Ultimate comparison of embedded platforms for AI
Neural grids take over the world. They count visitors, monitor quality, keep statistics and evaluate safety. A bunch of startups, industrial use.
Great frameworks. What is PyTorch, what is the second TensorFlow. Everything is becoming more convenient and convenient, simpler and simpler ...
But there is one dark side. They try to keep silent about her. There is nothing joyful there, only darkness and despair. Every time you see a positive article, you sigh sadly, because you understand that just a person did not understand something. Or hid it.
Let's talk about production on embedded devices.

It would seem. Look at the device’s performance, make sure that it’s enough, run it and get a profit.
But, as always, there are a couple of nuances. Let's put them in shelves:
Let’s take it in order, it doesn’t taste sweet ... What now is there and is suitable for neurons? There are not so many options, despite their variability. A few general words to limit the search:
So. The main things that are clearly embeding. In the article we will compare precisely them:

Misc. We will talk about them after the main comparisons:
We have been working with Jetson for a very long time. Back in 2014, Vasyutka invented mathematics for the then Swift precisely on Jetson. In 2015, at a meeting with Artec 3D, we talked about what a cool platform it is, after which they suggested that we build a prototype based on it. After a couple of months, the prototype was ready. Just a couple of years of work of the entire company, a couple of years of curses on the platform and heaven ... And Artec Leo was born - the coolest scanner in its class. Even Nvidia at the presentation of TX2 showed him as one of the most interesting projects created on the platform.
Since then, TX1 / TX2 / Nano we used somewhere in 5-6 projects.
And, probably, we know all the problems that were with the platform. Let's take it in order.
I won’t especially talk about him. The platform was very efficient in computing power on its day. But she was not grocery. NVIDIA sold the TegraTK1 chips that underpinned Jetson. But these chips were impossible to use for small and medium-sized manufacturers. In reality, only Google / HTC / Xiaomi / Acer / Google could do something on them except Nvidia. All the others integrated into the prod either debug boards or looted other devices.
Nvidia made the right conclusions, and the next generation was done awesomely. TX1 | TX2, these are no longer chips, but a chip on the board.


They are more expensive, but have a completely grocery level. A small company can integrate them into its product, this product is predictable and stable. I personally saw how 3-4 products were brought to production - and everything was good.
I will talk about TX2, because from the current line it is the main board.
But, of course, not all thank God. What's wrong:
What's awesome:
As a result, this is a good platform for you if you have piece devices, but for some reason you cannot put a full-fledged computer. Something massive? Biometrics - most likely not. Number recognition is on the edge, depending on the flow. Portable devices with a price of over 5k bucks - possible. Cars - no, it’s easier to put a more powerful platform a little more expensive.
It seems to me that with the release of a new generation of cheap TX2 devices, it will die over time.
Motherboards for Jetson TX1 | TX2 | TX2i and others look something like this:

And here or here there are more variations.

