畳み込みニューラルネットワークは、人間とは異なり、歪んだ画像を分類する優れた役割を果たします。

この記事では、高度なディープニューラルネットワークが歪んだ画像を完全に認識できる理由と、ニューラルネットワークが自然写真を分類するために使用する驚くほど簡単な戦略を明らかにする方法を示します。 ICLR 2019で公開されたこれらの発見には多くの意味があります。まず、「 ImageNet 」ソリューションを見つけることは考えられていたよりもはるかに簡単であることを示しています。 第二に、それらは、より解釈可能で理解しやすい画像分類システムを作成するのに役立ちます。 第三に、現代の畳み込みニューラルネットワーク(SNA)で観察されるいくつかの現象、たとえば、テクスチャを検索する傾向(ICLR 2019および対応するブログエントリの他の研究を参照)、およびオブジェクトの部分の空間配置を無視する傾向について説明します。
古き良きワードバッグモデル
ディープラーニングが登場する前の古き良き時代では、自然な画像の認識は非常に簡単でした。主要な視覚的特徴(「単語」)のセットを定義し、画像に各視覚的特徴が現れる頻度(「バッグ」)を決定し、これらに基づいて画像を分類しました数字。 したがって、このようなコンピュータービジョンのモデルは、「単語の袋」(単語の袋またはBoW)と呼ばれます。 たとえば、人間の目とペンという2つの視覚的特徴があり、画像を「人」と「鳥」の2つのクラスに分類するとします。 最も単純なBoWモデルは次のようになります。画像で見つかったそれぞれの目について、「人」に有利な証言を1増やします。逆に、各ペンに対して「鳥」に有利な証言を1増やします。より多くの証拠が得られるクラスです。
このような単純なBoWモデルの便利な機能は、意思決定プロセスの解釈可能性と明確さです:特定のクラスに有利な画像の特定の機能を正確に確認できるため、機能の空間統合は非常に単純です(ディープニューラルネットワークの機能の非線形統合と比較して)モデルがどのように決定を下すかを理解するだけです。
