私が参加してから1年余りで、次の「対話」が行われました。
.Net App :Entity Frameworkよろしくお願いします。
Entity Framework :申し訳ありませんが、理解できませんでした。 どういう意味?
.Net App :はい、10万件のトランザクションのコレクションを取得しました。 そして今、そこに示されている証券の価格の正確さを迅速にチェックする必要があります。
Entity Framework :ああ、やってみましょう...
.Net App :コードは次のとおりです。
var query = from p in context.Prices join t in transactions on new { p.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; query.ToList();
エンティティフレームワーク :

クラシック 多くの人がこの状況に精通していると思います。ローカルコレクションとDbSetの JOINを使用して、データベースを「美しく」すばやく検索したいとき。 通常、この経験は残念です。
この記事( 他の記事の無料翻訳 )では、一連の実験を行い、この制限を回避するためのさまざまな方法を試します。 コード(簡単な)、思考、ハッピーエンドのようなものがあります。
はじめに
誰もがEntity Frameworkについて知っており、多くの人が毎日それを使用しています 。多くの人が毎日それを使用しています。その他)ただし、ローカルコレクションとDbSetの JOINテーマは依然として弱点です。
挑戦する
価格のデータベースがあり、価格の正確性を確認する必要があるトランザクションのコレクションがあると仮定します。 そして、次のコードがあるとします。
var localData = GetDataFromApiOrUser(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in localData on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; var result = query.ToList();
このコードは、 Entity Framework 6ではまったく機能しません。 Entity Framework Coreでは -それは機能しますが、すべてがクライアント側で行われ、データベースに数百万のレコードがある場合-これはオプションではありません。
私が言ったように、私はこれを回避するさまざまな方法を試します。 単純なものから複雑なものまで。 私の実験では、次のリポジトリのコードを使用します 。 コードは、 C# 、. Net Core 、 EF Core 、およびPostgreSQLを使用して記述されています 。
また、費やした時間とメモリ消費量のいくつかの指標を撮影しました。 免責事項:テストが10分以上実行された場合、中断しました(制限は上からです)。 テストマシンIntel Core i5、8 GB RAM、SSD。

唯一の3つのテーブル: 価格 、 証券 、 価格ソース 。 価格-1000万エントリが含まれています。
方法1.ナイーブ
簡単なものから始めて、次のコードを使用しましょう。
