Built-in Go Features

Go allows you to write in assembler. But the authors of the language wrote such a standard library that it would not have to be done. There are ways to write portable and fast code at the same time. How? Welcome to cut.
Starting to write functions in assembler in go is very simple. For example, declare (forward declaration) the
Add
function, which adds 2 int64:
func Add(a int64, b int64) int64
This is a normal function, but the body of the function is missing. The compiler will reasonably swear when trying to compile a package.
% go build examples/asm ./decl.go:4:6: missing function body
Add a file with the extension .s and implement the function in assembler.
TEXT ·Add(SB),$0-24 MOVQ a+0(FP), AX ADDQ b+8(FP), AX MOVQ AX, ret+16(FP) RET
Now you can build, test and use
Add
as a normal function. This is widely used by the language developers themselves in the runtime, math, bytealg, syscall, reflect, crypto packages. This allows you to use hardware processor optimizations and commands that are not represented in the language .
But there is a problem - functions on asm cannot be optimized and built-in (inline). Without this, the overhead can be prohibitive.
var Result int64 func BenchmarkAddNative(b *testing.B) { var r int64 for i := 0; i < bN; i++ { r = int64(i) + int64(i) } Result = r } func BenchmarkAddAsm(b *testing.B) { var r int64 for i := 0; i < bN; i++ { r = Add(int64(i), int64(i)) } Result = r }
BenchmarkAddNative-8 1000000000 0.300 ns/op BenchmarkAddAsm-8 606165915 1.930 ns/op
There were several suggestions for inline assembler, as the
asm(...)
directive in gcc. None of them were accepted. In place of this, go added intrinsic functions.
Go built-in functions are written in regular go. But the compiler knows that they can be replaced with something more optimal. In Go 1.13, embedded functions are contained in
math/bits
and
sync/atomic
.
The functions in these packages have fancy signatures. In fact, they repeat the signatures of processor commands. This allows the compiler, if the target architecture supports, to transparently replace function calls with assembler instructions.
Below I want to talk about two different ways in which the go compiler creates more efficient code using built-in functions.
Population count
this number of units in the binary representation of a number is an important cryptographic primitive. Since this is an important operation, most modern cpu provide implementation in hardware.
The
math/bits
package provides this operation in the
OnesCount*
functions. They are recognized and replaced by the
POPCNT
processor
POPCNT
.
To see how this can be more efficient, let's compare 3 implementations. The first is the Kernigan algorithm .
func kernighan(x uint64) (count int) { for x > 0 { count++ x &= x - 1 } return count }
The number of cycles of the algorithm matches the number of bits set. More bits - longer execution time, which potentially leads to leakage of information on third-party channels.
The second algorithm is taken from the book of Hacker's Delight .
func hackersdelight(x uint64) uint8 { const m1 = 0b0101010101010101010101010101010101010101010101010101010101010101 const m2 = 0b0011001100110011001100110011001100110011001100110011001100110011 const m4 = 0b0000111100001111000011110000111100001111000011110000111100001111 const h1 = 0b0000000100000001000000010000000100000001000000010000000100000001 x -= (x >> 1) & m1 x = (x & m2) + ((x >> 2) & m2) x = (x + (x >> 4)) & m4 return uint8((x * h1) >> 56) }
The divide and conquer strategy allows this version to work for O (log₂) of the length of the number, and for a constant time of the number of bits, which is important for cryptography. Let's compare performance with
math/bits.OnesCount64
.
func BenchmarkKernighan(b *testing.B) { var r int for i := 0; i < bN; i++ { r = kernighan(uint64(i)) } runtime.KeepAlive(r) } func BenchmarkPopcnt(b *testing.B) { var r int for i := 0; i < bN; i++ { r = hackersdelight(uint64(i)) } runtime.KeepAlive(r) } func BenchmarkMathBitsOnesCount64(b *testing.B) { var r int for i := 0; i < bN; i++ { r = bits.OnesCount64(uint64(i)) } runtime.KeepAlive(r) }
To be honest, we pass the same parameters to the functions: a sequence from 0 to bN This is more true for the Kernigan method, since its execution time increases with the number of bits of the input argument. ➚
BenchmarkKernighan-4 100000000 12.9 ns/op BenchmarkPopcnt-4 485724267 2.63 ns/op BenchmarkMathBitsOnesCount64-4 1000000000 0.673 ns/op
math/bits.OnesCount64
wins in speed 4 times. But does it really use a hardware implementation, or did the compiler just better optimize the algorithm from Hackers Delight? It's time to get into assembler.
go test -c #
There is a simple utility for disassembling the go tool objdump, but I (unlike the author of the original article), I will use the IDA.