従来のBoWモデルは非常に人気があり、ディープラーニングが侵入する前は非常に効果的でしたが、効率が比較的低いためにすぐに流行しました。 しかし、ニューラルネットワークはBoWとは根本的に異なる決定戦略を使用していると確信していますか?
バッグ機能を備えた深さ解釈ネットワーク(BagNet)
この仮定をテストするために、BoWモデルの解釈可能性と明快さをニューラルネットワークの効率と組み合わせます。 戦略は次のようになります。
- 画像を小さな断片qx qに分割します。
- ピースをニューラルネットワークに渡して、各ピースのクラスメンバーシップ(ロジット)の証拠を取得します。
- すべての部分の証拠を要約して、イメージ全体のレベルで解決策を取得します。
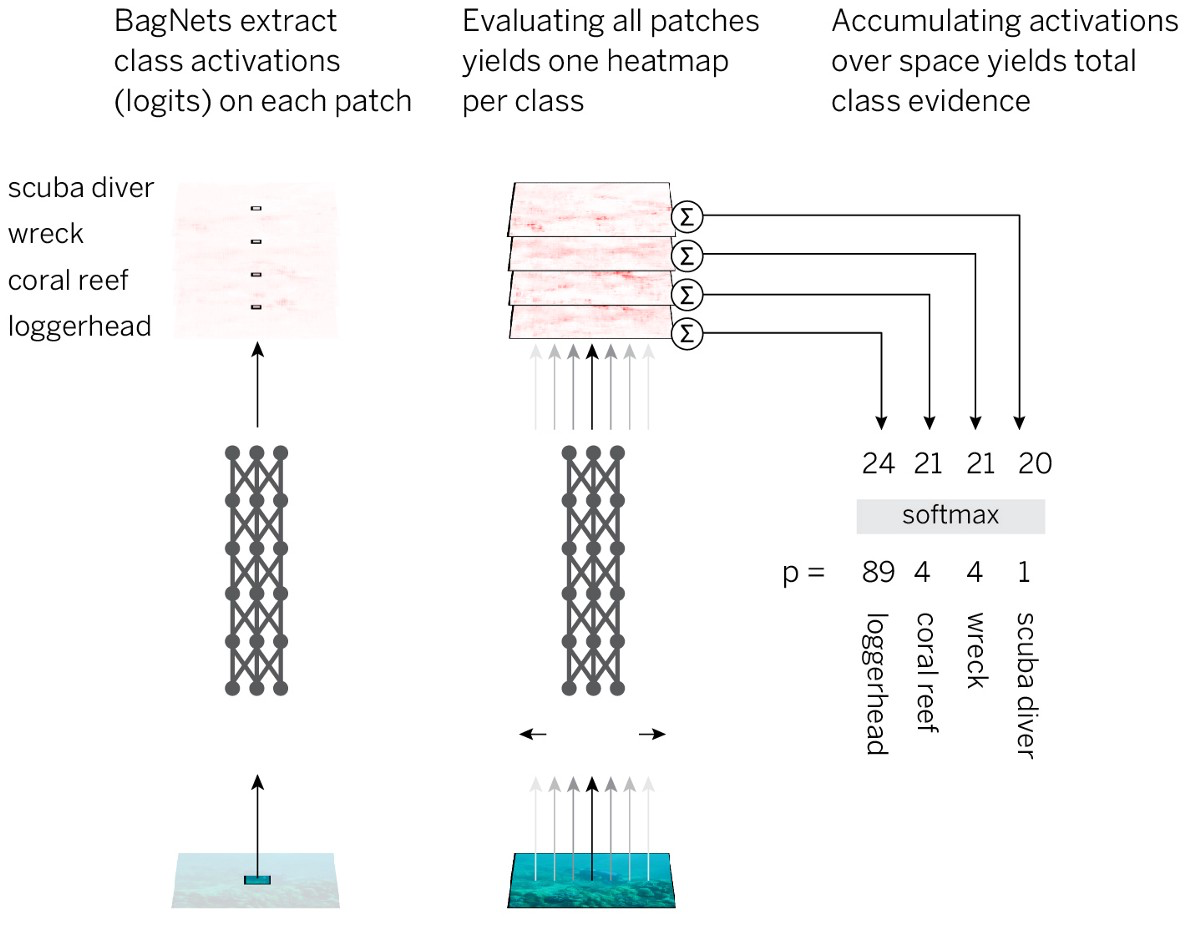
この戦略を最も簡単な方法で実装するために、標準のResNet-50アーキテクチャを採用し、ほぼすべての3x3畳み込みを1x1畳み込みに置き換えています。 その結果、最後の畳み込み層の各非表示要素は、画像のごく一部しか「見えません」(つまり、知覚領域は画像サイズよりもはるかに小さくなります)。 そのため、事前に計画された戦略を適用しながら、画像の強制的なマークアップを回避し、標準のSNAに可能な限り近づけます。 結果のアーキテクチャをBagNet-qと呼びます。ここで、qは最上層の知覚フィールドのサイズを示します(q = 9、17、および33でモデルをテストしました)。 BagNet-qはResNet-50よりも約2.5倍長く動作します。
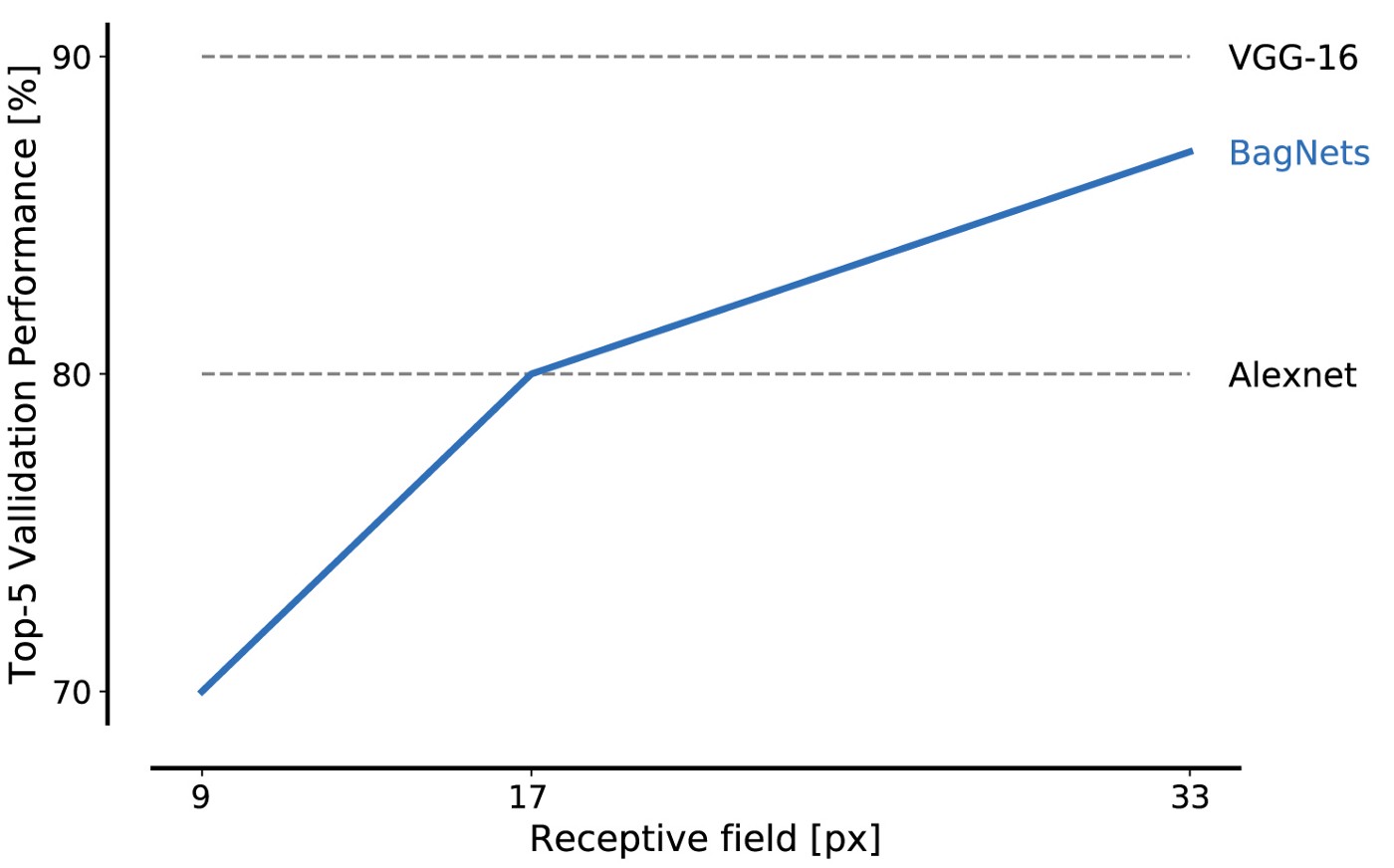