Jetson Nano is a very interesting thing. For Nvidia, this is a new form factor that, in terms of revolution, would have to compare with the TK1. But competitors are already running out. There are other devices that we’ll talk about. It is 2 times weaker than TX2, but 4 times cheaper. More precisely ... Math is complicated. Jetson Nano on the demo board costs 100 bucks (in Europe). But if you buy only a chip, then it will be more expensive. And you will need to breed him (there is no motherboard for him yet). And, God forbid, it will be 2 times cheaper on a large party than TX2.
In essence, Jetson Nano, on its base board, is such an advertising product for institutes / resellers / amateurs, which should spur interest and business application. By pluses and minuses (partially intersects with TX2):
Good:
Nano itself came out in early spring, somewhere from April / May, I actively poked at it. We have already managed to make two projects on them. In general, the problems identified above. As a hobby product / product for small batches - very cool. But whether it is possible to drag in production and how to do it is not yet clear.
We will be comparing with other devices much later. In the meantime, just talk about Jetson and speed. Why Nvidia is lying to us. How to optimize your projects.
Below everything is written about TensorRT-5.1. TensorRT-6.0.1 was released on September 17, 2019, all statements must be double-checked there.
Let's assume we believe Nvidia. Let's open their website and see the time of inference of SSD-mobilenet-v2 to 300 * 300:
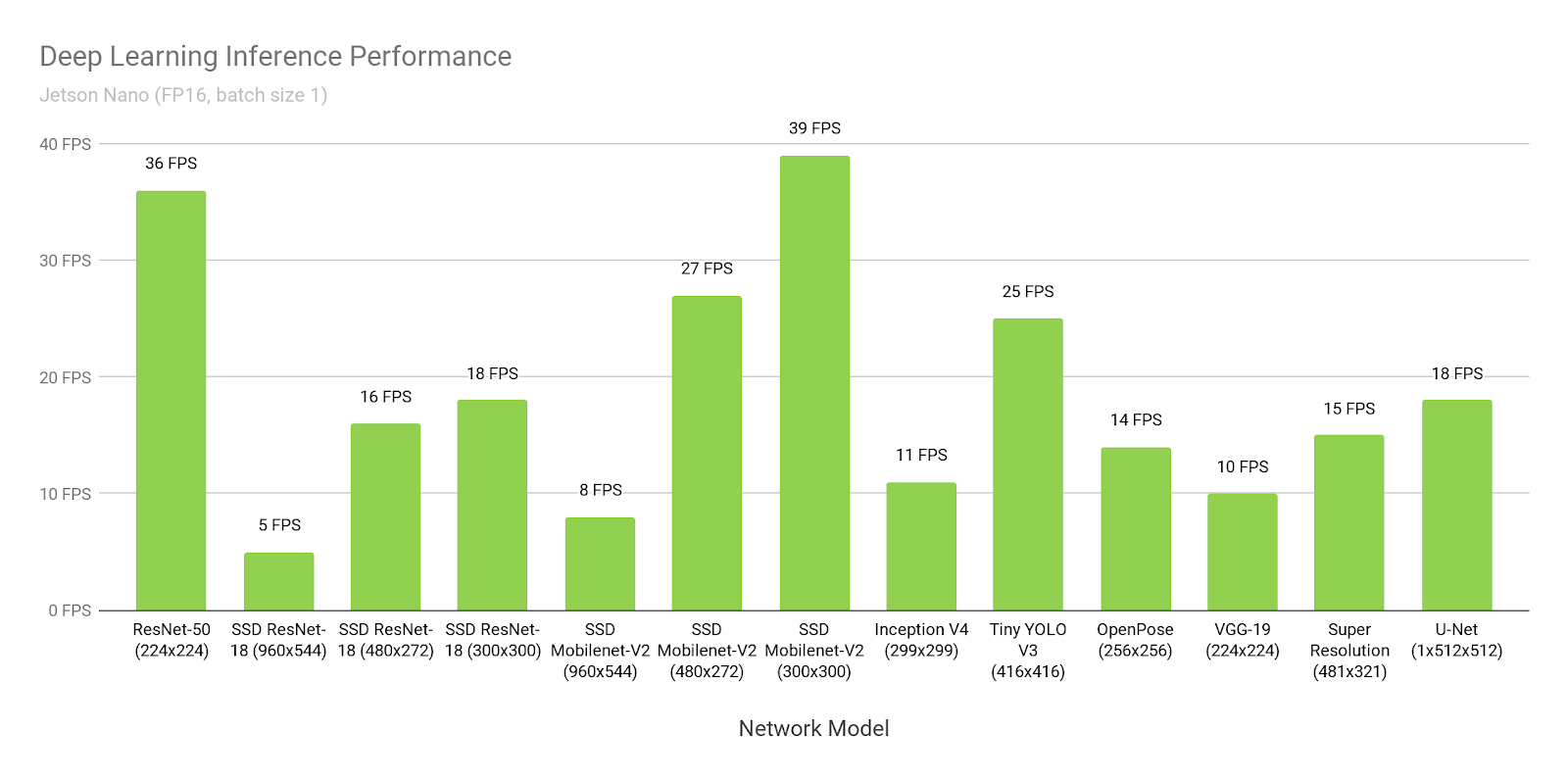
Wow, 39FPS (25ms). Yes, and the source code is laid out !
Hmm ... But why is it written here about 46ms?
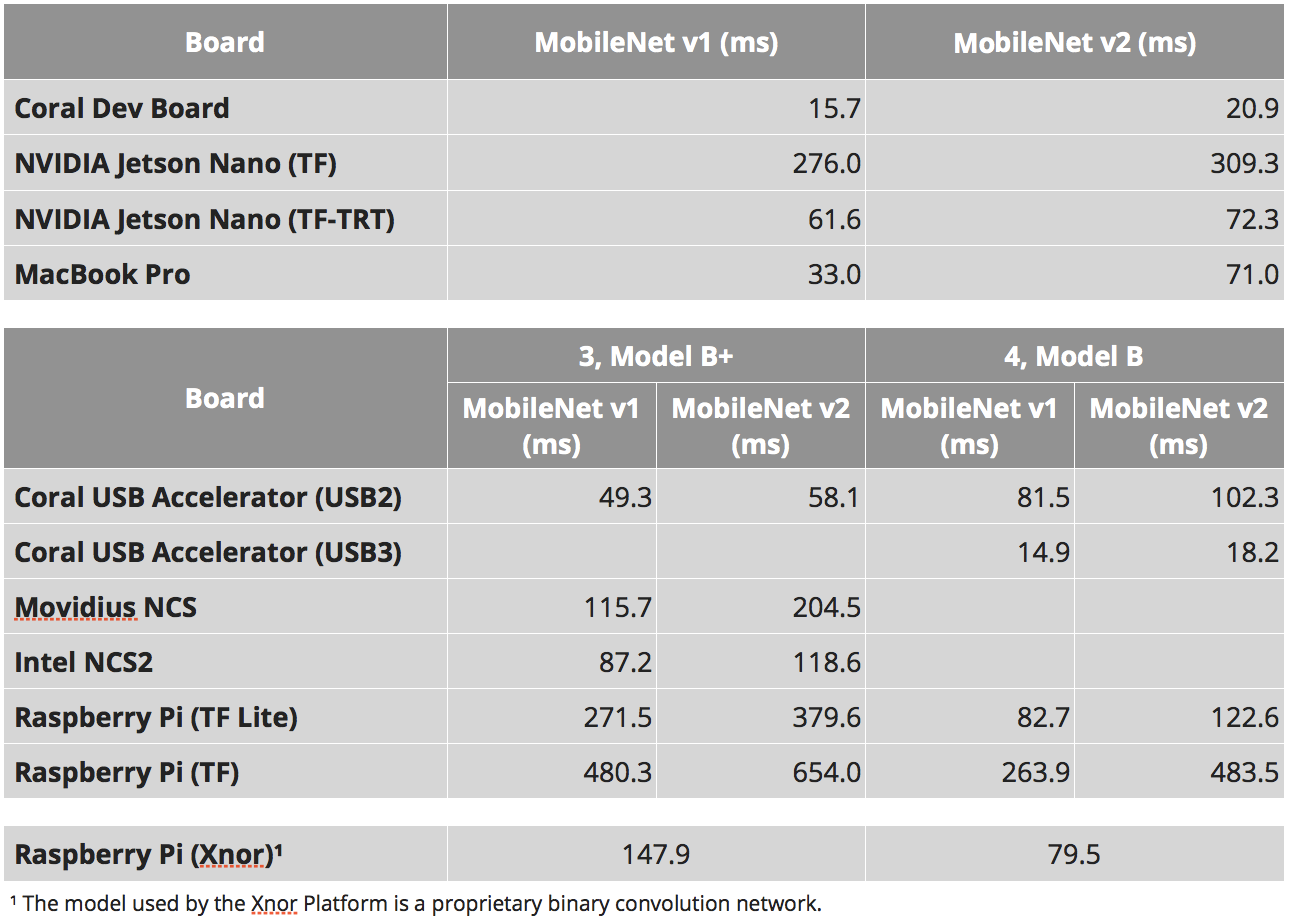
Wait ... And here they write that 309 ms is native, and 72ms is ported ...
Where is the truth?
The truth is that everyone thinks very different:
In the examples above:
You need to understand for yourself that if it were your neuron, which no one would have converted before you, then without problems you would be able to launch it at a speed of 72ms. And at a speed of 46 ms, sitting over the manuals and sorsa day-week.
Compared to many other options, this is very good. But don’t forget that whatever you do - never believe the NVIDIA benchmarks!
Production? .. I just hear dozens of engineers start laughing at the mention of the words “RPI” and “production” nearby. But, I have to say - RPI is still more stable than Jetson Nano and Google Coral. But, of course, TX2 loses and, apparently, gyrfalcone.

(The picture is from here . It seems to me that attaching fans to the RPi4 is a separate folk amusement.)
From the whole list, this is the only device that I did not hold in my hands / did not test. But he started up neurons on Rpi, Rpi2, Rpi3 (for example, he told me here ). In general, Rpi4, as I understand it, differs only in performance. It seems to me that the pros and cons of RPi know everything, but still. Minuses:
Pros:
We'll talk about Rpi speed at the end. Since the manufacturer does not postulate that his product for neurons, there are few benchmarks. Everyone understands that Rpi is not perfect in speed. But even he is suitable for some tasks.
We had a couple of semi-product tasks that we implemented at Rpi. The impression was pleasant.

From here and below, not full-fledged processors will go, but processors designed specifically for neural networks. It is as if their strengths and weaknesses at the same time.
So. Movidius. The company was bought by Intel in 2016. In the segment of interest to us, the company released two products, Movidius and Movidius 2. The second is faster, we will only talk about the second.
No, not like that. The conversation should not begin with Movidius, but with Intel OpenVino . I would say that this is ideology. More specifically, the framework. In fact, this is a set of pre-trained neurons and inferences to them, which are optimized for Intel products (processors, GPUs, special computers). Integrated with OpenCV, with the Raspberry Pi, with a bunch of other whistles and farts.
The advantage of OpenVino is that it has a lot of neurons. First of all, the most famous detectors. Neurons for recognition of people, persons, numbers, letters, poses, etc., etc. ( 1 , 2 , 3 ). And they are trained. Not by open datasets, but by datasets compiled by Intel itself. They are much larger / more diverse and better open. They can be retrained according to your cases, then they will work generally cool.
Is it possible to do better? Sure. For example, the recognition of numbers that we did - worked significantly better. But we spent many years on developing it and understanding how to make it perfect. And here you can get the fucking quality out of the box, which is enough for most cases.
OpenVino, of course, has several problems. Grids there do not appear immediately. If something new comes out, you have to wait a long time. Nets there appear deep grocery. You will not find any GANs there. Only deep benefit. And, in our experience, it’s quite difficult to overtake the grid there if you have any tricks in architecture that are different from harsh standards. But the guys overtook some , even quite complex models:

It seems to me that Intel with its OpenVino has chosen a very interesting strategy. They are in the role of a constant catch-up. But one who, after catching up, spreads any. At that moment, when everything is squeezed out of the neurons, Intel will come and capture the finished market. Already, in 70% of tasks, you can build a solution based on OpenVino.
And as part of this strategy, Movidius looks like its logical complement. This is the device on which you need to interest all this wealth. Most grids are optimized specifically for it (sometimes even to binary architecture, which is very fast).
Globally, he has one minus. USB is, damn it, not a food connector !!! You cannot make a device with USB. There is an exit. Intel sells chips. Even something like that is on sale on the last generation ( 1 , 2 )
It seems like there are products on it. But I have not seen a single product board on which to develop something. And no familiar small-medium-sized company has begun to develop anything based on this chip.
On the other hand, what will happen to the tank? .. It will still catch up with us and crush us :)
Oh yes, and out of joy. OpenVino, as I understand it, is being developed in Russia, in Nizhny Novgorod (it seems to me that half of Computer Vision is done there). Here Sergey tells about him:
(the report is more likely about AI 2.0, but there are a lot about OpenVino).
Okay, almost everything has been said. Short extract by Movidius 2. Cons:
Pros:
We ourselves did not use it in any project. All our friends who tested it for inference tasks - as a result, they did not take it into production.
But a couple of companies that I advised, where there were tasks of the level “we need to put 20-30 cameras on barriers, but we don’t want to buy anything, we will develop it ourselves” - it seems like in the end they took it Movidius.
Intel recently announced a new platform. But so far there is no detailed information, let's see.

UPD
They sent a link to this . Fee with two second movidius. It’s quite an embedded format. Many people use the PCI-e bus for this. To such things is only a matter of price. Two movidius - it is unlikely that such a thing will be cheaper than $ 200 cost. And you will also need your own board with your system ...
I am disappointed. No, there is nothing that I would not predict. But I'm disappointed that Google decided to release this. Testing is a miracle in the beginning of summer. Maybe something has changed since then, but I will describe my experience of that time.
Setting up ... To flash Jetson Tk-Tx1-Tx2 you had to plug it into the host computer and into the power supply. And that was enough. To flash Jetson Nano and RPi, you just need to push the image onto the USB flash drive.
And to flash Coral, you need to stick three wires in the correct order :

And do not try to make a mistake! By the way, there are errors / indescribable behavior in the guide. Probably I will not describe them, since from the beginning of the summer they could fix something. I remember that after installing Mendel any access via ssh was lost, including the one described by them, I had to manually edit some Linux configs.
It took me 2-3 hours to complete this process.
OK. Launched. Do you think it's easy to run your grid on it? Almost nothing :)
Here is a list of what you can let go.
To be honest, I did not get to this point quickly. Spent half a day. No really. You cannot download the model from the TF repository and run on the device. Or there it is necessary to cross-cut all layers. I did not find instructions.
So here. It is necessary to take the model from the repository from above. There are not many of them (3 models have been added since the beginning of summer). And how to train her? Open in TensorFlow in a standard pipeline? HAHAHAHAHAHAHAHA. Of course not!!!
You have a special Doker container , and the model will train only in it. (Probably, you can somehow mock your TF as well ... But there are instructions, instructions ... which weren’t and don't seem to be.)
Download / Install / Launch. What is it ... Why is the GPU at zero? .. BECAUSE TRAINING WILL BE ON THE CPU. Docker is only for him !!! Want some more fun?The manual says “based on a 6-core CPU with 64G memory workstation”. It seems that this is only advice? May be.Only now I didn’t have enough of my 8 gigs on that server where most of the models train. Training at the 4-th hour consumed them all. A strong feeling that they had something flowing. I tried a couple of days with different parameters on different machines, the effect was one.
I did not double-check this before posting the article. To be honest, it was enough for me once.
What else to add? That this code does not generate a model? To generate it you must:

This is the greatest disgust I have experienced in relation to an IT product over the past year ...
Globally, Coral should have the same ideology as OpenVino with Movidius. Only now Intel has been on this path for several years. With excellent manuals, support and good products ... And Google. Well, it's just Google ...
Minuses:
Pros:

The last one and a half years have been talking about this Chinese beast. Even a year ago I was saying something about him. But talking is one thing, and giving information is another. I talked with 3-4 large companies, where project managers / directors told me how cool this Girfalkon was. But they did not have any documentation. And they did not see him alive. The site has almost no information. Download from the site at least something can only partners (hardware developers). Moreover, the information on the site is very contradictory. In one place they write that they support only VGG , in another that only their neurons are based on GNet (which they assurevery small and really without loss of accuracy). In the third it is written that everything is converted with TF | Caffe | PyTorch, and in the fourth it is written about the mobile phone and other charms.
Understanding the truth is almost impossible. Once I was digging and digging a few videos in which at least some numbers slip:
If this is true, then it means that SSD (on mobile?) Under 224 * 224 on the GTI2801 chip they have ~ 60ms, which is quite comparable with movidius.
It seems like they have a much faster chip 2803, but information on it is even less:
This summer we got a board from firefly in our hands ( this module is installed there for calculations).
There was a hope that finally we would see alive. But it didn’t work out. The board was visible, but did not work. Crawling through individual English phrases in the Chinese documentation, they almost even understood what the problem was (the initial knurled system did not support the neural module, it was necessary to rebuild and re-roll everything ourselves). But it just didn’t work out, and there were already suspicions that the board did not fit our task (2GB of RAM is very small for neural networks + systems. In addition, there was no support for two networks at the same time).
But I managed to see the original documentation. From it, too little is understood (Chinese). For good, you had to test and look at the source.
RockChip tech support stupidly scored on us.
Despite this horror, it is clear to me that here, all the same, RockChip's jambs are here first of all. And I have a hope that in a normal board Gyrfalcon can be quite used. But due to lack of information, it’s hard for me to say.
Minuses:
Pros:
In short, the conclusion is this: very little information. You can’t only lay on this platform. And before you do something on it - you need to make a huge review.
I really like how 90% of comparisons of embedded devices reduce to speed comparisons. As you understood above, this characteristic is very arbitrary. For Jetson Nano, you can run neurons as pure tensorflow, you can use tensorflow-tensorrt, or you can use pure tensorrt. Devices with special tensor architecture (movidius | coral | gyrfalcone) - can be fast, but in the first place they can work only with standard architectures. Even for the Raspberry Pi, everything is not so simple. Neurons from xnor.ai give one and a half times acceleration. But I don’t know how honest they are, and what was gained by switching to int8 or other jokes.
At the same time, one more interesting thing is such a moment. The more complex the neuron, the more complex the device for inference - the more unpredictable the final acceleration that can be pulled out. Take some OpenPose. There is a nontrivial network, complex post-processing. Both this and that can be optimized due to:
Sometimes someone is trying to evaluate something is for all possible combinations. But really, as it seems to me, this is futile. First you need to decide on the platform, and only then try to completely pull out everything that is possible.
Why am I all this. Besides, the “ how long MobileNet ” test is a very bad test. He can tell that platform X is optimal. But when you try to deploy your neuron and post-processing there, you may be very disappointed.
But comparing mobilnet'ov still gives some information about the platform. For simple tasks. For situations where you understand that it’s still easier to reduce the task to standard approaches. When you want to evaluate the speed of the calculator.
The table below is taken from several places:
As a result, we have:

I’ll try to bring everything that I said above to a single table. I highlighted in yellow those places where my knowledge is not enough to make a definite conclusion. And, actually 1-6 - this is some comparative assessment of the platforms. The closer to 1, the better.

I know that for many people energy consumption is critical. But it seems to me that everything here is somewhat ambiguous, and I understand this too poorly - so I did not enter it. Moreover, ideology itself seems to be the same everywhere.
What we were talking about is just a small point in the vast space of variations of your system. Probably the common words that can characterize this area:
But, globally, if you reduce the significance of one of the criteria, you can add many other devices to the list. Below I will go through all the approaches that I have met.
As we said when we discussed Movidius, Intel has an OpenVino platform. It allows very efficient processing of neurons on Intel processors. At the same time, the platform allows you to support even all sorts of intel-gpu on a chip. I'm now afraid to say for sure what kind of performance there is for which tasks. But, as I understand it, a good stone with a GPU on board quite ⅓ gives a performance of 1080. For some tasks it can even be faster.

