
私は小さなプロジェクトについての話を共有します:投稿の著者が誰であるか知らずに、コメントで著者の回答を見つける方法。
機械学習に関する最小限の知識でプロジェクトを開始しましたが、ここでは専門家にとって新しいものは何もないと思います。 この資料は、ある意味では、さまざまな記事をまとめたものです。この記事では、どのようにタスクにアプローチしたかを説明します。
私の初期データは次のとおりでした。2.5Mのメディア素材とそれらに関する3950万のコメントを含むデータベース。 1Mの投稿については、何らかの形で資料の著者が知られています(この情報はデータベースに存在するか、間接的な根拠に基づいてデータを分析して取得されました)。 これに基づいて、マークアップされた215Kレコードからデータセットが作成されました。
最初は、自然な知性によって発せられ、全文検索または正規表現を使用したsqlクエリに変換されるヒューリスティックベースのアプローチを使用しました。 解析するテキストの最も簡単な例:「コメントをありがとう」または「良い評価をありがとう」。これは99.99%のケースの著者であり、「仕事をありがとう」または「ありがとう!」 資料を郵送します。 ありがとう!」-通常のレビュー。 そのようなアプローチでは、明白なタイプミスの場合、または著者がコメンテーターと対話している場合を除き、明らかな偶然の一致のみを除外できます。 したがって、ニューラルネットワークを使用することが決定されましたが、このアイデアは友人の助けなしでは実現しませんでした。
コメントの典型的なシーケンス、著者のどれですか?
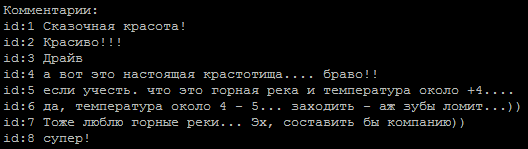
答え 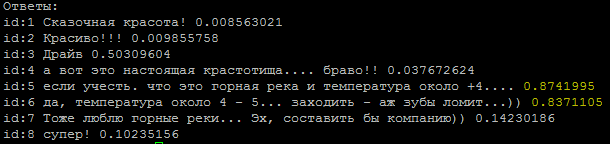
テキストの調性を決定する方法が基礎として採用されました;タスクは、著者ではなく著者の2つのクラスで簡単です。 モデルをトレーニングするために、仮想マシンにGPUとJupiterノートブックインターフェイスを提供するGoogleのサービスを使用しました。
インターネットで見つかったネットワークの例:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
htmlタグと特殊文字をクリアした行では、約65〜74%の精度が得られました。これは、コインを投げることと大差ありませんでした。
興味深い点は、
pad_sequences(x_train, maxlen=max_len, padding='pre')
を介した入力シーケンスのアライメントが結果に大きな違いをもたらしたことです。 私の場合、最良の結果はpadding = 'post'でした。
次のステップは、補題の使用であり、すぐに最大80%の精度の向上が得られ、これをさらに処理することができました。 現在の主な問題は、テキストを正しくクリアすることです。 たとえば、「ありがとう」という単語のタイプミスは、そのような正規表現に変換されました(使用頻度によってタイプミスが選択されました)(このような表現は、半ダースから20ダース蓄積しました)。
re16 = re.compile(ur"(?:\b:(?:1|c(?:|)|(?:|)|(?:(?:|(?:(?:(?:|(?:)?|))?|(?:)?))|)|(?:(?:(?:|)|)||||(?:(?:||(?:|)|(?:|(?:(?:(?:||(?:(?:||(?:[]|)|[]))?|[і]))?|||1)||)|)|||[]|(?:|)|(?:(?:(?:[]|)|?|(?:(?:(?:|(?:)?))?|)|(?:|)))?)||)|(?:|x))\b)", re.UNICODE)
ここでは、この言葉を各文章に追加する必要があると考える過度に礼儀正しい人々に特別な感謝を表明したいと思います。
タイプミスの割合を減らすことが必要でした、なぜなら lemmatizerの出口で奇妙な言葉を発し、有用な情報を失います。
しかし、銀色の裏地があり、タイプミスや複雑なテキストクリーニングの処理にうんざりしています。単語のベクトル表現word2vecを使用しました。 この方法では、すべてのタイプミス、タイプミス、および同義語を、狭い間隔のベクトルに変換できました。

