.
Dear readers! Do you plan to apply the methodology for optimizing the formation of web pages discussed here in your projects?
All Articles