var result = new List<Price>(); using (var context = CreateContext()) { foreach (var testElement in TestData) { result.AddRange(context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId)); } }
考え方は単純です。ループでは、データベースからレコードを1つずつ読み取り、結果のコレクションに追加します。 このコードには、単純さという利点が1つだけあります。 また、1つの欠点は低速です。データベースにインデックスがある場合でも、ほとんどの場合、データベースサーバーとの通信が必要になります。 メトリックは次のとおりです。
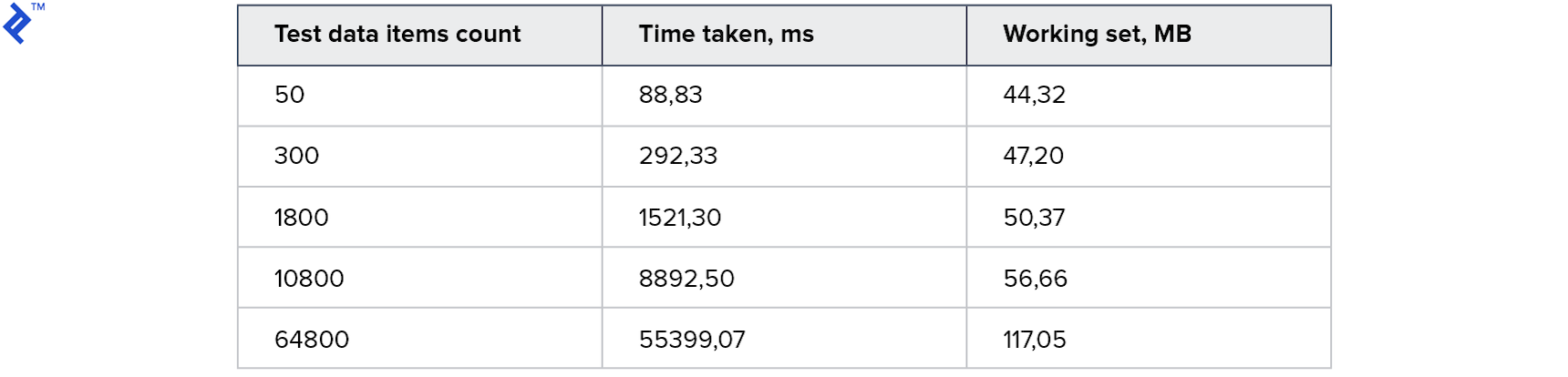
メモリ消費はわずかです。 大規模なコレクションには1分かかります。 始めるのは悪くありませんが、もっと早くしたいです。
方法2:単純な並列
並列処理を追加してみましょう。 アイデアは、複数のスレッドからデータベースにアクセスすることです。
var result = new ConcurrentBag<Price>(); var partitioner = Partitioner.Create(0, TestData.Count); Parallel.ForEach(partitioner, range => { var subList = TestData.Skip(range.Item1) .Take(range.Item2 - range.Item1) .ToList(); using (var context = CreateContext()) { foreach (var testElement in subList) { var query = context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId); foreach (var el in query) { result.Add(el); } } } });
結果:
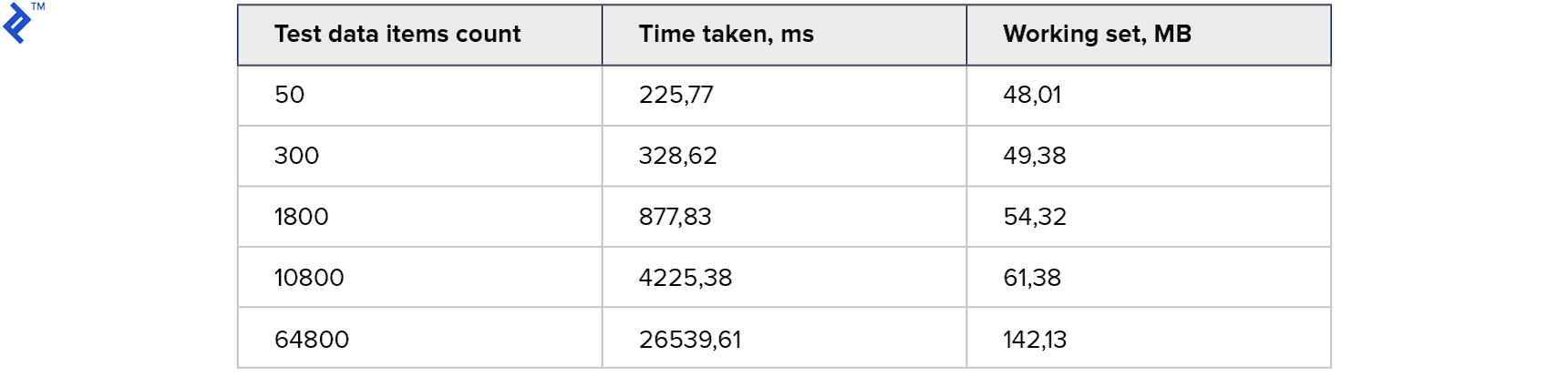
小さなコレクションの場合、このアプローチは最初の方法よりもさらに遅くなります。 最大の場合-2倍高速です。 興味深いことに、4つのスレッドが私のマシンで生成されましたが、これは4倍の高速化にはつながりませんでした。 これは、クライアント側とサーバー側の両方で、この方法のオーバーヘッドが大きいことを示唆しています。 メモリ消費量は増加しましたが、それほど大きくはありません。
方法3:複数を含む
他のことを試して、タスクを1つのクエリに減らしてみてください。 次のように実行できます。
- 一意のTicker 、 PriceSourceId、およびDate値の3つのコレクションを準備します
- リクエストを実行し、3を含む
- 結果をローカルで再確認する
