Service Workers in Slack Client: On Download Acceleration and Offline Mode
The material, the translation of which we publish today, is dedicated to the story about optimizing the new version of the Slack desktop client, one of the central features of which was the acceleration of loading.

At the beginning of work on the new version of the Slack desktop client, a prototype was created, which was called “speedy boots”. The goal of this prototype, as you might guess, was to accelerate the download as much as possible. Using the HTML file from the CDN cache, the Redux repository data stored in advance, and the service worker, we were able to download the light version of the client in less than a second (at that time, the usual load time for users with 1-2 workspaces was about 5 seconds ) The service worker was the center of this acceleration. In addition, he paved the way for opportunities that we often asked Slack users to implement. We are talking about the offline mode of the client. The prototype allowed us to literally see with one eye what the converted client can be capable of. Based on the above technologies, we started processing the Slack client, roughly imagining the result and focusing on speeding up the download and implementing the offline mode of the program. Let's talk about how the core of the updated client works.
Service Worker is essentially a powerful proxy object for network requests, which allows the developer, using a small amount of JavaScript code, to control how the browser handles individual HTTP requests. Service workers support an advanced and flexible caching API, which is designed so that Request objects are used as keys and Response objects are used as values. Service workers, as well as Web workers, are executed in their own processes, outside the main JavaScript code execution thread of any browser window.
Service Worker is a follower of Application Cache , which is now deprecated. It was a set of APIs represented by the
interface, which was used to create sites that implement offline features. When working with
, a static manifest file was used that describes the files that the developer would like to cache for offline use. By and large,
capabilities
limited to this. This mechanism was simple, but not flexible, which did not give the developer special control over the cache. At W3C, this was taken into account when developing the Service Worker specification . As a result, service workers allow the developer to manage many details regarding each network interaction session performed by a web application or website.
When we first started working with this technology, Chrome was the only browser supporting it, but we knew that there was not much time to wait for broad support for service workers. Now this technology is everywhere , it supports all major browsers.
When a user launches a new Slack client for the first time, we download a full set of resources (HTML, JavaScript, CSS, fonts and sounds) and place them in the service worker’s cache. In addition, we create a copy of the Redux repository located in memory and write this copy to the IndexedDB database. When the program is launched next time, we check for the presence of corresponding caches. If they are, we use them when downloading the application. If the user is connected to the Internet, we download the latest data after launching the application. If not, the client remains operational.
In order to distinguish between the above two options for loading the client - we gave them the names: hot (warm) and cold (cold) download. A client’s cold boot most often occurs when the user launches the program for the very first time. In this situation, there are no cached resources or Redux data stored. With a hot boot, we have everything you need to run the Slack client on the user's computer. Please note that most binary resources (images, PDFs, videos, and so on) are processed using the browser cache (these resources are controlled by regular caching headers). A service worker should not process them in a special way so that we can work with them offline.
