私自身について
私の名前はオレグ・スビドチェンコです。現在、サンクトペテルブルク大学で3年間勉強している前に、サンクトペテルブルクHSEの物理、数学、コンピューター科学の学校で勉強しています。 私はJetBrains Researchの研究者としても働いています。 大学に入る前に、私はモスクワ州立大学のSSCで学び、モスクワのチームの一員としてコンピューターサイエンスの学童の全ロシアオリンピアードの入賞者になりました。
何が必要ですか?
強化トレーニングを試してみたい場合は、マウンテンカーのチャレンジが最適です。 今日、インストールされているGymおよびPyTorchライブラリを備えたPythonと、ニューラルネットワークに関する基本的な知識が必要です。
タスクの説明
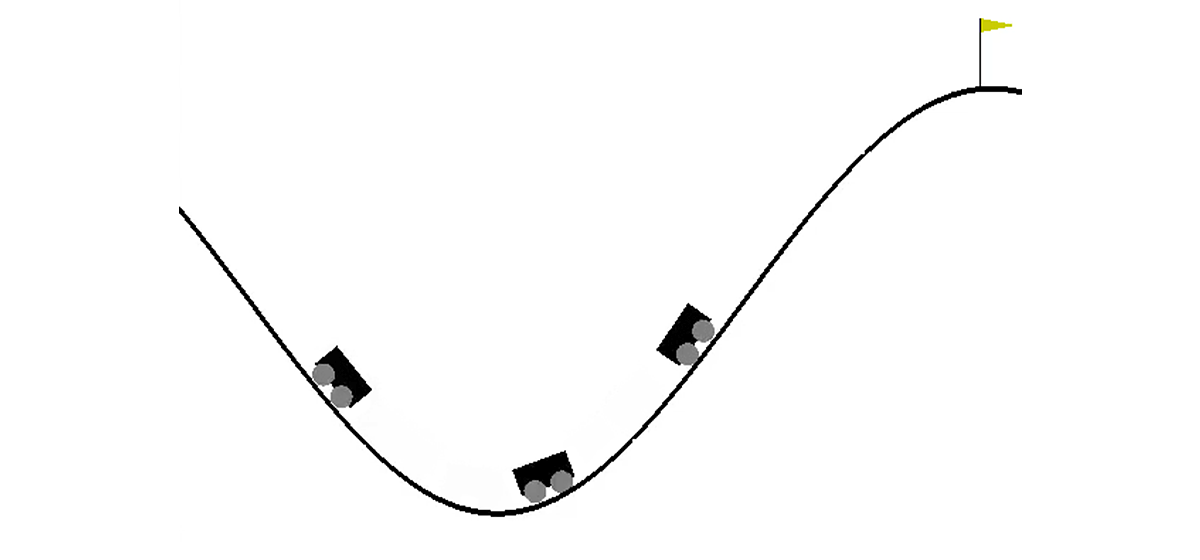
2次元の世界では、車は2つの丘の間の窪みから右の丘の頂上まで登る必要があります。 彼女は重力に打ち勝ち、最初の試みでそこに入るために十分なエンジン力を持っていないという事実によって複雑になっています。 エージェント(この場合はニューラルネットワーク)を訓練するように招待されています。エージェントは、それを制御することにより、できるだけ早く適切な丘を登ることができます。
機械制御は、環境との相互作用を通じて実行されます。 それは独立したエピソードに分割され、各エピソードは段階的に実行されます。 各ステップで、エージェントはアクションaに応じて環境から状態sおよび環境rを受け取ります。 さらに、エピソードが終了したことをメディアがさらに報告する場合があります。 この問題では、 sは数字のペアです。最初の数字はカーブ上の車の位置です(1つの座標で十分です。表面から自分自身を引き離すことはできないため)。2番目は表面上の速度です(記号付き)。 報酬rは、このタスクでは常に-1に等しい数です。 このようにして、エージェントはできるだけ早くエピソードを完了することをお勧めします。 可能なアクションは3つだけです。車を左に押し、何もせずに車を右に押します。 これらのアクションは、0から2までの数字に対応します。車が右の丘の頂上に到達した場合、またはエージェントが200歩進んだ場合、エピソードは終了する場合があります。
理論のビット
Habréには、 DQNに関する記事がすでにあり、著者は必要なすべての理論を十分に説明しています。 それでも、読みやすくするために、ここでより正式な形式で繰り返します。
強化学習タスクは、状態空間S、アクション空間A、係数のセットによって定義されます 、遷移関数Tと報酬関数R。一般に、遷移関数と報酬関数はランダム変数にできますが、ここでは、それらが一意に定義されたより単純なバージョンを検討します。 目標は、累積報酬を最大化することです。 ここで、tはメディアのステップ番号、Tはエピソードのステップ数です。
この問題を解決するために、状態sで開始するという条件で、状態sの価値関数Vを最大累積報酬の値として定義します。 このような関数を知っていれば、各ステップでsに可能な最大値を渡すだけで問題を解決できます。 ただし、すべてがそれほど単純なわけではありません。ほとんどの場合、どのアクションによって目的の状態になるかはわかりません。 したがって、関数の2番目のパラメーターとしてアクションaを追加します。 結果の関数はQ関数と呼ばれます。 状態sでアクションaを実行することで獲得できる最大の累積報酬を示します。 しかし、この関数を使用して問題を解決できます。状態sにいるとき、Q(s、a)が最大になるようなaを選択するだけです。
実際には、実際のQ関数はわかりませんが、さまざまな方法で近似できます。 そのような手法の1つに、Deep Q Network(DQN)があります。 彼の考えは、アクションのそれぞれについて、ニューラルネットワークを使用してQ関数を近似することです。
環境
さあ、練習しましょう。 まず、MountainCar環境をエミュレートする方法を学ぶ必要があります。 多数の標準強化学習環境を提供するジムライブラリは、このタスクに対処するのに役立ちます。 環境を作成するには、gymモジュールのmakeメソッドを呼び出して、目的の環境の名前をパラメーターとして渡します。
import gym env = gym.make("MountainCar-v0")
詳細なドキュメントはここにあり、環境の説明はここにあります 。
作成した環境で何ができるかをさらに詳しく考えてみましょう。
-
env.reset()
-現在のエピソードを終了し、新しいエピソードを開始します。 初期状態を返します。 -
env.step(action)
-指定されたアクションを実行します。 新しい状態、報酬、エピソードが終了したかどうか、およびデバッグに使用できる追加情報を返します。 -
env.seed(seed)
-ランダムシードを設定します。 これは、env.reset()中に初期状態がどのように生成されるかによって異なります。 -
env.render()
-環境の現在の状態を表示します。
DQNを実現します
DQNは、ニューラルネットワークを使用してQ関数を評価するアルゴリズムです。 元の記事で、 DeepMindは畳み込みニューラルネットワークを使用したAtariゲームの標準アーキテクチャを定義しました。 これらのゲームとは異なり、Mountain Carはイメージを状態として使用しないため、アーキテクチャを自分で決定する必要があります。