var result = new List<Price>(); using (var context = CreateContext()) { // var tickers = TestData.Select(x => x.Ticker).Distinct().ToList(); var dates = TestData.Select(x => x.TradedOn).Distinct().ToList(); var ps = TestData.Select(x => x.PriceSourceId).Distinct().ToList(); // 3 Contains var data = context.Prices .Where(x => tickers.Contains(x.Security.Ticker) && dates.Contains(x.TradedOn) && ps.Contains(x.PriceSourceId)) .Select(x => new { Price = x, Ticker = x.Security.Ticker, }) .ToList(); var lookup = data.ToLookup(x => $"{x.Ticker}, {x.Price.TradedOn}, {x.Price.PriceSourceId}"); // foreach (var el in TestData) { var key = $"{el.Ticker}, {el.TradedOn}, {el.PriceSourceId}"; result.AddRange(lookup[key].Select(x => x.Price)); } }
ここでの問題は、実行時間と返されるデータの量が、データ自体(クエリとデータベースの両方)に大きく依存していることです。 つまり、必要なデータのみのセットが返され、追加のレコード(100倍以上)も返されます。
これは、次の例を使用して説明できます。 次のデータの表があると仮定します。

また、 TradedOn = 2018-01-01の Ticker1とTradedOn = 2018-01-02の Ticker2の価格が必要だとします。
次に、 ティッカーの一意の値=( Ticker1 、 Ticker2 )
そしてTradedOnの一意の値=( 2018-01-01、2018-01-02 )
ただし、これらの組み合わせに実際に対応するため、結果として4つのレコードが返されます。 悪いことは、より多くのフィールドが使用されるほど、結果として余分なレコードを取得する可能性が高くなることです。
このため、この方法で取得したデータは、クライアント側でさらにフィルタリングする必要があります。 そしてこれが最大の欠点です。
メトリックは次のとおりです。
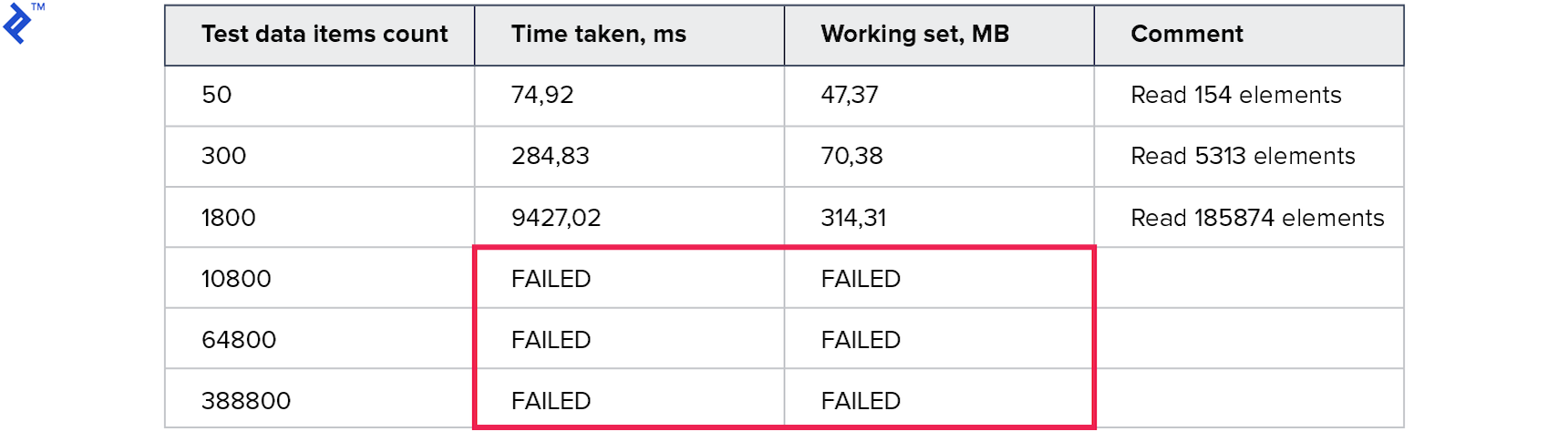
メモリ消費は、以前のすべての方法よりも悪いです。 読み取られた行の数は、要求された数の何倍にもなります。 大規模なコレクションのテストは、10分以上実行されたため中断されました。 この方法はよくありません。
方法4.述語ビルダー
反対側で試してみましょう:古き良き式 。 それらを使用して、次の形式で1つの大きなクエリを作成できます。
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
これにより、1つのリクエストを作成し、1回の呼び出しに必要なデータのみを取得できるようになることが期待されます。 コード:
var result = new List<Price>(); using (var context = CreateContext()) { var baseQuery = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId select new TestData() { Ticker = s.Ticker, TradedOn = p.TradedOn, PriceSourceId = p.PriceSourceId, PriceObject = p }; var tradedOnProperty = typeof(TestData).GetProperty("TradedOn"); var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId"); var tickerProperty = typeof(TestData).GetProperty("Ticker"); var paramExpression = Expression.Parameter(typeof(TestData)); Expression wholeClause = null; foreach (var td in TestData) { var elementClause = Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, tradedOnProperty), Expression.Constant(td.TradedOn) ), Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, priceSourceIdProperty), Expression.Constant(td.PriceSourceId) ), Expression.Equal( Expression.MakeMemberAccess( paramExpression, tickerProperty), Expression.Constant(td.Ticker)) )); if (wholeClause == null) wholeClause = elementClause; else wholeClause = Expression.OrElse(wholeClause, elementClause); } var query = baseQuery.Where( (Expression<Func<TestData, bool>>)Expression.Lambda( wholeClause, paramExpression)).Select(x => x.PriceObject); result.AddRange(query); }
コードは、以前の方法よりも複雑であることが判明しました。 Expressionを手動で構築するのは 、最も簡単で最速の操作ではありません。
指標:
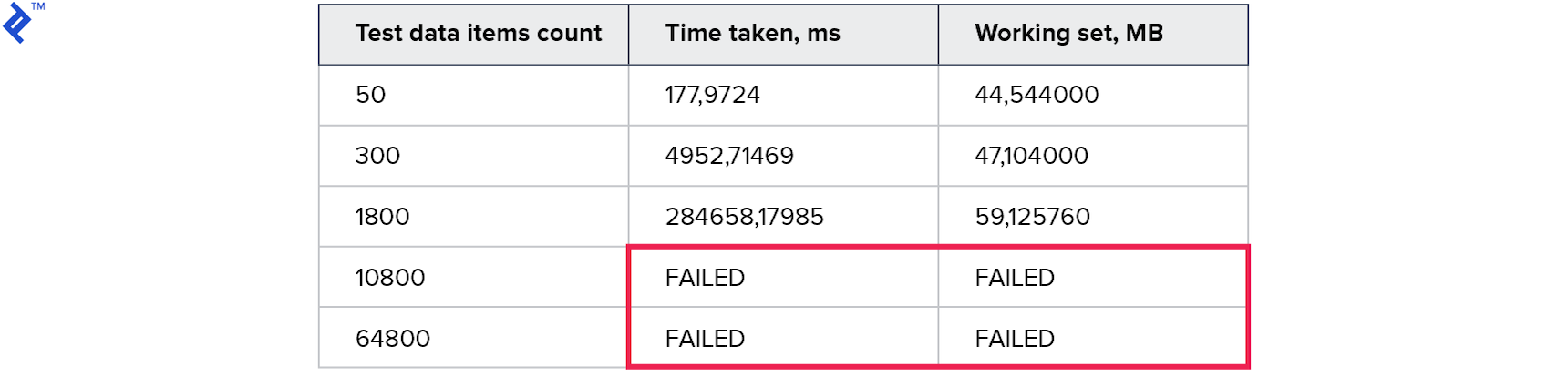
一時的な結果は、以前の方法よりもさらに悪化しました。 構築中のオーバーヘッドとツリーの通過は、1つのリクエストを使用することによるゲインよりもはるかに大きいことが判明したようです。
方法5:共有クエリデータテーブル
別のオプションを試してみましょう:
リクエストを完了するために必要なデータを書き込むデータベースに新しいテーブルを作成しました(暗黙的にコンテキストに新しいDbSetが必要です)。
今、あなたが必要な結果を得るために:
- トランザクションを開始
- クエリデータを新しいテーブルにアップロードする
- クエリ自体を実行します(新しいテーブルを使用)
- トランザクションのロールバック(クエリのデータテーブルをクリアするため)