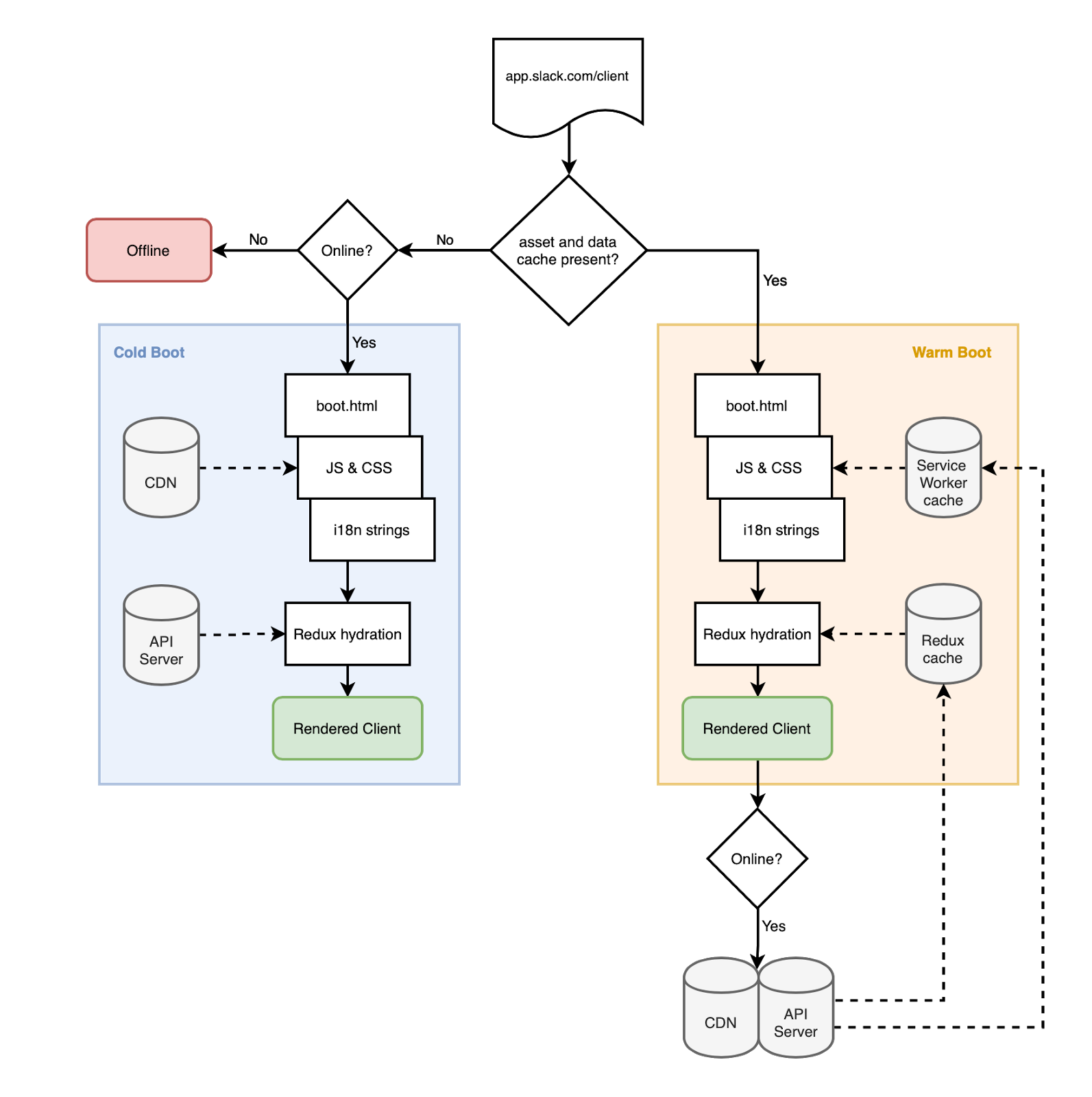
The choice between hot and cold loading
Service workers can handle three life cycle events. These are install , fetch and activate . Below we will talk about how we respond to each of these events, but first we need to talk about downloading and registering the service worker itself. Its life cycle depends on how the browser handles service worker file updates. Here's what you can read about it on MDN : “Installation is done if the downloaded file is recognized as new. This can be either a file that differs from the existing one (the difference between the files is determined by comparing them by byte), or a service worker file that was first encountered by the browser on the page being processed. ”
Each time we update the corresponding JavaScript, CSS or HTML file, it goes through the custom Webpack plugin, which creates a manifest with a description of the corresponding files with unique hashes ( here is an abbreviated example of a manifest file). This manifest is embedded in the service worker code, which causes the service worker to be updated at the next boot. Moreover, this is done even when the implementation of the service worker does not change.
