tidyrパッケージは、R言語で最も人気のあるライブラリの1つであるtidyverseのコアの一部です。
パッケージの主な目的は、データをきれいに表示することです。
このパッケージに特化したHabréの出版物はすでにありますが、それは2015年からのものです。 そして、数日前に著者のハドリー・ウィッカムが発表した最も関連性の高い変更についてお話したいと思います。
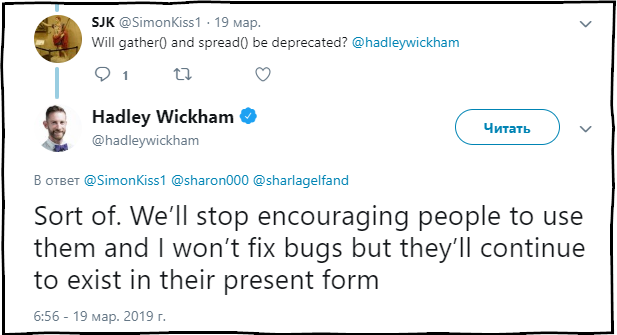
SJK : Gather ()およびSpread()関数は廃止されますか?
Hadley Wickham :ある程度。 これらの関数の使用を推奨することをやめ、それらのエラーを修正しますが、それらは現在の状態でパッケージ内に存在し続けます。
内容
- TidyDataのコンセプト
- tidyrパッケージに含まれる主な機能
- データをワイド形式からロング形式に、またはその逆に変換するための新しいコンセプト
- tidyr 0.8.3.9000の最新バージョンのインストール
- 新機能に切り替える
- データをワイド形式からロング形式に変換する簡単な例
- 仕様書
- 複数の値(.value)を使用した指定
- 日付フレームをロングからワイドに変換する
- 新しいtidyrコンセプトを使用したいくつかの高度な例
- おわりに
TidyDataのコンセプト
tidyrの目的は、データをいわゆるきちんとした外観にすることです。 正確なデータとは、次のようなデータです。
- 各変数は列にあります。
- 各観測は線です。
- 各値はセルです。
整頓されたデータに与えられるデータは、分析中の作業がはるかに単純で便利です。
tidyrパッケージに含まれる主な機能
tidyrには、テーブルを変換するための一連の関数が含まれています。
-
fill()
-列の欠損値を以前の値で埋めます。 -
separate()
-セパレータを介して1つのフィールドを複数に分割します。 -
unite()
-いくつかのフィールドを1つに結合する操作を実行します。これは、separate()
関数の逆です。 -
pivot_longer()
-データをワイド形式からロング形式に変換する関数。 -
pivot_wider()
-データを長い形式から広い形式に変換する関数。 操作は、pivot_longer()
関数によって実行される操作の反対です。 -
gather()
deprecated-データをワイド形式からロング形式に変換する関数。 -
spread()
非推奨 -データを長い形式から広い形式に変換する関数。gather()
関数が実行するものの逆の操作。
データをワイド形式からロング形式に、またはその逆に変換するための新しいコンセプト
以前は、関数gather()
およびspread()
この種の変換に使用されていました。 これらの関数の存在の長年にわたって、パッケージの作成者を含むほとんどのユーザーにとって、これらの関数の名前とその引数は明確ではなく、それらを見つけて、これらの関数のどれが日付フレームを広くから長くするかを理解するのが困難であることが明らかになりましたフォーマットおよびその逆。
これに関連して、日付フレームを変換するように設計された2つの新しい重要な関数がtidyrに追加されました。
新しいpivot_longer()
とpivot_wider()
関数は、John MountとNina Zumelによって作成されたcdataパッケージの関数の一部に触発されました。
tidyr 0.8.3.9000の最新バージョンのインストール
新しい機能を利用できるtidyr 0.8.3.9000 パッケージの新しい最新バージョンをインストールするには、次のコードを使用します。
devtools::install_github("tidyverse/tidyr")
執筆時点では、これらの関数はGitHubのパッケージの開発バージョンでのみ利用可能です。
新機能に切り替える
実際、古いスクリプトを転送して新しい関数を処理することは難しくありません。理解を深めるために、古い関数のドキュメントから例を取り上げ、新しいpivot_*()
関数を使用して同じ操作がどのように実行されるかを示します。
ワイド形式からロング形式に変換します。
# example library(dplyr) stocks <- data.frame( time = as.Date('2009-01-01') + 0:9, X = rnorm(10, 0, 1), Y = rnorm(10, 0, 2), Z = rnorm(10, 0, 4) ) # old stocks_gather <- stocks %>% gather(key = stock, value = price, -time) # new stocks_long <- stocks %>% pivot_longer(cols = -time, names_to = "stock", values_to = "price")
長い形式をワイドに変換します。
# old stocks_spread <- stocks_gather %>% spread(key = stock, value = price) # new stock_wide <- stocks_long %>% pivot_wider(names_from = "stock", values_from = "price")
なぜなら 上記のpivot_longer()
およびpivot_wider()
では、ソース表stocksにはnames_toおよびvalues_to引数に列がリストされていないため、それらの名前は引用符で示す必要があります。