たとえば、それぞれに32個のニューロンの2つの隠れ層があるアーキテクチャを考えてみましょう。 各非表示レイヤーの後、 ReLUをアクティベーション関数として使用します。 状態を説明する2つの数値がニューラルネットワークの入力に供給され、出力でQ関数の推定値を取得します。
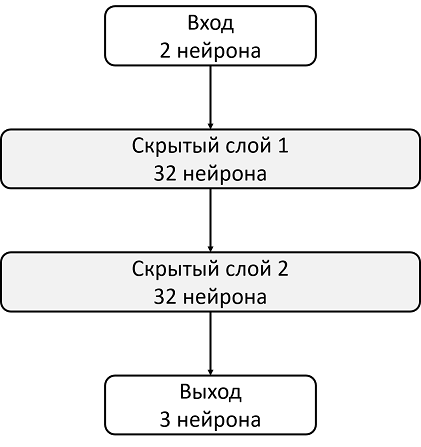
import torch.nn as nn model = nn.Sequential( nn.Linear(2, 32), nn.ReLU(), nn.Linear(32, 32), nn.ReLU(), nn.Linear(32, 3) ) target_model = copy.deepcopy(model) # def init_weights(layer): if type(layer) == nn.Linear: nn.init.xavier_normal(layer.weight) model.apply(init_weights)
GPUでニューラルネットワークをトレーニングするため、そこにネットワークをロードする必要があります。
# CPU, “cuda” “cpu” device = torch.device("cuda") model.to(device) target_model.to(device)
データをロードする必要があるため、デバイス変数はグローバルになります。
また、勾配降下を使用してモデルの重みを更新するオプティマイザーを定義する必要があります。 はい、複数あります。
optimizer = optim.Adam(model.parameters(), lr=0.00003)
すべて一緒に
import torch.nn as nn import torch device = torch.device("cuda") def create_new_model(): model = nn.Sequential( nn.Linear(2, 32), nn.ReLU(), nn.Linear(32, 32), nn.ReLU(), nn.Linear(32, 3) ) target_model = copy.deepcopy(model) # def init_weights(layer): if type(layer) == nn.Linear: nn.init.xavier_normal(layer.weight) model.apply(init_weights) # , (GPU CPU) model.to(device) target_model.to(device) # , optimizer = optim.Adam(model.parameters(), lr=0.00003) return model, target_model, optimizer
ここで、エラー関数とそれに沿った勾配を考慮し、降下を適用する関数を宣言します。 ただし、その前に、バッチからGPUにデータをダウンロードする必要があります。
state, action, reward, next_state, done = batch # state = torch.tensor(state).to(device).float() next_state = torch.tensor(next_state).to(device).float() reward = torch.tensor(reward).to(device).float() action = torch.tensor(action).to(device) done = torch.tensor(done).to(device)
次に、Q関数の実際の値を計算する必要がありますが、それがわからないため、次の状態の値を使用して評価します。
target_q = torch.zeros(reward.size()[0]).float().to(device) with torch.no_grad(): # Q-function target_q[done] = target_model(next_state).max(1)[0].detach()[done] target_q = reward + target_q * gamma
そして現在の予測:
q = model(state).gather(1, action.unsqueeze(1))
target_qとqを使用して、損失関数を計算し、モデルを更新します。
loss = F.smooth_l1_loss(q, target_q.unsqueeze(1)) # optimizer.zero_grad() # loss.backward() # . , for param in model.parameters(): param.grad.data.clamp_(-1, 1) # optimizer.step()
すべて一緒に