Whenever a service worker updates, we get an
event. In response to it, we go through the files whose descriptions are contained in the manifest built into the service worker, load each of them and place them in the corresponding cache block. File storage is organized using the new Cache API, which is part of the Service Worker specification. This API stores
objects using
objects as keys. As a result, it turns out that the storage is amazingly simple. It goes well with how service worker events receive requests and return responses.
Keys to cache blocks are assigned based on the deployment time of the solution. The time stamp is embedded in the HTML code, as a result, it can be sent, as part of the file name, in the request to download each resource. Separate caching of resources from each deployment is important in order to avoid sharing incompatible resources. Thanks to this, we can be sure that the initially downloaded HTML file will only download compatible resources, and this is true both when they are downloaded over the network and when they are downloaded from the cache.
After the service worker is registered, it will begin to process all network requests belonging to the same source. The developer cannot make it so that some requests are processed by a service worker, while others are not. But the developer has full control over what exactly needs to be done with the requests received by the service worker.
When processing a request, we first examine it. If what is requested is present in the manifest and is in the cache, we return the response to the request by taking the data from the cache. If there isn’t what is needed in the cache, we return a real network request that accesses the real network resource as if the service worker was not involved in this process at all. Here is a simplified version of our
event handler:
In reality, such code contains much more Slack-specific logic, but the core of our handler is as simple as in this example.

When analyzing network interactions, the answers returned from the service worker can be recognized by the ServiceWorker mark in the column indicating the amount of data
The
event is raised after the successful installation of a new or updated service worker. We use it to analyze cached resources and invalidate cache blocks that are older than 7 days. This is a good practice of maintaining the system in order, and in addition, it allows you to ensure that too old resources are not used when loading the client.
You may have noticed that our implementation implies that anyone who starts the Slack client after the very first launch of the client will receive not the latest, but cached resources loaded during the previous registration of the service worker. In the original client implementation, we tried to update the service worker after each download. However, a typical Slack user may, for example, download a program only once a day, in the morning. This can lead to the fact that he will constantly work with a client whose code for the whole day lags behind the latest release (we release new releases several times a day).
Unlike a typical website, which, upon visiting, is quickly abandoned, the Slack client on the user's computer is open for hours and is in an open state. As a result, our code has a rather long lifespan, which requires us to use special approaches to maintain its relevance.