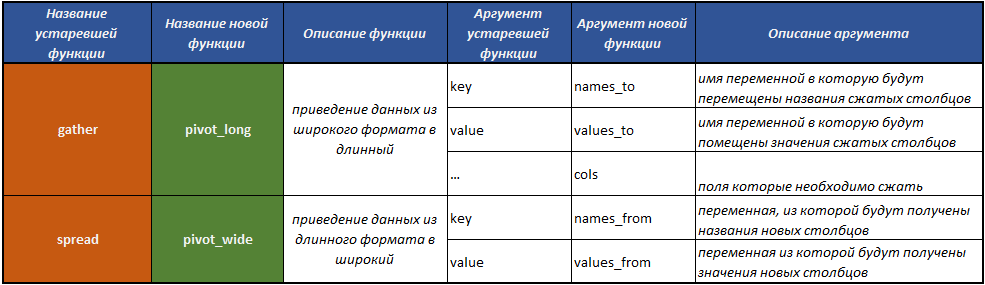
新しいtidyrコンセプトの使用に切り替える方法を最も簡単に理解できるテーブル。
著者からのメモ
以下のテキストはすべて順応性があり、整頓されたライブラリの公式サイトからのビネットの無料翻訳とさえ言えます。
データをワイド形式からロング形式に変換する簡単な例
pivot_longer ()
-列の数を減らし、行の数を増やすことで、データセットを長くします。

この記事に記載されている例を実行するには、まず必要なパッケージを接続する必要があります。
library(tidyr) library(dplyr) library(readr)
(特に)人々が自分の宗教と年収について尋ねられた調査の結果の表があると仮定します。
#> # A tibble: 18 x 11 #> religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` #> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 Agnostic 27 34 60 81 76 137 #> 2 Atheist 12 27 37 52 35 70 #> 3 Buddhist 27 21 30 34 33 58 #> 4 Catholic 418 617 732 670 638 1116 #> 5 Don't k… 15 14 15 11 10 35 #> 6 Evangel… 575 869 1064 982 881 1486 #> 7 Hindu 1 9 7 9 11 34 #> 8 Histori… 228 244 236 238 197 223 #> 9 Jehovah… 20 27 24 24 21 30 #> 10 Jewish 19 19 25 25 30 95 #> # … with 8 more rows, and 4 more variables: `$75-100k` <dbl>, #> # `$100-150k` <dbl>, `>150k` <dbl>, `Don't know/refused` <dbl>
この表には、回答者の宗教データが行に含まれており、収入レベルは列名全体に散らばっています。 各カテゴリの回答者の数は、宗教と収入レベルの交差点のセル値に保存されます。 テーブルをきちんとした正しい形式にするには、 pivot_longer()
使用します。
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count")
pew %>% pivot_longer(cols = -religion, names_to = "income", values_to = "count") #> # A tibble: 180 x 3 #> religion income count #> <chr> <chr> <dbl> #> 1 Agnostic <$10k 27 #> 2 Agnostic $10-20k 34 #> 3 Agnostic $20-30k 60 #> 4 Agnostic $30-40k 81 #> 5 Agnostic $40-50k 76 #> 6 Agnostic $50-75k 137 #> 7 Agnostic $75-100k 122 #> 8 Agnostic $100-150k 109 #> 9 Agnostic >150k 84 #> 10 Agnostic Don't know/refused 96 #> # … with 170 more rows
pivot_longer()
引数
- 最初の引数colsは 、マージする列を示します。 この場合、 timeを除くすべての列。
- names_to引数は、結合した列名から作成される変数の名前を提供します。
- values_toは、 結合された列のセル値に格納されたデータから作成される変数の名前を提供します。
仕様書
これは、 tidyrパッケージの新しい機能です。これは、廃止された機能を操作するときに以前は使用できませんでした。
仕様はデータフレームであり、その各行は新しい出力日付フレームの1つの列に対応し、次で始まる2つの特別な列です。
- .nameには、列の元の名前が含まれます。
- .valueには、セル値が入る列の名前が含まれます。
仕様の残りの列は、 .nameの圧縮可能な列の名前が新しい列にどのように表示されるかを反映しています。
仕様では、列名に格納されるメタデータについて説明します。各列に1行、各変数に1列を組み合わせて列名と組み合わせます。おそらくこの定義は混乱しているように見えますが、いくつかの例を検討すると、すべてがより明確になります。
仕様の意味は、変換されたデータフレームの新しいメタデータを取得、変更、および設定できることです。
pivot_longer_spec()
関数は、テーブルをワイド形式からロング形式に変換するときに仕様を操作するためにpivot_longer_spec()
れます。
この関数の動作方法は、日付フレームを取得し、上記のようにメタデータを生成します。
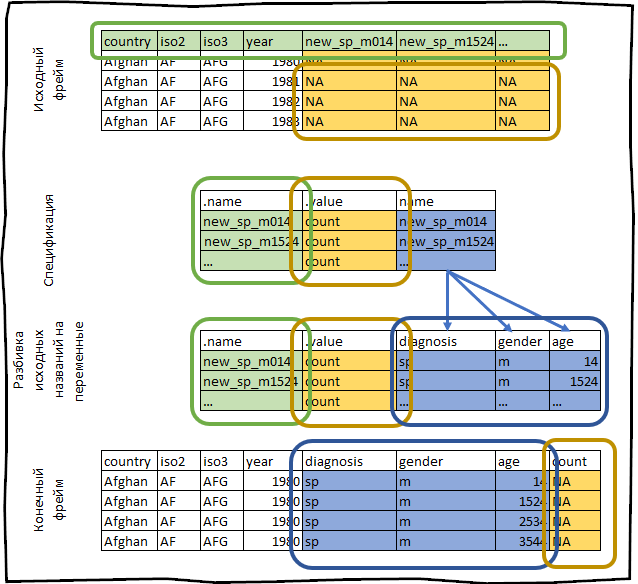
たとえば、 tidyrパッケージに付属しているwhoデータセットを見てみましょう。 このデータセットには、結核の発生率について国際保健機関から提供された情報が含まれています。