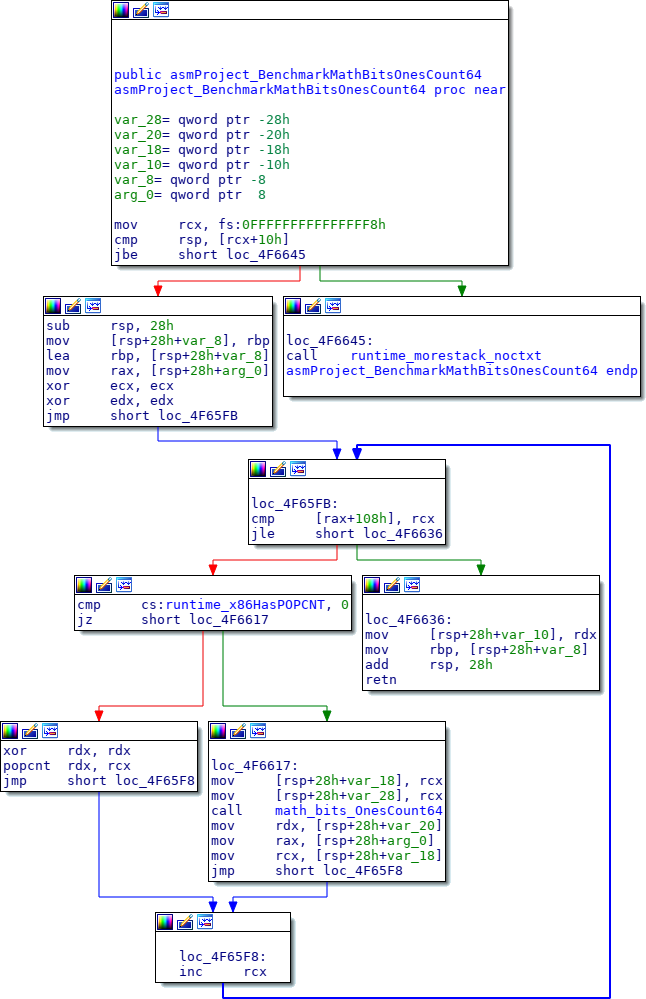
There is a lot going on here. Most important: the x86
POPCNT
instruction is built into the code of the test itself, as we had hoped. This makes banchmark faster than alternatives.
This branch is interesting.
cmp cs:runtime_x86HasPOPCNT, 0 jz lable
Yes, this is polyphile on assembler. Not all processors support
POPCNT
. When the program starts, before your
main
, the
runtime.cpuinit
function checks if there is a necessary instruction and saves it in
runtime.x86HasPOPCNT
. Each time, the program checks whether it is possible to use
POPCNT
, or use a polyfile. Since the value of
runtime.x86HasPOPCNT
does not change after initialization, the prediction of processor branching is relatively accurate.
Atomic counter
Intrinsic functions are regular Go code; they can be inline in an instruction stream. For example, we will make an abstraction of a counter with methods from strange signatures of functions of the atomic package.
package main import ( "sync/atomic" ) type counter uint64 func (c *counter) get() uint64 { return atomic.LoadUint64((*uint64)(c)) } func (c *counter) inc() uint64 { return atomic.AddUint64((*uint64)(c), 1) } func (c *counter) reset() uint64 { return atomic.SwapUint64((*uint64)(c), 0) } func F() uint64 { var c counter c.inc() c.get() return c.reset() } func main() { F() }
Someone will think that such an OOP will add overhead. But Go is not Java - the language does not use binding in runtime unless you explicitly use interfaces. The code above will be collapsed into an efficient stream of processor instructions. What will main look like?
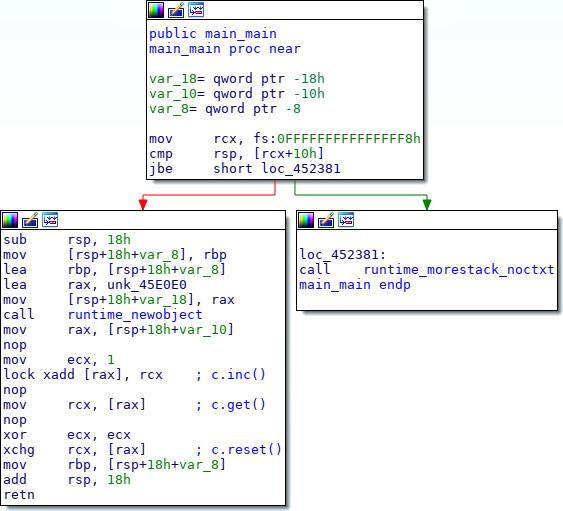
In order.
c.inc
turns into
lock xadd [rax], 1
- atomic addition of x86.
c.get
becomes the usual
mov
instruction, which is already atomic in x86.
c.reset
becomes an atomic
xchg
exchange between a null register and memory.
Conclusion
Embedded functions - a neat solution that provides access to low-level operations without expanding the language specification. If the architecture does not have specific sync / atomic primitives (like some ARM variants), or operations from math / bits, then the compiler inserts a polyfile on pure go.
All Articles