コードは次のようになります。
var result = new List<Price>(); using (var context = CreateContext()) { context.Database.BeginTransaction(); var reducedData = TestData.Select(x => new SharedQueryModel() { PriceSourceId = x.PriceSourceId, Ticker = x.Ticker, TradedOn = x.TradedOn }).ToList(); // context.QueryDataShared.AddRange(reducedData); context.SaveChanges(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in context.QueryDataShared on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; result.AddRange(query); context.Database.RollbackTransaction(); }
最初の指標:
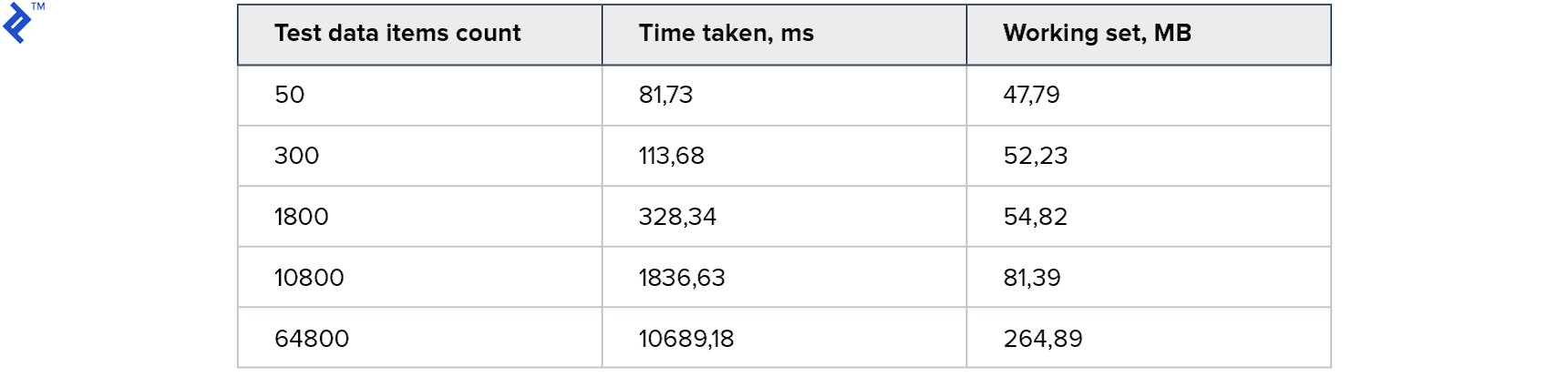
すべてのテストが機能し、迅速に機能しました! メモリ消費も許容されます。
したがって、トランザクションを使用することにより、このテーブルは複数のプロセスで同時に使用できます。 そして、これは実際の既存のテーブルであるため、 Entity Frameworkのすべての機能を使用できます。データをテーブルにロードし、 JOINを使用してクエリを作成し、実行するだけです。 一見、これが必要なものですが、重大な欠点があります。
- 特定の種類のクエリ用のテーブルを作成する必要があります
- トランザクションを使用する必要があります(そして、DBMSリソースを無駄にします)
- そして、読む必要があるときに何かを書く必要があるというまさにアイデアは奇妙に見えます。 リードレプリカでは、機能しません。
そして、残りはすでに使用できる多かれ少なかれ機能するソリューションです。
方法6. MemoryJoin拡張機能
これで、以前のアプローチを改善することができます。 考えは次のとおりです。
- 1つのタイプのクエリに固有のテーブルを使用する代わりに、一般的なオプションを使用できます。 つまり、 shared_query_dataのような名前でテーブルを作成し、いくつかのGuidフィールド、いくつかのLong 、いくつかのStringなどを追加します。 単純な名前を使用できます: Guid1 、 Guid2 、 String1 、 Long1 、 Date2など。 このテーブルは、クエリタイプの95%で使用できます。 プロパティ名は、後で選択パースペクティブを使用して「調整」できます。
- 次に、 shared_query_dataのDbSetを追加する必要があります。
- しかし、データベースにデータを書き込む代わりに、 VALUES構造を使用して値を渡すとしたらどうでしょうか。 つまり、最終的なSQLクエリでは、 shared_query_dataにアクセスする代わりに、 VALUESにアピールする必要があります。 どうやってやるの?