who #> # A tibble: 7,240 x 60 #> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 #> <chr> <chr> <chr> <int> <int> <int> <int> #> 1 Afghan… AF AFG 1980 NA NA NA #> 2 Afghan… AF AFG 1981 NA NA NA #> 3 Afghan… AF AFG 1982 NA NA NA #> 4 Afghan… AF AFG 1983 NA NA NA #> 5 Afghan… AF AFG 1984 NA NA NA #> 6 Afghan… AF AFG 1985 NA NA NA #> 7 Afghan… AF AFG 1986 NA NA NA #> 8 Afghan… AF AFG 1987 NA NA NA #> 9 Afghan… AF AFG 1988 NA NA NA #> 10 Afghan… AF AFG 1989 NA NA NA #> # … with 7,230 more rows, and 53 more variables
仕様を作成します。
spec <- who %>% pivot_longer_spec(new_sp_m014:newrel_f65, values_to = "count")
#> # A tibble: 56 x 3 #> .name .value name #> <chr> <chr> <chr> #> 1 new_sp_m014 count new_sp_m014 #> 2 new_sp_m1524 count new_sp_m1524 #> 3 new_sp_m2534 count new_sp_m2534 #> 4 new_sp_m3544 count new_sp_m3544 #> 5 new_sp_m4554 count new_sp_m4554 #> 6 new_sp_m5564 count new_sp_m5564 #> 7 new_sp_m65 count new_sp_m65 #> 8 new_sp_f014 count new_sp_f014 #> 9 new_sp_f1524 count new_sp_f1524 #> 10 new_sp_f2534 count new_sp_f2534 #> # … with 46 more rows
フィールドcountry 、 iso2 、 iso3はすでに変数です。 私たちのタスクは、列をnew_sp_m014からnewrel_f65に反転さ せることです 。
これらの列の名前には、次の情報が格納されます。
- 接頭辞
new_
は、列に結核の新しい症例に関するデータが含まれることを示し、現在の日付フレームには新しい疾患に関する情報のみが含まれるため、現在のコンテキストのこの接頭辞には意味がありません。 -
sp
/rel
/sp
/ep
は、病気を診断する方法を説明しています。 - 患者の
m
/f
性別。 -
014
患者の年齢範囲。
正規表現を使用したextract()
関数を使用して、これらの列を分離できます。
spec <- spec %>% extract(name, c("diagnosis", "gender", "age"), "new_?(.*)_(.)(.*)")
#> # A tibble: 56 x 5 #> .name .value diagnosis gender age #> <chr> <chr> <chr> <chr> <chr> #> 1 new_sp_m014 count sp m 014 #> 2 new_sp_m1524 count sp m 1524 #> 3 new_sp_m2534 count sp m 2534 #> 4 new_sp_m3544 count sp m 3544 #> 5 new_sp_m4554 count sp m 4554 #> 6 new_sp_m5564 count sp m 5564 #> 7 new_sp_m65 count sp m 65 #> 8 new_sp_f014 count sp f 014 #> 9 new_sp_f1524 count sp f 1524 #> 10 new_sp_f2534 count sp f 2534 #> # … with 46 more rows
これはソースデータセットの列名のインデックスであるため、 .name列は変更しないでください。
性別と年齢( 性別と年齢の列)には固定値と既知の値があるため、これらの列を係数に変換することが推奨されます。
spec <- spec %>% mutate( gender = factor(gender, levels = c("f", "m")), age = factor(age, levels = unique(age), ordered = TRUE) )
最後に、作成した仕様をwhoフレームの元の日付に適用するには、 pivot_longer()
関数でspec引数を使用する必要があります。
who %>% pivot_longer(spec = spec)
#> # A tibble: 405,440 x 8 #> country iso2 iso3 year diagnosis gender age count #> <chr> <chr> <chr> <int> <chr> <fct> <ord> <int> #> 1 Afghanistan AF AFG 1980 sp m 014 NA #> 2 Afghanistan AF AFG 1980 sp m 1524 NA #> 3 Afghanistan AF AFG 1980 sp m 2534 NA #> 4 Afghanistan AF AFG 1980 sp m 3544 NA #> 5 Afghanistan AF AFG 1980 sp m 4554 NA #> 6 Afghanistan AF AFG 1980 sp m 5564 NA #> 7 Afghanistan AF AFG 1980 sp m 65 NA #> 8 Afghanistan AF AFG 1980 sp f 014 NA #> 9 Afghanistan AF AFG 1980 sp f 1524 NA #> 10 Afghanistan AF AFG 1980 sp f 2534 NA #> # … with 405,430 more rows
