まず、一般的なApache Igniteとは何ですか。 これは、SQL、トランザクション、およびキャッシュをサポートする分散キー/値リポジトリであるデータベースです。 さらに、Igniteでは、ユーザーサービスをIgniteクラスターに直接展開できます。 開発者は、Igniteが提供するすべてのツール(分散データ構造、メッセージング、ストリーミング、コンピューティング、データグリッド)を利用できるようになります。 たとえば、データグリッドを使用する場合、データウェアハウス用に個別のインフラストラクチャを管理する問題、およびその結果として生じるオーバーヘッドはなくなります。

Service Grid APIを使用すると、構成で展開スキームを指定し、それに応じてサービス自体を指定するだけで、サービスを展開できます。
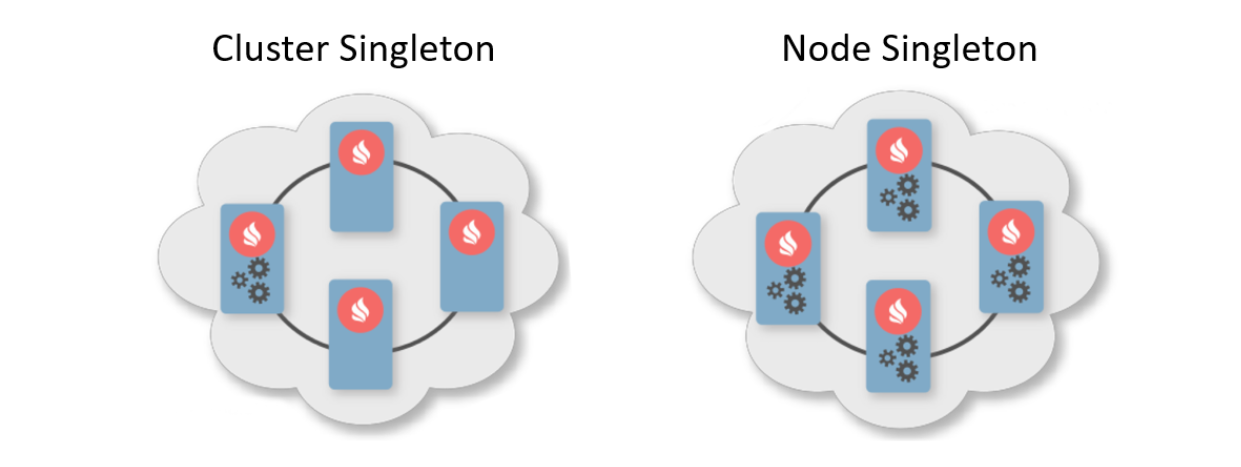
通常、展開パターンは、クラスターノードに展開する必要があるインスタンスの数を示します。 2つの典型的な展開パターンがあります。 1つ目はクラスターシングルトンです。クラスター内のどの時点でも、ユーザーサービスの1つのインスタンスが使用可能であることが保証されます。 2つ目はノードシングルトンです。サービスの1つのインスタンスがクラスターの各ノードにデプロイされます。
ユーザーは、クラスター全体のサービスインスタンスの数を指定し、適切なノードをフィルタリングするための述語を定義することもできます。 このシナリオでは、サービスグリッド自体がサービスの展開に最適な分布を計算します。
さらに、アフィニティサービスなどの機能があります。 アフィニティは、キーとパーティションの関係、および関係者とトポロジ内のノードの関係を定義する関数です。 キーを使用して、データが保存されているプライマリノードを決定できます。 したがって、独自のサービスをアフィニティ機能のキーとキャッシュに関連付けることができます。 アフィニティ機能が変更されると、自動再操作が発生します。 そのため、サービスは常に操作するデータの隣に配置され、それに応じて情報へのアクセスのオーバーヘッドが削減されます。 このようなスキームは、一種の連結コンピューティングと呼ばれます。
Service Gridの美しさを理解したので、その開発の歴史について説明します。
以前は何でしたか
Service Gridの以前の実装は、Igniteのトランザクション複製システムキャッシュに基づいていました。 Igniteの「キャッシュ」という言葉はストレージを意味します。 つまり、ご想像のとおり、これは一時的なものではありません。 キャッシュは複製可能であり、各ノードにはデータセット全体が含まれていますが、キャッシュ内にはパーティションビューがあります。 これは、ストレージの最適化によるものです。

ユーザーがサービスを展開しようとしたときに何が起きましたか?