- Entity Framework Coreで-FromSqlを使用するだけです。
- Entity Framework 6では、 DbInterceptionを使用する必要があります。 つまり 、実行直前にVALUESコンストラクトを追加して、生成されたSQLを変更します。 これにより、制限が発生します。単一のリクエストでは、 VALUES構造は1つだけです。 しかし、それは動作します!
- データベースに書き込む予定はないので、最初のステップでshared_query_dataテーブルを作成します。まったく必要ありませんか? 回答:はい、必要ありませんが、クエリを作成するためにEntity Frameworkがデータスキームを知っている必要があるため、 DbSetはまだ必要です。 データベースに存在せず、Entity Frameworkを刺激するためだけに使用される一般化されたモデルにはDbSetが必要であり、それが何をしているのかがわかっていることがわかります。
- 入力は、次のタイプのオブジェクトのコレクションを受け取りました。
class SomeQueryData { public string Ticker {get; set;} public DateTimeTradedOn {get; set;} public int PriceSourceId {get; set;} }
- String1 、 String2 、 Date1 、 Long1 などのフィールドを持つDbSetを自由に使用できます
- Tickerを String1 、 Date1の TradedOn 、およびLong1のPriceSourceIdに格納します ( intとlongのフィールドを別々に作成しないように、 intはlongにマップします)
- FromFrom + VALUESは次のようになります。
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)")
- これで、入力時と同じ型を使用して投影を行い、便利なIQueryableを返すことができます。
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
私はこのアプローチを実装し、NuGetパッケージEntityFrameworkCore.MemoryJoinとして設計することもできました ( コードも入手可能です)。 名前にCoreという単語が含まれているという事実にもかかわらず、 Entity Framework 6もサポートされています。 私はこれをMemoryJoinと呼びましたが、実際にはVALUESコンストラクトでローカルデータをDBMSに送信し、すべての作業がその上で行われます。
コードは次のとおりです。
