Benchmark RPC Systems (and Inverted Json)
Comparison of various tools (RabbitMQ, Crossbar.io, Nats.io, Nginx, etc.) for organizing RPC between microservices.
Memory usage 
CPU usage 
Multi processor test 
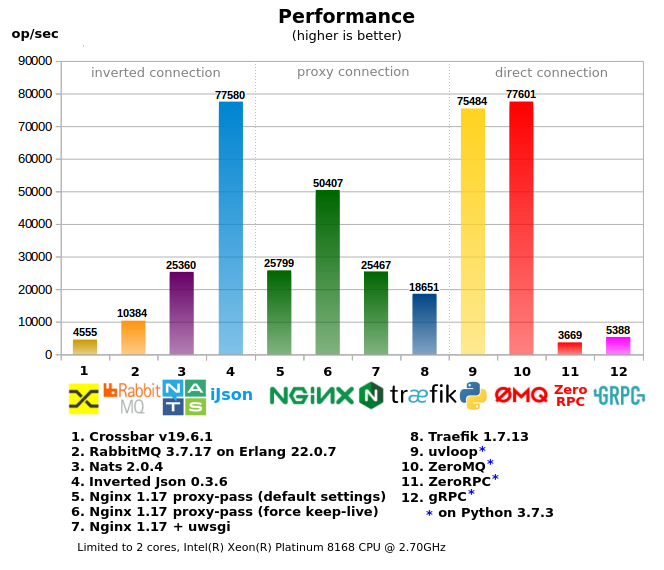
1. Tests
All tools are divided into 3 groups:
- “Direct connection” - when the client directly addresses the worker, in projects with a large number of workers / services it is the most difficult to configure, requires a “smart client”, ie when calling, the client must have information on how and where to send the request (or an additional local proxy is needed), as a rule it produces the least load on the network.
- “Proxy connection” - a variant with a single entry point, a simple client, but at the same time difficulties remain on the side of workers / serials - forwarding and allocating ports, registering addresses for proxies, more complicated firewall settings, additional tools are often used to manage this entire farm .
- “Inverted connection” - a single entry point for both clients and workers (can be considered as an ESB), the most simple network setup.
- Memory and processor usage taken from `docker stats`
- In the “2-core” test, the server and clients with the breaks are divided into different cores in order to reduce the influence on each other, therefore the server is limited to 2 cores through the taskset (multi-core test without restrictions)
2. MQ or RPC
Although these 2 communication methods are different, sometimes the first is used instead of the second and vice versa.
If you try to outline the boundaries, when to use what, you can get something like this:
- RPC (procedure call) - when the client requires a response immediately (in a short period of time), when the worker needs to answer while the client is waiting for a response, and if the client leaves (by timeout), this answer is no longer needed (this is why you do not need to save the “request ", As is often done in MQ systems).
For example, when you make a query in the database - you do RPC, you will not want to use MQ for this. - MQ - when the answer is not needed (immediately), when you just need to complete some kind of task in the end or just transfer the data.
For example, to send letters you can send a task via MQ
3. RPC over RabbitMQ
RabbitMQ is often used to organize RPCs, but like similar MQ systems it creates an additional overhead, which is why its use is not very productive.
If you use the “queue” for RPC, then you need to clean the channels, because if the worker has fallen for a while, then after restarting it can get a bunch of irrelevant tasks, because clients sent requests all this time and, in addition, waited in vain for an answer. the worker was not active. In total, the worker will receive the task even if the client has left before, the same with the client, if the client’s channel is not counted, then he may get clogged with unaccepted answers from the worker, although in RabbitMQ you can close the client channel, but at the same time performance drops dramatically.
You also need to do a pork worker to know if he is alive.
In addition, resources are spent on working with channels, when in RPC systems data is simply sent to the worker and vice versa.
4. Inverted Json
There are many different MQ systems, but not many Job servers (RPCs) such as Gearman / Crossbar.io are very small choices, so developers often take MQ systems for RPCs.
Therefore, Inverted JSON (iJson) was created - a proxy server with an http interface where clients and workers connect as a network client: [client] -> [Inverted Json] <- [worker], written in C / C ++, uses epoll, state machines for routing, json streaming parser, slices instead of strings *, etc. methods for better performance.
Advantages of Inverted JSON over RabbitMQ:
- No need to clean client and worker channels from messages not received
- It is not necessary to ping the worker, the client will receive an error immediately if the worker disconnects (with a keepalive connection)
- Easier api - just an http request (as a rule, it is already supported by all languages and frameworks)
- Works faster and consumes less memory
- An easier way to send commands to a specific worker (for example, if there are several workers in a queue, but you need to work with one specific one)
Other Inverted Json Information
- The ability to transfer binary data (not just json, as the name might seem)
- It is not necessary to specify id if the worker is connected as keep-alive, Inverted Json simply connects the client and the worker directly.