今やったことはすべて、次のように概略的に表すことができます。
複数の値(.value)を使用した指定
上記の例では、 .value仕様列には値が1つしか含まれていませんでした。ほとんどの場合、これは起こります。
ただし、値のデータ型が異なる列からデータを収集する必要がある場合に、状況が発生することがあります。 廃止されたspread()
関数では、これは非常に困難です。
次の例は、 data.tableパッケージのビネットから借用しています。
トレーニングデータフレームを作成しましょう。
family <- tibble::tribble( ~family, ~dob_child1, ~dob_child2, ~gender_child1, ~gender_child2, 1L, "1998-11-26", "2000-01-29", 1L, 2L, 2L, "1996-06-22", NA, 2L, NA, 3L, "2002-07-11", "2004-04-05", 2L, 2L, 4L, "2004-10-10", "2009-08-27", 1L, 1L, 5L, "2000-12-05", "2005-02-28", 2L, 1L, ) family <- family %>% mutate_at(vars(starts_with("dob")), parse_date)
#> # A tibble: 5 x 5 #> family dob_child1 dob_child2 gender_child1 gender_child2 #> <int> <date> <date> <int> <int> #> 1 1 1998-11-26 2000-01-29 1 2 #> 2 2 1996-06-22 NA 2 NA #> 3 3 2002-07-11 2004-04-05 2 2 #> 4 4 2004-10-10 2009-08-27 1 1 #> 5 5 2000-12-05 2005-02-28 2 1
各行の作成された日付フレームには、1つの家族の子に関するデータが含まれています。 家族には1人または2人の子供がいます。 各子供について、生年月日と性別のデータが提供され、各子供のデータは別々の列にあります。私たちのタスクは、このデータを分析に適した形式にすることです。
各子供に関する情報を持つ2つの変数があることに注意してください:彼の性別と生年月日(接頭辞dopの列には生年月日が、接頭辞性別の列には子供の性別が含まれます)。 予想される結果では、それらは別々の列に配置する必要があります。 これを行うには、 .value
列に2つの異なる値を持つ仕様を生成します。
spec <- family %>% pivot_longer_spec(-family) %>% separate(col = name, into = c(".value", "child"))%>% mutate(child = parse_number(child))
#> # A tibble: 4 x 3 #> .name .value child #> <chr> <chr> <dbl> #> 1 dob_child1 dob 1 #> 2 dob_child2 dob 2 #> 3 gender_child1 gender 1 #> 4 gender_child2 gender 2
それでは、上記のコードによって実行されるステップを見ていきましょう。
-
pivot_longer_spec(-family)
列を除くすべての使用可能な列を圧縮する仕様を作成します。 -
separate(col = name, into = c(".value", "child"))
。valueseparate(col = name, into = c(".value", "child"))
-ソースフィールドの名前を含む.name列を分離し、下線を引いて.valueおよびchild列に値を入れます。 -
mutate(child = parse_number(child))
- 子フィールドの値をテキストから数値データ型に変換します。
これで、受信した仕様を初期データフレームに適用し、テーブルを目的の形式にすることができます。
family %>% pivot_longer(spec = spec, na.rm = T)
#> # A tibble: 9 x 4 #> family child dob gender #> <int> <dbl> <date> <int> #> 1 1 1 1998-11-26 1 #> 2 1 2 2000-01-29 2 #> 3 2 1 1996-06-22 2 #> 4 3 1 2002-07-11 2 #> 5 3 2 2004-04-05 2 #> 6 4 1 2004-10-10 1 #> 7 4 2 2009-08-27 1 #> 8 5 1 2000-12-05 2 #> 9 5 2 2005-02-28 1
引数na.rm = TRUE
を使用します。これは、現在のデータ形式により、存在しない観測値に対して追加の行が作成されるためです。 なぜなら ファミリー2には子が1つしかなく、 na.rm = TRUE