- 組み込みの連続クエリメカニズムを使用して、リポジトリ内のデータを更新するためにサブスクライブするクラスター内のすべてのノード。
- 読み取りコミットされたトランザクションの下の開始ノードが、シリアル化されたインスタンスを含むサービスの構成を含むレコードをデータベースに作成しました。
- 新しいレコードの通知を受信すると、コーディネーターは構成に基づいて分布を計算しました。 結果のオブジェクトはデータベースに書き戻されます。
- ノードは、新しい配布およびデプロイされたサービスに関する情報を読み取ります
必要に応じて。
私たちに合わなかったもの
ある時点で、サービスに取り組むことは不可能であるという結論に達しました。 いくつかの理由がありました。
展開中に何らかのエラーが発生した場合は、すべてが発生したノードのログからのみ確認できます。 非同期のデプロイしかなかったため、デプロイメントメソッドからユーザーに制御を戻した後、サービスを開始するのに余分な時間がかかり、その時点でユーザーは何も制御できませんでした。 Service Gridをさらに開発し、新しい機能を確認し、新しいユーザーを引き付け、全員の生活を楽にするために、何かを変更する必要があります。
新しいサービスグリッドを設計するとき、まず同期展開の保証を提供したいと考えました。ユーザーがAPIから制御を返すとすぐに、サービスをすぐに使用できるようになりました。 また、イニシエーターにデプロイメントエラーを処理する機会を与えたいと思いました。
さらに、実装を促進したい、つまりトランザクションとリバランスから逃れたいと思いました。 キャッシュは複製可能であり、バランスが取れていないという事実にもかかわらず、多くのノードを含む大規模な展開中に問題が発生しました。 トポロジを変更する場合、ノードは情報を交換する必要があり、大規模な展開では、このデータの重量が大きくなる可能性があります。
トポロジが不安定な場合、コーディネーターはサービスの分布を再計算する必要がありました。 また、一般的に、不安定なトポロジでトランザクションを処理する必要がある場合、予測が困難なエラーが発生する可能性があります。
問題
問題を伴わないグローバルな変化とは? これらの最初はトポロジの変更でした。 サービスの展開時であっても、ノードはいつでもクラスターに出入りできることを理解する必要があります。 さらに、展開時にノードがクラスターに入る場合、サービスに関するすべての情報を新しいノードに一貫して転送する必要があります。 そして、すでに展開されているものだけでなく、現在および将来の展開についても話し合っています。
これは、別のリストにまとめることができる問題の1つにすぎません。
- ノードの起動時に静的に構成されたサービスを展開する方法は?
- クラスターからのノードの終了-ホストがホストする場合はどうなりますか?
- コーディネーターが変更された場合はどうすればよいですか?
- クライアントがクラスターに再接続した場合はどうすればよいですか?
- 有効化/無効化のリクエストを処理する必要がありますか?