In this case, the form factor, for example Intel NUC, is quite compact. Good cooling, packaging, etc. The speed will be faster than the Jetson TX2. By accessibility / ease of purchase - much easier. The stability of the platform out of the box is higher.
Cons two - power consumption and price. Development is a little more complicated.

This is another jetson. Essentially the oldest version. The speed is about 2 times faster than Jetson TX2 plus there is support for int8 computing, which allows you to overclock another 4 times. By the way, check out this picture from Nvidia:
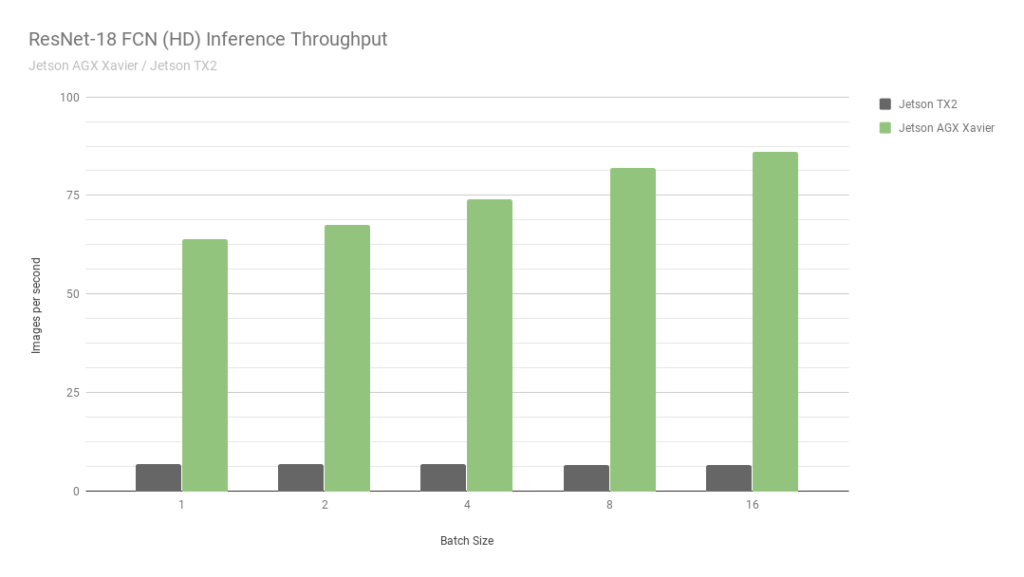
They compare two of their own Jetson. One in int8, the second in int32. I don’t even know what words to say here ... In short: “NEVER BELIEVE NVIDIA GRAPHICS”.
Despite the fact that AGX is good - it does not reach the normal GPUs from Nvidia in terms of computing power. Nevertheless, in terms of energy efficiency - they are very cool. The main minus the price.
We ourselves did not work with them, so it’s hard for me to say something more detailed, to describe the range of tasks where they are the most optimal.
If you remove the strict restriction on energy consumption, then Jetson TX2 does not look optimal. Like the AGX. Usually people are scared to use the GPU in production. Separate payment, all that.
But there are millions of companies that offer you to assemble a custom solution on one board. Usually these are boards for laptops / minicomputers. Or, in the end, like this :

One of the startups in which I have been working for the last 2.5 years ( CherryHome ) has taken exactly this path. And we are very satisfied.
Minus, as usual, in energy consumption, which was not critical for us. Well, the price bites a bit.
I do not want to go deep into this topic. To tell everything that is in modern mobile phones for neurons / which frameworks / which hardware, etc., you will need more than one article with this size. And taking into account the fact that we poked in this direction only 2-3 times, I consider myself incompetent for this. So just a couple of observations:
It seems to me that for embedded mobile phones is not the best solution (the exception is some low-budget face recognition systems). But I saw a couple of cases when they were used as early prototypes.
Was recently at a Usedata conference. And there one of the reports was about the inference of neurons at the cheapest percentages (GAP8). And, as they say, the need for inventions is cunning. In the story, an example was very far-fetched. But the author told how they were able to achieve inference by face in about a second. On a very simple grid, essentially without a detector. By crazy and long optimizations and savings on matches.
I always don’t like such tasks. No research, only blood.
But, it’s worth recognizing that I can imagine puzzles where low-consuming percentages give a cool result. Probably not for face recognition. But somewhere where you can recognize the input image in 5-10 seconds ...

While preparing this article, I came across this embedded platform. There is very little information on it. As I understand it, zero support. Productivity is also at zero ... And not a single test on speed ...
Every time they come to us for advice on an embedded platform, I want to shout “run, you fools!”. It is necessary to carefully assess the need for such a solution. Check out any other options. Everyone and always, I advise you to do a prototype with server architecture. And during its operation it is up to you to decide whether to implement a real embedded. After all, embedded is:
Yes, I know that there are tasks where server decisions cannot be made. But, oddly enough, they are much smaller than is commonly believed.
In the article, I tried to do without obvious conclusions. It is rather a story about what is now. To draw conclusions - it is necessary to investigate in each case. And not only platforms. But the task itself. Any task can be simplified a little / slightly modified / slightly sharpened under the device.
The problem with this topic is that the topic is changing. New devices / frameworks / approaches are coming. For example, if NVIDIA turns on int8 support for Jetson Nano tomorrow, the situation will change dramatically. When I write this article - I can’t be sure that the information has not changed two days ago. But I hope that my short story will help you better navigate your next project.
It would be cool if you have additional information / I missed something / said something wrong - write the details here.
ps
Already when I finished writing the article almost, snakers4 dropped a recent post from his telegram channel Spark in me, which is almost about the same problems with Jetson. But, as I wrote above, - in conditions of any power consumption - I would put something like zotacs or IntelNUC. And as embedded jetson is not the worst platform.