- The ability to "subscribe" to several commands (channels), subscribe to a pattern (for example command / *) without losing performance.
- Docker image is only 2.6 MB (slim version)
- Kernel Inverted Json only ~ 1400 lines of code (v0.3), less code - less bugs;)
- Inverted JSON does not modify the request body (body), but sends it as is.
5. Try Inverted Json in 3 minutes
You can try Inverted Json right now if you have Docker and curl :

Description from the picture:
1) Running the docker image of Inverted Json on port 80 (you can choose any), --log 32 logs incoming requests:
$ docker run -it -p 80:8001 lega911/ijson --log 32
2) We register the worker for the “calc / sum” task, and wait for the task:
$ curl localhost/rpc/add -d '{"name": "calc/sum"}'
3) The client makes an RPC request calc / sum:
$ curl localhost/calc/sum -d '{"id": 15, "data": "2+3"}'
4) The worker receives the task `{" id ": 15," data ":" 2 + 3 "}` - the data is unchanged, now you need to send the result to the same id:
$ curl localhost/rpc/result -d '{"id": 15, "result": 5}'
... and the client gets the result as it is
`{"id": 15, "result": 5}`
5.1. Jsonrpc
JsonRPC 2 is not supported, but there are some rudiments, for example, the client can send requests like (url / rpc / call):
{"jsonrpc": "2.0", "method": "calc/sum", "params": [42, 23], "id": 1}
accept errors like:
{"jsonrpc": "2.0", "error": {"code": -32601, "message": "Method not found"}, "id": null}
However, if there is demand, then JsonRPC support can be improved.
5.2. Python client and worker example
# client.py import requests print(requests.post('http://127.0.0.1:8001/test/command', json={'id': 1, 'params': 'Hello'}).json()) # worker.py import requests while True: request = requests.post('http://127.0.0.1:8001/rpc/add', json={'name': '/test/command'}).json() response = { 'id': request['id'], 'result': request['params'] + ' world!' } requests.post('http://127.0.0.1:8001/rpc/result', json=response)
And here you can find an example in the "worker mode", which is more productive and compact.
6. Some thoughts on the benchmark result
- Crossbar.io : is based on python, so it is not so fast and cannot use multiple cores due to the GIL.
- RabbitMQ : RPC on top of MQ, which imposes an additional overhead. A rapid drop in performance with increasing load (not reflected in the test).
- Nats : not a bad one, although inferior to Inverted Json, as RPC over MQ will also have the same problems.
- Inverted Json : reached the network limit (i.e. launching several copies of tests on different cores does not give a better result in total), showed the most efficient use of memory and processor relative to performance.
- Nginx : when proxy-pass, performance drops quickly if keep-alive mode is not turned on (turned off by default), due to the fact that linux does not allow opening / closing many sockets in a short period of time (this is not reflected in the test).
- Traefik : very voracious, used 600% of the CPU at peak, inferior to nginx in speed
- uvloop (under asyncio) - gives very good performance, because most written in C / C ++, for RPC is more preferable than ZeroMQ
- ZeroMQ - the worker himself is written in Python, so he ran into the kernel, although the multiprocessor test consumes more than 100% CPU, this is due to the fact that zeromq itself is written in C / C ++ without GIL capture. It gives great performance, but on the other hand, if the worker does not just a + b, any complication will lead to a significant reduction in RPC, because will hit the core even earlier.
- ZeroRPC : declared as a lightweight wrapper over ZeroMQ, in reality, 95% of the performance from ZeroMQ is lost, it seems that it is not so light.
- GRPC : the option for python produces a lot of boilerplate python code, i.e. the processor turns out to be heavy and quickly rests on the CPU, for compiled languages there is probably no such problem.
- 2-core and multi-core tests, in multi-core some indicators decreased, because you have to compete for CPU resources with the client test code, on the other hand, some tests gave great performance, for example Traefik, which ate 600% CPU
7. Conclusion
If you have a large company and many employees, then you can afford to support various complex tools for organizing direct connections between microservices, which can provide effective communication.
And for small companies and startups, where a small team needs to solve problems from various fields, Inverted Json can save time and resources.
For the development of Inverted Json, plans include support for pubsub, kubernetes, and other interesting ideas.
If you are interested in the project or just want to help the author, you can put an asterisk on the github project , thanks.
PS:
- It took more time to create this article including tests than to create Inverted Json itself
- Inverted Json prototypes were also written in 1. python + asyncio + uvloop, 2. in GoLang
- Tests have been reviewed by various experts.
- “Slices instead of strings” - in most cases when parsing http / json the data are not copied to strings, but the link to the source data is used, thus, there is no unnecessary allocation and copying of memory.
- If you will test - do not use requests in python, it is very slow, better than pycurl, this wrapper is used in tests.
- The benchmark is here
- Sources here
All Articles