At the same time, we strive to ensure that users work with the latest versions of the code, so that they receive the latest features, bug fixes, and performance improvements. Shortly after we released a new client, we implemented a mechanism in it that allows us to narrow the gap between what users are working with and what we have released. If, after the last update, a new version of the system was deployed, we load fresh resources that will be used the next time the client boots. If nothing new can be found, then nothing is loaded. After this change was made to the client, the average “life” time of the resources with which the client was loaded was halved.
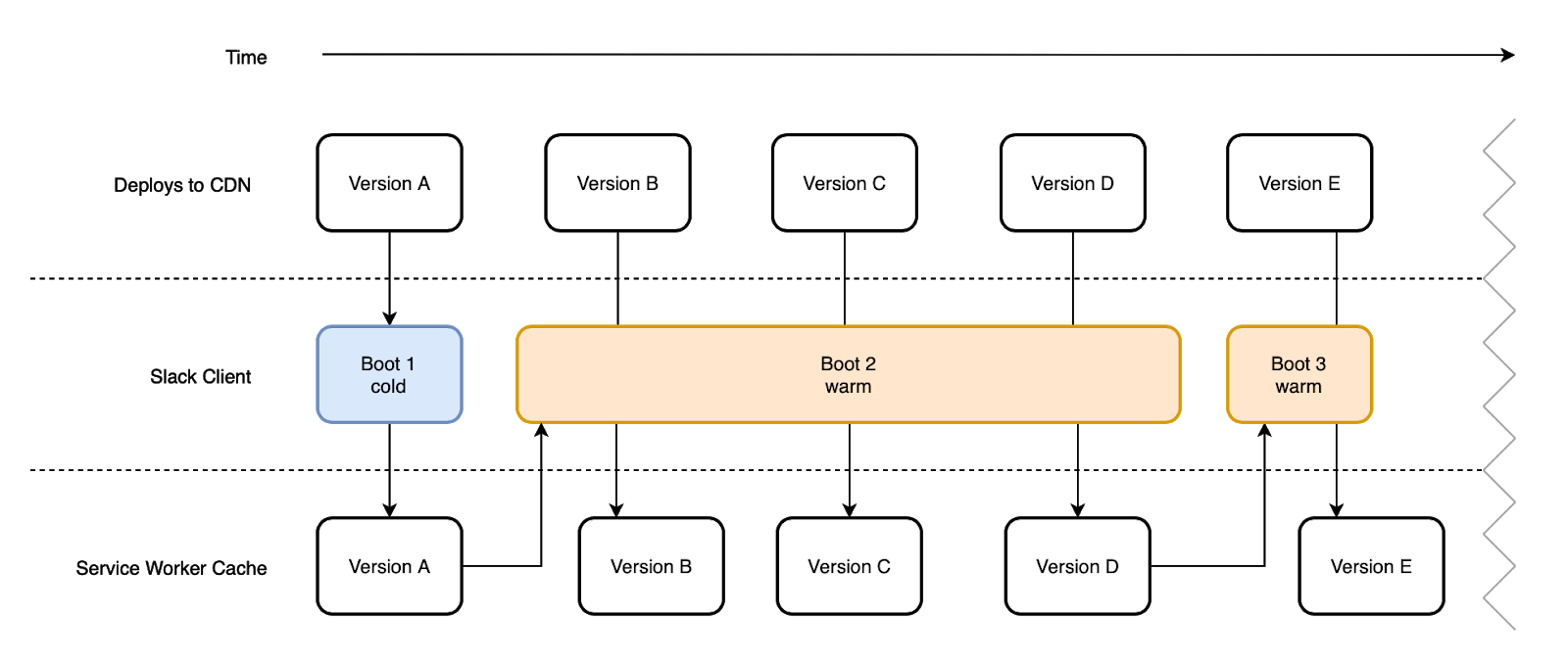
New versions of the code are downloaded regularly, but only the latest version is used when downloading the program
With the help of flags of new features (Feature Flags) we mark in the code base that work on which has not yet been completed. This allows us to include new features in the code before their public releases. This approach reduces the risk of errors in production due to the fact that new features can be freely tested along with the rest of the application, doing this long before the work on them is completed.
New features in Slack are usually released when they make changes to the corresponding APIs. Before we started using service workers, we had a guarantee that new features and changes in the API would always be synchronized. But after we began to use the cache, which may not contain the latest version of the code, it turned out that the client may be in a situation where the code is not synchronized with the backend capabilities. In order to cope with this problem, we cache not only resources, but also some API responses.
The fact that service workers process absolutely all network requests has simplified the solution. With each update of the service worker, we, among other things, execute API requests, caching responses in the same cache block as the corresponding resources. This connects the capabilities and experimental functions with the right resources - potentially obsolete, but guaranteed to be consistent with each other.
This, in fact, is only the tip of the iceberg of opportunities available to the developer thanks to service workers. A problem that could not be solved using the
mechanism, or one that would require both client and server mechanisms to be resolved, is simply and naturally solved using service workers and the Cache API.
The service worker accelerated the loading of the Slack client by organizing local storage of resources that are ready for use the next time the client boots. The network - the main source of delays and ambiguities that our users might encounter, now has virtually no effect on the situation. We, so to speak, removed it from the equation. And if you can remove the network from the equation, then it turns out that you can implement offline functionality in the project. Our support for offline mode is very straightforward right now. The user can download the client and can read messages from downloaded conversations. The system at the same time prepares for synchronization marks on read messages. But now we have a basis for the future implementation of more advanced mechanisms.