Great frameworks. What is PyTorch, what is the second TensorFlow. Everything is becoming more convenient and convenient, simpler and simpler ...
But there is one dark side. They try to keep silent about her. There is nothing joyful there, only darkness and despair. Every time you see a positive article, you sigh sadly, because you understand that just a person did not understand something. Or hid it.
Let's talk about production on embedded devices.
What is the problem.
It would seem. Look at the device’s performance, make sure that it’s enough, run it and get a profit.
But, as always, there are a couple of nuances. Let's put them in shelves:
- Production. If your device is not made in single copies, then you need to be sure that the system does not hang, that the devices will not overheat, that if the power goes out, everything will automatically boot. And this is on a big party. This gives only two options - either the device should be fully designed taking into account all possible problems. Or you need to overcome the problems of the source device. Well, for example, these are ( 1 , 2 ). Which, of course, is tin. To solve the problems of someone else’s device in large batches, an unrealistic amount of energy must be spent.
- Real benchmarks. A lot of scam and tricks. NVIDIA in most examples overestimates performance by 30-40%. But not only she has fun. Below I give many examples when productivity can be 4-5 times less than you want. You can’t get laid "everything worked well on the computer, it will be proportionally worse here."
- Very limited support for neural network architecture. There are many embedded hardware platforms that greatly restrict the networks that can be run on them (Coral, gyrfalcone, snapdragon). Porting to such platforms will be painful.
- Support. Something does not work for you, but the problem is on the side of the device? .. This is fate, it will not work. For RPi only, the community shuts up most of the bugs. And, in part, for Jetson.
- Price. It seems to many that embedded is cheap. But, in reality, with an increase in device performance, the price will rise almost exponentially. RPi-4 is 5 times cheaper than Jetson Nano / Google Coral and 2-3 times weaker. Jetson Nano is 5 times cheaper than Jetson TX2 / Intel NUC, and 2-3 times weaker than them.
- Lorgus. Remember this design from Zhelyazny?
It seems that I set it as the title picture ..." the Logrus is a shifting, three-dimensional maze which represents the forces of Chaos in the multiverse. " All this is an abundance of bugs and holes, all these miscellaneous pieces of iron, all changing frameworks ... It's normal when the market picture completely changes in 2-3 months. During this year, it has changed 3-4 times. You cannot enter the same river twice. So all current thoughts are true for the summer of 2019.
What is
- I will not parse neurons / inferences on phones. This in itself is a huge topic. But since phones are embedded platforms with an interference fit, I don’t think it’s bad.
- I will touch on Jetson TX1 | TX2. In the current conditions, these are not the most optimal of the platforms for the price, but there are situations when they are still convenient to use.
- I do not guarantee that the list will include all platforms that exist today. Maybe I forgot something, maybe I don’t know about something. If you know more interesting platforms - write!
So. The main things that are clearly embeding. In the article we will compare precisely them:
- Jetson platform. There are several devices for it:
- Jetson Nano - a cheap and fairly modern (spring 2019) toy
- Jetson Tx1 | Tx2 - quite expensive but good platforms for performance and versatility
- Raspberry Pi . In reality, only RPi4 has the performance for neural networks. But some individual tasks can be done on the third generation. I even started up very simple grids at the first.
- Google Coral Platform. In fact, for embeding devices there is only one chip and two devices - Dev Board and USB Accelerator
- Intel Movidius Platform. If you are not a huge company, then only Movidius 1 | Movidius 2 sticks will be available to you.
- Gyrfalcone platform. The miracle of Chinese technology. There are already two generations - 2801, 2803
Misc. We will talk about them after the main comparisons:
- Intel processors. First of all, NUC builds. Almost embedding
- Nvidia Mobile GPUs. Ready-made solutions can be considered not embedding. And if you collect embedding, then it will turn out decently on finances.
- Mobile phones. Android is characterized by the fact that in order to use maximum performance, it is necessary to use exactly the hardware that a particular manufacturer has. Or use something universal, such as tensorflow light. For Apple, the same thing.
- Jetson AGX Xavier is an expensive Jetson version with more performance.
- GAP8 - low-power processors for super-cheap devices.
- Mysterious Grove AI HAT
Jetson
We have been working with Jetson for a very long time. Back in 2014, Vasyutka invented mathematics for the then Swift precisely on Jetson. In 2015, at a meeting with Artec 3D, we talked about what a cool platform it is, after which they suggested that we build a prototype based on it. After a couple of months, the prototype was ready. Just a couple of years of work of the entire company, a couple of years of curses on the platform and heaven ... And Artec Leo was born - the coolest scanner in its class. Even Nvidia at the presentation of TX2 showed him as one of the most interesting projects created on the platform.
Since then, TX1 / TX2 / Nano we used somewhere in 5-6 projects.
And, probably, we know all the problems that were with the platform. Let's take it in order.
Jetson tk1
I won’t especially talk about him. The platform was very efficient in computing power on its day. But she was not grocery. NVIDIA sold the TegraTK1 chips that underpinned Jetson. But these chips were impossible to use for small and medium-sized manufacturers. In reality, only Google / HTC / Xiaomi / Acer / Google could do something on them except Nvidia. All the others integrated into the prod either debug boards or looted other devices.
Jetson TX1 | TX2
Nvidia made the right conclusions, and the next generation was done awesomely. TX1 | TX2, these are no longer chips, but a chip on the board.
They are more expensive, but have a completely grocery level. A small company can integrate them into its product, this product is predictable and stable. I personally saw how 3-4 products were brought to production - and everything was good.
I will talk about TX2, because from the current line it is the main board.
But, of course, not all thank God. What's wrong:
- Jetson TX2 is an expensive platform. In most products, you will use the main module (as I understand it, from the size of the batch, the price will be somewhere from 200-250 to 350-400 cu apiece). He needs CarrierBoard for him. I don’t know the current market, but earlier it was about 100-300 cu depending on the configuration. Well, and on top of your body kit.
- Jetson TX2 is not the fastest platform. Below we will discuss comparative speeds, there I will show why this is not the best option.
- It is necessary to remove a lot of heat. Perhaps this is true for almost all platforms that we will talk about. The housing must solve the problem of heat dissipation. Fans
- This is a bad platform for small parties. Lots of hundreds of devices - approx. Ordering motherboards, developing designs and packaging is the norm. Lots of thousands of devices? Design your motherboard - and chic. If you need 5-10 - bad. You will have to take DevBoard most likely. They are large, they are a bit disgusting to flash. This is not an RPi-ready platform.
- Nvidia's poor technical support. I heard a lot of abuse that they respond to requests that this is either secret information or monthly responses.
- Poor infrastructure in Russia. It’s difficult to order, you have to wait a long time. But at the same time, dealers work well. I recently came across a Jetson nano that burned out on launch day - changed without question. Himself picked up by courier / brought a new one. WAH! Also, he himself saw that the Moscow office advises well. But as soon as the level of their knowledge does not allow to answer the question and requires a request to the international office - it takes a long time to wait for answers.
What's awesome:
- A lot of information, a very large community.
- Around Nvidia there are many small accessories companies. They are open to negotiations, you can tune their decision. And CarierBoard, and firmware, and cooling systems.
- Support for all normal frameworks (TensorFlow | PyTorch) and full support for all networks. The only conversion you may have to do is transfer the code to TensorRT. This will save memory, possibly speed up. Compared to what will be on other platforms, this is ridiculous.
- I do not know how to breed boards. But from those who did this for Nvidia, I heard that TX2 is a good option. There are manuals that correspond to reality.
- Good power consumption. But of all that exactly “embedded” will be with us - the worst :)
- Caliper in Russia (explained above why)
- Unlike movidius | RPi | Coral | Gyrfalcon is a real GPU. You can drive on it not only grids, but also normal algorithms
As a result, this is a good platform for you if you have piece devices, but for some reason you cannot put a full-fledged computer. Something massive? Biometrics - most likely not. Number recognition is on the edge, depending on the flow. Portable devices with a price of over 5k bucks - possible. Cars - no, it’s easier to put a more powerful platform a little more expensive.
It seems to me that with the release of a new generation of cheap TX2 devices, it will die over time.