、ファミリー2の出力に1行が含まれます。
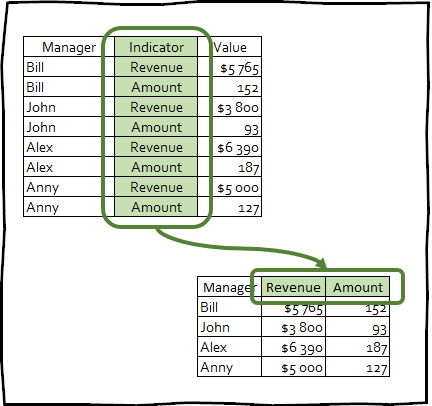
日付フレームをロングからワイドに変換する
pivot_wider()
-は逆変換であり、逆も同様です。行の数を減らすことにより、フレーム日付の列の数を増やします。
この種類の変換は、データをきれいに表示するために使用されることはほとんどありませんが、プレゼンテーションで使用されるピボットテーブルを作成したり、他のツールと統合したりする場合に役立ちます。
実際、関数pivot_longer()
とpivot_wider()
は対称的であり、反対のアクションを実行します。すなわち、 df %>% pivot_longer(spec = spec) %>% pivot_wider(spec = spec)
およびdf %>% pivot_wider(spec = spec) %>% pivot_longer(spec = spec)
は元のdfを返します。
テーブルをワイド形式にキャストする最も簡単な例
pivot_wider()
関数の動作を示すために、 fish_encountersデータセットを使用します。 このデータセットには 、さまざまなステーションが川沿いの魚の動きを記録する方法に関する情報が格納されます。
#> # A tibble: 114 x 3 #> fish station seen #> <fct> <fct> <int> #> 1 4842 Release 1 #> 2 4842 I80_1 1 #> 3 4842 Lisbon 1 #> 4 4842 Rstr 1 #> 5 4842 Base_TD 1 #> 6 4842 BCE 1 #> 7 4842 BCW 1 #> 8 4842 BCE2 1 #> 9 4842 BCW2 1 #> 10 4842 MAE 1 #> # … with 104 more rows
ほとんどの場合、この表は、各ステーションの情報を別々の列に入力すると、より有益で使いやすくなります。
fish_encounters %>% pivot_wider(names_from = station, values_from = seen)
fish_encounters %>% pivot_wider(names_from = station, values_from = seen) #> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 NA NA NA NA NA #> 5 4847 1 1 1 NA NA NA NA NA NA NA #> 6 4848 1 1 1 1 NA NA NA NA NA NA #> 7 4849 1 1 NA NA NA NA NA NA NA NA #> 8 4850 1 1 NA 1 1 1 1 NA NA NA #> 9 4851 1 1 NA NA NA NA NA NA NA NA #> 10 4854 1 1 NA NA NA NA NA NA NA NA #> # … with 9 more rows, and 1 more variable: MAW <int>
このデータセットは、ステーションによって魚が検出された場合にのみ情報を記録します。 あるステーションによって魚が修正されなかった場合、このデータはテーブルに表示されません。 これは、NAによって出力が読み込まれることを意味します。
ただし、この場合、レコードが存在しないということは魚が気付かなかったことを意味することがわかっているため、 pivot_wider()
関数でvalues_fill引数を使用し、これらの欠損値をゼロで埋めることができます。
fish_encounters %>% pivot_wider( names_from = station, values_from = seen, values_fill = list(seen = 0) )
#> # A tibble: 19 x 12 #> fish Release I80_1 Lisbon Rstr Base_TD BCE BCW BCE2 BCW2 MAE #> <fct> <int> <int> <int> <int> <int> <int> <int> <int> <int> <int> #> 1 4842 1 1 1 1 1 1 1 1 1 1 #> 2 4843 1 1 1 1 1 1 1 1 1 1 #> 3 4844 1 1 1 1 1 1 1 1 1 1 #> 4 4845 1 1 1 1 1 0 0 0 0 0 #> 5 4847 1 1 1 0 0 0 0 0 0 0 #> 6 4848 1 1 1 1 0 0 0 0 0 0 #> 7 4849 1 1 0 0 0 0 0 0 0 0 #> 8 4850 1 1 0 1 1 1 1 0 0 0 #> 9 4851 1 1 0 0 0 0 0 0 0 0 #> 10 4854 1 1 0 0 0 0 0 0 0 0 #> # … with 9 more rows, and 1 more variable: MAW <int>
複数のソース変数から列名を生成する
製品、国、年の組み合わせを含むテーブルがあると想像してください。 テストフレームの日付を生成するには、次のコードを実行できます。
df <- expand_grid( product = c("A", "B"), country = c("AI", "EI"), year = 2000:2014 ) %>% filter((product == "A" & country == "AI") | product == "B") %>% mutate(value = rnorm(nrow(.)))