ImageNetデータベースのデータに対するBagNetのパフォーマンスは、小片を使用する場合でも印象的です:17x17ピクセルのフラグメントはAlexNetレベルの効率を達成するのに十分であり、33x33ピクセルのフラグメントは87%の精度を達成するのに十分で、トップ5に入ります。 3x3パッケージをより慎重に配置し、ハイパーパラメーターを調整することにより、効率を高めることができます。
これが私たちの最初の主要な結果です。ImageNetは小さな画像機能のセットのみを使用して解決できます。 オブジェクトの形状やオブジェクトの部分間の相互作用など、構図の部分の遠い空間的関係は完全に無視できます。 それらは問題を解決するために絶対に必要ではありません。
BagNet'ovの注目すべき特徴は、意思決定システムの透明性です。 たとえば、特定のクラスで最も特徴的な画像の特徴を見つけることができます。 たとえば、大きな魚であるテンチは、通常、緑の背景の指の画像によって認識されます。 なんで? このカテゴリーの写真のほとんどには、トロフィーとしてテンチを持っている漁師がいるからです。 また、BagNetが画像を線として誤って認識する場合、これは通常、写真のどこかに緑の背景に指があるために発生します。

画像の最も特徴的な部分。 各セルの一番上の行は正しい認識に対応し、一番下の行は誤った認識につながる気を散らす断片に対応しています
また、画像のどの部分が決定に寄与したかを示す正確な「ヒートマップ」も取得します。

ヒートマップは近似ではなく、画像の各部分の寄与を正確に示します。
BagNetは、画像の局所的特徴と対象物のカテゴリーとの間の弱い統計的相関に基づいてのみImageNetで高い精度を得ることが可能であることを実証しています。 これで十分な場合、なぜ標準のResNet-50ニューラルネットワークは根本的に異なることを学ぶのでしょうか? 画像の豊富な局所的特徴が問題を解決するのに十分である場合、ResNet-50がオブジェクトの形状などの複雑な大規模な関係を研究する必要があるのはなぜですか?