Motherboards for Jetson TX1 | TX2 | TX2i and others look something like this:
And here or here there are more variations.
Jetson nano
Jetson Nano is a very interesting thing. For Nvidia, this is a new form factor that, in terms of revolution, would have to compare with the TK1. But competitors are already running out. There are other devices that we’ll talk about. It is 2 times weaker than TX2, but 4 times cheaper. More precisely ... Math is complicated. Jetson Nano on the demo board costs 100 bucks (in Europe). But if you buy only a chip, then it will be more expensive. And you will need to breed him (there is no motherboard for him yet). And, God forbid, it will be 2 times cheaper on a large party than TX2.
In essence, Jetson Nano, on its base board, is such an advertising product for institutes / resellers / amateurs, which should spur interest and business application. By pluses and minuses (partially intersects with TX2):
- The design is weak and not debugged:
- It overheats, with a constant load periodically hangs / flies. A familiar company has been trying to pick up all the problems for 3 months - it doesn’t work.
- I have one burned out when powered by USB. I heard that one friend had a USB output burned out, and the plug was working. Most likely some troubles with USB power.
- If you package the original board, then the radiator from NVIDIA is not enough, for example it will overheat.
- Speed is somehow not enough. Almost 2 times less than TX2 (in reality, it can be 1.5, but it depends on the task).
- Lots of 5-10 devices are generally very good. 50-200 - it’s difficult, you’ll have to compensate for all the manufacturer’s bugs, hang it on your dogs, if you need to add something like POE, it will hurt. Larger parties. Today I have not heard about successful projects. But it seems to me that there difficulties can emerge as with TK1. To be honest, I would like to hope that Jetson Nano 2 will be released next year, where these childhood diseases will be corrected.
- Support is bad, same as TX2
- Poor infrastructure
Good:
- Enough budget compared to competitors. Especially for small parties. Favorably priced / performance
- Unlike movidius | RPi | Coral | Gyrfalcon is a real GPU. You can drive on it not only grids, but also normal algorithms
- Just start any network (same as tx2)
- Power Consumption (same as tx2)
- Caliper in Russia (same as tx2)
Nano itself came out in early spring, somewhere from April / May, I actively poked at it. We have already managed to make two projects on them. In general, the problems identified above. As a hobby product / product for small batches - very cool. But whether it is possible to drag in production and how to do it is not yet clear.
Talk about the speed of Jetson.
We will be comparing with other devices much later. In the meantime, just talk about Jetson and speed. Why Nvidia is lying to us. How to optimize your projects.
Below everything is written about TensorRT-5.1. TensorRT-6.0.1 was released on September 17, 2019, all statements must be double-checked there.
Let's assume we believe Nvidia. Let's open their website and see the time of inference of SSD-mobilenet-v2 to 300 * 300:
Wow, 39FPS (25ms). Yes, and the source code is laid out !
Hmm ... But why is it written here about 46ms?
Wait ... And here they write that 309 ms is native, and 72ms is ported ...
Where is the truth?
The truth is that everyone thinks very different:
- SSD consists of two parts. One part is the neuron. The second part is the post-processing of what the neuron produced (non maximum suppression) + the pre-processing of what is loaded on the input.
- As I said earlier, under Jetson everything needs to be converted to TensorRT. This is such a native framework from NVIDIA. Without it, everything will be bad. Only there is one problem. Not everything is ported there, especially from TensorFlow. Globally, there are two approaches:
- Google, realizing that this is a problem, released a thing called “tf-trt” for TensorFlow. In fact, this is an add-on on tf, which allows you to convert any grid to tensorrt. Parts that are not supported are inferred on the CPU, the rest on the GPU.
- Rewrite all layers / find their analogues
In the examples above:
- In this link, 300ms time is the usual tensorflow without optimization.
- There, 72ms is the tf-trt version. There, all nms is essentially done on the process.
- This is a fan version, where a person transferred the whole nms and wrote it on gpu himself.
- And this ... This NVIDIA decided to measure all the performance without post-processing anywhere without explicitly mentioning it.
You need to understand for yourself that if it were your neuron, which no one would have converted before you, then without problems you would be able to launch it at a speed of 72ms. And at a speed of 46 ms, sitting over the manuals and sorsa day-week.
Compared to many other options, this is very good. But don’t forget that whatever you do - never believe the NVIDIA benchmarks!
RaspberryPI 4
Production? .. I just hear dozens of engineers start laughing at the mention of the words “RPI” and “production” nearby. But, I have to say - RPI is still more stable than Jetson Nano and Google Coral. But, of course, TX2 loses and, apparently, gyrfalcone.
(The picture is from here . It seems to me that attaching fans to the RPi4 is a separate folk amusement.)
From the whole list, this is the only device that I did not hold in my hands / did not test. But he started up neurons on Rpi, Rpi2, Rpi3 (for example, he told me here ). In general, Rpi4, as I understand it, differs only in performance. It seems to me that the pros and cons of RPi know everything, but still. Minuses:
- It would not be desirable, this is not a grocery solution. Overheating . Periodic freezes. But due to the huge community, there are hundreds of solutions to every problem. This does not make Rpi good for thousands of print runs. But tens / hundreds - wai notes.
- Speed. This is the slowest device of all the main ones that we are talking about.
- There is almost no support from the manufacturer. This product is aimed at enthusiasts.
Pros:
- Price. No, of course, if you breed the board yourself, then using gyrfalcone you can be able to make it cheaper in lots of thousands. But most likely this is unrealistic. Where RPi performance is enough - this will be the cheapest solution.
- Popularity. When Caffe2 came out, there was a version for Rpi in the base release. Tensorflow light? Of course it works. Etc. What the manufacturer does not do is transfer users. I ran on different RPi and Caffe and Tensorflow and PyTorch, and a bunch of rarer things.
- Convenience for small parties / pieces. Just flash the flash drive and run. There is WiFi on board, unlike JetsonNano. You can simply power it through PoE (it seems like you need to buy an adapter that is sold actively).
We'll talk about Rpi speed at the end. Since the manufacturer does not postulate that his product for neurons, there are few benchmarks. Everyone understands that Rpi is not perfect in speed. But even he is suitable for some tasks.
We had a couple of semi-product tasks that we implemented at Rpi. The impression was pleasant.
Movidius 2
From here and below, not full-fledged processors will go, but processors designed specifically for neural networks. It is as if their strengths and weaknesses at the same time.
So. Movidius. The company was bought by Intel in 2016. In the segment of interest to us, the company released two products, Movidius and Movidius 2. The second is faster, we will only talk about the second.
No, not like that. The conversation should not begin with Movidius, but with Intel OpenVino . I would say that this is ideology. More specifically, the framework. In fact, this is a set of pre-trained neurons and inferences to them, which are optimized for Intel products (processors, GPUs, special computers). Integrated with OpenCV, with the Raspberry Pi, with a bunch of other whistles and farts.
The advantage of OpenVino is that it has a lot of neurons. First of all, the most famous detectors. Neurons for recognition of people, persons, numbers, letters, poses, etc., etc. ( 1 , 2 , 3 ). And they are trained. Not by open datasets, but by datasets compiled by Intel itself. They are much larger / more diverse and better open. They can be retrained according to your cases, then they will work generally cool.
Is it possible to do better? Sure. For example, the recognition of numbers that we did - worked significantly better. But we spent many years on developing it and understanding how to make it perfect. And here you can get the fucking quality out of the box, which is enough for most cases.
OpenVino, of course, has several problems. Grids there do not appear immediately. If something new comes out, you have to wait a long time. Nets there appear deep grocery. You will not find any GANs there. Only deep benefit. And, in our experience, it’s quite difficult to overtake the grid there if you have any tricks in architecture that are different from harsh standards. But the guys overtook some , even quite complex models:
It seems to me that Intel with its OpenVino has chosen a very interesting strategy. They are in the role of a constant catch-up. But one who, after catching up, spreads any. At that moment, when everything is squeezed out of the neurons, Intel will come and capture the finished market. Already, in 70% of tasks, you can build a solution based on OpenVino.
And as part of this strategy, Movidius looks like its logical complement. This is the device on which you need to interest all this wealth. Most grids are optimized specifically for it (sometimes even to binary architecture, which is very fast).