ベクトル空間での単語とその関係。
クリーニングルールは大幅に簡素化され(aha、ストーリーテラー)、すべてのメッセージ、ユーザー名が文章に分割され、ファイルにアップロードされました。 重要なポイント:コメンテーターの簡潔さにより、高品質のベクターを構築するために、例えばフォーラムやウィキペディアからの追加のコンテキスト情報が必要です。 作成されたファイルについて、古典的なword2vec、Glove、FastTextの3つのモデルがトレーニングされました。 多くの実験を経て、私は最終的にFastTextに落ち着きました。これは、私の場合で最も質的に特徴的な単語クラスターです。
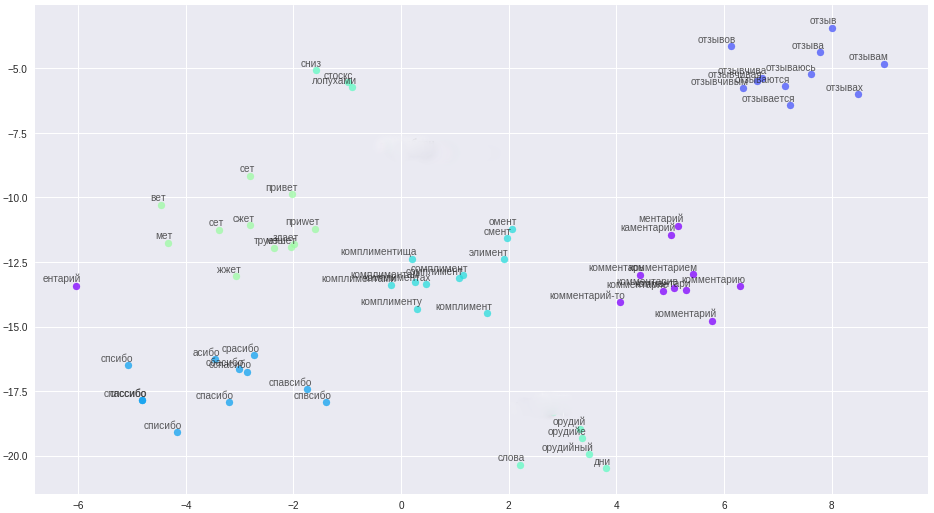
これらすべての変更により、安定した84〜85%の精度が得られました。
モデルの例
def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X) # X = Dropout(0.1)(X) X = MaxPooling1D(pool_size=2)(X) X = LSTM(256, kernel_regularizer=regularizers.l2(0.004))(X) X = Dropout(0.3)(X) X = Dense(128, kernel_regularizer=regularizers.l2(0.0004))(X) X = LeakyReLU()(X) X = BatchNormalization()(X) X = Dense(1, activation="sigmoid")(X) model = Model(model_input, X, name='w2v_conv1d') return model def model_gru(model_input, embd_size = 128): X = model_conv_core(model_input, embd_size) X = MaxPooling1D(2)(X) X = Dropout(0.2)(X) X = GRU(256, activation='relu', return_sequences=True, kernel_regularizer=regularizers.l2(0.004))(X) X = Dropout(0.5)(X) X = GRU(128, activation='relu', kernel_regularizer=regularizers.l2(0.0004))(X) X = Dropout(0.5)(X) X = BatchNormalization()(X) X = Dense(1, activation="sigmoid")(X) model = Model(model_input, X, name='w2v_gru') return model def model_conv2d(model_input, embd_size = 128): from keras.layers import MaxPool2D, Conv2D, Reshape num_filters = 256 filter_sizes = [3, 5, 7] X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) reshape = Reshape((maxSequenceLength, embd_size, 1))(X) conv_0 = Conv2D(num_filters, kernel_size=(filter_sizes[0], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape) conv_1 = Conv2D(num_filters, kernel_size=(filter_sizes[1], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape) conv_2 = Conv2D(num_filters, kernel_size=(filter_sizes[2], embd_size), padding='valid', kernel_initializer='normal', activation='relu')(reshape) maxpool_0 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[0] + 1, 1), strides=(1,1), padding='valid')(conv_0) maxpool_1 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[1] + 1, 1), strides=(1,1), padding='valid')(conv_1) maxpool_2 = MaxPool2D(pool_size=(maxSequenceLength - filter_sizes[2] + 1, 1), strides=(1,1), padding='valid')(conv_2) X = concatenate([maxpool_0, maxpool_1, maxpool_2], axis=1) X = Dropout(0.2)(X) X = Flatten()(X) X = Dense(int(embd_size / 2.0), activation='relu', kernel_regularizer=regularizers.l2(0.004))(X) X = Dropout(0.5)(X) X = BatchNormalization()(X) X = Dense(1, activation="sigmoid")(X) model = Model(model_input, X, name='w2v_conv2d') return model
コード内の6つのモデル。 一部のモデルはネットワークから取得され、一部は独立して発明されています。
モデルごとに異なるコメントが際立っていることに気づき、これがモデルのアンサンブルを使用するアイデアを促しました。 最初に、アンサンブルを手動で組み立て、モデルの最適なペアを選択してから、ジェネレーターを作成しました。 徹底的な検索を最適化するために、グレーコードを基準として使用しました。
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
アンサンブルにより、「人生はより楽しくなりました」であり、モデルの正確性の現在の割合は86-87%のレベルに維持されます。これは、主にデータセットの一部の著者の質の低い分類に関連付けられています。

私が出会った問題:
- 不均衡なデータセット。 著者からのコメントの数は、他のコメンテーターよりもかなり少なかった。
- サンプル内のクラスは厳密な順序になります。 肝心なのは、分類の質が最初、中間、最後で大きく異なることです。 これは、f1メジャーのスケジュールの学習プロセスではっきりと見えます。
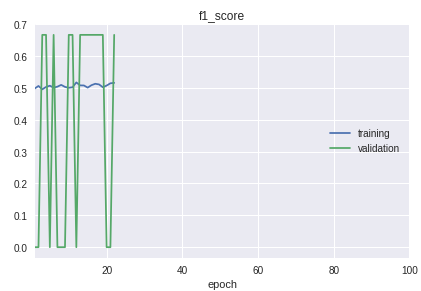
このソリューションでは、トレーニングサンプルと検証サンプルに分離するために自転車が作成されました。 実際にはほとんどの場合、sklearnライブラリーのtrain_test_splitプロシージャで十分です。
現在の作業モデルのグラフ:

その結果、短いコメントから著者の自信を持って定義されたモデルを得ました。 さらなる改善は、実際のデータの分類の結果をクリーニングし、トレーニングデータセットに転送することに関連付けられます。
追加の説明を含むすべてのコードはリポジトリにあります 。
追記:大量のテキストを分類する必要がある場合は、 VDCNNの 「Very Deep Convolutional Neural Network」 モデル (kerasでの実装 )をご覧ください。これはテキスト用のResNetに類似しています。
使用した材料:
• 機械学習コースの概要
• 畳み込みを使用した畳み込み解析
• NLPの畳み込みネットワーク
• 機械学習のメトリック
https://ld86.github.io/ml-slides/unbalanced.html
• モデルの内部