After many months of development, experimentation and optimization, we learned a lot about how service workers work in practice. In addition, it turned out that this technology is well suited for large-scale projects. In less than a month since the client’s public release with a service worker, we successfully serve tens of millions of requests daily from millions of installed service workers. This led to about a 50% reduction in the loading time of new customers compared to old ones, and to the fact that hot loading is about 25% faster than cold.
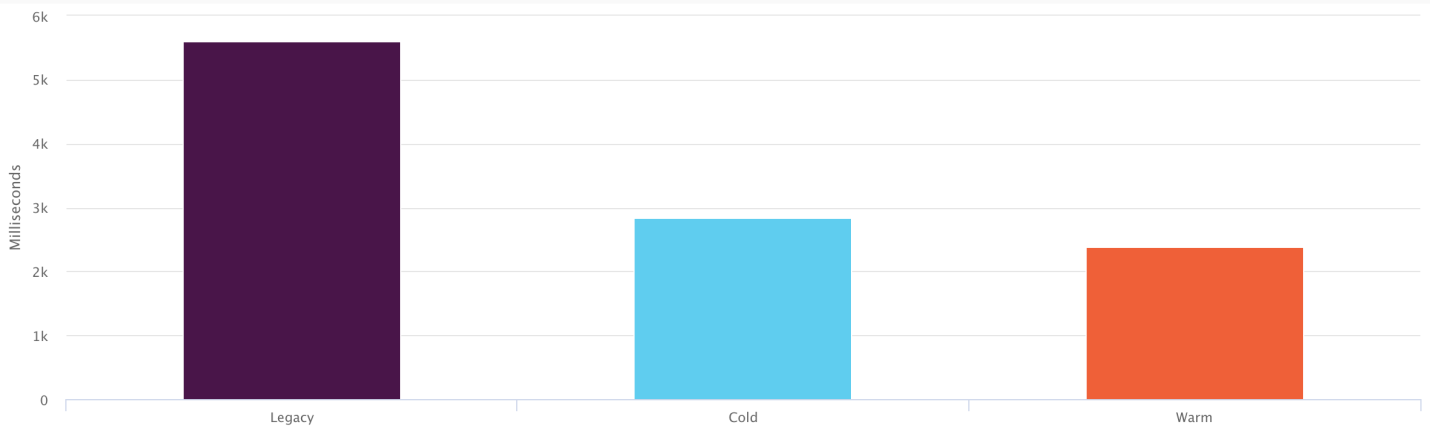
From left to right: loading an old client, cold loading a new client, hot loading a new client (the lower the indicator, the better)
Dear readers! Do you use service workers in your projects?


Background
At the beginning of work on the new version of the Slack desktop client, a prototype was created, which was called “speedy boots”. The goal of this prototype, as you might guess, was to accelerate the download as much as possible. Using the HTML file from the CDN cache, the Redux repository data stored in advance, and the service worker, we were able to download the light version of the client in less than a second (at that time, the usual load time for users with 1-2 workspaces was about 5 seconds ) The service worker was the center of this acceleration. In addition, he paved the way for opportunities that we often asked Slack users to implement. We are talking about the offline mode of the client. The prototype allowed us to literally see with one eye what the converted client can be capable of. Based on the above technologies, we started processing the Slack client, roughly imagining the result and focusing on speeding up the download and implementing the offline mode of the program. Let's talk about how the core of the updated client works.
What is a service worker?
Service Worker is essentially a powerful proxy object for network requests, which allows the developer, using a small amount of JavaScript code, to control how the browser handles individual HTTP requests. Service workers support an advanced and flexible caching API, which is designed so that Request objects are used as keys and Response objects are used as values. Service workers, as well as Web workers, are executed in their own processes, outside the main JavaScript code execution thread of any browser window.