Globally, he has one minus. USB is, damn it, not a food connector !!! You cannot make a device with USB. There is an exit. Intel sells chips. Even something like that is on sale on the last generation ( 1 , 2 )
It seems like there are products on it. But I have not seen a single product board on which to develop something. And no familiar small-medium-sized company has begun to develop anything based on this chip.
On the other hand, what will happen to the tank? .. It will still catch up with us and crush us :)
Oh yes, and out of joy. OpenVino, as I understand it, is being developed in Russia, in Nizhny Novgorod (it seems to me that half of Computer Vision is done there). Here Sergey tells about him:
(the report is more likely about AI 2.0, but there are a lot about OpenVino).
Okay, almost everything has been said. Short extract by Movidius 2. Cons:
- The basic version is not grocery. Worse than Rpi and Jetson Nano. Is it possible to buy a chip and assemble your device on its basis - it is not clear. But in any case, it is long and expensive. Perhaps Third Party solutions will come out?
- It's difficult to port your networks. Fancy layers immediately to minus. Partially offset by the range of networks presented.
- Speed is not the fastest. But more on that later.
- You need a basic device to run. The rate of inference depends on the device and on the presence of USB 3.0 on it
- If I understand correctly, then two grids cannot be kept in memory at the same time. It is necessary to perform upload-download. Which slows the inference of several networks. For the first generation Movidius, that was exactly the case. It seems that nothing should have changed.
Pros:
- Very simple and comfortable. A minimal knowledge of python is enough to create a working prototype. No need to train anything.
- Low power consumption, does not overheat
- Good support, as I heard
We ourselves did not use it in any project. All our friends who tested it for inference tasks - as a result, they did not take it into production.
But a couple of companies that I advised, where there were tasks of the level “we need to put 20-30 cameras on barriers, but we don’t want to buy anything, we will develop it ourselves” - it seems like in the end they took it Movidius.
Intel recently announced a new platform. But so far there is no detailed information, let's see.
UPD
They sent a link to this . Fee with two second movidius. It’s quite an embedded format. Many people use the PCI-e bus for this. To such things is only a matter of price. Two movidius - it is unlikely that such a thing will be cheaper than $ 200 cost. And you will also need your own board with your system ...
Google coral
I am disappointed. No, there is nothing that I would not predict. But I'm disappointed that Google decided to release this. Testing is a miracle in the beginning of summer. Maybe something has changed since then, but I will describe my experience of that time.
Setting up ... To flash Jetson Tk-Tx1-Tx2 you had to plug it into the host computer and into the power supply. And that was enough. To flash Jetson Nano and RPi, you just need to push the image onto the USB flash drive.
And to flash Coral, you need to stick three wires in the correct order :
And do not try to make a mistake! By the way, there are errors / indescribable behavior in the guide. Probably I will not describe them, since from the beginning of the summer they could fix something. I remember that after installing Mendel any access via ssh was lost, including the one described by them, I had to manually edit some Linux configs.
It took me 2-3 hours to complete this process.
OK. Launched. Do you think it's easy to run your grid on it? Almost nothing :)
Here is a list of what you can let go.
To be honest, I did not get to this point quickly. Spent half a day. No really. You cannot download the model from the TF repository and run on the device. Or there it is necessary to cross-cut all layers. I did not find instructions.
So here. It is necessary to take the model from the repository from above. There are not many of them (3 models have been added since the beginning of summer). And how to train her? Open in TensorFlow in a standard pipeline? HAHAHAHAHAHAHAHA. Of course not!!!
You have a special Doker container , and the model will train only in it. (Probably, you can somehow mock your TF as well ... But there are instructions, instructions ... which weren’t and don't seem to be.)
Download / Install / Launch. What is it ... Why is the GPU at zero? .. BECAUSE TRAINING WILL BE ON THE CPU. Docker is only for him !!! Want some more fun?The manual says “based on a 6-core CPU with 64G memory workstation”. It seems that this is only advice? May be.Only now I didn’t have enough of my 8 gigs on that server where most of the models train. Training at the 4-th hour consumed them all. A strong feeling that they had something flowing. I tried a couple of days with different parameters on different machines, the effect was one.
I did not double-check this before posting the article. To be honest, it was enough for me once.
What else to add? That this code does not generate a model? To generate it you must:
- Lag count
- Convert him to tflite
- Compile to Edge TPU Formal. Thank God now this is done on a computer. In the spring, this could only be done online. And there it was necessary to put a tick “I will not use it for evil / I do not violate any laws with this model”. Now, thank God there isn’t this.
This is the greatest disgust I have experienced in relation to an IT product over the past year ...
Globally, Coral should have the same ideology as OpenVino with Movidius. Only now Intel has been on this path for several years. With excellent manuals, support and good products ... And Google. Well, it's just Google ...
Minuses:
- This board is not grocery at the AD level. I have not heard about the sale of chips => production is unrealistic
- The level of development is as terrible as possible. Everything bazhet. The development pipeline does not fit into traditional schemes.
- . “ ” . ,
- . TX2.
- . -. .
Pros:
- Coral
- , , Movidius. .
Gyrfalcon
The last one and a half years have been talking about this Chinese beast. Even a year ago I was saying something about him. But talking is one thing, and giving information is another. I talked with 3-4 large companies, where project managers / directors told me how cool this Girfalkon was. But they did not have any documentation. And they did not see him alive. The site has almost no information. Download from the site at least something can only partners (hardware developers). Moreover, the information on the site is very contradictory. In one place they write that they support only VGG , in another that only their neurons are based on GNet (which they assurevery small and really without loss of accuracy). In the third it is written that everything is converted with TF | Caffe | PyTorch, and in the fourth it is written about the mobile phone and other charms.
Understanding the truth is almost impossible. Once I was digging and digging a few videos in which at least some numbers slip:
If this is true, then it means that SSD (on mobile?) Under 224 * 224 on the GTI2801 chip they have ~ 60ms, which is quite comparable with movidius.
It seems like they have a much faster chip 2803, but information on it is even less:
This summer we got a board from firefly in our hands ( this module is installed there for calculations).
There was a hope that finally we would see alive. But it didn’t work out. The board was visible, but did not work. Crawling through individual English phrases in the Chinese documentation, they almost even understood what the problem was (the initial knurled system did not support the neural module, it was necessary to rebuild and re-roll everything ourselves). But it just didn’t work out, and there were already suspicions that the board did not fit our task (2GB of RAM is very small for neural networks + systems. In addition, there was no support for two networks at the same time).
But I managed to see the original documentation. From it, too little is understood (Chinese). For good, you had to test and look at the source.
RockChip tech support stupidly scored on us.
Despite this horror, it is clear to me that here, all the same, RockChip's jambs are here first of all. And I have a hope that in a normal board Gyrfalcon can be quite used. But due to lack of information, it’s hard for me to say.
Minuses:
- No open sales, only interact with firms
- Little information, no community. Existing information is often in Chinese. Platform features cannot be predicted in advance
- Most likely the interference is not more than one network at a time.
- Only the manufacturers of iron can interact with the gyroplane itself. The rest need to look for some intermediaries / manufacturers of boards.
Pros:
- As I understand it, the price of a chipboard is much cheaper than the rest. Even in the form of flash drives.
- Already there are third-party devices with an integrated chip. Therefore, development is somewhat simpler than movidius.
- They assure that there are many pre-trained grids, the transfer of grids is much simpler than Movidius | Coral. But I would not guarantee this as the truth. We did not succeed.
In short, the conclusion is this: very little information. You can’t only lay on this platform. And before you do something on it - you need to make a huge review.
Speeds
I really like how 90% of comparisons of embedded devices reduce to speed comparisons. As you understood above, this characteristic is very arbitrary. For Jetson Nano, you can run neurons as pure tensorflow, you can use tensorflow-tensorrt, or you can use pure tensorrt. Devices with special tensor architecture (movidius | coral | gyrfalcone) - can be fast, but in the first place they can work only with standard architectures. Even for the Raspberry Pi, everything is not so simple. Neurons from xnor.ai give one and a half times acceleration. But I don’t know how honest they are, and what was gained by switching to int8 or other jokes.