#> # A tibble: 45 x 4 #> product country year value #> <chr> <chr> <int> <dbl> #> 1 A AI 2000 -2.05 #> 2 A AI 2001 -0.676 #> 3 A AI 2002 1.60 #> 4 A AI 2003 -0.353 #> 5 A AI 2004 -0.00530 #> 6 A AI 2005 0.442 #> 7 A AI 2006 -0.610 #> 8 A AI 2007 -2.77 #> 9 A AI 2008 0.899 #> 10 A AI 2009 -0.106 #> # … with 35 more rows
私たちのタスクは、1つの列に製品と国の各組み合わせのデータが含まれるように、日付フレームを拡張することです。 これを行うには、 names_from引数に結合するフィールドの名前を含むベクトルを渡すだけです。
df %>% pivot_wider(names_from = c(product, country), values_from = "value")
#> # A tibble: 15 x 4 #> year A_AI B_AI B_EI #> <int> <dbl> <dbl> <dbl> #> 1 2000 -2.05 0.607 1.20 #> 2 2001 -0.676 1.65 -0.114 #> 3 2002 1.60 -0.0245 0.501 #> 4 2003 -0.353 1.30 -0.459 #> 5 2004 -0.00530 0.921 -0.0589 #> 6 2005 0.442 -1.55 0.594 #> 7 2006 -0.610 0.380 -1.28 #> 8 2007 -2.77 0.830 0.637 #> 9 2008 0.899 0.0175 -1.30 #> 10 2009 -0.106 -0.195 1.03 #> # … with 5 more rows
また、 pivot_wider()
関数に仕様を適用することもできます。 しかし、 pivot_wider()
に入力されるとpivot_wider()
仕様は、 pivot_longer()
反対をpivot_longer()
指定された列は、 pivot_longer()
および他の列の値を使用して作成されます。
このデータセットでは、データに存在するものだけでなく、国と製品の考えられる各組み合わせに独自の列を持たせたい場合、ユーザー仕様を生成できます。
spec <- df %>% expand(product, country, .value = "value") %>% unite(".name", product, country, remove = FALSE)
#> # A tibble: 4 x 4 #> .name product country .value #> <chr> <chr> <chr> <chr> #> 1 A_AI A AI value #> 2 A_EI A EI value #> 3 B_AI B AI value #> 4 B_EI B EI value
df %>% pivot_wider(spec = spec) %>% head()
#> # A tibble: 6 x 5 #> year A_AI A_EI B_AI B_EI #> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2000 -2.05 NA 0.607 1.20 #> 2 2001 -0.676 NA 1.65 -0.114 #> 3 2002 1.60 NA -0.0245 0.501 #> 4 2003 -0.353 NA 1.30 -0.459 #> 5 2004 -0.00530 NA 0.921 -0.0589 #> 6 2005 0.442 NA -1.55 0.594
新しいtidyrコンセプトを使用したいくつかの高度な例
例として米国の収入と賃貸人口調査のデータセットを使用して、データをきれいに表示する
us_rent_incomeデータセットには、2017年の米国の各州の平均収入と家賃に関する情報が含まれています(データセットはtidycensusパッケージで利用可能です)。
us_rent_income #> # A tibble: 104 x 5 #> GEOID NAME variable estimate moe #> <chr> <chr> <chr> <dbl> <dbl> #> 1 01 Alabama income 24476 136 #> 2 01 Alabama rent 747 3 #> 3 02 Alaska income 32940 508 #> 4 02 Alaska rent 1200 13 #> 5 04 Arizona income 27517 148 #> 6 04 Arizona rent 972 4 #> 7 05 Arkansas income 23789 165 #> 8 05 Arkansas rent 709 5 #> 9 06 California income 29454 109 #> 10 06 California rent 1358 3 #> # … with 94 more rows