Service Worker is a follower of Application Cache , which is now deprecated. It was a set of APIs represented by the
AppCache
interface, which was used to create sites that implement offline features. When working with
AppCache
, a static manifest file was used that describes the files that the developer would like to cache for offline use. By and large,
AppCache
capabilities
AppCache
limited to this. This mechanism was simple, but not flexible, which did not give the developer special control over the cache. At W3C, this was taken into account when developing the Service Worker specification . As a result, service workers allow the developer to manage many details regarding each network interaction session performed by a web application or website.
When we first started working with this technology, Chrome was the only browser supporting it, but we knew that there was not much time to wait for broad support for service workers. Now this technology is everywhere , it supports all major browsers.
How we use service workers
When a user launches a new Slack client for the first time, we download a full set of resources (HTML, JavaScript, CSS, fonts and sounds) and place them in the service worker’s cache. In addition, we create a copy of the Redux repository located in memory and write this copy to the IndexedDB database. When the program is launched next time, we check for the presence of corresponding caches. If they are, we use them when downloading the application. If the user is connected to the Internet, we download the latest data after launching the application. If not, the client remains operational.
In order to distinguish between the above two options for loading the client - we gave them the names: hot (warm) and cold (cold) download. A client’s cold boot most often occurs when the user launches the program for the very first time. In this situation, there are no cached resources or Redux data stored. With a hot boot, we have everything you need to run the Slack client on the user's computer. Please note that most binary resources (images, PDFs, videos, and so on) are processed using the browser cache (these resources are controlled by regular caching headers). A service worker should not process them in a special way so that we can work with them offline.
The choice between hot and cold loading
Service Worker Life Cycle
Service workers can handle three life cycle events. These are install , fetch and activate . Below we will talk about how we respond to each of these events, but first we need to talk about downloading and registering the service worker itself. Its life cycle depends on how the browser handles service worker file updates. Here's what you can read about it on MDN : “Installation is done if the downloaded file is recognized as new. This can be either a file that differs from the existing one (the difference between the files is determined by comparing them by byte), or a service worker file that was first encountered by the browser on the page being processed. ”
Each time we update the corresponding JavaScript, CSS or HTML file, it goes through the custom Webpack plugin, which creates a manifest with a description of the corresponding files with unique hashes ( here is an abbreviated example of a manifest file). This manifest is embedded in the service worker code, which causes the service worker to be updated at the next boot. Moreover, this is done even when the implementation of the service worker does not change.
▍Event install
Whenever a service worker updates, we get an
install
event. In response to it, we go through the files whose descriptions are contained in the manifest built into the service worker, load each of them and place them in the corresponding cache block. File storage is organized using the new Cache API, which is part of the Service Worker specification. This API stores
Response
objects using
Request
objects as keys. As a result, it turns out that the storage is amazingly simple. It goes well with how service worker events receive requests and return responses.
Keys to cache blocks are assigned based on the deployment time of the solution. The time stamp is embedded in the HTML code, as a result, it can be sent, as part of the file name, in the request to download each resource. Separate caching of resources from each deployment is important in order to avoid sharing incompatible resources. Thanks to this, we can be sure that the initially downloaded HTML file will only download compatible resources, and this is true both when they are downloaded over the network and when they are downloaded from the cache.
▍Event fetch
After the service worker is registered, it will begin to process all network requests belonging to the same source. The developer cannot make it so that some requests are processed by a service worker, while others are not. But the developer has full control over what exactly needs to be done with the requests received by the service worker.
When processing a request, we first examine it. If what is requested is present in the manifest and is in the cache, we return the response to the request by taking the data from the cache. If there isn’t what is needed in the cache, we return a real network request that accesses the real network resource as if the service worker was not involved in this process at all. Here is a simplified version of our
fetch
event handler:
self.addEventListener('fetch', (e) => { if (assetManifest.includes(e.request.url) { e.respondWith( caches .open(cacheKey) .then(cache => cache.match(e.request)) .then(response => { if (response) return response; return fetch(e.request); }); ); } else { e.respondWith(fetch(e.request)); } });
In reality, such code contains much more Slack-specific logic, but the core of our handler is as simple as in this example.