var result = new List<Price>(); using (var context = CreateContext()) { // : , var reducedData = TestData.Select(x => new { x.Ticker, x.TradedOn, x.PriceSourceId }).ToList(); // IEnumerable<> IQueryable<> var queryable = context.FromLocalList(reducedData); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in queryable on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; result.AddRange(query); }
指標:
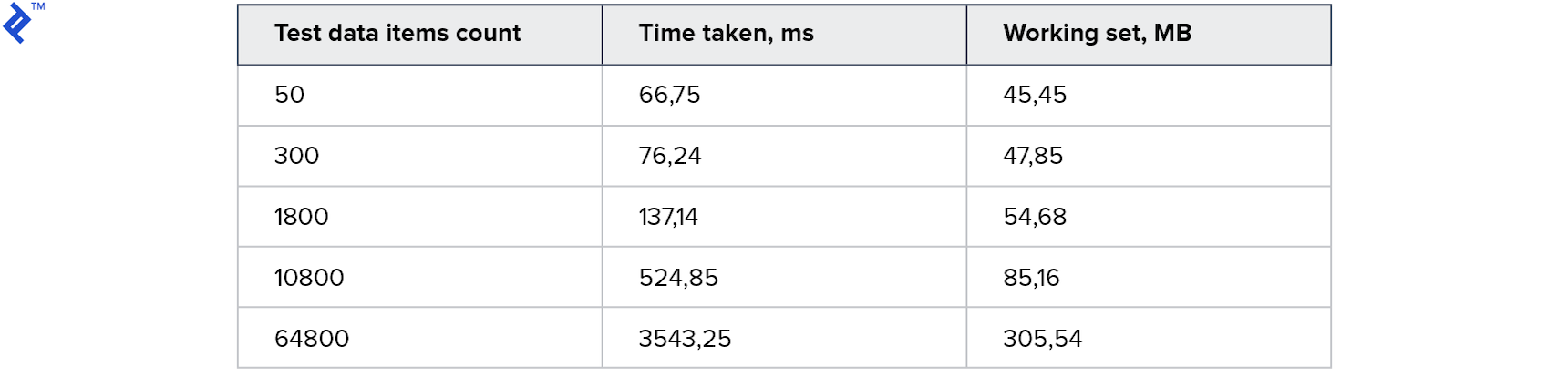
これは私が今まで試した中で最高の結果です。 コードは非常にシンプルで簡単であり、同時にリードレプリカでも機能していました。
SELECT "p"."PriceId", "p"."ClosePrice", "p"."OpenPrice", "p"."PriceSourceId", "p"."SecurityId", "p"."TradedOn", "t"."Ticker", "t"."TradedOn", "t"."PriceSourceId" FROM "Price" AS "p" INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId" INNER JOIN ( SELECT "x"."string1" AS "Ticker", "x"."date1" AS "TradedOn", CAST("x"."long1" AS int4) AS "PriceSourceId" FROM ( SELECT * FROM ( VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2), (2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5), (3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8) ) AS __gen_query_data__ (id, string1, date1, long1) ) AS "x" ) AS "t" ON (("s"."Ticker" = "t"."Ticker") AND ("p"."PriceSourceId" = "t"."PriceSourceId")