最新のSNSが最も単純なBoWネットワークの運用と同様の戦略に従うという仮説をテストするために、BagNetの次の「兆候」で異なるネットワーク-ResNet、DenseNet、およびVGGをテストしました。
- ソリューションは、イメージフィーチャの空間シャッフルとは無関係です(これはVGGモデルでのみ確認できます)。
- 画像のさまざまな部分の変更は、互いに依存しないようにする必要があります(クラスメンバーシップへの影響という意味で)。
- 標準のSNAとBagNetのエラーは類似している必要があります。
- 標準のSNSとBagNetは、同様の機能に敏感でなければなりません。
4つのすべての実験で、SNSとBagNetの驚くほど類似した動作を発見しました。 たとえば、最後の実験では、BagNetがSNAと同じ画像の同じ場所に最も敏感であることを示しています(たとえば、重複している場合)。 実際、BagNetヒートマップ(空間感度マップ)は、DeepLift(DenseNet-169のヒートマップを直接計算する)などの属性メソッドによって取得されたヒートマップよりも、DenseNet-169の感度をよりよく予測します。 もちろん、SNAはBagNetの動作を正確に繰り返すわけではありませんが、特定の逸脱が実証されています。 特に、ネットワークが深くなるほど、機能のサイズが大きくなり、依存関係がさらに拡大します。 したがって、ディープニューラルネットワークは実際にはBagNetモデルよりも改善されていますが、分類の基礎が何らかの形で変化しているとは思いません。
BoW分類を超えて
BoW戦略のスタイルでSNAの意思決定を観察すると、SNAの奇妙な機能の一部を説明できます。 まず、これはSNAがテクスチャに非常に結びついている理由を説明しています 。 第二に、SNAが画像の一部の混合に敏感ではない理由。 これは、敵対的なステッカーや敵対的な妨害の存在を説明することもあります。混乱する信号は画像のどこにでも配置でき、SNSは画像の残りの部分に適合するかどうかに関係なく、この信号を確実にキャッチします。
実際、私たちの研究は、SNAが画像を認識する場合、多くの弱い統計法則を使用し、人々のようにオブジェクトのレベルで画像の一部を統合しないことを示しています。 同じことは、他のタスクや感覚モダリティにも当てはまります。
弱い統計的相関を使用する傾向を克服するために、アーキテクチャ、タスク、およびトレーニング方法を慎重に計画する必要があります。 1つのアプローチは、SNAトレーニングの歪みを小さなローカルフィーチャからよりグローバルなフィーチャに変換することです。 もう1つは、ニューラルネットワークが依存しない機能を削除または置換することです。これは、ICLR 2019の別の出版物で、スタイル転送の前処理を使用して、自然のオブジェクトのテクスチャを削除しました。
しかし、最大の問題の1つは画像の分類のままです。ローカルフィーチャが十分であれば、自然界の実際の「物理」を研究するインセンティブはありません。 モデルを動かしてオブジェクトの物理的性質を調べるように、タスクを再構築する必要があります。 これを行うには、ほとんどの場合、モデルが因果関係を抽出できるように、純粋に観察的な教示を超えて、入力データと出力データの相関関係を調べる必要があります。
一緒に、我々の結果は、SNAが非常に単純な分類戦略に従うことができることを示唆しています。 2019年にそのような発見ができるという事実は、ディープニューラルネットワークの作業の内部機能をまだ理解していないことを強調しています。 理解が不足しているため、人間と機械の知覚のギャップを埋める根本的に改善されたモデルとアーキテクチャを開発することはできません。 理解を深めることで、このギャップを狭める方法を見つけることができます。 これは非常に便利です。SNAをオブジェクトの物理的特性にシフトしようとすると、人間レベルでのノイズへの耐性が突然達成されました 。 私たちの世界の物理的および因果関係の性質を真に理解するSNAの開発に向かう途中で、他の多くの興味深い結果が現れることを期待しています。