us_rent_income データセットのデータが保存されている形式でそれらを操作することは非常に不便なので、列rent 、 rent_moe 、 come 、 Income_moeを含むデータセットを作成したいと思います。 この仕様を作成する方法は多数ありますが、主なことは、変数値と推定値/ moeの各組み合わせを生成してから、列名を生成する必要があることです。
spec <- us_rent_income %>% expand(variable, .value = c("estimate", "moe")) %>% mutate( .name = paste0(variable, ifelse(.value == "moe", "_moe", "")) )
#> # A tibble: 4 x 3 #> variable .value .name #> <chr> <chr> <chr> #> 1 income estimate income #> 2 income moe income_moe #> 3 rent estimate rent #> 4 rent moe rent_moe
この仕様をpivot_wider()
提供すると、私たちが探している結果が得られます:
us_rent_income %>% pivot_wider(spec = spec)
#> # A tibble: 52 x 6 #> GEOID NAME income income_moe rent rent_moe #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> #> 1 01 Alabama 24476 136 747 3 #> 2 02 Alaska 32940 508 1200 13 #> 3 04 Arizona 27517 148 972 4 #> 4 05 Arkansas 23789 165 709 5 #> 5 06 California 29454 109 1358 3 #> 6 08 Colorado 32401 109 1125 5 #> 7 09 Connecticut 35326 195 1123 5 #> 8 10 Delaware 31560 247 1076 10 #> 9 11 District of Columbia 43198 681 1424 17 #> 10 12 Florida 25952 70 1077 3 #> # … with 42 more rows
世界銀行
データセットを適切な形式にするには、いくつかの手順が必要になる場合があります。
world_bank_pop データセットには、2000年から2018年までの各国の人口に関する世界銀行のデータが含まれています。
#> # A tibble: 1,056 x 20 #> country indicator `2000` `2001` `2002` `2003` `2004` `2005` `2006` #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 ABW SP.URB.T… 4.24e4 4.30e4 4.37e4 4.42e4 4.47e+4 4.49e+4 4.49e+4 #> 2 ABW SP.URB.G… 1.18e0 1.41e0 1.43e0 1.31e0 9.51e-1 4.91e-1 -1.78e-2 #> 3 ABW SP.POP.T… 9.09e4 9.29e4 9.50e4 9.70e4 9.87e+4 1.00e+5 1.01e+5 #> 4 ABW SP.POP.G… 2.06e0 2.23e0 2.23e0 2.11e0 1.76e+0 1.30e+0 7.98e-1 #> 5 AFG SP.URB.T… 4.44e6 4.65e6 4.89e6 5.16e6 5.43e+6 5.69e+6 5.93e+6 #> 6 AFG SP.URB.G… 3.91e0 4.66e0 5.13e0 5.23e0 5.12e+0 4.77e+0 4.12e+0 #> 7 AFG SP.POP.T… 2.01e7 2.10e7 2.20e7 2.31e7 2.41e+7 2.51e+7 2.59e+7 #> 8 AFG SP.POP.G… 3.49e0 4.25e0 4.72e0 4.82e0 4.47e+0 3.87e+0 3.23e+0 #> 9 AGO SP.URB.T… 8.23e6 8.71e6 9.22e6 9.77e6 1.03e+7 1.09e+7 1.15e+7 #> 10 AGO SP.URB.G… 5.44e0 5.59e0 5.70e0 5.76e0 5.75e+0 5.69e+0 4.92e+0 #> # … with 1,046 more rows, and 11 more variables: `2007` <dbl>, #> # `2008` <dbl>, `2009` <dbl>, `2010` <dbl>, `2011` <dbl>, `2012` <dbl>, #> # `2013` <dbl>, `2014` <dbl>, `2015` <dbl>, `2016` <dbl>, `2017` <dbl>
私たちの目標は、各変数が別々の列にあるきちんとしたデータセットを作成することです。 どのステップが必要かはまだ明確ではありませんが、最も明らかな問題から始めましょう。1年は複数の列に分散しています。
これを修正するには、 pivot_longer()
関数を使用する必要があります。
pop2 <- world_bank_pop %>% pivot_longer(`2000`:`2017`, names_to = "year")