At the same time, one more interesting thing is such a moment. The more complex the neuron, the more complex the device for inference - the more unpredictable the final acceleration that can be pulled out. Take some OpenPose. There is a nontrivial network, complex post-processing. Both this and that can be optimized due to:
- GPU Post-Processing Transfer
- Post-Processing Optimization
- Neural network optimization for platform features, for example:
- Using platform-optimized networks
- Using network modules for the platform
- Porting to int8 | int16 | binarization
- (GPU|CPU|...). Jetson TX1 . , .
Sometimes someone is trying to evaluate something is for all possible combinations. But really, as it seems to me, this is futile. First you need to decide on the platform, and only then try to completely pull out everything that is possible.
Why am I all this. Besides, the “ how long MobileNet ” test is a very bad test. He can tell that platform X is optimal. But when you try to deploy your neuron and post-processing there, you may be very disappointed.
But comparing mobilnet'ov still gives some information about the platform. For simple tasks. For situations where you understand that it’s still easier to reduce the task to standard approaches. When you want to evaluate the speed of the calculator.
The table below is taken from several places:
- : 1 , 2 , 3
- SSD “ ”. . . .
- TensorRT. .
- gyrfalcon mobilnet v2 + . 2803 3-4 . 2803 SSD. .
- ( Nvidia NMS, )
- For Jetson TX2 I used these ratings, but there are 5 classes, on the same number of classes that the rest will be slower. I somehow figured out from the experience / comparison with Nano in the cores what should be there
- I did not take into account jokes with bit rate. I don’t know what bitness Movidius and Gyrfalcon worked on.
As a result, we have:
Platform Comparison
I’ll try to bring everything that I said above to a single table. I highlighted in yellow those places where my knowledge is not enough to make a definite conclusion. And, actually 1-6 - this is some comparative assessment of the platforms. The closer to 1, the better.
I know that for many people energy consumption is critical. But it seems to me that everything here is somewhat ambiguous, and I understand this too poorly - so I did not enter it. Moreover, ideology itself seems to be the same everywhere.
Side step
What we were talking about is just a small point in the vast space of variations of your system. Probably the common words that can characterize this area:
- Low power consumption
- Small size
- High computing power
But, globally, if you reduce the significance of one of the criteria, you can add many other devices to the list. Below I will go through all the approaches that I have met.
Intel
As we said when we discussed Movidius, Intel has an OpenVino platform. It allows very efficient processing of neurons on Intel processors. At the same time, the platform allows you to support even all sorts of intel-gpu on a chip. I'm now afraid to say for sure what kind of performance there is for which tasks. But, as I understand it, a good stone with a GPU on board quite ⅓ gives a performance of 1080. For some tasks it can even be faster.
In this case, the form factor, for example Intel NUC, is quite compact. Good cooling, packaging, etc. The speed will be faster than the Jetson TX2. By accessibility / ease of purchase - much easier. The stability of the platform out of the box is higher.
Cons two - power consumption and price. Development is a little more complicated.
Jetson agx
This is another jetson. Essentially the oldest version. The speed is about 2 times faster than Jetson TX2 plus there is support for int8 computing, which allows you to overclock another 4 times. By the way, check out this picture from Nvidia:
They compare two of their own Jetson. One in int8, the second in int32. I don’t even know what words to say here ... In short: “NEVER BELIEVE NVIDIA GRAPHICS”.
Despite the fact that AGX is good - it does not reach the normal GPUs from Nvidia in terms of computing power. Nevertheless, in terms of energy efficiency - they are very cool. The main minus the price.
We ourselves did not work with them, so it’s hard for me to say something more detailed, to describe the range of tasks where they are the most optimal.
Nvidia gpu | laptop version
If you remove the strict restriction on energy consumption, then Jetson TX2 does not look optimal. Like the AGX. Usually people are scared to use the GPU in production. Separate payment, all that.
But there are millions of companies that offer you to assemble a custom solution on one board. Usually these are boards for laptops / minicomputers. Or, in the end, like this :
One of the startups in which I have been working for the last 2.5 years ( CherryHome ) has taken exactly this path. And we are very satisfied.
Minus, as usual, in energy consumption, which was not critical for us. Well, the price bites a bit.
Mobile phones
I do not want to go deep into this topic. To tell everything that is in modern mobile phones for neurons / which frameworks / which hardware, etc., you will need more than one article with this size. And taking into account the fact that we poked in this direction only 2-3 times, I consider myself incompetent for this. So just a couple of observations:
- There are many hardware accelerators on which neurons can be optimized.
- There is no general solution that goes well everywhere. Now there is some attempt to make Tensorflow lite such a solution. But, as I understand it, it has not yet become one.
- Some manufacturers have their own special farmworks. We helped to optimize the framework for Snapdragon a year ago. And it was terrible. The quality of neurons there is much lower than on everything that I talked about today. There is no support for 90% of the layers, even basic ones, such as “addition”.
- Since there is no python, the inference of networks is very strange, illogical and inconvenient.
- In terms of performance, it happens that everything is very good (for example, on some iphone).
It seems to me that for embedded mobile phones is not the best solution (the exception is some low-budget face recognition systems). But I saw a couple of cases when they were used as early prototypes.
Gap8
Was recently at a Usedata conference. And there one of the reports was about the inference of neurons at the cheapest percentages (GAP8). And, as they say, the need for inventions is cunning. In the story, an example was very far-fetched. But the author told how they were able to achieve inference by face in about a second. On a very simple grid, essentially without a detector. By crazy and long optimizations and savings on matches.
I always don’t like such tasks. No research, only blood.
But, it’s worth recognizing that I can imagine puzzles where low-consuming percentages give a cool result. Probably not for face recognition. But somewhere where you can recognize the input image in 5-10 seconds ...
Grove AI HAT
While preparing this article, I came across this embedded platform. There is very little information on it. As I understand it, zero support. Productivity is also at zero ... And not a single test on speed ...
Server / Remote Recognition
Every time they come to us for advice on an embedded platform, I want to shout “run, you fools!”. It is necessary to carefully assess the need for such a solution. Check out any other options. Everyone and always, I advise you to do a prototype with server architecture. And during its operation it is up to you to decide whether to implement a real embedded. After all, embedded is:
- Increased development time, often 2-3 times.
- Sophisticated support and debugging in production. Any development with ML is a constant revision, update of neurons, system updates. Embedded is still harder. How to reload firmware? And if you already have access to all units, then why calculate on them when you can calculate on one device?
- System complexity / increased risk. More points of failure. At the same time, while the system does not work as a whole, one may not understand: is the platform suitable for this task?
- Price increase. It's one thing to put a simple board like nano pi. And the other is to buy TX2.
Yes, I know that there are tasks where server decisions cannot be made. But, oddly enough, they are much smaller than is commonly believed.
findings
In the article, I tried to do without obvious conclusions. It is rather a story about what is now. To draw conclusions - it is necessary to investigate in each case. And not only platforms. But the task itself. Any task can be simplified a little / slightly modified / slightly sharpened under the device.
The problem with this topic is that the topic is changing. New devices / frameworks / approaches are coming. For example, if NVIDIA turns on int8 support for Jetson Nano tomorrow, the situation will change dramatically. When I write this article - I can’t be sure that the information has not changed two days ago. But I hope that my short story will help you better navigate your next project.
It would be cool if you have additional information / I missed something / said something wrong - write the details here.
ps
Already when I finished writing the article almost, snakers4 dropped a recent post from his telegram channel Spark in me, which is almost about the same problems with Jetson. But, as I wrote above, - in conditions of any power consumption - I would put something like zotacs or IntelNUC. And as embedded jetson is not the worst platform.
All Articles