- しかし、Destroyキャッシュと呼ばれ、アフィニティサービスがそれに関連付けられている場合はどうでしょうか。
そして、これはすべてから遠いです。
解決策
ターゲットとして、メッセージを使用した通信プロセスの実装を伴うイベント駆動型アプローチを選択しました。 Igniteはすでに、ノード間でメッセージを転送できるようにする2つのコンポーネント(communication-spiとdiscovery-spi)を実装しています。
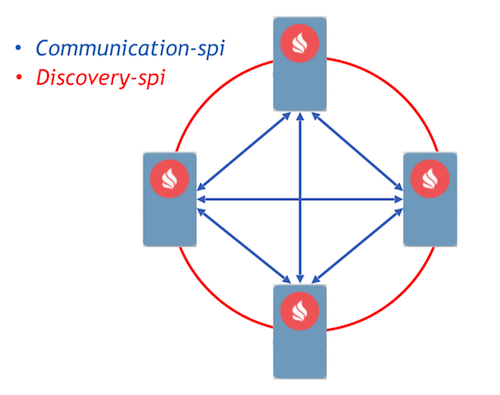
Communication-spiにより、ノードはメッセージを直接通信および転送できます。 大量のデータを送信するのに適しています。 Discovery-spiを使用すると、クラスター内のすべてのノードにメッセージを送信できます。 標準実装では、これはリングトポロジに従って行われます。 Zookeeperとの統合もあります。この場合、スタートポロジが使用されます。 注目に値するもう1つの重要な点:discovery-spiは、メッセージがすべてのノードに正しい順序で配信されることを保証します。
展開プロトコルを検討してください。 展開と配布のすべてのユーザーリクエストは、discovery-spiを介して送信されます。 これにより、次のことが保証されます。
- 要求は、クラスター内のすべてのノードによって受信されます。 これにより、コーディネーターの変更時にリクエストの処理を続行できます。 また、1つのメッセージで、各ノードに、サービスの構成やシリアル化されたインスタンスなど、必要なすべてのメタデータが含まれることを意味します。
- 厳密なメッセージ配信順序により、構成の競合と競合する要求を解決できます。
- トポロジーへのノードの入力もdiscovery-spiによって処理されるため、サービスの操作に必要なすべてのデータが新しいノードに届きます。
要求を受信すると、クラスター内のノードはそれを検証し、処理のためのタスクを形成します。 これらのタスクはキューに入れられ、別のワーカーによって別のスレッドで処理されます。 これは、展開にかなりの時間がかかり、高価なディスカバリストリームが受け入れられないため、このように実装されます。
キューからのすべての要求は、デプロイメントマネージャーによって処理されます。 彼には、このキューからタスクを引き出し、初期化して展開を開始する特別なワーカーがいます。 この後、次のアクションが発生します。
- 新しい決定論的割り当て機能により、各ノードは独立して分布を計算します。
- ノードはデプロイメントの結果とともにメッセージを形成し、コーディネーターに送信します。
- コーディネーターはすべてのメッセージを集約し、展開プロセス全体の結果を生成します。結果は、discovery-spiを介してクラスター内のすべてのノードに送信されます。
- 結果を受信すると、展開プロセスは終了し、その後タスクはキューから削除されます。

新しいイベント駆動型設計:org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
展開時にエラーが発生した場合、ノードはすぐにこのエラーをメッセージに含め、コーディネーターに送信します。 メッセージの集約後、コーディネーターは展開中のすべてのエラーに関する情報を取得し、discovery-spiを介してこのメッセージを送信します。 エラー情報は、クラスター内のすべてのノードで利用できます。
このアルゴリズムに従って、サービスグリッド内のすべての重要なイベントが処理されます。 たとえば、トポロジの変更は、discovery-spiメッセージでもあります。 そして、一般的に、プロトコルが何であるかと比較すると、プロトコルは非常に軽量で信頼性が高いことが判明しました。 展開中の状況を処理するため。
次に何が起こるか
今、計画について。 Igniteプロジェクトの主要な開発は、Igniteを改善するためのイニシアチブ、いわゆるIEPとして実行されます。 サービスグリッドの再設計には、「サービスグリッドのオイル変更」という冗談の名前を持つIEP- IEP No. 17もあります。 しかし実際には、エンジンのオイルではなく、エンジン全体を交換しました。
IEPのタスクを2つのフェーズに分割しました。 1つは主要なフェーズで、展開プロトコルの変更で構成されます。 すでにウィザードに組み込まれているため、バージョン2.8に表示される新しいサービスグリッドを試すことができます。 2番目のフェーズには、他の多くのタスクが含まれます。
- ホットリープ
- サービスのバージョン管理
- 弾力性の向上
- シンクライアント
- さまざまなメトリックを監視およびカウントするためのツール
最後に、フォールトトレラントな高可用性システムを構築するためのService Gridをアドバイスできます。 また、 dev-listおよびuser-listに招待して、経験を共有してください。 あなたの経験はコミュニティにとって非常に重要です。これは、次に進むべき場所、将来コンポーネントを開発する方法を理解するのに役立ちます。