ここでは、Selectを使用した一般化モデル(フィールドString1 、 Date1 、 Long1 )が、コードで使用されるモデル(フィールドTicker 、 TradedOn 、 PriceSourceId )にどのように変わるかを確認することもできます。
すべての作業は、SQLサーバーで1つのクエリで実行されます。 そして、これは小さなハッピーエンドであり、最初に話した。 それでも、この方法を使用するには、理解と次の手順が必要です。
- 追加のDbSetをコンテキストに追加する必要があります(ただし、テーブル自体は省略できます)
- デフォルトで使用される一般化モデルでは、 Guid 、 String 、 Double 、 Long 、 Dateなどのタイプの3つのフィールドが宣言されています。 要求タイプの95%にはこれで十分です。 また、20個のフィールドを持つオブジェクトのコレクションをFromLocalListに渡すと、オブジェクトが複雑すぎることを示す例外がスローされます。 これは弱い制限であり、回避することができます-タイプを宣言し、そこに少なくとも100個のフィールドを追加できます。 ただし、より多くのフィールド-作業が遅くなります。
- 技術的な詳細は、私の記事に記載されています 。
おわりに
この記事では、JOINローカルコレクションとDbSetのトピックに関する考えを示しました。 VALUESを使用した私の開発は、コミュニティにとって興味深いものであると思われました。 この問題を自分で解決したとき、少なくとも私はそのようなアプローチに会いませんでした。 個人的には、この方法は現在のプロジェクトのパフォーマンスの問題を克服するのに役立ちました。おそらくあなたにも役立つでしょう。
誰かがMemoryJoinの使用は "難解"であり、さらに開発する必要があり、それまでは使用する必要がないと言うでしょう。 これがまさに私が非常に疑わしかった理由であり、ほぼ一年間、私はこの記事を書きませんでした。 私はそれがより簡単に動作することを望んでいることに同意します(いつかうまくいくことを望みます)が、最適化はジュニアのタスクではなかったことも言います。 最適化では、常にツールの動作を理解する必要があります。 そして、 最大 8倍の加速が得られる場合( Naive Parallel vs MemoryJoin )、2つのポイントとドキュメントを習得します。
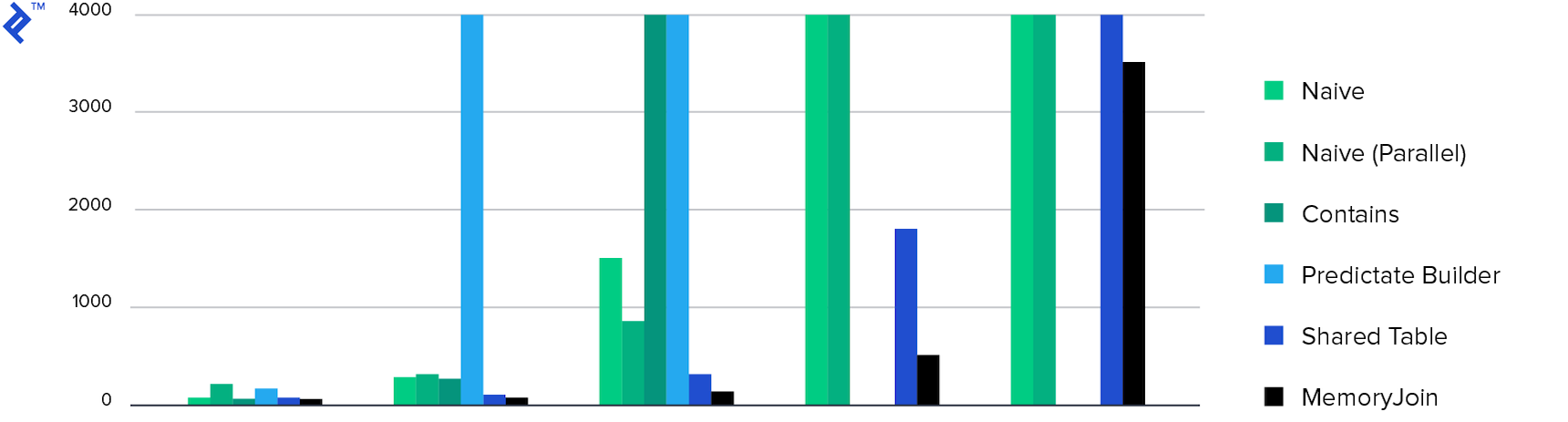
そして最後に、ダイアグラム:
費やした時間。 10分未満でタスクを完了したメソッドは4つだけであり、10秒未満でタスクを完了した唯一の方法はMemoryJoinです。
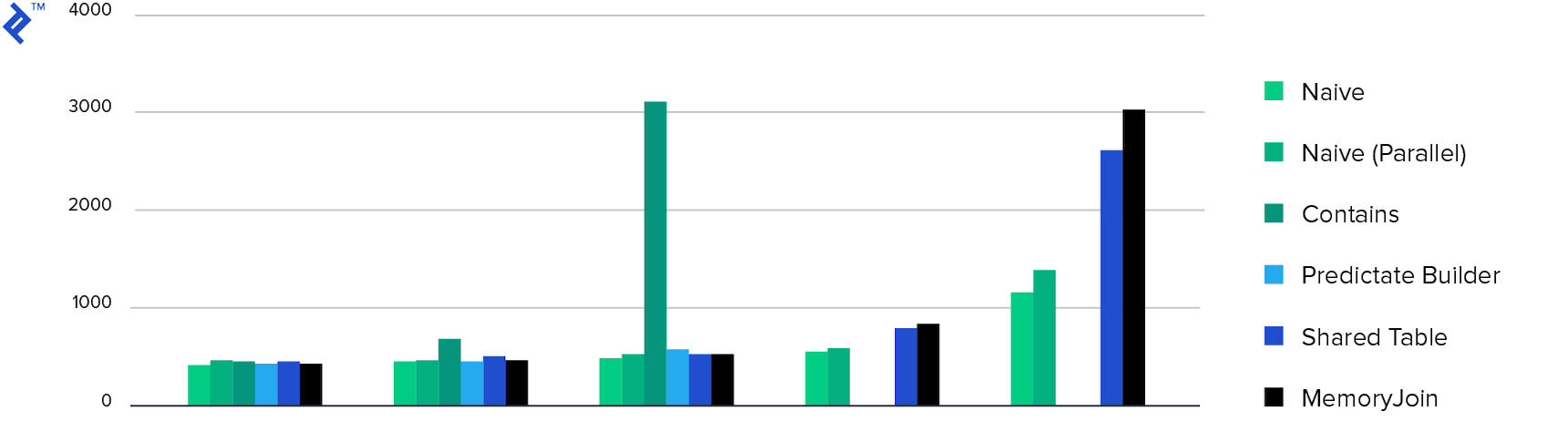
メモリ消費。 Multiple Containsを除き、すべてのメソッドはほぼ同じメモリ消費を示しました。 これは、返されるデータの量が原因です。
読んでくれてありがとう!