#> # A tibble: 19,008 x 4 #> country indicator year value #> <chr> <chr> <chr> <dbl> #> 1 ABW SP.URB.TOTL 2000 42444 #> 2 ABW SP.URB.TOTL 2001 43048 #> 3 ABW SP.URB.TOTL 2002 43670 #> 4 ABW SP.URB.TOTL 2003 44246 #> 5 ABW SP.URB.TOTL 2004 44669 #> 6 ABW SP.URB.TOTL 2005 44889 #> 7 ABW SP.URB.TOTL 2006 44881 #> 8 ABW SP.URB.TOTL 2007 44686 #> 9 ABW SP.URB.TOTL 2008 44375 #> 10 ABW SP.URB.TOTL 2009 44052 #> # … with 18,998 more rows
— indicator.
pop2 %>% count(indicator)
#> # A tibble: 4 x 2 #> indicator n #> <chr> <int> #> 1 SP.POP.GROW 4752 #> 2 SP.POP.TOTL 4752 #> 3 SP.URB.GROW 4752 #> 4 SP.URB.TOTL 4752
SP.POP.GROW — , SP.POP.TOTL — , SP.URB. * , . : area — (total urban) (population growth):
pop3 <- pop2 %>% separate(indicator, c(NA, "area", "variable"))
#> # A tibble: 19,008 x 5 #> country area variable year value #> <chr> <chr> <chr> <chr> <dbl> #> 1 ABW URB TOTL 2000 42444 #> 2 ABW URB TOTL 2001 43048 #> 3 ABW URB TOTL 2002 43670 #> 4 ABW URB TOTL 2003 44246 #> 5 ABW URB TOTL 2004 44669 #> 6 ABW URB TOTL 2005 44889 #> 7 ABW URB TOTL 2006 44881 #> 8 ABW URB TOTL 2007 44686 #> 9 ABW URB TOTL 2008 44375 #> 10 ABW URB TOTL 2009 44052 #> # … with 18,998 more rows
variable :
pop3 %>% pivot_wider(names_from = variable, values_from = value)
#> # A tibble: 9,504 x 5 #> country area year TOTL GROW #> <chr> <chr> <chr> <dbl> <dbl> #> 1 ABW URB 2000 42444 1.18 #> 2 ABW URB 2001 43048 1.41 #> 3 ABW URB 2002 43670 1.43 #> 4 ABW URB 2003 44246 1.31 #> 5 ABW URB 2004 44669 0.951 #> 6 ABW URB 2005 44889 0.491 #> 7 ABW URB 2006 44881 -0.0178 #> 8 ABW URB 2007 44686 -0.435 #> 9 ABW URB 2008 44375 -0.698 #> 10 ABW URB 2009 44052 -0.731 #> # … with 9,494 more rows
, , , -:
contacts <- tribble( ~field, ~value, "name", "Jiena McLellan", "company", "Toyota", "name", "John Smith", "company", "google", "email", "john@google.com", "name", "Huxley Ratcliffe" )
, , , . , , ("name"), , , field “name”:
contacts <- contacts %>% mutate( person_id = cumsum(field == "name") ) contacts
#> # A tibble: 6 x 3 #> field value person_id #> <chr> <chr> <int> #> 1 name Jiena McLellan 1 #> 2 company Toyota 1 #> 3 name John Smith 2 #> 4 company google 2 #> 5 email john@google.com 2 #> 6 name Huxley Ratcliffe 3
, , :
contacts %>% pivot_wider(names_from = field, values_from = value)
#> # A tibble: 3 x 4 #> person_id name company email #> <int> <chr> <chr> <chr> #> 1 1 Jiena McLellan Toyota <NA> #> 2 2 John Smith google john@google.com #> 3 3 Huxley Ratcliffe <NA> <NA>
おわりに
, tidyr , spread()
gather()
. pivot_longer()
pivot_wider()
.