gamma = 0.99 def fit(batch, model, target_model, optimizer): state, action, reward, next_state, done = batch # state = torch.tensor(state).to(device).float() next_state = torch.tensor(next_state).to(device).float() reward = torch.tensor(reward).to(device).float() action = torch.tensor(action).to(device) done = torch.tensor(done).to(device) # , target_q = torch.zeros(reward.size()[0]).float().to(device) with torch.no_grad(): # Q-function target_q[done] = target_model(next_state).max(1)[0].detach()[done] target_q = reward + target_q * gamma # q = model(state).gather(1, action.unsqueeze(1)) loss = F.smooth_l1_loss(q, target_q.unsqueeze(1)) # optimizer.zero_grad() # loss.backward() # . , for param in model.parameters(): param.grad.data.clamp_(-1, 1) # optimizer.step()
モデルはQ関数のみを考慮し、アクションを実行しないため、エージェントが実行するアクションを決定する関数を決定する必要があります。 意思決定アルゴリズムとして、 -貪欲な政治。 彼女の考えは、エージェントは通常、貪欲にアクションを実行し、Q関数の最大値を選択しますが、確率は 彼はランダムな行動をとります。 アルゴリズムが貪欲なポリシーによってのみガイドされて実行されないアクションを検査できるように、ランダムアクションが必要です。このプロセスは探索と呼ばれます。
def select_action(state, epsilon, model): if random.random() < epsilon: return random.randint(0, 2) return model(torch.tensor(state).to(device).float().unsqueeze(0))[0].max(0)[1].view(1, 1).item()
バッチを使用してニューラルネットワークをトレーニングするため、環境とのやり取りの経験を保存し、そこからバッチを選択するバッファを必要とします。
class Memory: def __init__(self, capacity): self.capacity = capacity self.memory = [] self.position = 0 def push(self, element): """ """ if len(self.memory) < self.capacity: self.memory.append(None) self.memory[self.position] = element self.position = (self.position + 1) % self.capacity def sample(self, batch_size): """ """ return list(zip(*random.sample(self.memory, batch_size))) def __len__(self): return len(self.memory)
素朴な決定
最初に、学習プロセスで使用する定数を宣言し、モデルを作成します。
# model target model target_update = 1000 # , batch_size = 128 # max_steps = 100001 # exploration max_epsilon = 0.5 min_epsilon = 0.1 # memory = Memory(5000) model, target_model, optimizer = create_new_model()
相互作用プロセスをエピソードに分割することは論理的であるという事実にもかかわらず、学習プロセスを説明するためには、環境の各ステップの後に勾配降下の1ステップを作成したいので、それを別々のステップに分割する方が便利です。
ここで学習の1つのステップがどのように見えるかについて詳しく説明しましょう。 max_stepsステップのステップ番号と現在の状態stateでステップを作成していると仮定します。 次に、アクションを実行します -貪欲なポリシーは次のようになります。
epsilon = max_epsilon - (max_epsilon - min_epsilon)* step / max_steps action = select_action(state, epsilon, model) new_state, reward, done, _ = env.step(action)
獲得した経験をすぐにメモリに追加し、現在のエピソードが終了した場合は新しいエピソードを開始します。
memory.push((state, action, reward, new_state, done)) if done: state = env.reset() done = False else: state = new_state
そして、勾配降下のステップを実行します(もちろん、少なくとも1つのバッチを既に収集できる場合)。
if step > batch_size: fit(memory.sample(batch_size), model, target_model, optimizer)
これで、target_modelの更新が残ります。
