
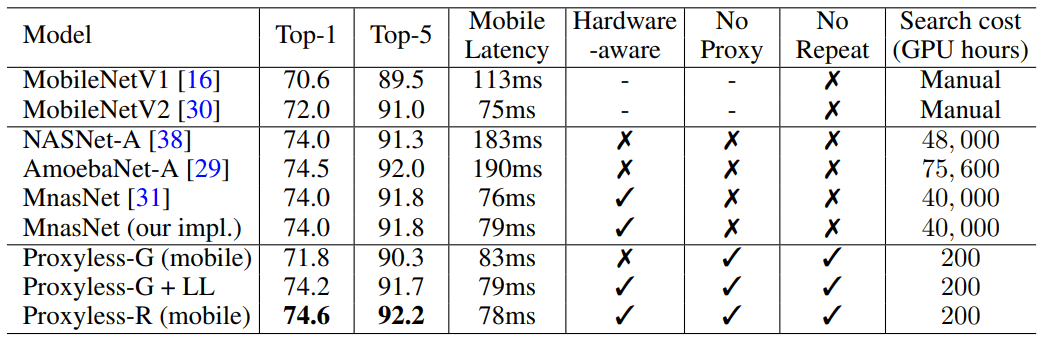
ProxylessNASは、特定のタスクおよび機器のニューラルネットワークのアーキテクチャを直接最適化します。これにより、従来のプロキシアプローチと比較して生産性が大幅に向上します。 ImageNetデータセットでは、ニューラルネットワークは200 GPU時間(対応するデバイスの200〜378倍高速)で設計され、モバイルデバイス用に自動的に設計されたCNNモデルはMobileNetV2 1.4と同じレベルの精度に達し、1.8倍高速に動作します。
マサチューセッツ工科大学の研究者は、特定のハードウェア向けの高性能ニューラルネットワークの自動設計のための効率的なアルゴリズムを開発しました、 と MIT News は書いて います。
機械学習システムの自動設計のためのアルゴリズムは、AIの分野における新しい研究分野です。 この手法はニューラルアーキテクチャ検索(NAS)と呼ばれ、難しい計算タスクと見なされます。
自動設計されたニューラルネットワークは、人間が開発したものよりも正確で効率的な設計です。 しかし、ニューラルアーキテクチャの検索には、非常に大きな計算が必要です。 たとえば、GPU上で実行するためにGoogleが最近開発した最新のNASNet-Fアルゴリズムは、48,000時間のGPUコンピューティングを使用して、画像の分類と検出に使用される1つの畳み込みニューラルネットワークを作成します。 もちろん、Googleは何百ものGPUやその他の専用ハードウェアを並行して実行できます。 たとえば、1000個のGPUでこの計算にかかるのは2日だけです。 しかし、すべての研究者がそのような機会を持っているわけではなく、Googleコンピューティングクラウドでアルゴリズムを実行すると、かなりの額に飛ぶ可能性があります。
MITの研究者は、2019年5月6日から9日に開催されるICLR 2019の学習表現に関する国際会議の記事を準備しました。 記事ProxylessNAS:ターゲットタスクとハードウェアでの直接ニューラルアーキテクチャ検索では、特定のハードウェアプラットフォーム向けの特殊な畳み込みニューラルネットワークを直接開発できるProxylessNASアルゴリズムについて説明しています。
大量の画像データで実行する場合、アルゴリズムはわずか200時間のGPU動作で最適なアーキテクチャを設計しました。 これは、他のアルゴリズムを使用したCNNアーキテクチャの開発よりも2桁高速です(表を参照)。
リソースが限られている研究者や企業は、このアルゴリズムの恩恵を受けるでしょう。 より一般的な目標は「AIを民主化すること」です、とMITのMicrosystems Technology Laboratoriesの電気工学およびコンピューターサイエンスの助教授であるソングライターのSong Han氏は言います。
カーンは、このようなNASアルゴリズムがエンジニアの知的作業に取って代わることは決してないと付け加えました。「目標は、ニューラルネットワークのアーキテクチャの設計と改善に伴う反復的で退屈な作業を軽減することです。」
彼らの研究では、研究者はニューラルネットワークの不要なコンポーネントを削除し、計算時間を短縮し、NASアルゴリズムを実行するためにハードウェアメモリの一部のみを使用する方法を見つけました。 これにより、開発されたCNNが特定のハードウェアプラットフォーム(CPU、GPU、モバイルデバイス)でより効率的に動作することが保証されます。
CNNアーキテクチャは、「フィルター」と呼ばれる調整可能なパラメーターと、それらの間の可能な関係を持つレイヤーで構成されます。 フィルターは、3×3、5×5または7×7などの正方形グリッドの画像ピクセルを処理します。各フィルターは1つの正方形をカバーします。 実際、フィルターは画像内を移動し、ピクセルグリッドの色を1つのピクセルに結合します。 さまざまなレイヤーで、さまざまな方法で接続されてデータを交換するさまざまなサイズのフィルター。 CNN出力は、すべてのフィルターから結合された圧縮画像を生成します。 可能なアーキテクチャの数、いわゆる「検索スペース」は非常に大きいため、NASを使用して大量の画像データセットでニューラルネットワークを作成するには、膨大なリソースが必要です。 通常、開発者はより小さなデータセット(プロキシ)でNASを実行し、結果のCNNアーキテクチャをターゲットに転送します。 ただし、この方法ではモデルの精度が低下します。 さらに、同じアーキテクチャがすべてのハードウェアプラットフォームに適用され、パフォーマンスの問題につながります。
MITの研究者は、ImageNetデータセットで画像を直接分類するタスクに関する新しいアルゴリズムのトレーニングとテストを行いました。ImageNetデータセットには、1000クラスの何百万もの画像が含まれています。 最初に、CNN候補のすべての可能な「パス」を含むサーチスペースを作成し、アルゴリズムがそれらの中から最適なアーキテクチャを見つけるようにしました。 サーチスペースをGPUのメモリに収めるために、彼らはパスレベル2値化と呼ばれる方法を使用しました。これは一度に1つのパスのみを保存し、メモリを1桁節約します。 2値化は、パスレベルのプルーニングと組み合わせられます。これは、システムを損傷することなく、ニューラルネットワーク内のどのニューロンを安全に削除できるかを伝統的に研究する方法です。 ニューロンを削除する代わりに、NASアルゴリズムはパス全体を削除し、アーキテクチャを完全に変更します。
最終的に、アルゴリズムは考えられないすべてのパスを遮断し、最も高い確率でパスのみを保存します-これが究極のCNNアーキテクチャです。
この図は、GPU、CPU、モバイルプロセッサ(それぞれ上から下)用にProxylessNASが開発した画像を分類するためのニューラルネットワークのサンプルを示しています。