When analyzing network interactions, the answers returned from the service worker can be recognized by the ServiceWorker mark in the column indicating the amount of data
▍Event activate
The
activate
event is raised after the successful installation of a new or updated service worker. We use it to analyze cached resources and invalidate cache blocks that are older than 7 days. This is a good practice of maintaining the system in order, and in addition, it allows you to ensure that too old resources are not used when loading the client.
Client code lagging behind the latest release
You may have noticed that our implementation implies that anyone who starts the Slack client after the very first launch of the client will receive not the latest, but cached resources loaded during the previous registration of the service worker. In the original client implementation, we tried to update the service worker after each download. However, a typical Slack user may, for example, download a program only once a day, in the morning. This can lead to the fact that he will constantly work with a client whose code for the whole day lags behind the latest release (we release new releases several times a day).
Unlike a typical website, which, upon visiting, is quickly abandoned, the Slack client on the user's computer is open for hours and is in an open state. As a result, our code has a rather long lifespan, which requires us to use special approaches to maintain its relevance.
At the same time, we strive to ensure that users work with the latest versions of the code, so that they receive the latest features, bug fixes, and performance improvements. Shortly after we released a new client, we implemented a mechanism in it that allows us to narrow the gap between what users are working with and what we have released. If, after the last update, a new version of the system was deployed, we load fresh resources that will be used the next time the client boots. If nothing new can be found, then nothing is loaded. After this change was made to the client, the average “life” time of the resources with which the client was loaded was halved.
New versions of the code are downloaded regularly, but only the latest version is used when downloading the program
New Feature Flags Sync
With the help of flags of new features (Feature Flags) we mark in the code base that work on which has not yet been completed. This allows us to include new features in the code before their public releases. This approach reduces the risk of errors in production due to the fact that new features can be freely tested along with the rest of the application, doing this long before the work on them is completed.
New features in Slack are usually released when they make changes to the corresponding APIs. Before we started using service workers, we had a guarantee that new features and changes in the API would always be synchronized. But after we began to use the cache, which may not contain the latest version of the code, it turned out that the client may be in a situation where the code is not synchronized with the backend capabilities. In order to cope with this problem, we cache not only resources, but also some API responses.
The fact that service workers process absolutely all network requests has simplified the solution. With each update of the service worker, we, among other things, execute API requests, caching responses in the same cache block as the corresponding resources. This connects the capabilities and experimental functions with the right resources - potentially obsolete, but guaranteed to be consistent with each other.
This, in fact, is only the tip of the iceberg of opportunities available to the developer thanks to service workers. A problem that could not be solved using the
AppCache
mechanism, or one that would require both client and server mechanisms to be resolved, is simply and naturally solved using service workers and the Cache API.
Summary
The service worker accelerated the loading of the Slack client by organizing local storage of resources that are ready for use the next time the client boots. The network - the main source of delays and ambiguities that our users might encounter, now has virtually no effect on the situation. We, so to speak, removed it from the equation. And if you can remove the network from the equation, then it turns out that you can implement offline functionality in the project. Our support for offline mode is very straightforward right now. The user can download the client and can read messages from downloaded conversations. The system at the same time prepares for synchronization marks on read messages. But now we have a basis for the future implementation of more advanced mechanisms.
After many months of development, experimentation and optimization, we learned a lot about how service workers work in practice. In addition, it turned out that this technology is well suited for large-scale projects. In less than a month since the client’s public release with a service worker, we successfully serve tens of millions of requests daily from millions of installed service workers. This led to about a 50% reduction in the loading time of new customers compared to old ones, and to the fact that hot loading is about 25% faster than cold.
From left to right: loading an old client, cold loading a new client, hot loading a new client (the lower the indicator, the better)
Dear readers! Do you use service workers in your projects?
All Articles