if step % target_update == 0: target_model = copy.deepcopy(model)
ただし、学習プロセスもフォローしたいと思います。 これを行うには、epsilon = 0でtarget_modelを更新するたびに追加のエピソードを再生し、総報酬をwards_by_target_updatesバッファーに保存します。
if step % target_update == 0: target_model = copy.deepcopy(model) state = env.reset() total_reward = 0 while not done: action = select_action(state, 0, target_model) state, reward, done, _ = env.step(action) total_reward += reward done = False state = env.reset() rewards_by_target_updates.append(total_reward)
すべて一緒に
# model target model target_update = 1000 # , batch_size = 128 # max_steps = 100001 # exploration max_epsilon = 0.5 min_epsilon = 0.1 def fit(): # memory = Memory(5000) model, target_model, optimizer = create_new_model() for step in range(max_steps): # epsilon = max_epsilon - (max_epsilon - min_epsilon)* step / max_steps action = select_action(state, epsilon, model) new_state, reward, done, _ = env.step(action) # , , memory.push((state, action, reward, new_state, done)) if done: state = env.reset() done = False else: state = new_state # if step > batch_size: fit(memory.sample(batch_size), model, target_model, optimizer) if step % target_update == 0: target_model = copy.deepcopy(model) #Exploitation state = env.reset() total_reward = 0 while not done: action = select_action(state, 0, target_model) state, reward, done, _ = env.step(action) total_reward += reward done = False state = env.reset() rewards_by_target_updates.append(total_reward) return rewards_by_target_updates
このコードを実行すると、次のグラフのようなものが得られます。

何が悪かったのですか?
これはバグですか? これは間違ったアルゴリズムですか? これらの悪いパラメーターはありますか? そうでもない。 実際、問題はタスク、つまり報酬の機能です。 もっと詳しく見てみましょう。 各ステップで、エージェントは-1の報酬を受け取ります。これはエピソードが終了するまで発生します。 そのような報酬は、エージェントができるだけ早くエピソードを完了するように動機付けますが、同時に彼にそれを行う方法を教えません。 このため、エージェントのこのような定式化の問題を解決する方法を学ぶ唯一の方法は、探索を使用して何度も解決することです。
もちろん、私たちの代わりに、より複雑なアルゴリズムを使用して環境を研究することもできます -貪欲なポリシー。 ただし、第一に、それらのアプリケーションのために、我々のモデルはより複雑になりますので、避けたいと思います。第二に、このタスクに十分に機能するという事実ではありません。 代わりに、タスク自体を変更することによって、つまり報酬関数を変更することによって、つまり問題の原因を取り除くことができます。 いわゆる報酬シェーピングを適用します。
収束の高速化
直感的な知識から、丘を登るには加速する必要があることがわかります。 速度が速いほど、エージェントは問題の解決に近づきます。 たとえば、報酬に特定の係数を持つ速度モジュールを追加することで、これについて彼に伝えることができます。
modified_reward =報酬+ 10 * abs(new_state [1])
したがって、関数フィットの行
memory.push((状態、アクション、報酬、new_state、完了))に置き換える必要があります
memory.push((状態、アクション、modified_reward、new_state、完了))ここで、新しいチャートを見てみましょう(変更せずに元の賞を提示します):
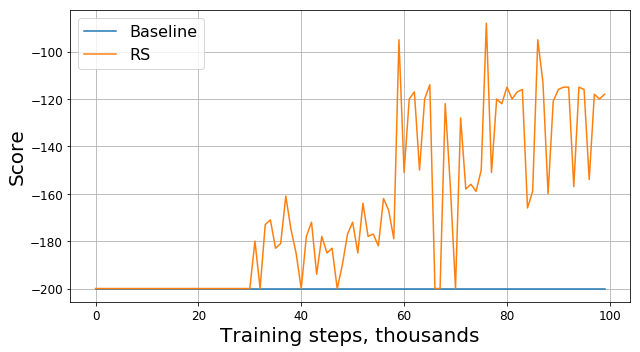
ここで、RSはReward Shapingの略です。
これをするのはいいですか?
進歩は明らかです。賞が-200とは異なり始めたため、エージェントは丘を登ることを明確に学びました。 残っている質問は1つだけです。報酬の機能を変更すると、タスク自体も変更されます。見つかった新しい問題の解決策は、古い問題に役立つのでしょうか。
そもそも、私たちの場合の「良さ」の意味を理解しています。 問題を解決するために、最適なポリシーを見つけようとしています。エピソードの総報酬を最大化するポリシーです。 この場合、「good」という単語を「optimal」という単語に置き換えることができます。探しているからです。 また、DQNが修正された問題の最適な解決策を遅かれ早かれ見つけ出し、局所的な最大値で動けなくなることを楽観的に願っています。 したがって、質問は次のように再定式化できます。報酬の機能を変更すると、問題自体も変更されます。新しい問題の最適な解決策は古い問題に最適ですか?
結局のところ、一般的なケースではそのような保証を提供することはできません。 答えは、報酬の機能を正確にどのように変更したか、それが以前にどのように配置されたか、環境自体がどのように配置されたかによって異なります。 幸いなことに、報酬の関数を変更すると、見つかったソリューションの最適性にどのように影響するかを調査した著者の記事があります。
まず、潜在的な方法に基づいた「安全な」変更のクラス全体を見つけました。 どこで -状態。状態のみに依存します。 そのような機能に対して、著者は、新しい問題の解決策が最適であれば、古い問題の解決策も最適であることを証明することができました。
第二に、著者は他の そのような問題、報酬関数R、および変更された問題に対する最適な解決策があるため、この解決策は元の問題にとって最適ではありません。 これは、潜在的な方法に基づかない変更を使用した場合、見つかったソリューションの良さを保証できないことを意味します。
したがって、報酬関数を変更するための潜在的な関数の使用は、アルゴリズムの収束率のみを変更できますが、最終的なソリューションには影響しません。
収束を正しくスピードアップする
報酬を安全に変更する方法がわかったので、単純なヒューリスティックの代わりに潜在的な方法を使用して、タスクを再度変更してみましょう。
modified_reward =報酬+ 300 *(ガンマ* abs(new_state [1])-abs(state [1]))
元の賞のスケジュールを見てみましょう:
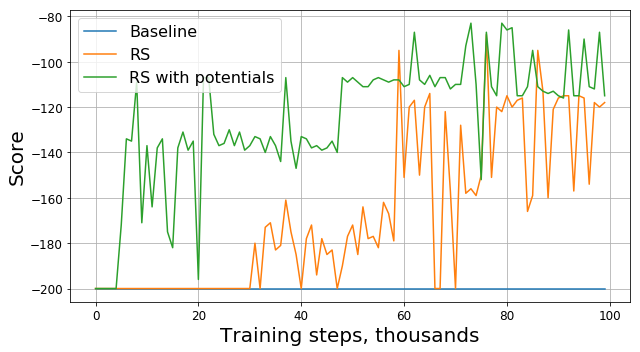
結局のところ、理論的な保証に加えて、潜在的な機能の助けを借りて報酬を変更すると、特に初期段階で結果が大幅に改善されました。 もちろん、エージェントをトレーニングするためにより最適なハイパーパラメーター(ランダムシード、ガンマ、およびその他の係数)を選択できる可能性がありますが、いずれにしてもモデルの収束速度を大幅に向上させるシェーピングに報酬を与えます。
あとがき
最後まで読んでくれてありがとう! 強化訓練へのこの小さな実践指向の遠足を楽しんだことを願っています。 マウンテンカーは「おもちゃ」の仕事であることは明らかですが、気づいたように、人間の観点からそのような一見単純な仕事でも解決するようエージェントに教えることは難しい場合があります。